【論文紹介】オンライン強化学習においてベルマン誤差の歪みを補正するQ学習
近年、深層強化学習の分野では、歪んだ誤差分布が学習に悪影響を及ぼすことが指摘されています。その問題に取り組み、新しい手法を提案した論文「Symmetric Q-learning: Reducing Skewness of Bellman Error in Online Reinforcement Learning」について著者の大村が解説します。詳細は論文(https://arxiv.org/abs/2403.07704)をご覧ください。
研究背景
深層強化学習(RL)は、AI の分野における革新的な進展の一つとして、自動運転車、ロボット工学、医療、金融など、さまざまなアプリケーションでの自律的な意思決定プロセスに貢献してきました。特に、自動化された制御システムや複雑な戦略を要するゲームの領域では、RLは人間を超える性能を示し、多くの注目を集めています。しかし、RL技術の背後には、まだ克服されていない多くの技術的な課題が存在します。
強化学習の基本的な構成要素である価値関数の推定は、学習プロセスにおいて極めて重要な役割を果たします。価値関数を通じて、エージェントは与えられた状態や選択した行動の質を評価し、最適な戦略を学習することができます。この価値関数の学習には一般に、最小二乗法が使用されますが、この方法は最尤法を通して、誤差が正規分布に従うということを仮定しています。しかしながら、最近の研究 [1] では、実際にはRLの学習過程における誤差分布が正規分布から逸脱し、歪んでいることがしばしばあり、この現象が学習効率の低下やパフォーマンスの悪化に繋がりうることを指摘しています。そこで我々の研究では、この誤差分布の歪みに対して取り組みました。
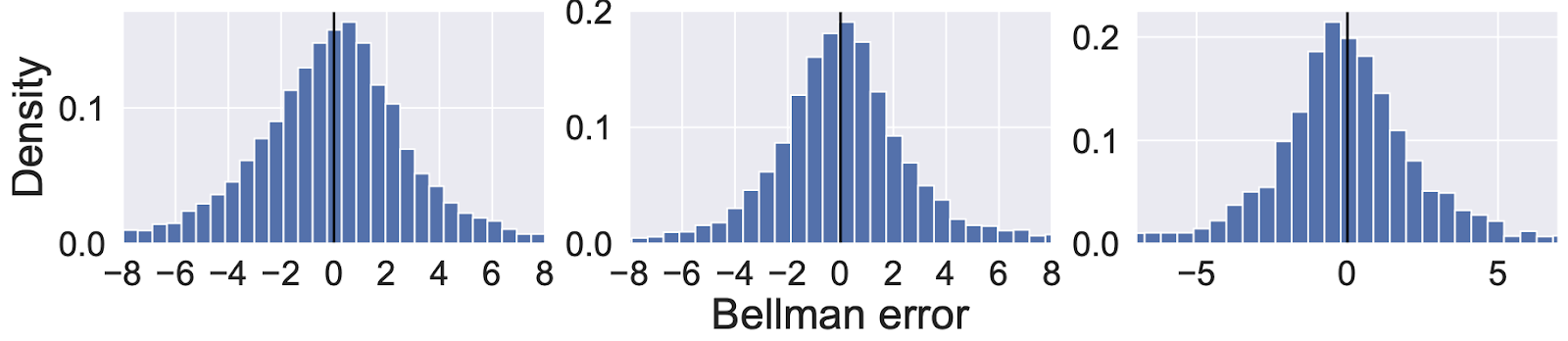
方法と結果
この問題に対処するため、我々の研究では、誤差にノイズを加えることによって、任意の誤差分布の歪みを効果的に減少させる新たなアプローチ(Symmetric Q-learning)を提案します。
この手法では、ノイズを加えることで誤差分布の歪みを正し、より正規分布に近い形へと調整します。誤差に加えるノイズの分布を、実際の誤差分布を反転させた分布となるように学習します。そして、そのノイズ分布からサンプルされたノイズを、元の誤差に足し合わせることで、ノイズを足された後の誤差は対称な分布となります。
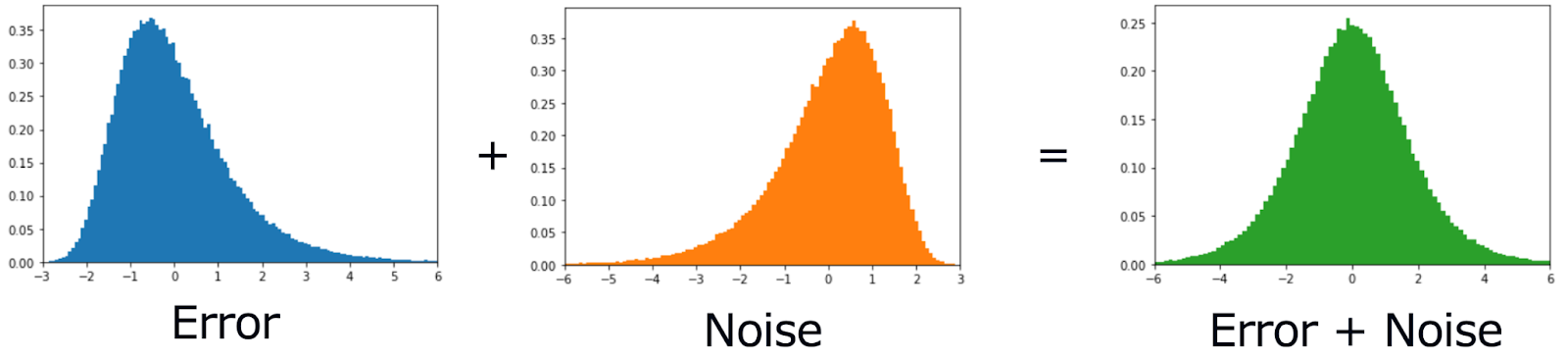
そして、その値に対して最小二乗法を用いることで、誤差分布が正規分布に従うという仮定により適した推定ができるようになります。それにより価値関数の学習が、より実際のデータに即した形で行われるようになり、正確な推定が期待されます。
実用的なアルゴリズムでは、混合正規分布(GMM)を用いてノイズの分布を近似します。GMMのパラメータは、負の誤差に対する尤度を最大化することで推定されます。このノイズ分布の推定と、ノイズを用いた価値関数の学習を繰り返していくことで、RLアルゴリズムの性能の向上を目指します。細かい工夫として、ノイズ分布の平均が0になるように都度調整することで、価値関数の推定にバイアスが加えられないようにしています。
我々の提案する手法の有効性を検証するために、Randomized Ensemble Double Q-learning(REDQ)[2] という最先端の深層RLアルゴリズムと組み合わせた評価が行われました。実験は、物理シミュレーションプラットフォームMuJoCo上での複数のタスクを用いて実施され、提案手法がこれらの環境において、従来手法と比較して同等、またはそれ以上のサンプル効率を達成できたことが確認されました。これらの結果は、RLにおける最小二乗法の利用に関連する問題を解決し、より高性能な学習アルゴリズムの開発に貢献する可能性を示しています。

まとめ
本研究では、深層強化学習の誤差分布の歪みを修正する新手法「Symmetric Q-learning」を提案しました。この手法はノイズの追加により誤差分布を仮定されている形に近づけ、サンプル効率の向上を実現しました。
我々の研究成果は、人工知能分野で権威ある国際学会 AAAI 2024 (The 38th Annual AAAI Conference on Artificial Intelligence) で発表されました。この場で他の研究者たちとの貴重な意見交換を行うことができたため、得られたフィードバックを基に、我々の研究アプローチをさらに洗練させていきます。

