【論文紹介】画像中の物体についての“知識獲得”が可能な質問文生成の実現
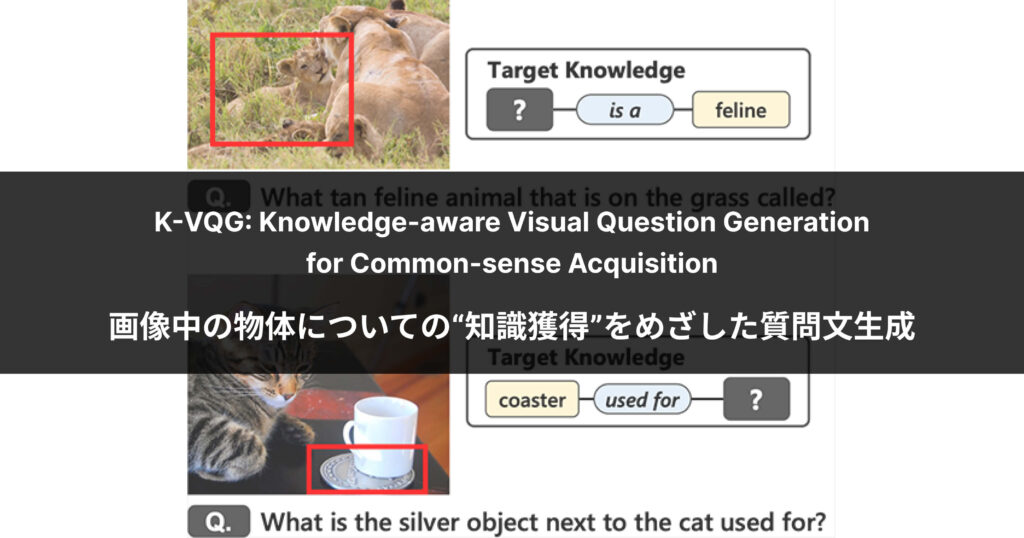
今回は、画像中の物体についての知識を獲得できるような質問文生成の実現に向け、モデルの提案を行った論文「K-VQG: Knowledge-aware Visual Question Generation for Common-sense Acquisition」について、著者の上原 康平が解説します。
研究背景
一般に、現在の画像認識は「人間がデータを与えて機械学習のモデルを学習させる」という、画像認識モデル側から見て “受動的” な形で行われています。
このような画像認識のあり方には、モデルの学習のために必要な情報をデータ一つひとつに付与する作業=アノテーションが必要で、多くの労力を要するという課題があります。さらに言えば、そもそも人間には「画像認識モデルが本当に必要としている知識とは何か」は分かりません。
これらをふまえ、機械学習のモデルの方から人間へ質問をすることで、「モデルが必要としている知識とは何か」を明確にしてそれに応えられるようになり、さらにアノテーションコストも削減できるのではないか、という考えからスタートしたのが本研究です。
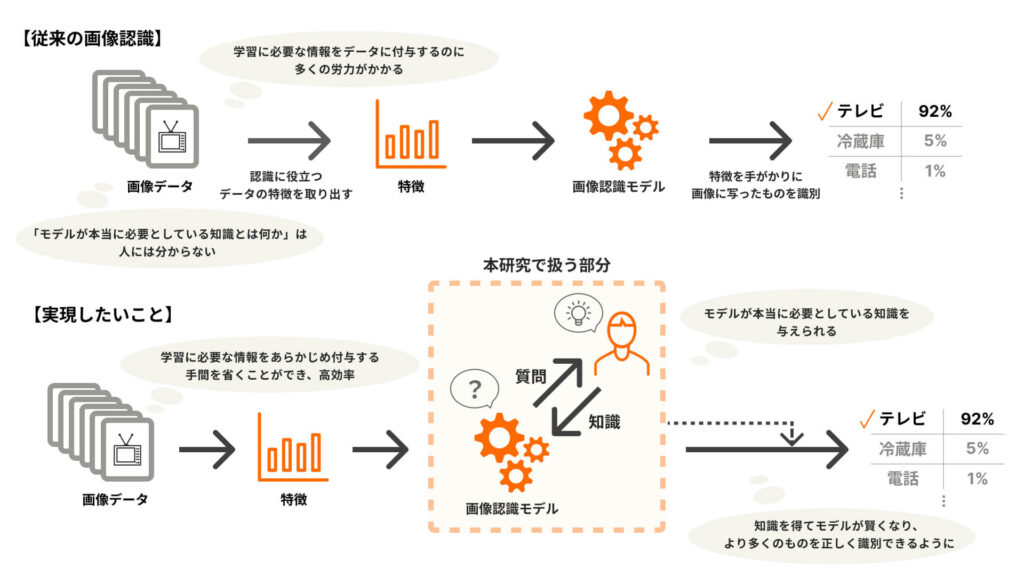
“分からないことを人に尋ねる” というのは、人間の子どもが成長していく過程で周りの大人に対して行っていることです。この学習の本質とも言える部分を人間に倣うことで、人に的確に質問を投げかけて賢くなっていくようなシステムを作れれば、というモチベーションで研究に臨んでいます。
これまでも、画像をもとにした質問文生成を扱う研究はさまざま行われてきました。
関連研究で用いられているのは基本的に、画像・質問・回答の3つからなるデータセット(データの集まり)で、これらのデータを使って「想定される回答」や別途用意された「回答カテゴリ」「回答タイプ」などの情報から質問文が生成されています。

【例1】では質問をするためにモデルがあらかじめ回答を知っている必要があり、“知識を獲得する” ことを動機とした質問文生成の条件設定としては不自然だと言えます。
また【例2】【例3】では、与えられた制約のもとで考え得る選択肢が多く、狙った知識が得られるように質問を細かくコントロールするのは容易ではありません。(例えば【例3】ではイスの数を尋ねる質問文を例に挙げていますが、「回答タイプ:数字」という制約のみでは、テーブルの数を尋ねても花瓶の数を尋ねてもよいことになります)
つまり、これまでの手法やデータセットでは、画像中の特定の物体に関する知識についてピンポイントで尋ね、回答からその知識を得られるような質問文の生成はできなかった、ということ。
こうした課題をふまえ、画像中の物体についての知識獲得に必要なデータセットの構築と、質問文生成モデルの提案を行ったのが今回の研究です。
方法と結果
今回構築した「K-VQG(※)データセット」と提案した「K-VQGモデル」について、それぞれ詳しくご紹介します。
※K-VQG:画像に関する質問を行う能力を機械に与えることを目的とした研究分野である「VQG(Visual Question Generation)」に、“知識の獲得(Knowledge-aware)” の要素を加えて本研究で提案した概念のこと
【用語】
- 知識トリプレット
→特定の物体に関する知識を単語またはフレーズの3つ組で表現したもの - 特徴
→モデルがデータを認識する手がかりとなる情報のこと - トランスフォーマー エンコーダー
→入力された画像や文章の特徴を統合する - トランスフォーマー デコーダー
→トランスフォーマー エンコーダーによって変換された特徴を、一定の規則に従って文章などの形式に変換する
まず、今回の目的である「画像中の特定の物体に関する知識についてピンポイントで尋ね、回答からその知識を得られるような質問文の生成」を実現するために、用いるデータセットには
- 画像
- 画像中の特定の物体に関する知識トリプレット
- 質問(画像に関するもので、かつ2.の知識トリプレットを獲得できるもの)
の3つを持つ、という条件を満たすことが求められます。これをふまえて、クラウドソーシング(※)を活用してワーカーに次のような形でタスクを依頼し、データセットの構築を行いました。
※クラウドソーシング:インターネット上で不特定多数の人に業務を発注する形態のこと。コストパフォーマンスの高さから、大規模なデータセットを構築するにあたって一般的にとられる手段のひとつとなっています。
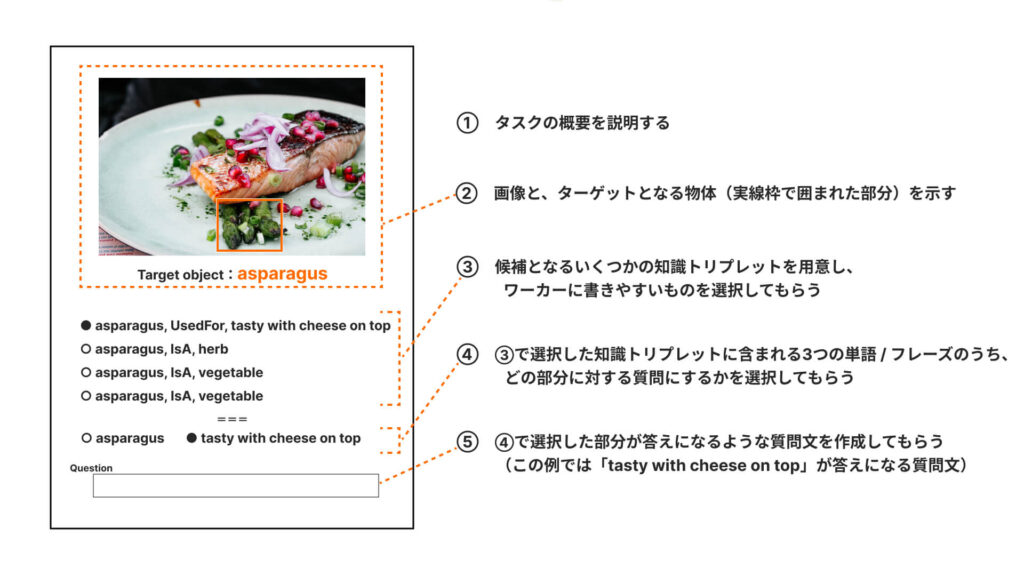
タスクでは「質問の対象となる物体は何か」をあらかじめ指定し、さらにその物体についての「どのような知識が答えになる質問にするか」を選択した上で質問を作成してもらっています。
これにより、単に “画像に写っている何らかの物体についての、何らかの質問” ではなく、“画像に写っている特定の物体についての知識を獲得できる質問” が含まれたデータセットとなっているのがK-VQGデータセットの最大の特徴です。
※データのクオリティを担保するために、「ワーカーによって作成された質問がタスクに対して適切か」を確認するタスク=バリデーションタスクも実施しました。クラウドソーシングで別途ワーカーを募集し、ひとつの質問につき約3名にクオリティの確認を依頼。全員の回答が否定的評価で一致した質問文については、データセットから除外しています。
====
データセット構築後、今度は実際にこのK-VQGデータセットを使って「ターゲットとなる知識を獲得できるような質問」を生成できるモデルの構築を行いました。
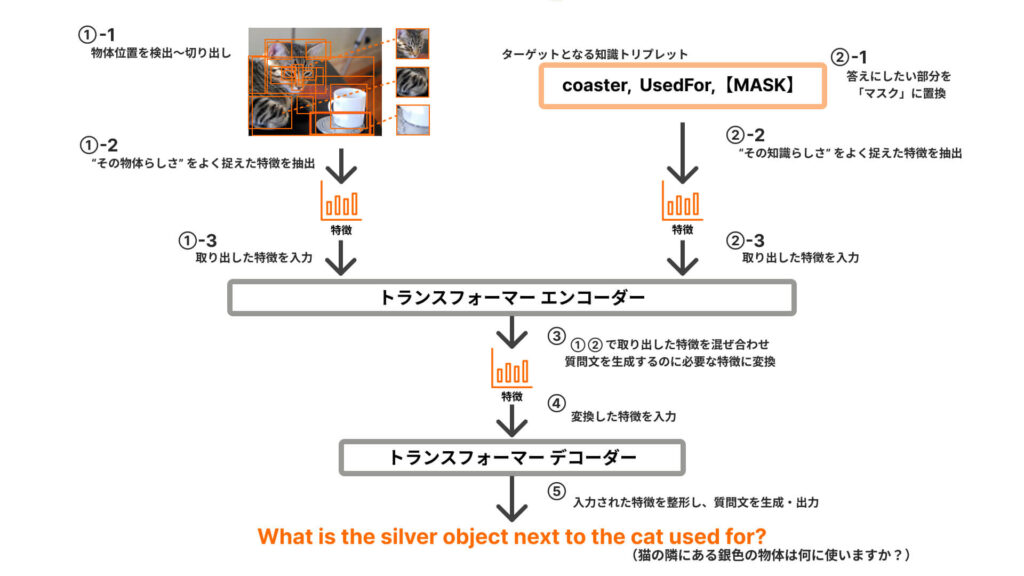
| ①-1 物体検出モデルを使って画像中の物体の位置を検出し、物体領域として切り出す ①-2 切り出した物体領域から、その物体らしさをよく捉えた特徴を取り出す ①-3 取り出した特徴をトランスフォーマー エンコーダーに入力する ②-1 ターゲットとなる知識トリプレットのうち、答えにしたい部分を「マスク」に置き換える ②-2 置き換えを行った知識トリプレットを文章と見なし、文章理解モデルを使ってこの文章らしさをよく捉えた特徴を取り出す ②-3 取り出した特徴をトランスフォーマー エンコーダーに入力する ③ トランスフォーマー エンコーダーが、①と②で取り出された画像と知識の特徴を混ぜ合わせ、質問文を作るのに必要な特徴に変換する ④ 変換された特徴をトランスフォーマー デコーダーに入力する ⑤ トランスフォーマー デコーダーが入力された特徴を整形し、質問文を生成・出力する |
与えられた画像と知識トリプレットにまつわる情報をそれぞれ理解し、その情報を組み合わせて質問を生成できるようにモデルの学習を行う、という流れになっています。
====
有用性の検証として、「K-VQGデータセットを使ってK-VQGモデルに画像とターゲットとなる知識トリプレットを与え、その知識について質問するような質問文を生成させる」という条件で実験を行いました。
①生成された質問文の品質を評価する指標と、②知識の一貫性を評価する指標(※)を用いて、定量的に評価を実施。生成される質問の質が高く、またその質問が望ましい知識を獲得できるものになっているという点で、従来手法と比べて提案手法が優れていることを示しました。
※生成された質問から「この質問はどのような知識をターゲットにしていたのか」を復元するモデルを作成し、復元された知識と、初めにモデルに与えられた知識が一致するかどうかを測ったもの。
まとめ
今回は、画像をもとにした質問文生成の研究における
- “質問によって知識を獲得する” という目的を果たせていない
- 質問の対象や内容を細かくコントロールできない
という課題の解決に向け、画像中の物体についての知識獲得に必要なデータセットの構築と質問文生成タスクのベンチマークモデルの提案を行いました。
これにより、“画像中の特定の物体に関する知識についてピンポイントで尋ね、その知識を獲得できるような質問文” の生成が可能になりました。
今後このK-VQGデータセットとK-VQGモデルを応用することで、“機械の質問に人が答え、その回答を得て機械が賢くなる” といった、人が組み込まれた機械の学習プロセス「Human-in-the-loop」などの発展にも貢献し得ると考えています。
| 【研究を振り返って】 データを集めるフェーズ、中でも特にクラウドソーシングにおけるクオリティコントロールが大変でした。 |