【論文紹介】未知物体認識のための知識を質問生成によって獲得する研究
本記事では,コンピュータビジョンのトップジャーナルであるIJCVに採択された上原助教の論文「Learning by Asking Questions for Knowledge-Based Novel Object Recognition」について紹介します.
- 論文リンク:https://link.springer.com/article/10.1007/s11263-023-01976-7
- プロジェクトページ:https://uehara-mech.github.io/learning-by-asking
本論文では,人間のように質問をしながら賢くなる知能システムの実現を目指した研究に取り組みました.
知能システムにもいろいろありますが,ここでは,コンピュータビジョンの研究において最も有名なタスクである「物体認識」を行う知能システムをターゲットとし,「質問によって知識を獲得し,いままで認識できなかった物体を認識できるようにする」ことを具体的な目標としました.
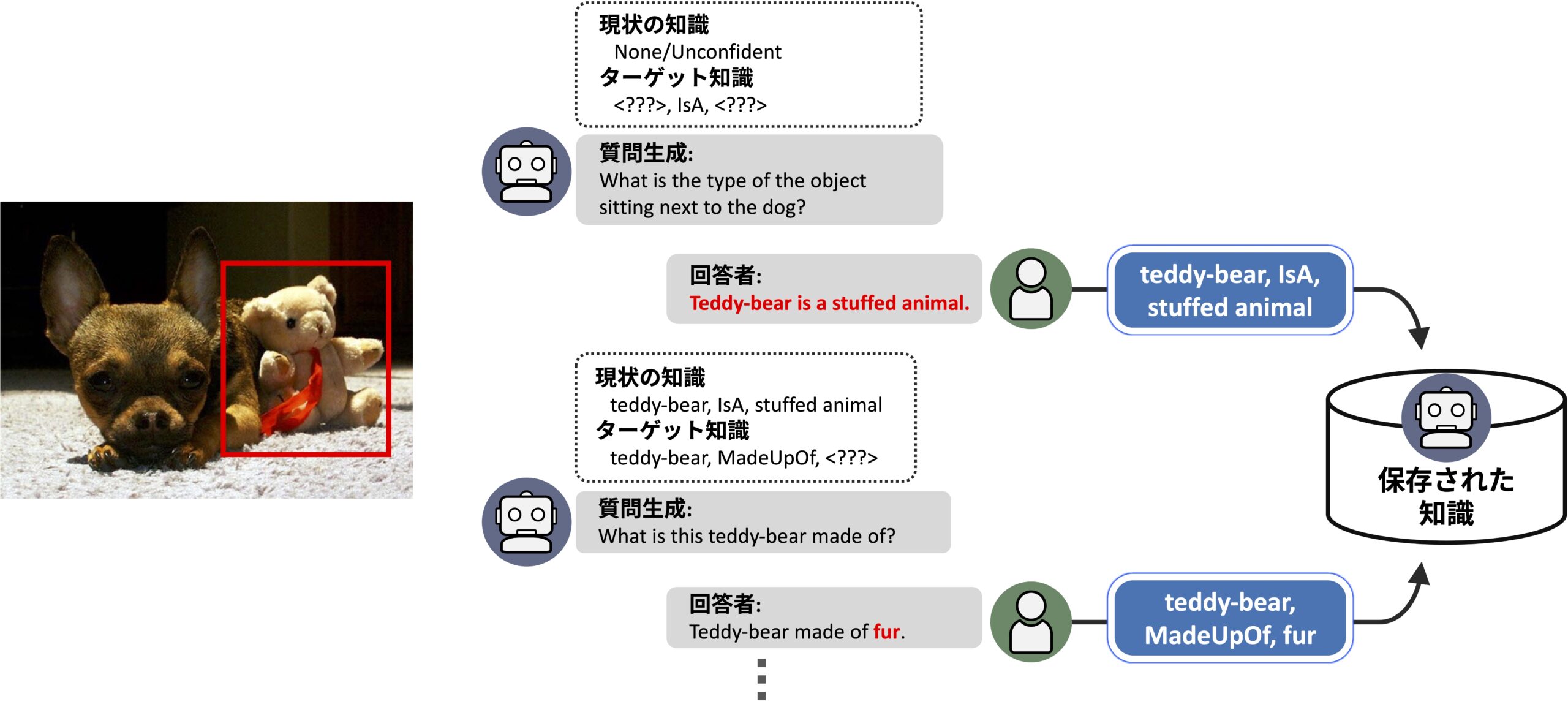
このシステムができることは以下のようになります.
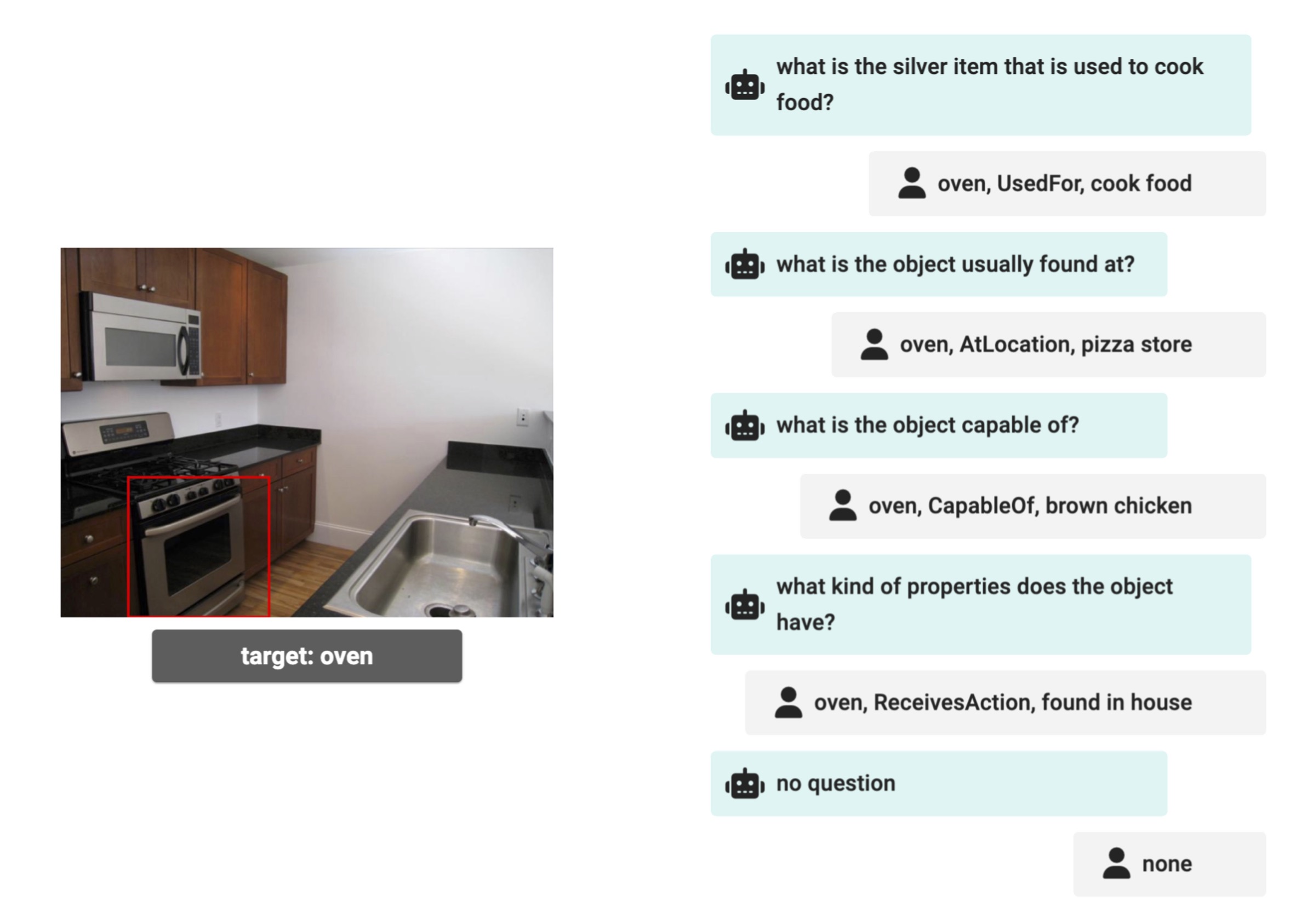
- 与えられた画像に写っている物体について,質問を生成する
- 質問によって獲得した知識を保存し,物体認識に活用する
なお,本研究では対象の物体はすでに検出済みとして扱っていますが,実際にこのシステムを運用する際は,画像から任意の物体を検出する既存研究(Open Vocabulary Object Detection; Grounding DINO1, Owl-ViT2など)と組み合わせるといった方法をとることができます.
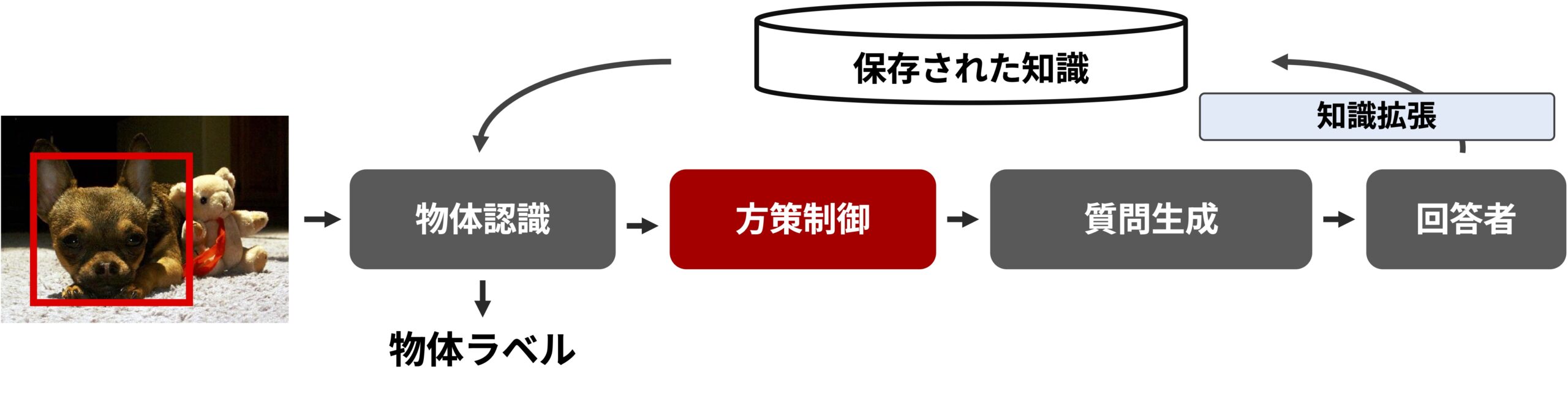
提案システムの全体図
上記の機能を実現するため,私たちが考えたのは,以下のようなモジュールからなるシステムです.
- 知識にもとづいた物体認識を行うモジュール
- 与えられた画像と物体をもとに,「物体についての知識を獲得できる」質問を生成するモジュール(VQG; VIsual Question Generationモジュール)
- 質問生成の方策を制御するモジュール
また,どのような形式で「知識」を扱うかも考えておく必要があります.本研究では,「知識グラフ」をもとにした知識表現を用いています.知識グラフとは,知識をグラフ構造で表したものです.
ここでは,各々の知識はトリプレット(triplet)という方式で表現されます.トリプレットは,「head, relation, tail」の3つの要素からなります.
headは物体の名前など,tailは物体の属性など,relationはheadとtailをつなぐ関係性を表します.たとえば,「ブルーベリーはビタミンCを含む」という知識は,「blueberry(head),has(relation),vitamin C(tail)」というトリプレットで表されます.
この知識トリプレットを無数に組み合わせたものが,知識グラフです.
知識に基づいた物体認識を行うモジュール
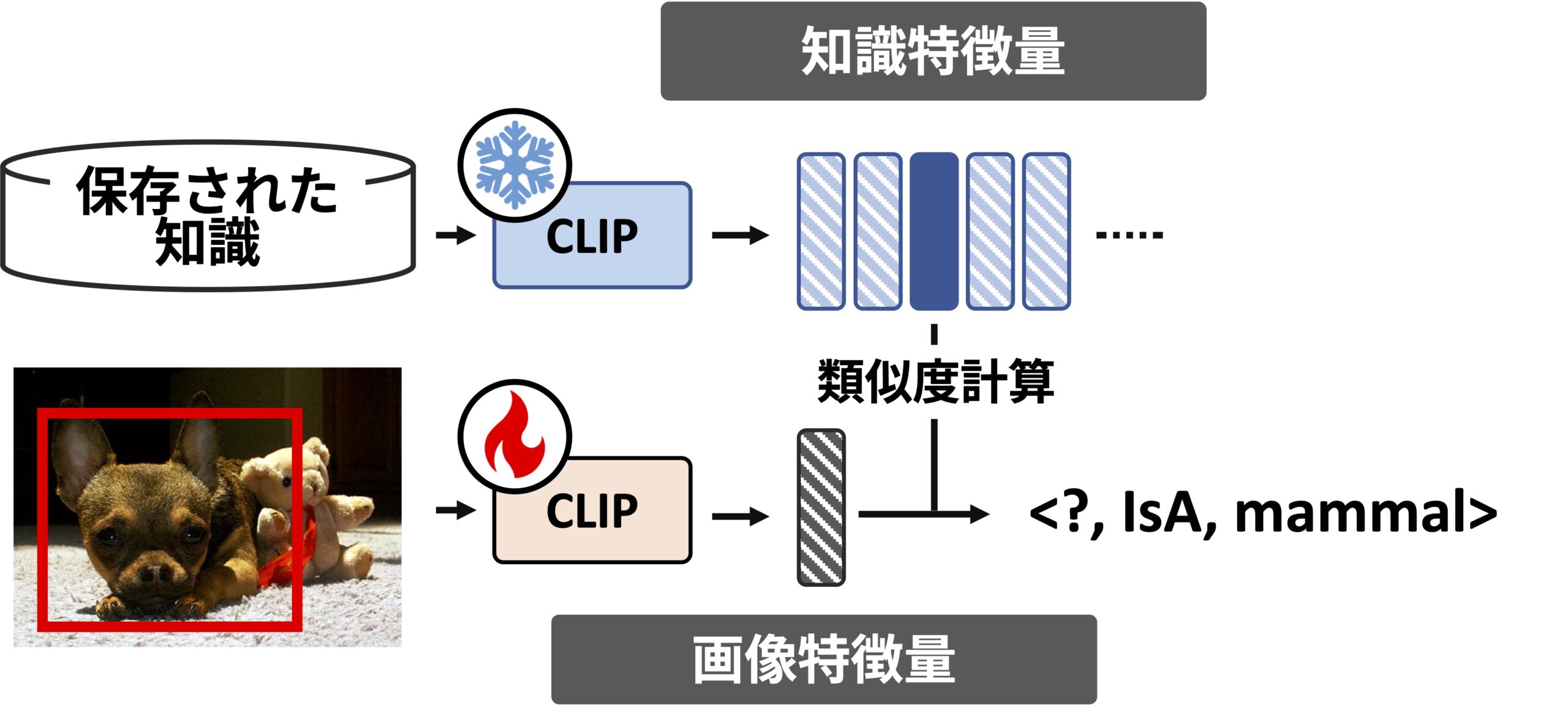
ここでは,知識トリプレットを用いた物体認識モジュールについて説明します.基本的なアイディアは,「知識」と「物体の画像」との類似度を用いるというものです.画像と,その画像の説明文との類似度を計算することのできるモデルは,既存研究に存在します(CLIP 3).
本研究では,CLIPを知識トリプレットと物体画像のペアデータで追加学習することで,与えられた知識と物体画像の類似度を予測できるモデルを作成しました.
知識に基づく質問を生成するモジュール
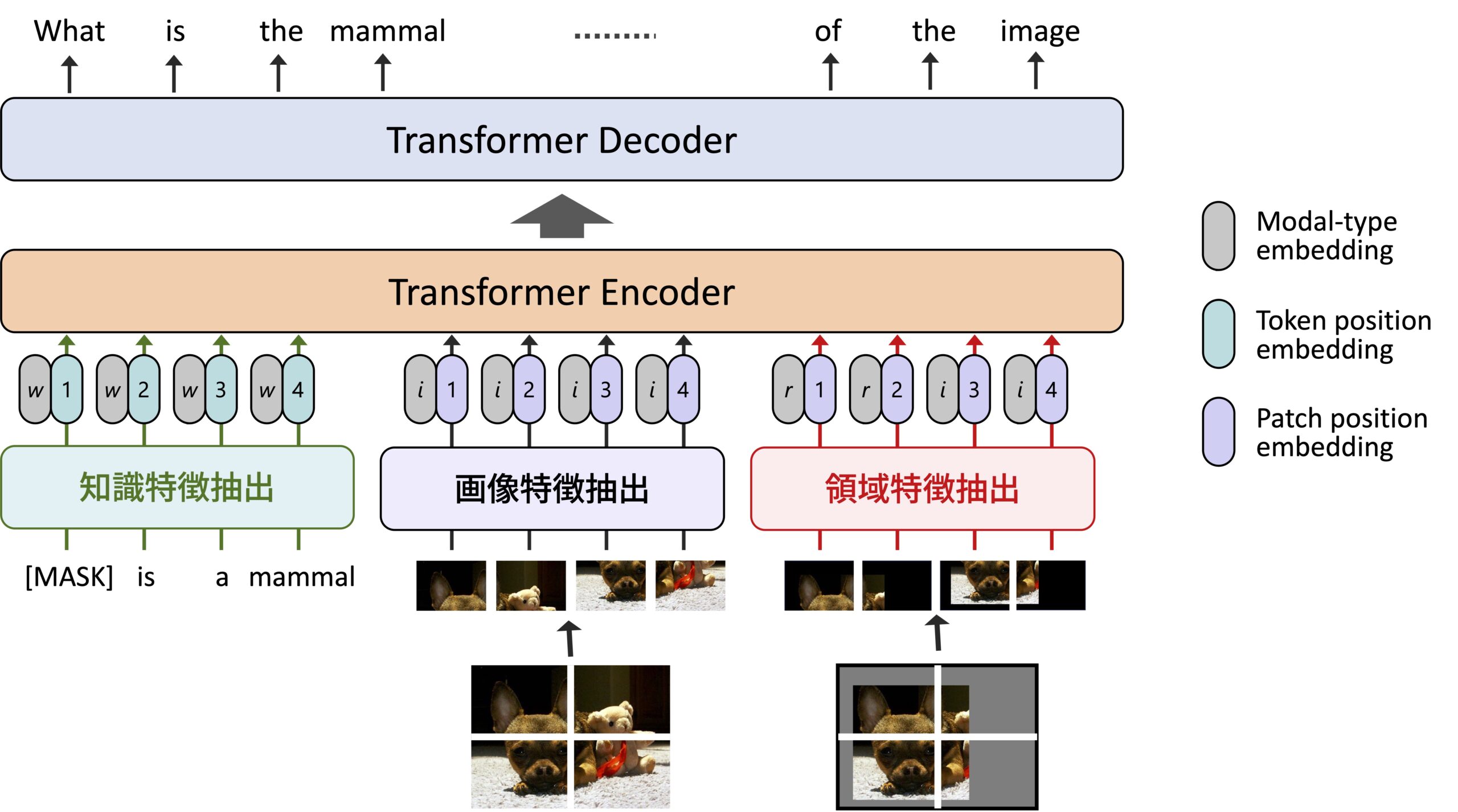
質問生成モジュールでは,画像と,画像中の対象物体,そして獲得したい知識を条件として与え,適切な質問文を生成します.
このモジュールは,基本的には画像を特徴量に変換する画像エンコーダーと,知識を特徴量に変換する知識エンコーダー,文章を生成するテキストデコーダーからなり,「画像・知識・質問文」がそろったデータセットを用いて学習されます.
注意すべき点として,質問を生成する際,事前に回答を知ることはできないということがあります.
すなわち,「画像中の犬の種類は何ですか?」という質問を生成する際に,「dog, is, chihuahua」という知識を入力することはできない(chihuahuaであることは質問をする段階では分からない)ということになります.
よって,質問生成モジュールの学習の際,知識を入力するときは,知識トリプレットから回答になる部分をマスクして,「dog, is, [MASK]」のように変換しておきます.
ここで,本研究を行うにあたってのひとつのハードルに,上記の「画像・知識・質問文」がそろった大規模データセットが存在しないという問題がありました.
そこで,私たちは,データセット作成を業者に依頼し,高いクオリティをもつ大規模データセットであるProfessional K-VQGデータセットを新たに構築しました.
Professional K-VQGデータセットと,以前の研究で構築したK-VQGデータセット4を組み合わせることで構成されるK-VQG v2データセットは,約2万2千件の質問文を含むデータセットとなりました.
質問の方策を決定するモジュール
質問をただ闇雲に生成しても,物体認識に関係のない知識が蓄えられるだけで,一向に物体認識の成績があがらないという問題がありえます.
それを防ぐため,物体認識の性能を向上させられるような質問を生成できるよう,質問生成の方策をコントロールするのが,このモジュールの役割です.
ここでは,強化学習アルゴリズムの一種であるREINFORCEを用いて,方策コントロールを実現します.
強化学習では,設定された報酬を最大化するようなモデルを学習します.
ここでは,報酬として「所望の知識が獲得された後の物体認識性能と,もとの物体認識性能の差」を利用することで,獲得した知識によってなるべく物体認識の性能が向上するようにしています.
実験
結果として,「適切な方策の決定」と「質問生成モジュールの設計」が,質問生成による新規物体認識に重要であるということがわかりました.
参考文献
- Liu et al., Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint, 2023. ↩︎
- Minderer et al., Simple Open-Vocabulary Object Detection with Vision Transformers. ECCV, 2022. ↩︎
- Radford et al., Learning Transferable Visual Models From Natural Language Supervision. ICML, 2021. ↩︎
- Uehara et al., K-VQG: Knowledge-aware Visual Question Generation for Common-sense Acquisition. WACV, 2023. ↩︎

