大規模言語モデル分散学習ハッカソンに参加してきました!

文責:田中康太郎
最近ChatGPTやBardに代表される大規模言語モデル(Large Language Model; LLM)が注目を集めています。これらのモデルは高い自然言語処理能力を持っており、様々な分野での応用が検討されています。一方で、LLMを訓練するためには大量の計算リソースを必要とし、データパラレル、モデルパラレルといった分散学習やハイパーパラメータのチューニングが必要となります。LLMの学習に必要な技術的知見を蓄えるため、国立研究開発法人産業技術総合研究所が提供するスーパーコンピューター、ABCIを活用した第1回大規模言語モデル分散学習ハッカソン(https://abci.ai/event/2023/06/13/ja_event.html)に日髙雅俊、橋本智洋、田中康太郎が参加しました。本ブログでは田中康太郎がハッカソンでの取り組みとLLMの学習に必要な技術的知見を紹介いたします。
今回はLLMをスクラッチからマルチノードで効率的に学習する方法を学ぶことを目標にし、3人のメンバーがそれぞれ異なるライブラリを用いて検証を行いました。
TransformersとDeepSpeedを用いたOPT [Zhang et al., 2022]の学習
OPTはMeta社が公開しているオープンソースのLLMで、パラメータ数が1億2500万 (125m)の比較的小さなものから、GPT-3[Brown et al., 2020]と同等の1750億 (175b)のモデルまで公開されています。本ハッカソンではVRAM16GBのV100を利用しましたが、パラメータ数の多いモデルを学習しようとすると、工夫なしではVRAMの容量が足りません。そこで、DeepSpeed(https://github.com/microsoft/DeepSpeed)というMicrosoft社が提供しているライブラリを用いました。このライブラリにはZeRO [Rajbhandari et al., 2020]と呼ばれるメモリ効率化手法が実装されており、パラメータ数の多いモデルの学習を可能にしています。手法の詳細はこのブログで紹介されています(https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)。検証ではZeRO stage 3を利用しました。
本セクションでは以下の3点について紹介します。
- 大容量データの符号化処理の難しさ
- マルチGPU, マルチノードによる学習のスケール化
- OPT125mと350mの学習結果とチューニング方法
大容量データの符号化処理の難しさ
言語モデルを学習するためにはまず文字データを符号化する必要があります。今回はGPT-2 [Radford et al., 2018]で用いられたバイト対符号化(Byte-Pair Encoding; BPE)を行いました。符号化処理には以下の2つのアプローチが考えられます。
- 訓練前に全てのデータに対して符号化を行うアプローチ
- 訓練時にバッチ単位で符号化を行うアプローチ
訓練前に符号化を行えば訓練時のCPU処理を少なくすることができ、訓練を高速化できます。一方で、訓練データが大規模の場合、CPUメモリにのらずプロセスが止まる場合がある上、符号化の間GPUが有効活用できないという問題があります。
今回BookCorpus [Zhu et al., 2015]など約120GBのデータセットで訓練しようとしたところ、訓練前に符号化するアプローチではメモリ不足によりプロセスを完了することができず、6GBまで減らしても符号化に6時間(マルチスレッド、シングルプロセス)かかりました。ABCIのような時間課金制度の場合、符号化処理の間GPUが動いていないにも関わらず高額の課金がされてしまうという問題があるため、符号化はCPU処理で事前に行った上で、結果をキャッシュとして保存し、訓練時はそのキャッシュをロードする形をとりました。 一方、訓練時にバッチ単位で符号化を行うアプローチを試すために、Huggingfaceのdataset streaming (https://huggingface.co/docs/datasets/stream)を利用しました。dataset splitを自動で作成する機能がないことや、訓練パラメータとしてステップ数を指定しなければいけないなどの制限はある一方、符号化処理やグルーピング処理を待つ必要がなくなります。DeepSpeedなしの場合ではstreamingを用いた訓練ができた一方、DeepSpeedと組み合わせるとGPU使用率が100%にも関わらずGPU温度や電力消費量があがらず、学習も始まらなくなり、うまく行きませんでした。
マルチGPU、マルチノードによる学習のスケール化
訓練に使うGPU数を上げた時に訓練速度や性能に影響があるかを調べるため、OPT-125mをwikitextデータセット[Merity et al., 2016]で3エポック訓練するタスクを以下の条件で比較しました。
- 1 GPU (DeepSpeedなし)
- 1 ノード(4 GPU, DeepSpeedなし)
- 1 ノード+DS(4 GPU)
- 2 ノード+DS(8 GPU)
- 4 ノード+DS(16 GPU)
- 16 ノード+DS(64 GPU)
1ノードでDeepSpeedを用いない場合はOut of memoryとなりました。その他の条件の結果は図1の通りです。

結果からノード数を増やすと、ノード数に比例して訓練速度が上がることがわかりました。一方で1 GPUから1 ノード(GPU数4倍)に増やしても、訓練速度は4倍にはなりませんでした。この原因について詳しく特定することはできませんでしたが、ZeRO stage 3はメモリ使用が効率的な反面、訓練速度が落ちることがハッカソンの他チームの発表で報告されていました。
OPT125mと350mの学習結果とチューニング方法
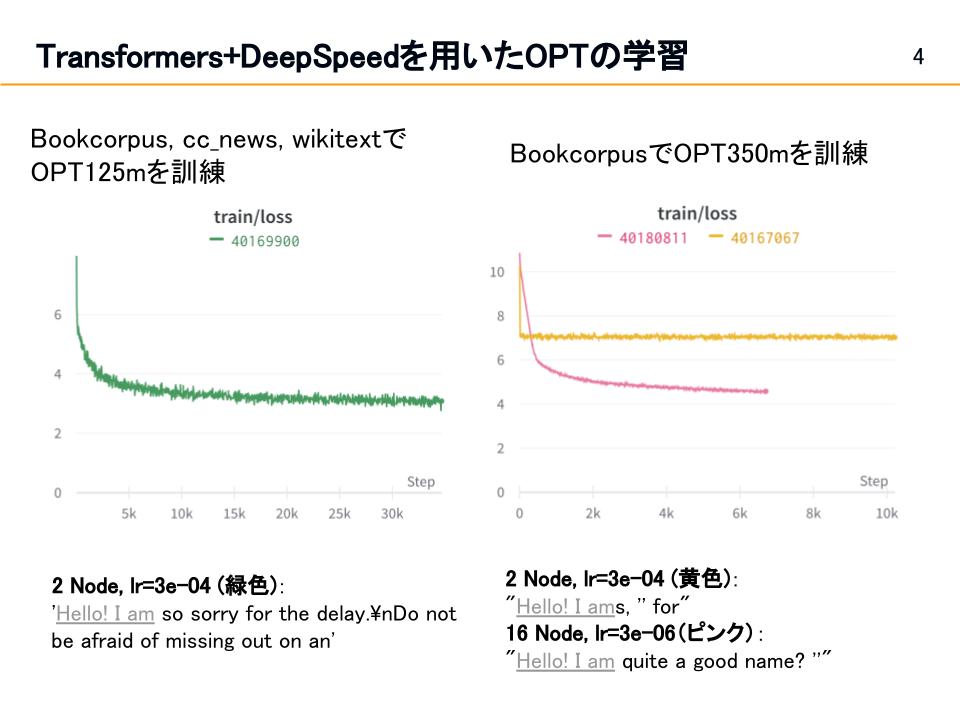
BookCorpus, CC News, WikiTextのデータセットを結合しOPT125mで訓練を行いました(図2の左)。ハイパーパラメータは基本的にOPTの論文に従いましたが、バッチサイズはメモリ削減のため2としました。24時間訓練をしたところ、訓練の損失は約3まで下がりました。訓練したモデルに”Hello! I am”の続きを生成させたところ、”Hello! I am sorry for the delay”のように文脈にあった、文法的に正しい文章が生成されました。
OPT350mはBookCorpusを用いて訓練しました。はじめ、2ノード、lr=3e-04の条件で訓練したところ、図2の右の黄色線のように訓練損失が7あたりから下がらなくなり、生成結果も”Hello! I ams, for”のように英語の頻出単語をランダムに並べたようなものになりました。そこで、学習を安定させるためにlrを3e-06まで下げ、ノード数を16ノードまで増やした(バッチサイズを上げることと同等)ところ損失は4程度まで下がり、生成結果も”Hello! I am quite a good name?”のように英語らしい文章となりました。
Megatron-LMを用いたGPT-3 [Brown et al., 2020]の学習
VRAMにモデルがのりきらない場合の対処法として、ZeRO以外にパイプライン並列やテンソル並列があります。パイプライン並列やテンソル並列について詳しくはこのサイトで紹介されています。(https://huggingface.co/docs/transformers/v4.17.0/en/parallelism)
パイプライン並列やテンソル並列はHuggingfaceを含めた多くのライブラリに実装されていませんが、NVIDIA社が公開しているMegatron-LM(https://github.com/NVIDIA/Megatron-LM)に実装が公開されているため、こちらを利用しました。
パイプライン並列やテンソル並列を用いる場合、分割方法に関するパラメータが発生し、最適なパラメータを探索する必要があります。そこで、本セクションではパイプライン並列やテンソル並列を用いた学習において、分割方法に関するハイパーパラメータと学習速度の関係を確認する実験の結果を紹介します。

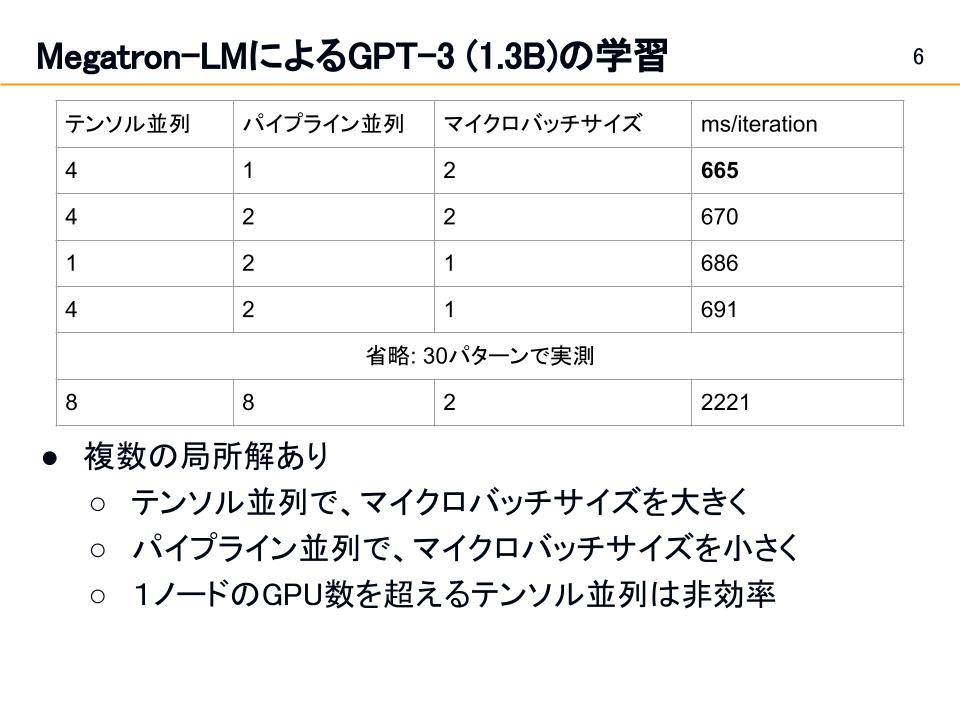
実験ではGPT-3 (1.3B)を図3の環境で訓練し、テンソル並列、パイプライン並列、マイクロバッチサイズのハイパーパラメータを変更し、最適なパラメータ探索を行いました。結果は図4の通りで、簡単な数式で求まる最適解は残念ながら見つからなかった一方、テンソル並列ではマイクロバッチサイズを大きくしたり、パイプライン並列ではマイクロバッチサイズを小さくしたりといった局所的な最適解は見られました。実験の結果、最速の設定と下手な設定では訓練速度に3倍以上の差が見られたため、長時間訓練する際は事前にチューニングを行う必要性があることがわかりました。
Megatron-DeepSpeedを用いたGPT-3の学習
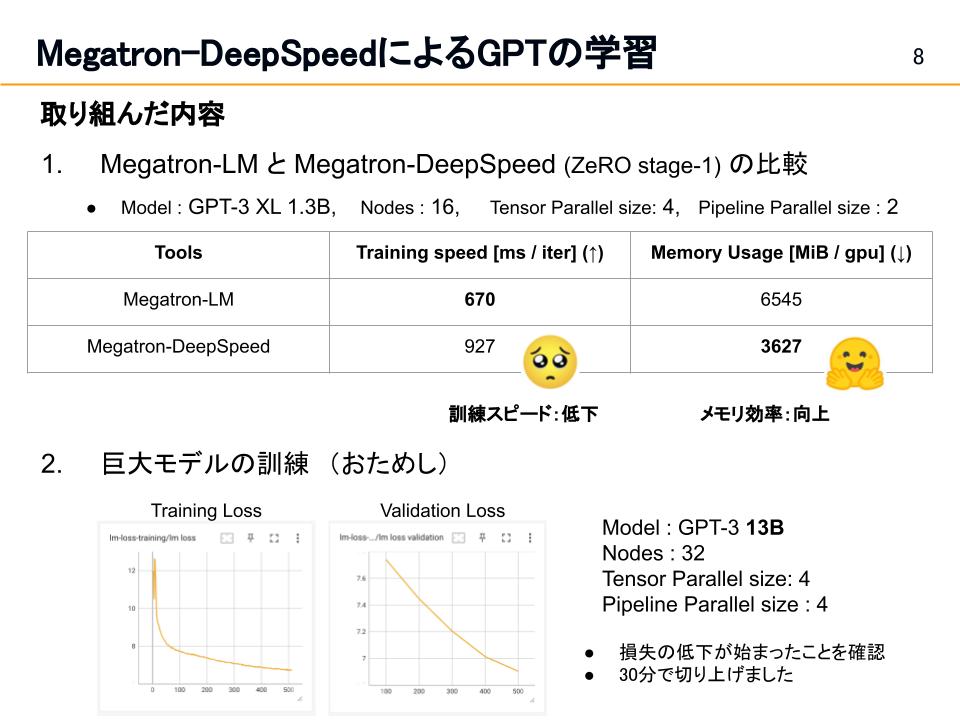
Megatron-LMをDeepSpeedと併用することで、マルチノードのGPUをメモリ効率よく用いて、大きなモデルを訓練を可能にするライブラリがMicrosoft社から公開されています。(https://github.com/microsoft/Megatron-DeepSpeed)本章ではこのライブラリを用いたGPT-3 13Bの訓練動作確認とMegatron-LMとの比較について紹介します。
Megatron-LMとMegatron-DeepSpeed (ZeRO stage-1)を用いたGPT-3 13Bの訓練を比較すると、図5のように、訓練速度は低下した一方、メモリ効率が向上しました。パラメータ数の大きなモデルを訓練する場合、多くのGPUがある場合はMegatron-LMのパイプライン並列やテンソル並列で十分ですが、GPU数に限りがある場合はCPU offloadingなどのメモリ効率化が実装されているDeepSpeedと併用することが有効であると考えられます。
おわりに
本ハッカソンでは一週間以上に渡ってABCIを無償で利用させていただき、大規模モデルの訓練に関する技術的知見を得ることができました。期間中はチューターの方々による手厚いサポートに加えて、他の参加者の方からもアドバイスや知見をいただきました。誠にありがとうございます。