【論文紹介】GPAvatar: 画像からの汎化可能かつ精密なヘッドアバターの生成
ヘッドアバターを忠実に再構築し、表情と姿勢を正確に制御するためには、既存の手法ではトレーニングに大量の個別データが必要であり、表情の制御はまだ十分に精確ではありません。今回、私たちはこれらの問題に取り組み、論文「GPAvatar: Generalizable and Precise Head Avatar from Image(s)」を発表しました。この研究について、本稿では著者のXuangeng Chuが解説します。本研究は2024年のInternational Conference on Learning Representations (ICLR)にて発表される予定です。
【研究背景】
ヘッドアバターの再構築は、仮想現実、オンラインミーティング、ゲーム、映画産業などのアプリケーションにおいて重要です。この分野の基本的な目標は、ヘッドアバターを忠実に再構築し、表情とポーズを精確に制御することです。
従来の手法では、操作可能な人間のヘッドアバターを作成することは難しく、熟練したモデラーやアニメーターが必要でした。操作可能なヘッドアバターの作成を簡素化し、その応用を促進するために、研究者たちは2D歪みフィールド、メッシュ法、およびニューラルレンダリング手法を含むAI技術を使用した一連の手法を開発してきました。これらの手法は、操作可能なヘッドアバターを迅速に作成する初期の成功を収めていますが、複数のビューの一貫性の維持、非顔情報の統合、および新しいアイデンティティへの拡張において課題があります。
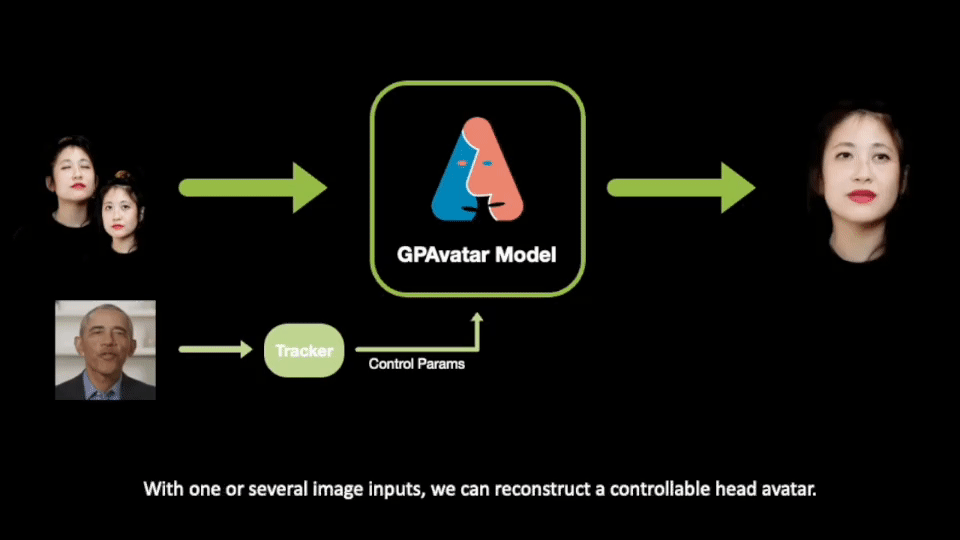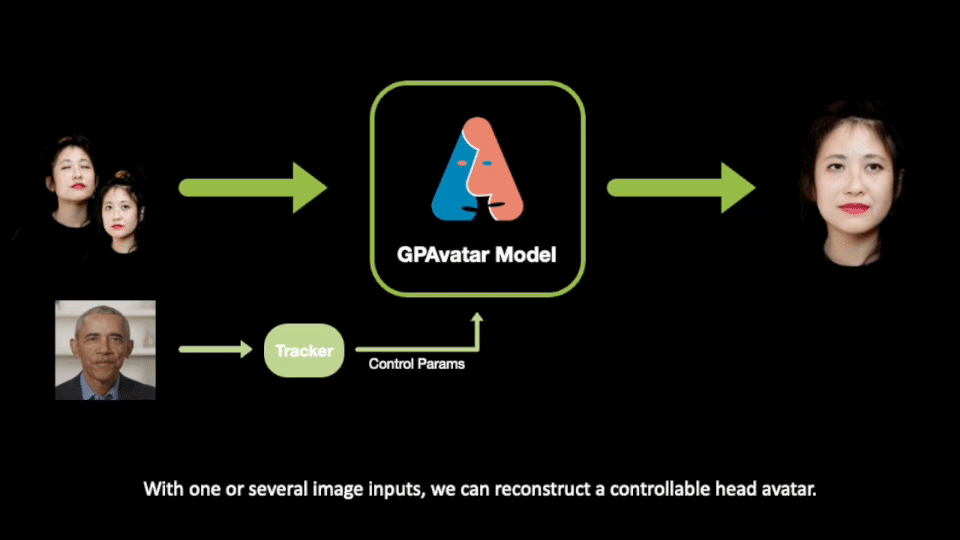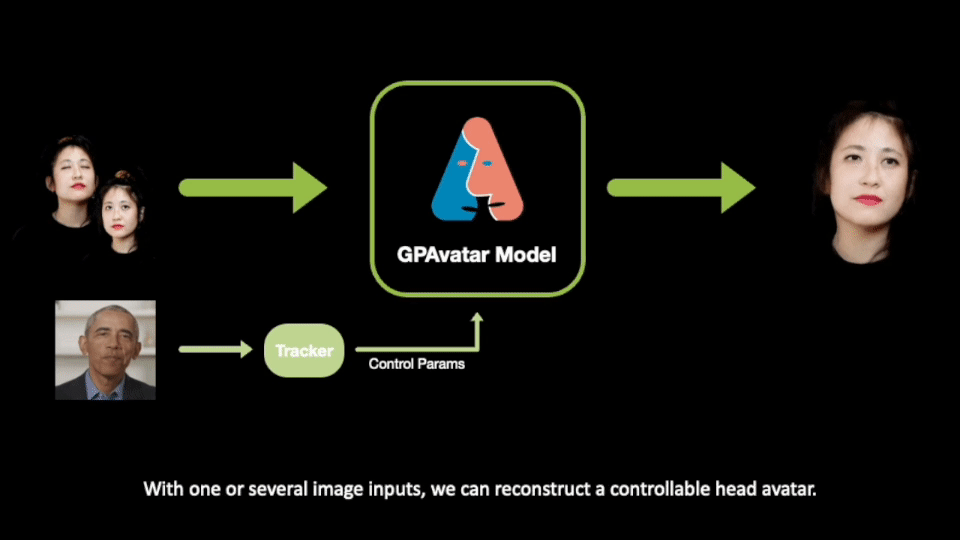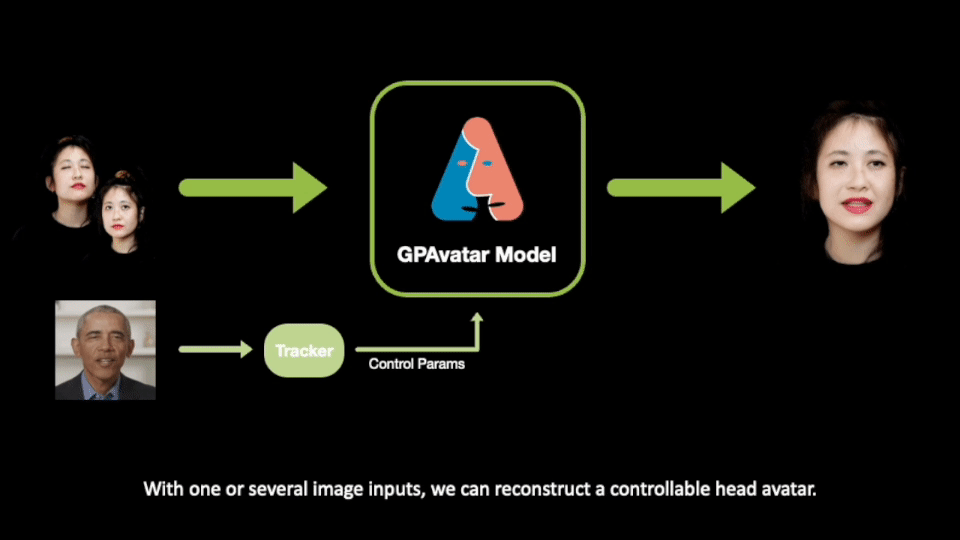
ここで紹介される研究では、GPAvatarと呼ばれるフレームワークが提案されています。1 つまたは少数のユーザー画像のみを提供することで、フレームワークは微調整や再トレーニングを行わずに操作可能なアバターを作成し、忠実なアイデンティティの再構築、精確な表情制御、および複数のビューの一貫性を実現します。
以下では、いくつかの関連する手法を簡単に紹介します:
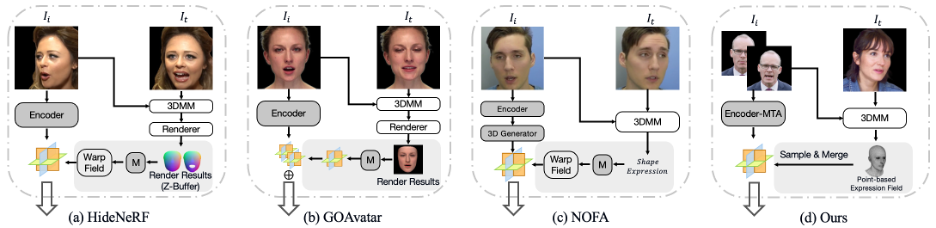
HideNeRF[1]、GOAvatar[2]、およびNOFA[3]は、GPAvatarと似た機能を共有しています。ただし、HideNeRFとGOAvatarはメッシュ深度をレンダリングしてから特徴を抽出するため、表情の特徴の過度な処理が行われ、結果として表情の詳細が失われます。一方で、NOFAは直接一次元のFLAME表情特徴を利用していますが、その表現力が十分でない可能性があります。
これらの手法と比較して、私たちの手法は点群を直接利用しています。これにより、他の方法とは異なり、表情を最も正確に制御できます。
【方法と結果】
【用語と背景手法】
- NeRF[4]: 私たちの手法は、Neural Radiance Fields (NeRF) を使用してレンダリングとモデリングを行います。NeRFは、2D画像から3D表現を抽出し、任意の視点からの再レンダリングを可能にします。我々はこの技術を拡張して、ワンショットの入力を受け入れ、ダイナミックなシーンを処理できるようにしています。
- FLAME[5]/3DMM: 私たちの手法は表情制御に FLAME を使用します。 FLAME は、幾何学的精度と柔軟性で知られる 3DMM (3D Deformable Model) であり、顔の特徴や表情を正確に制御できます。 1 次元の顔の表情と形状の特徴を入力として受け取り、対応する形状と表情の 3D メッシュモデルを生成できます。 我々はFLAMEメッシュからのポイントクラウドを表情制御に使用しています。
提案された手法について詳細に説明します。
私たちの手法は、任意の数*の入力からヘッドを再構築し、表情ポーズを自由に制御し、入力画像の詳細とアイデンティティを忠実に再構築できます。
*1つの画像のみが入力される場合も含まれます。
以下は、私たちの手法の全体的なパイプラインです。
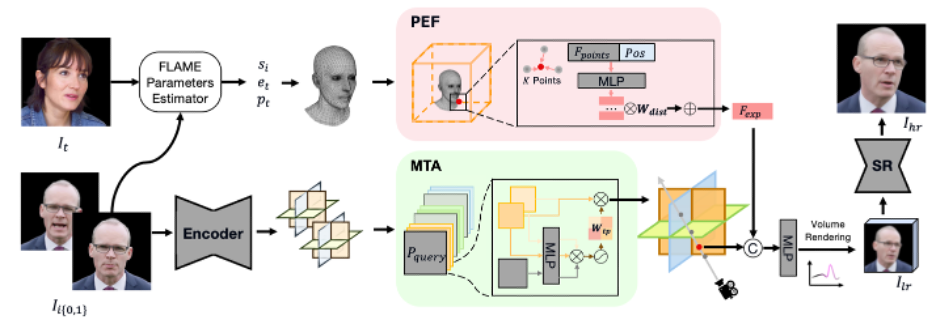
私たちの手法は主にエンコーダーと2つのブランチから構成されています:1つのブランチはポイントベースの表情フィールド (Point-based Expression Field, PEF) を使用して微細な表情特徴を捉え、もう1つのブランチはマルチトライプレーンアテンション(Multi Tri-planes Attention, MTA)を介して複数の入力からの情報を統合します。最終的には、レンダリングと超解像のコンポーネントがあります。
最初に、我々はエンコーダーを使用して、元の画像をEG3D[6]からのトライプレーン表現にマッピングします。トライプレーン表現は強力な3Dジオメトリの先行知識を持ち、合成品質と速度の良いバランスを実現しているため、これを標準の特徴空間とします。実験では、この構造がダウンサンプリングプロセス中に入力画像からのグローバルな情報を効果的に統合し、アップサンプリングプロセス中には相互に相関する平面を生成できることが観察されました。
次に、FLAMEからのポイントクラウドを使用してポイントベースの表情フィールドを構築し、過度な処理を避けつつできるだけ表情の詳細を保存します。Point-based Expression Field (PEF)は、動的な表情をモデル化するために設計されています。この目標を達成するために、各FLAME頂点に学習可能な重みをバインドします。NeRFサンプリングプロセス中の任意のクエリ3D位置に対して、PEF内の最も近いK点を取得し、それらの対応する特徴と距離を取得します。その後、各点の特徴を回帰するために線形層を使用し、距離重み付き集約に基づいてサンプル位置の最終特徴を計算します。同時に、2つの特徴空間から特徴をサンプリングするため、正準特徴空間はPEFとFLAMEからの3D先行情報と共に学習に協力します。このプロセス中、学習可能な特徴を持つポイントの位置はFLAMEの表情パラメータとともに変化し、動的な表情特徴フィールドを形成します。そして、この動的な表情フィールドにより、FLAMEの変化がNeRF特徴空間に直接寄与し、過度な処理からの情報損失を回避します。
前述のモジュールに基づいて、高い忠実度の結果が得られます。ただし、ソース画像が任意であるため、これにはいくつかの困難なケースがあります。例えば、ソース画像に遮蔽があるか、ソース画像の目が閉じられているのに、目を開いた表情が必要な場合などです。この状況では、モデルは統計的に平均された目や顔の特徴に基づいて錯覚を生成する可能性がありますが、これらの錯覚は誤っているかもしれません。この画像は欠落部分の真実を生成できませんが、補完するための他の画像があるかもしれません。この目標を達成するために、我々は複数の画像のトライプレーン特徴を結合するためのアテンションベースのモジュールを実装しました。これをMulti Tri-planes Attention(MTA)と呼びます。我々のMTAは、異なる画像から抽出された複数のトライプレーンをクエリするために三つの学習可能な平面を使用し、特徴の結合のための重みを生成します。実験を通じて、MTAが一発の入力において欠落した情報(例:極端なポーズ変化下の瞳の情報や顔のもう片方)を補完することを示しています。訓練後、MTAは任意の数の画像を入力として受け入れることができます。
前述のコンポーネントを組み合わせて最終的な特徴を得た後、我々はクラシックなNeRFレンダリング手法を用いて低解像度の2D結果を得ます。その後、共同で訓練された超解像モデルを利用して最終結果を得ます。
以下は、いくつかの結果の例です。左には入力画像があり、右にはモデルの出力と目標の表情が表示されています。

さらに、上記の画像の生成時に得られた深度情報も以下に示します。

詳細なビデオ結果やオープンソースのコードについては、プロジェクトのウェブサイトを参照してください:https://xg-chu.github.io/project_gpavatar
【まとめ】
我々は、広範なデータや微調整の必要がなく、迅速な3Dヘッドアバターの再構築と精確な表情制御が可能な手法を紹介しました。この低コストのアプローチが、仮想現実、オンラインミーティング、ゲーム、映画産業など、さまざまな産業において制御可能な3Dアバターの創造に寄与できると信じています。
【研究を振り返って】
確立された技術的な道筋から逸脱した新しいダイナミック制御手法の探索は、リスクと不確実性に満ちたプロセスでした。
参考文献
[1] Li, Weichuang, et al. "One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field." IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
[2] Li, Xueting, et al. "Generalizable One-shot Neural Head Avatar." In the Thirty-seventh Annual Conference on Neural Information Processing Systems(NeurIPS), 2023.
[3] Yu, Wangbo, et al. Nofa: Nerf-based one-shot facial avatar reconstruction. In ACM SIGGRAPH 2023 Conference Proceedings, 2023.
[4] Mildenhall, Ben, et al. NeRF: Representing scenes as neural radiance fields for view synthesis. European Conference on Computer Vision (ECCV), 2020.
[5] Li, Tianye, et al. Learning a model of facial shape and expression from 4D scans. ACM Transactions on Graphics (Proc. SIGGRAPH Asia), 2017.
[6] Chan, Eric R., et al. "Efficient geometry-aware 3D generative adversarial networks." IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022.