【論文紹介】低光補正と露出補正をしつつ3次元画像を生成する研究
本記事では,AI分野のトップ学会の一つであるAAAIに採択された本研究室博士課程学生のCuiさんの論文「Aleth-NeRF: Illumination Adaptive NeRF with Concealing Field Assumption」について紹介します.
論文リンク: https://arxiv.org/pdf/2312.09093.pdf
コードリンク: https://github.com/cuiziteng/Aleth-NeRF
ウェブサイトリンク: https://cuiziteng.github.io/Aleth_NeRF_web/
本論文では、不良な照明条件(例:低照度および過度な露光)で撮影された画像を用い、教師なしで補正しつつNeRFを使用することで、正常な照明での連続した3Dシーンを生成することを目指しています。
提案手法の概要
この論文では、Aleth-NeRFモデルを提案し、教師なしの低光照補正、過曝光補正、および新しい視点の合成を実現します。提案手法の名前は,古代ギリシャの視覚的な観点に着想を得ています。ギリシャ人は夜に物体が見えないのは空気中に障害があるためだと考えました。女神Aletheiaは真実/隠蔽されていないことを象徴し、ギリシャ語で「真実」を意味し、これがAleth-NeRFの名前の由来です。この着想から、提案手法ではNeRFモデルにConcealing Fields(隠蔽フィールド)の概念を導入し、voxel-wiseの局所隠蔽フィールドとglobal-wiseの全体的な隠蔽フィールドに分かれます。
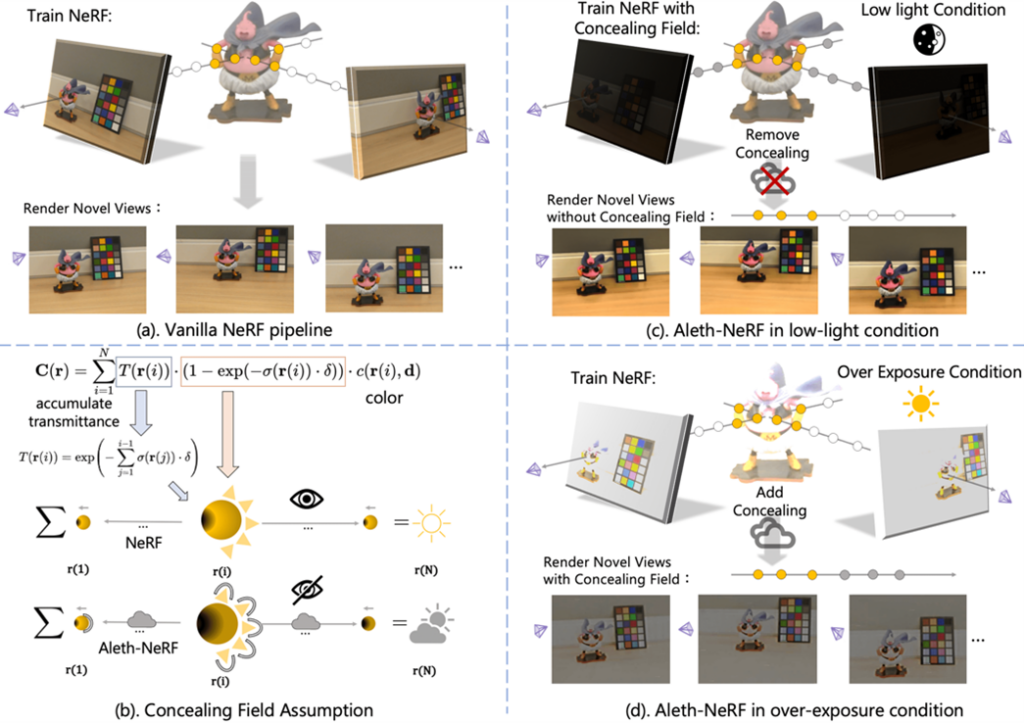
低光照シナリオのモデルの訓練は、上記の図(c)に示されています。訓練段階では、隠蔽フィールドがNeRFのボリュームレンダリングに組み込まれ、低光照シーンの訓練に利用されます。テスト段階では、隠蔽フィールドは取り除かれ、通常の照明でシーンをレンダリングします。過曝光シナリオのトレーニングは、上記の図(d)に示されています。訓練段階は通常通りですが、テスト段階では隠蔽フィールドが追加され、通常の照明でシーンをレンダリングします。これらのシナリオに対して、NeRFネットワークおよび隠蔽フィールドに対してトレーニング段階で教師なしの損失関数を導入して、隠蔽フィールドの生成を制御します。
モデルの構造
局所な隠蔽場はNeRFのMLPネットワークによって生成され、元のNeRFの2つの出力(色と密度)と同じであり、voxel-wiseに属しています。一方、グローバルな隠蔽場は、各シーンで固定された学習可能なネットワークパラメータであり、global-wiseに属しています。これらの2つの隠蔽場は共同してVolume Renderingに組み込まれ、元のNeRFのVolume Renderingを減衰させます。Concealing Fieldの導入により、Volume Rendering内の各粒子は前の粒子による遮蔽作用が強化され、Concealing Fieldを使用して暗闇を表現します。同時に、訓練段階ではConcealing Fieldの生成を制約するためにさまざまな教師なし損失関数を追加し、不良な照明環境をより効果的に補正および修復するのに役立ちます。低光照シーンの訓練段階では、Concealing Fieldを導入したVolume Renderingの式を使用し、テスト段階ではConcealing Fieldを取り除いた元のVolume Renderingの式を使用します。一方、過曝シーンではその逆が行われます。
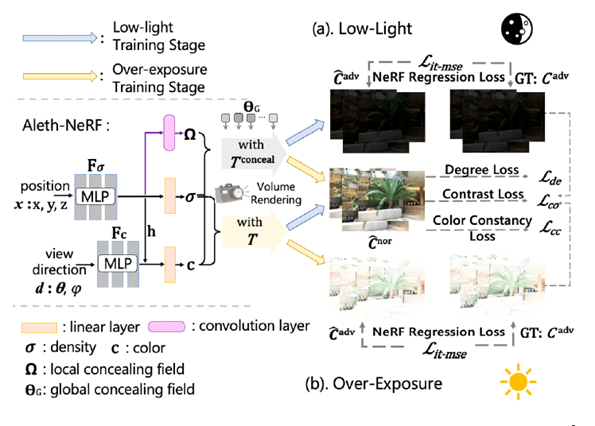
損失関数
Aleth-NeRFの教師なしの強化/過曝補正を確保するために、Concealing Fieldsの生成を制約するためにいくつかの追加の損失関数を導入しています。まず、NeRFの元々のMSE損失関数L_mseをL_it-mseに変換しています。つまり、MSE損失を計算する前に画像を反転Tone曲線を通すことです。なぜなら、元のMSE損失では暗いピクセルは通常重みが小さく、過曝ピクセルは通常重みが大きいため、最初に反転Tone曲線を追加することで、ある程度バランスをとることができるからです。残りの損失関数は三つの教師なしの損失関数で構成されており、それには全体の明るさ範囲(Enhance Degree)を制御する損失関数L_de、コントラスト(Contrast Degree)を制御する損失関数L_co、およびColor Constancy損失関数L_ccが含まれています。損失関数L_deと損失関数L_coのハイパーパラメータを調整することにより、異なる程度の強化を実現することも可能です。
データセット
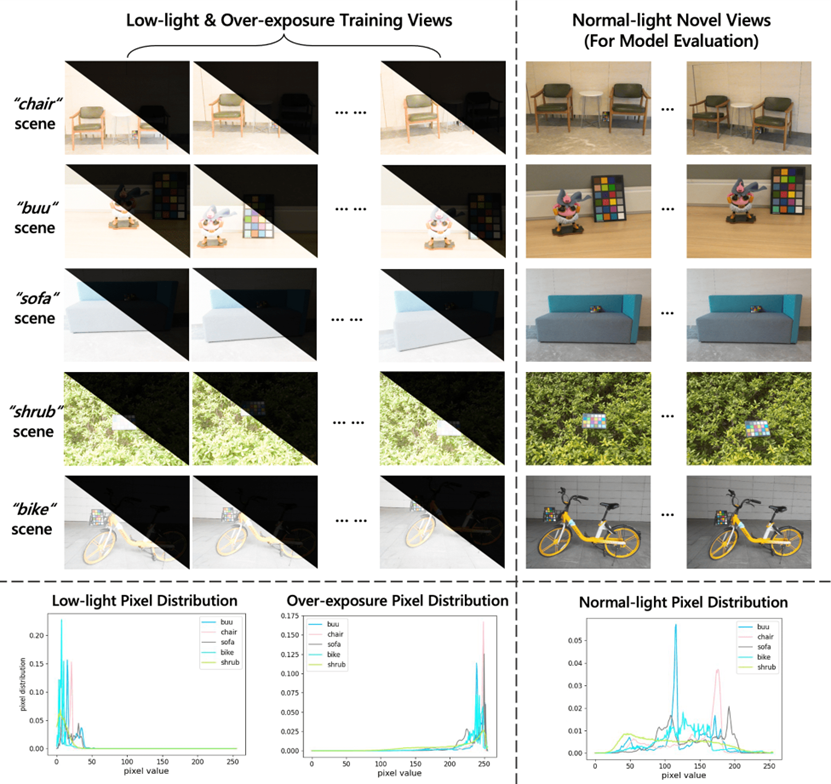
データセットに関して、私たちは低光照/過曝光/通常の光照のペアを持つマルチビューデータセット(LOMデータセット)を提案しました。提案手法では低光照および過曝光の画像をモデルのトレーニングに使用し、通常の光照の画像は新しい視点からの画像の生成の検証に使用します。2D画像の強化やビデオの強化とは異なり、このタスクはより難しいものとなります。なぜなら、画像の強化と同時に生成された画像のマルチビューの一貫性を確保する必要があるからです。データセットの画像は以下の通りで、5つの実世界のシーン(buu、chair、sofa、bike、shrub)をカメラで収集しました。各シーンには25〜65枚のマルチビュー画像が含まれ、各画像には3つの異なる露光条件(低光照/過曝光/通常の光照)があります。このデータセットはウェブサイトまたはGitHubからダウンロードできます。それぞれの露光条件に対応する画像の一例は以下の図の通りです。
実験結果
実験では、元のNeRFモデルをベースラインとし、2D画像/ビデオの補正手法と比較しました。補正手法との比較では、2つの異なる方法を設計しました:(1) 低光照/過曝光画像でNeRFをトレーニングし、その後Novel View Synthesisの段階で2D補正手法をポストプロセッシングとして使用する方法、(2) 2D画像/ビデオの補正手法を使用してデータセットを前処理し、その後これらの強化されたデータでNeRFをトレーニングする方法です。実験の結果、方法(1)の欠点は、低品質な画像でトレーニングされたNeRF自体が信頼性に欠け、その結果、低解像度およびぼやけた状態が生じやすいことです。方法(2)の欠点は、2D画像/ビデオの強化手法が3Dマルチビューの一貫性を保証できないことがよくある点です。全体的には、Aleth-NeRFのようなエンドツーエンドの手法が最適な結果となり、最終的な平均指標で最適な効果を得ることができ、3Dの可視化でも多視点の一貫性を維持できることが実験で示されました。
可視化した結果:

課題と展望
Aleth-NeRFは低照度および過曝光の状況で撮影された画像に対し優れた教師なしでの補正を実現していますが、これらの成果はこのタスクの初期的な成果に過ぎません。例えば、NeRF自体が持つ訓練の遅さやシーンの一般化の難しさなどの欠点があり、またAleth-NeRFは非均一な照明状況や影のあるシーンなど一部の課題に対処できません。さらに、一部のシーンではAleth-NeRFによる復元された画像の色彩に偏りが見られ、一部の過曝光のシーンでは色彩が失われるなどの課題も存在します。本研究では、古代ギリシャの視覚理論からの影響を受けて、Aleth-NeRFはConcealing Fieldsの概念を提案し、暗さを直感的かつ単純な方法でモデリングしています。しかし、他の異なるアプローチによる暗さモデリングの方法も良好な効果を発揮する可能性があり、より効果的な低照度モデリングはAleth-NeRFの課題を克服するかもしれません。