【論文紹介】ドメインギャップによる深層学習の性能低下を克服する

深層学習を応用した画像認識における課題のひとつとして、「ドメインギャップ」に起因する性能低下が挙げられます。
今回は、この課題を克服するための改善手法を提案した論文「Backprop Induced Feature Weighting for Adversarial Domain Adaptation with Iterative Label Distribution Alignment」について、著者のThomas Westfechtelが解説します。
研究背景
研究の出発点は、博士課程でロボットの研究をする中で直面した「深層学習を用いた画像認識の手法をロボットに適用すると、“画像認識の学習用データ(※)がつくられた環境” と “ロボットが活動する環境” にギャップがあるために認識の性能が下がってしまう」という課題でした。
※学習用データ:深層学習のモデルを訓練するために使うデータのこと
こうした環境のギャップ(ドメインギャップ)に起因する課題を解決するために行われるアプローチのひとつとして、どちらの環境でも有効な特徴(※)を見つけるというものがあります。(このような特徴をこの記事では【環境に対して不変な特徴】と表現します)
※特徴:AIがデータを認識する手がかりとなる情報のこと。AIによる画像認識では、例えばテレビの写った画像データの中から “テレビらしさ” をよく捉えた特徴を取り出すことで、効率よく「画像に写っているのはテレビだろう」と推測しています。
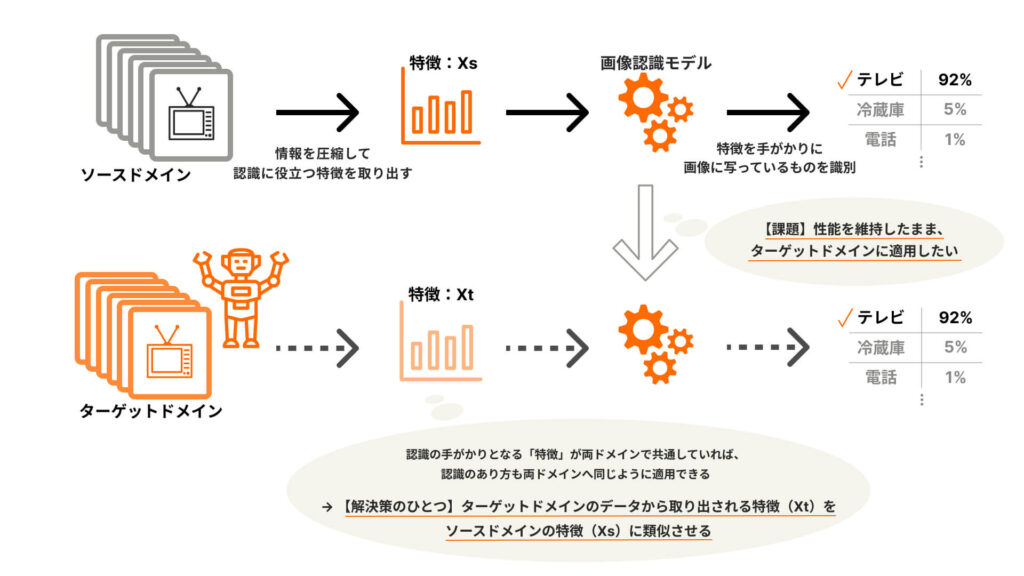
画像認識の学習用データの集まり(ソースドメイン)とロボットに「何が写っているか」を認識させたい画像データの集まり(ターゲットドメイン)のどちらにも有効な特徴を見つけられれば、その特徴を手がかりとする画像認識の方法も両ドメインに同じように適用できるようになる……つまり、ソースドメインをもとにつくられたモデルを、性能を維持したままターゲットドメインでも活用できるようになるだろう、という考え方です。
ただ、この「【環境に対して不変な特徴】を見つけることで環境のギャップを克服する」というアプローチにおいても、性能面の課題が残されています。
従来の手法では画像データ全体から【環境に対して不変な特徴】を探しているため、画像に写ったものを識別する際に特に重要になる局所的な特徴だけでなく、背景など大域的な特徴にまで注目してしまう状態に。これによって識別の精度が下がってしまうのです。
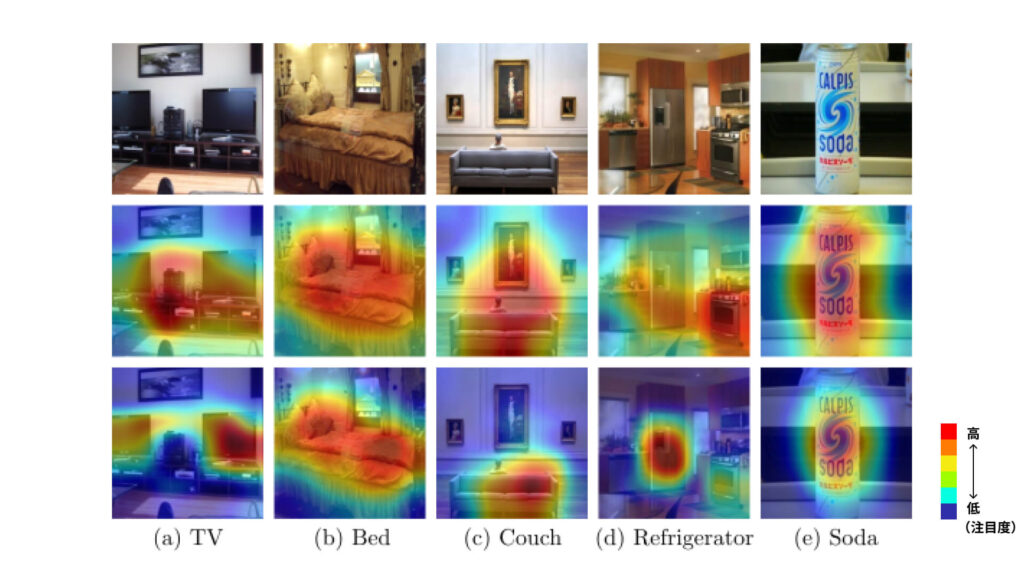
この課題を受け、画像データの中で識別に重要な特徴に注目できるように改善手法を提案したのが今回の研究です。
方法と結果
今回提案した手法を、従来の手法と比較してご説明します。
【用語】
- 特徴抽出器
→与えられた画像データから、識別に役立つ情報=特徴を取り出す
- ドメイン識別器
→取り出された特徴をもとに「このデータはソースとターゲット、どちらのドメインから来たものか」とドメインを識別する
- カテゴリ分類器
→「この画像に写っているのは何か」を識別(テレビ、ベッド、ソファ…といったカテゴリ=クラスごとに分類)する
【従来の手法】
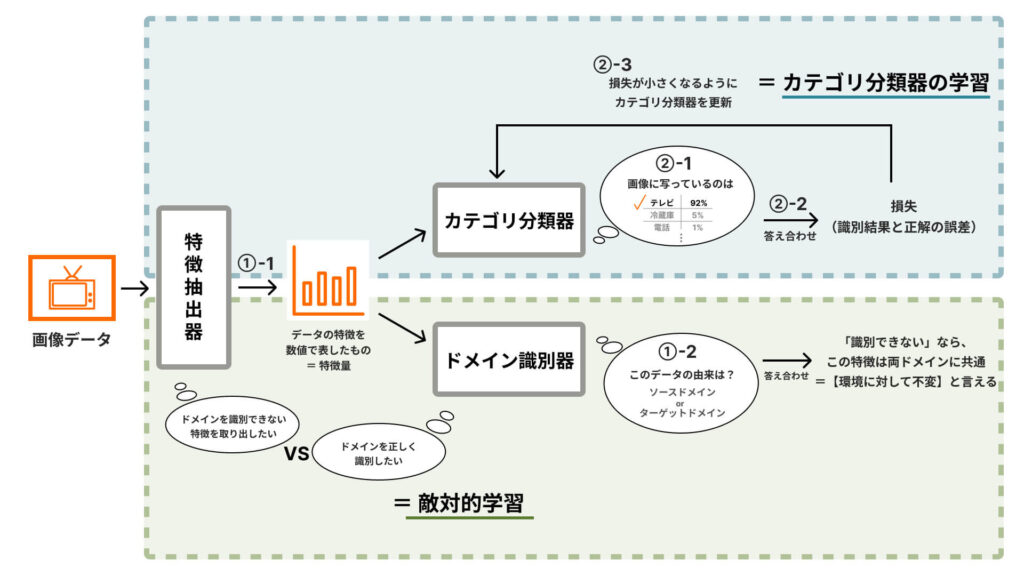
| ①-1 特徴抽出器が、画像データから特徴を抽出する ①-2 抽出した特徴を手がかりに、ドメイン識別器が「このデータがどちらのドメインから来ているものか」を識別する |
①(図のグリーン部分)では、ドメイン識別器は「特徴をもとにドメインを正しく識別できるように」、特徴抽出器は「ドメイン識別器がドメインを識別できないような特徴を取り出せるように」、それぞれ学習します。
この二つを競わせて学習を進める(=敵対的学習)ことで、特徴抽出器はドメイン識別器がドメインを識別できないような特徴、つまり両ドメインに共通する特徴を抽出できるようになります。
| ②-1 ①-1で抽出した特徴を手がかりに、カテゴリ分類器が画像に写っているものを識別する ②-2 損失(カテゴリ分類器による識別結果と正解値との誤差)を計算する ②-3 損失が小さくなるように、カテゴリ分類器を更新(関数の係数部分を調整)する |
②(図のブルー部分)では、カテゴリ分類器による識別の結果をふまえ、できる限り損失が小さくなるようにカテゴリ分類器を更新します。これを繰り返すことで、カテゴリ分類器は画像に写っているものをより精度高く識別できるようになっていきます。
従来の手法では、このように「ドメイン識別器と特徴抽出器による敵対的学習」と「カテゴリ分類器の学習」とが別々に行われていました。
【提案手法】
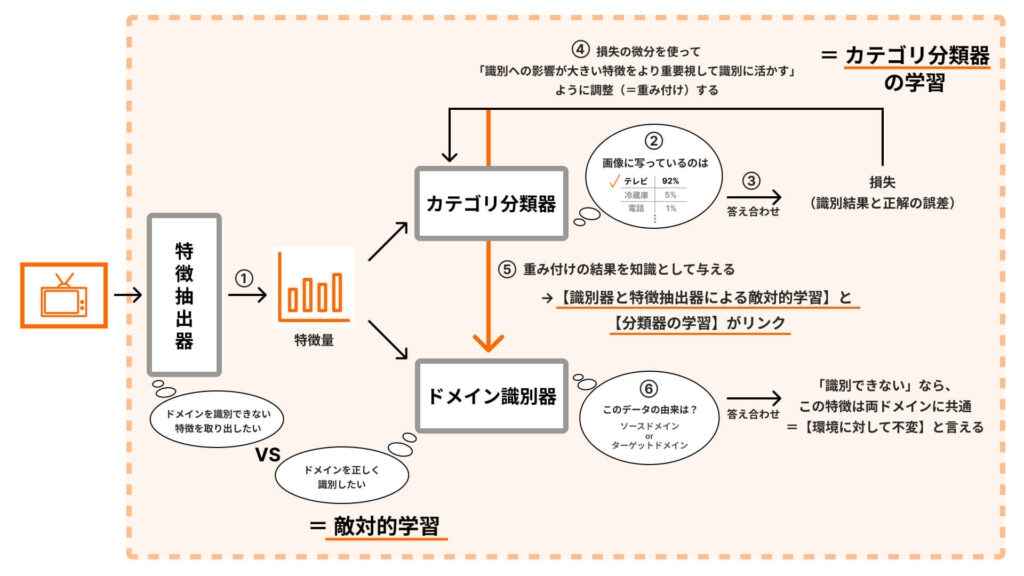
| ① 特徴抽出器が画像データから特徴を抽出する ② 抽出した特徴を手がかりに、カテゴリ分類器が画像に写っているものを識別する ③ 損失を計算する ④ 損失の微分を計算し、その結果をふまえて「各特徴をどのくらい重要視して識別の参考にするか=特徴量の “重み”」を調整(=重み付け)する ⑤ 重み付けの結果を知識としてドメイン識別器に与える ⑥ ⑤の知識をふまえて、特徴をもとにドメイン識別器が画像データのドメインを識別する |
提案手法では、「ドメイン識別器と特徴抽出器による敵対的学習」と「カテゴリ分類器の学習」とを別々に行わず、密接にリンクさせています。
まず従来手法と同様に、カテゴリ分類器が画像データから抽出した特徴を手がかりに画像に写っているものを識別し(①②)、その結果と正解値との誤差である損失を計算(③)した後に、提案手法では損失の微分を計算します(④)。
損失の微分を求めることは、「どの特徴が・どのくらい影響を与えた結果、この損失が生まれたか」を明らかにすることを意味します。
この微分の計算結果から識別に与える影響が大きい特徴を見つけ出して「この特徴をより重視して識別を行うべき」と各特徴量の重みを調整し、この重み付けの結果を次の識別に活かす(④)ことで、カテゴリ分類器は画像に写っているものをより精度高く識別できるようになっていくのです。
さらに、この重み付けの結果をドメイン識別器と特徴抽出器による敵対的学習に紐づける(⑤)ことで、識別への影響が大きい重要な特徴の中から【環境に対して不変な特徴】を見つけられるようになります。
つまり、【環境に対して不変な特徴】を見つける作業に「中でも重視すべき特徴はどれか」という観点を反映できるようになるということ。これによって、背景などの大域的な特徴に注目してしまい認識の精度が下がるという課題を解決できるのです。
====
ここでもう一つ、「データの分布」にも注意しなければなりません。
カテゴリ分類器の学習のもととなるデータには「テレビの画像は100枚くらいあるけれど、飛行機は10枚ほどしかない」というように、クラスごとにサンプル数の分布に偏りがあるのが一般的です。こういった偏りがあると、サンプルが多いもの(この例ではテレビ)をしっかりと分類することにばかりフォーカスがあたり、サンプルが少ないもの(この例では飛行機)がうまく識別できなくなってしまうことが懸念されます。つまり、識別の正確性が担保しづらくなってしまうのです。
識別精度の低下を防ぐには、学習する際に、分類したいクラスごとに同じ量のサンプルを取ることが望ましいと言えるでしょう。
しかし、クラスごとにサンプルを取るとなると、ターゲットドメインのデータ一つひとつに「この画像に写っているのは車である」といった正解を示す情報=ラベルが付けられている必要があります。つまり、ラベルが付けられた大規模なデータセット(データの集まり)を用意することが難しい場合には、「クラスごとに同じ数のサンプルを取る」ことが叶わないのです。
そこで今回採用したのが、ラベルなしのデータセットにおいてクラスのバランスを取るために「擬似ラベル」を使う方法です。
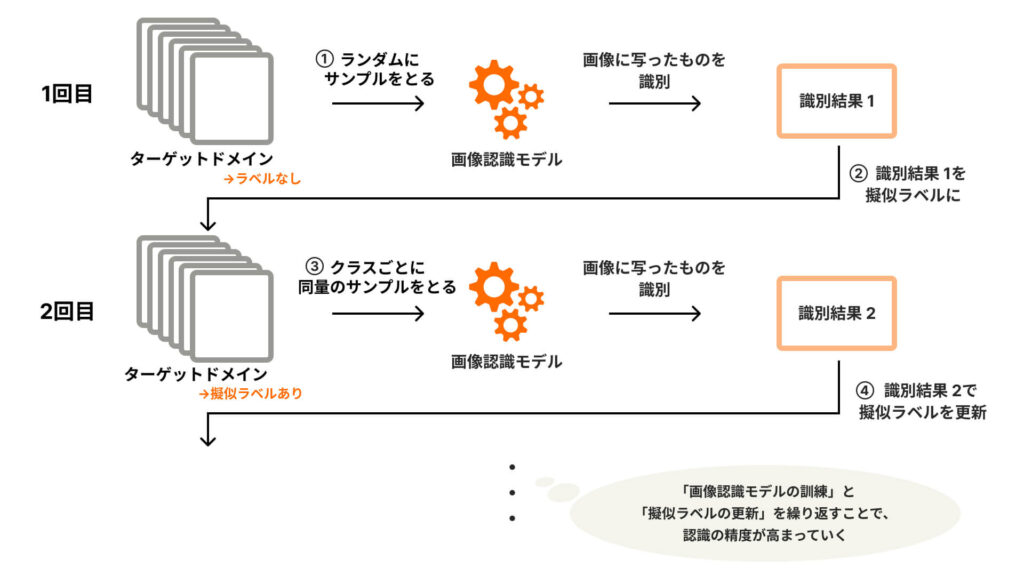
| ① ターゲットドメインからランダムにサンプルをとってモデルを学習させる ② 「この写真に写っているのは〇〇だ」という識別結果を擬似ラベルとする ③ 擬似ラベルをもとに、クラスごとに同じ数のサンプルをとってモデルをもう一度学習させる ④ 2回目の識別結果を用いて擬似ラベルを更新する ⑤ 更新された擬似ラベルをもとに、クラスごとに同じ数のサンプルをとってさらにもう一度学習する (以下、識別結果による擬似ラベルの更新と、擬似ラベルを活用した学習の繰り返し) |
学習のたびにその結果をもとに擬似ラベルを更新し、また次の学習を行う…という過程を何度も繰り返すことで、「画像認識のモデルの訓練」と「擬似ラベルの更新」の相乗効果によって識別の精度が高まっていくと考えられています。
====
「ドメイン識別器と特徴抽出器による敵対的学習」と「カテゴリ分類器の学習」をリンクさせること、そして識別結果を擬似ラベルとして用いて反復的な学習を行わせること。
この2つの提案手法について、ドメイン適応の研究でよく用いられるOffice-31・OfficeHome・DomainNetという3つのオンラインデータセットを利用して実験を実施。アブレーション(提案するモデルを構成する要素のうち一部を取り除いて実験を行い、結果から各要素あり・なしの場合の性能を比べること)を行って有効性を示しました。
まとめ
今回はドメイン適応の課題に対し、
- 画像データの中で特に重要な特徴に注目して識別を行うために、「ドメイン識別器と特徴抽出器による敵対的学習」と「カテゴリ分類器の学習」をリンクさせることが重要であること
- 精度高い認識のためにはドメイン内のクラスのバランスにも注目し、その偏りの影響を克服する必要があること
を示し、それぞれに対する解決方法の一つを提示しました。
これにより、ドメインのギャップを克服して精度の高い画像認識が行えるように。また擬似ラベルを用いることで、ラベル付きの大規模なデータセットを用意しなくとも学習が行えるため、限られたリソース下での研究に貢献し得ると考えています。
| 【研究を振り返って】 最終的には環境に対して不変(=二つのドメインに共通して有効)な特徴を利用する方法を取ることになりましたが、実はこの研究は「各ドメインの “特徴的な特徴” を利用したい」というところからスタートしたものでした。例えば一方のドメインの画像データが白黒、もう一方のドメインの画像データがカラーの場合……両ドメインに共通していなくとも「色」という重要な特徴があるならば、これも識別に利用したいという考えです。 しかしこの方法では学習がうまくいかず、さまざまなアイディアを試す中で今回の方法にたどり着きました。この試行錯誤の過程が一番大変だったなと振り返ります。 これまでも深層学習はツールとして活用してきたものの、メインテーマとして研究したのは今回が初めてで、とても勉強になりました |