【論文紹介】物体の形状や構造についての教師情報・事前知識を用いない、姿勢を自由にコントロールできる3D表現の学習
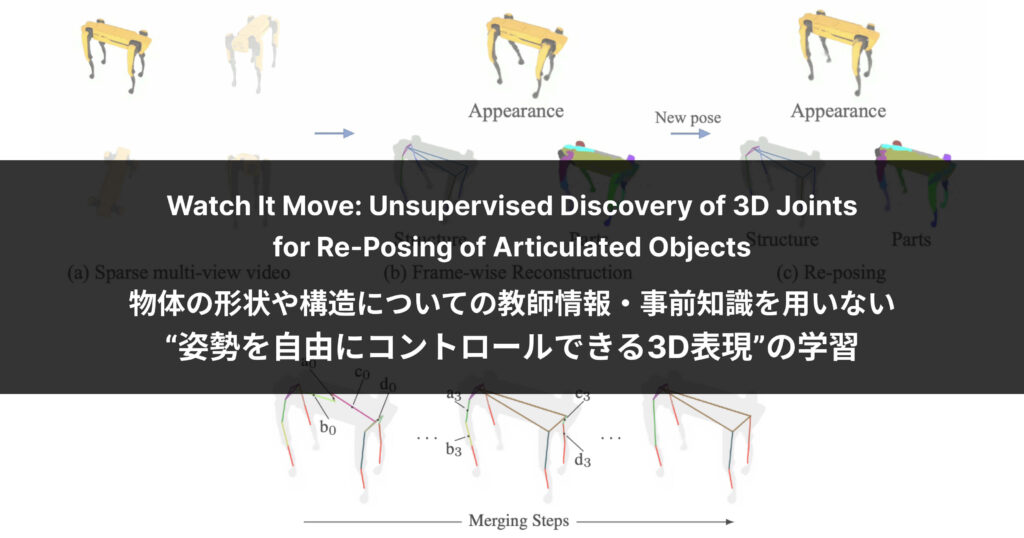
姿勢を自由にコントロールできるような多関節物体の3D表現を得るには、既存の手法では物体の姿勢を示す教師情報や構造についての事前知識が必要であり、これらを含むデータの構築には多くのコストがかかります。
今回は、この課題を克服するための新たな学習手法を提案した論文「Watch It Move: Unsupervised Discovery of 3D Joints for Re-Posing of Articulated Objects」について、著者の野口 敦裕が解説します。
研究背景
VR(仮想現実)・AR(拡張現実)空間やゲームなどの制作において、人や動物をはじめとしたキャラクターを動かすにあたって活用されるものに「3Dモデル」があります。これは、キャラクターをコンピュータ上の3D空間で立体的に描いてつくった形状データを指すもので、2D画像と異なり、前後・左右・上下の全方向からそのキャラクターの形を見ることができます。
人や動物のように関節を持つ物体=多関節物体について、このような3D表現を形にし、その物体の姿勢を自由にコントロールできるようにするには、現状「人の手で加工したり、3Dスキャナなどの特殊なセンサーを使用したりして3Dの形状を作り、骨を入れる」という作業が必要で多くの手間がかかります。
このような作業に代えて、 “データから自動で形状や構造の3D表現を構築する” ことで、さまざまなコンテンツ制作に貢献できるだろうと取り組んでいるのが、今回ご紹介する研究です。
関連研究を3つピックアップしてご紹介します。
①物体(関節を持たない)をさまざまな角度から撮影した複数の2D画像と「その画像をどこから写しているか」というカメラの視点の情報から、3D表現を得ることができる「NeRF:Neural Radiance Fields」1があります。この技術によって、実際の画像データには存在しないような、別視点から見た物体のリアルな見た目を描画することができますが、ここで扱えるのは静的なシーンに限られます。
②NeRFを動的なシーンに拡張した「D-NeRF: Neural Radiance Fields for Dynamic Scenes」2などの技術では、動いている物体(多関節物体を含む)の3D表現を得ることができます。しかしここで行えるのは、“視点を変える” ことのみです。つまり物体の動きとしては、実際の動画中のものが再現されるのみにとどまり、物体の姿勢を自由にコントロールすることはできません。
③NeRFを多関節物体に拡張した「NARF:Neural Articulated Radiance Fields」3では、2D画像から姿勢を自由にコントロールできる多関節物体の3D表現が得られます。



しかしその学習には、2Dの画像データに加えて
- 物体の姿勢を示す教師情報(※)
- 物体の構造にまつわる事前知識(その物体にいくつのパーツがあり、それぞれがどのように結合しているかなど)
が必要で、このような情報を含むデータを用意するには多くのコストがかかります。
※教師情報:モデルを訓練するために、画像データにあらかじめ付与される情報のこと
こうした従来の研究の課題をふまえ、今回の研究では、物体の姿勢にまつわる教師情報も構造にまつわる事前知識もない中で、姿勢を自由にコントロールできる3D表現を実現する新たな学習手法を提案しました。
方法と結果
今回提案した手法について、詳しくご紹介します。
【用語】
- フレーム
→動画のもととなる静止画像、各コマのこと - フレームID
→各フレームが動画中の何フレーム目かを示す数字
- 前景マスク
→物体が写っている部分が1、背景が0となっている画像で、物体が写っている領域の形状を含む情報 - 陰関数表現
→関数を利用して物体を表現する手法。3次元空間中のある点の座標を入力すると「その点における密度や色などの情報」を出力するニューラルネットワークを用いて物体の形状や見た目を表現する
提案手法では、物体の姿勢を示す教師情報や構造にまつわる事前知識を一切用いずに、姿勢を自由にコントロールできる3D表現を形づくる、つまり物体の見た目・形状・構造を同時に推定し再現することをゴールとします。
ここで用いるのは、物体が動いている様子を多視点から撮影した2D動画(※)のみです。
※各視点からの動画はすべて同じタイミングで撮影されているものとします。
【見た目・形状・構造の推定の流れ】
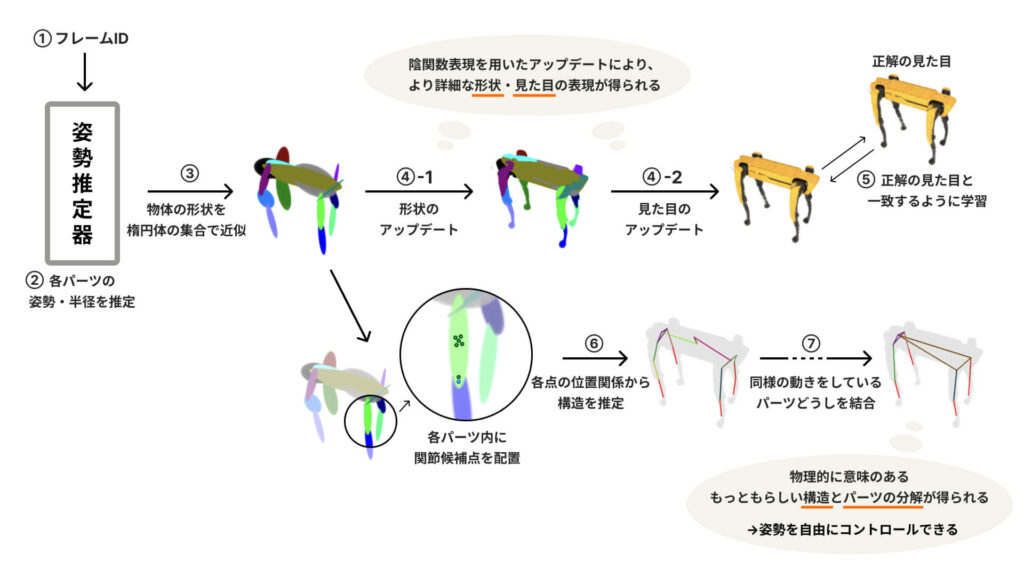
| ① 姿勢推定器がフレームIDを受け取る ② 物体の各パーツをまずは大まかに楕円体で表現することとし、フレームIDに対応する時刻における各パーツの姿勢と半径を姿勢推定器が推定する ③ ②で推定した各パーツの姿勢と半径をふまえ、楕円体の集合で物体の形状を近似する ④ 陰関数表現を使って、見た目と形状のアップデートを行う ⑤ ④を経てつくり出された見た目が、対応するフレームの正解の見た目と一致するように学習を行う ⑥ 各パーツの内部に関節位置の候補となる点を置き、点どうしの位置関係から物体の構造を推定する ⑦ 全フレームを通して同様の動きをしているパーツを結合し、よりもっともらしい構造とパーツの分解を学習する |
まずフレームIDを受け取って、その時刻における各パーツの姿勢と半径を推定する「姿勢推定器」を用意します。楕円体を使って物体の形状を単純化(※)し、楕円体で表したそれぞれのパーツの姿勢や半径など位置に関する情報をこの姿勢推定器を用いて明らかにすることで、物体の大まかな形状が得られます(①〜③)。
※楕円体のような基本的な形状などを用いて「その物体がどのような形状をしているか」を明確に示したものを、この記事では「明示的な表現」と表します。
ただ楕円体を用いた状態では物体の細かな形状までは表せないため、ここで「陰関数表現」との組み合わせが重要になります。
陰関数表現とは、関数を利用して物体を表現する手法のこと。3次元空間中のある点の座標を入力すると「その点における密度や色などの情報」を出力するニューラルネットワークを用いて、物体の形状や見た目を表現します。
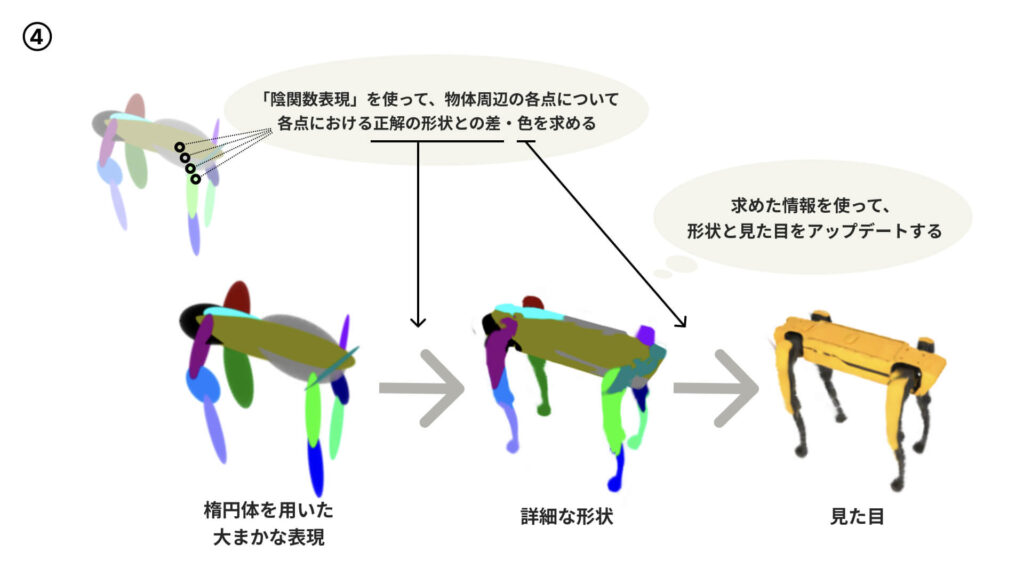
④では、「3D空間中の座標をインプットすると、その点における “楕円体で形づくった形状と正解の形状との差” と “色” がアウトプットされるモデルを用意。このモデルを使って物体周辺の各点について情報を求め、それらを用いて「物体を楕円体で大まかに表した状態」→「物体のより細かな形状や色まで表現された状態」へのアップデートを行います。
陰関数表現では、3D空間中のある点を見たときに「その点上にパーツがあるかどうか」までは分かりますが、「ではそのパーツがどのような形をしているか」「パーツどうしがどのように関係し合っているか」を推定するのは簡単ではありません。
そこで、明示的な表現を使って「ここにパーツがある」「ここに関節がありそうだ」ということを学び、その後陰関数表現を使って詳細な形状を探っていく……と2つの表現を組み合わせて用いているのが、提案手法の大きな特徴のひとつです。
====
提案手法では、物体の見た目と形状だけでなく、同時にパーツの分解と構造についても学習していきます。
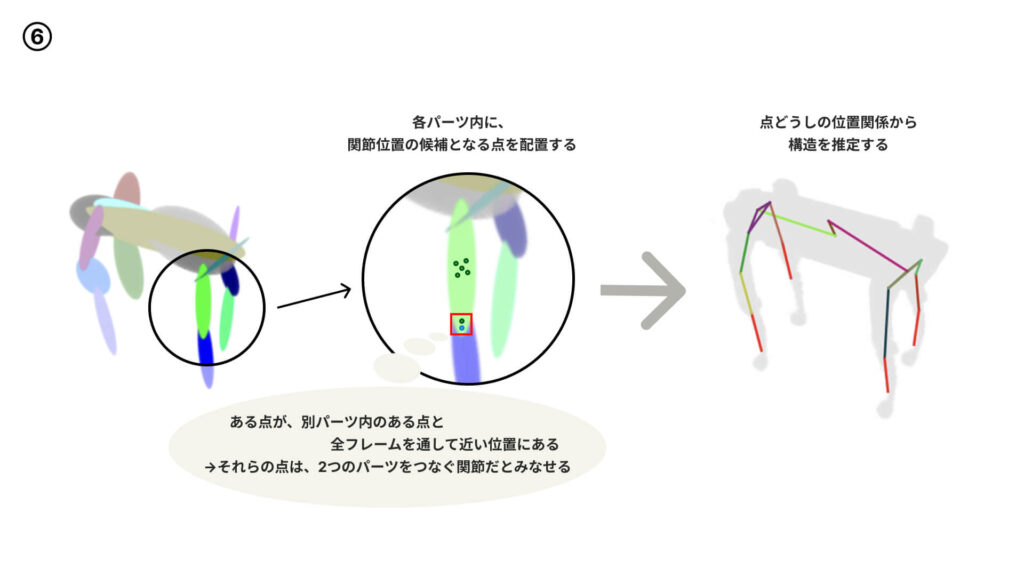
まず楕円体で表した各パーツの内部に関節候補点を置き、それらの各点の動画中での位置関係を見ることで、「この点は全フレームを通して別パーツ内のこの点と近い位置にあるから、これが関節だろう」と構造を推定していくことができます(⑥)。
このとき、本手法では「“その物体にいくつのパーツがあり、それぞれがどのように結合しているか” といった構造にまつわる事前知識は与えられていない」という前提があるため、楕円体で表した各パーツはあくまで物体を仮の方法で分解したものと言えます。
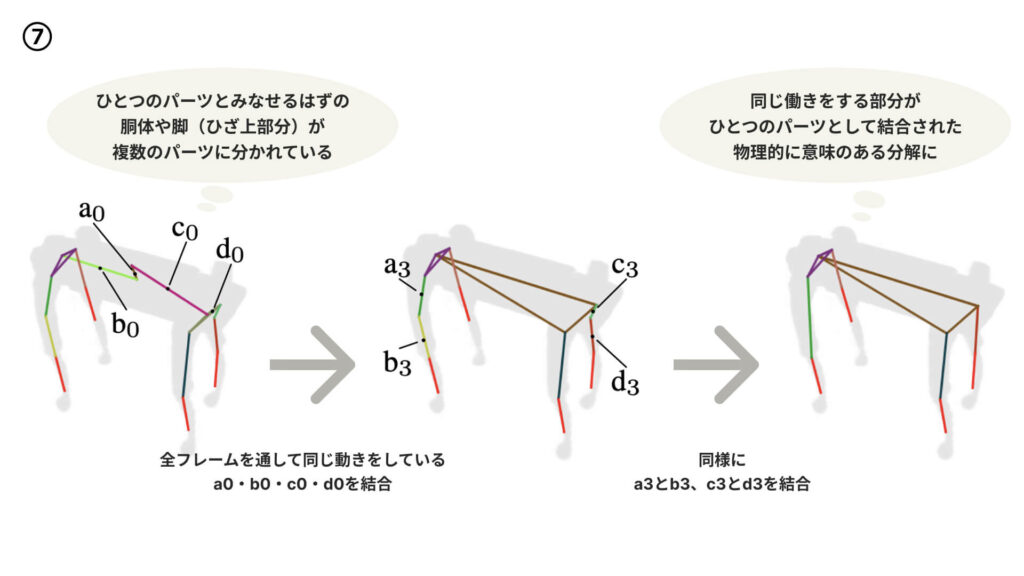
そこで、初めは細かめに物体を分解した状態で学習をスタート。そこから、姿勢推定器が推定した各時刻における各パーツの姿勢情報をふまえ、全フレームを通して互いに同じような動きをしているパーツどうしをひとつのパーツとみなして結合する、という過程を経ることで、物理的に意味のあるもっともらしいパーツの分解が得られる仕組みになっているのです(⑦)。
このようにしてもっともらしい物体の構造とパーツの分解が得られれば、関節の周りでパーツを回転させることで自由に物体の姿勢をコントロールできるようになります。
このような手法の提案により、「物体の姿勢を示す教師情報や構造にまつわる事前知識もない中での、自由な姿勢のコントロールが可能な3D表現の学習」を可能にし、従来手法の課題を改善しました。
また本手法には物体の構造にまつわる事前知識を必要としないため、人に限らずさまざまな構造の物体に適用できるというメリットがあります。

====
提案手法の有用性については、次のような方法で評価を行いました。(「どこに関節があるか」の正解が分かりやすい、人を例にとって実験を実施しています)
- モデルを訓練する際に用いたデータにはない、新たな視点からの見た目を本手法を用いて生成し、「その見た目がどれだけ あらかじめ用意した正解データと一致しているか」を定量的に評価
- 本手法によって推定された関節位置をもとに “正解の関節位置(=人の関節位置)”を推定するようなモデルを別途用意し、「そのモデルがどれだけ実際の人の関節位置に近い位置に関節を推定できているか」を定量的に評価
- 反対に、“正解の関節位置” をもとに “本手法を用いて推定された関節位置” を推定するようなモデルを用意。このモデルが推定した関節位置をふまえて新たな姿勢を生成し、「その姿勢における見た目がどれだけ正解データと一致しているか」を定量的に評価
まとめ
今回は、
- 姿勢を自由にコントロールできる3D表現を得る
- その際に必要となるデータ構築のコストを削減する
という目標に対し、これらを同時に実現する方法のひとつを提示しました。
これにより、姿勢を自由にコントロールできる3D表現の学習が教師情報や事前知識なしでできるように。より低コストで3Dモデル作成ができるという点で、VR・AR、ゲームといったコンテンツ制作などに貢献し得ると考えています。
| 【研究を振り返って】 明示的な3D表現はパーツの形状や結合関係を学習するのに適していますが、詳細な形状や見た目を表現できません。一方で、陰関数3D表現は詳細な形状や見た目を2Dデータから学習するのに適しているものの、パーツの形状や結合関係を推定するのは困難です。これらの手法を融合し、互いの短所をうまくカバーする方法を考えるのが特に難しかったと振り返ります。 |
参考文献
[1] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision (ECCV), 2020.
[2] Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-NeRF: Neural radiance fields for dynamic scenes. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[3] Atsuhiro Noguchi, Xiao Sun, Stephen Lin, and Tatsuya Harada. Neural articulated radiance field. In IEEE International Conference on Computer Vision (ICCV), 2021.