【論文紹介】画像からの不適合抽出と解決による識別的ユーモアキャプションの生成に関する研究
画像からユーモラスなキャプションを生成するには、高度な外部知識を活用する必要がある上、画像の細かい特徴をもとにした内容を生成する必要があるという難しさがあります。私たちの発表した論文「Content-Specific Humorous Image Captioning Using Incongruity Resolution Chain-of-Thought」ではマルチモーダル大規模言語モデルを用いて、画像の細かい特徴を捉えたユーモラスなキャプションの生成を実現しました。本稿では著者の田中康太郎が解説します。本研究は2024年のNorth American Chapter of the Association for Computational Linguistics (NAACL Findings)にて発表される予定です。

【研究背景・目的】
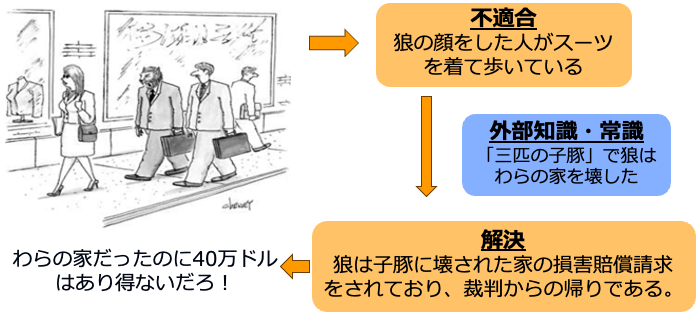
画像にユーモラスなキャプションをつけたコンテンツは世界中の様々なコミュニティで楽しまれています。例えばミームは欧米のSNSで、ボケては日本のオンラインコミュニティで、The new yorker cartoon captioning contestは雑誌の読者の間で人気です。本研究ではこのようなユーモラスなキャプションの生成を扱います。 人間が生成する画像とキャプションのユーモアには二つの特徴があります。一つ目は画像に存在するおかしさまたは不適合を外部知識や常識を用いて意外な解決を行うことでユーモアが生まれるということです。例えば図2の画像には狼の顔をした人がスーツを着ているというおかしさがあります。これを「三匹の子豚」というストーリーでは狼がわらの家を壊したという外部知識をもとに、「狼は子豚に壊された家の損害賠償請求をされており、裁判からの帰りである」という意外な解決を行うことで、面白いキャプションが出来上がります。
もう一つの特徴として、人間が生成するキャプションは画像の細かい特徴をもとにしており、画像ごとに異なるキャプションが紐づくということです。これを識別的なキャプションと呼ぶことにします。例えば、図3の上の例では中央の人が狼の顔をしているという細かい特徴をもとにキャプションを生成しており、下の例では、鳥が会社で会議をしているという細かい特徴をもとに種銭という掛け言葉で面白さを作っています。この2つの画像に紐づくキャプションは異なっています。逆に識別的でないキャプションの例をあげると、どちらの画像もビジネスが関係ありそうという大雑把な特徴のみから、「間違った会議室に入ってしまった」という同じストーリーのキャプションになってしまいます。既存のユーモラスなキャプションを生成する手法では、識別的でないキャプションが生成されてしまうことが本研究の分析でわかりました。

本研究では、人間が作成した画像とキャプションのユーモアの特徴を反映したキャプション生成を行えるようにすることを目標とします。
【手法と結果】
本研究ではマルチモーダル大規模研後モデル(MLLM)を用いて、ユーモラスなキャプション生成を行います。MLLMは大量の画像テキストペアのデータを用いて学習されているため、画像と「この画像に面白いキャプションをつけてください」という指示文を入力することでユーモラスなキャプションを生成できます。MLLMの特徴として、学習時に獲得した外部知識に沿ったテキストが生成できるということがあります。また、不適合解決のような論理的思考力が必要な複雑なタスクにおいて、指示文で取るべき思考過程を指定したり、複数の論理ステップを踏むように指定したりすると、性能が向上することが示されています。これをChain of thought promptingと呼びます。
MLLMに識別的ユーモアキャプションを生成させるための指示文フレームワークIRCoTを提案します。IRCoTはGPT4-VのようなMLLMに5ステップに分けてキャプションを生成させます。各ステップでMLLMは前のステップで与えられた指示やそれに対する自身が生成した内容も考慮して出力を行います。
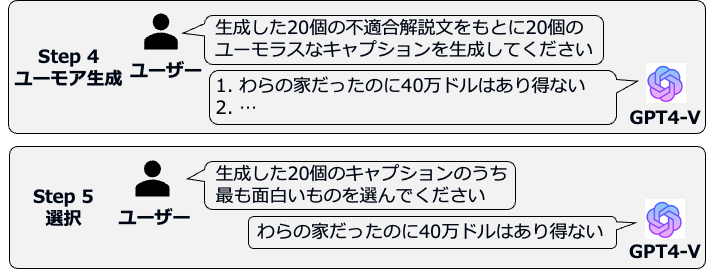
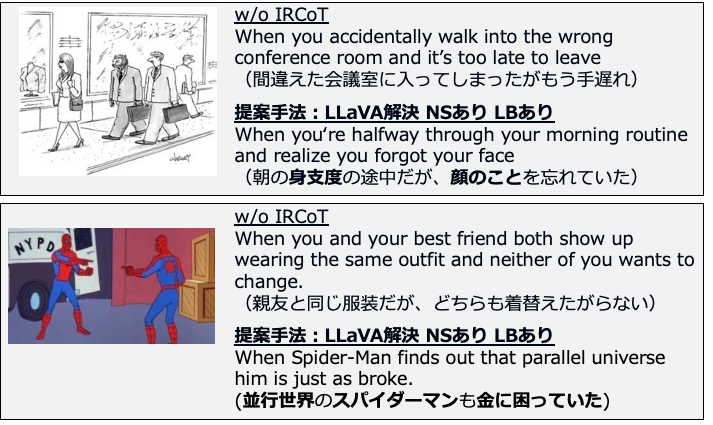
まずステップ1では与えられた画像の詳細な説明を生成させ、ステップ2で画像中の不適合を抽出します。次にステップ3で不適合を解決できる説明文を20個生成させます。次にステップ4ではステップ3で生成した20個の不適合解説に対応する20個のユーモラスなキャプションを生成します。最後にステップ4で自身が生成したキャプションのうち最も面白いものを選択します。IRCoTでは最初のステップで画像固有の細かい特徴を抽出し、それをもとに不適合解決とユーモア生成をするように促すため、識別的ユーモアキャプションが生成できると考えられます。
また、ステップ3の不適合解決でどんな不適合も解決できるキーワードを用いた説明が生成され、キャプションの識別性が下がることを防ぐためにLogit BiasとNegative Samplingを提案します。どちらの手法でもまずどんな不適合でも解決できるキーワードリストを作成するためにまずユーモアに用いられている複数の画像をGPT4-Vに入力し、IRCoTの不適合解決まで行い、解決文を多数生成します。また、MSCOCOのような一般的な画像とキャプションがペアになっているデータセットを選択し、不適合解決文に登場する単語と画像キャプションデータセットに登場する単語の出現頻度を集計します。すると、Thisやaのようにどのような説明文にも登場するような単語は不適合解決文でも画像キャプションデータセットでも同程度の出現頻度になる一方で、movieのようなどのような不適合でも解決できてしまうキーワードは不適合解決文にのみ多数出現します。不適合解決文では多く出現し、画像キャプションデータセットではあまり出現しない単語を抽出し、どんな不適合でも解決できるキーワードリストとします。この手法で実際に抽出された単語としてはmovie, story, manga, play, gameなどがありました。

Logit BiasとNegative SamplingはMLLMにどんな不適合でも解決できるキーワードリストの単語を出力させないようにする工夫です。Logit biasは推論時にモデルが出力する次の単語の確率値の中でこれらのキーワードリスト中の単語の確率のみを下げることで生成を抑えます。また、Negative Samplingではキーワードリスト中の単語を生成すると罰を与える損失を用いてファインチューニングします。Logit BiasやNegative SamplingはIRCoTの不適合解決のステップのみで使用されます。
本手法の生成したキャプションの識別性と面白さを定量的に評価しました。その結果、IRCoTを用いて生成したキャプションを既存手法に比べて識別性が高かった上、Logit BiasとNegative Samplingを用いることで、さらに生成されるキャプションの識別性が高まり、人間が作ったキャプションに近くなりました。また、生成されたキャプションの面白さをクラウドソーシングプラットフォームを用いて、人間に評価してもらったところ、人間が作ったキャプションよりも、本手法によって機械が生成したキャプションの方が面白いという結果になりました。
【まとめ】
本研究ではIRCoT, Logit Bias, Negative samplingを提案し、生成されたキャプションの面白さを維持しながら、MLLMを用いて画像の細かい特徴をもとにした識別的ユーモアキャプションを生成できることを示しました。今後の展望としては、MLLMの画像理解性能を高めることで、より面白いキャプション生成ができるようになることが期待される上、ユーモア生成の思考過程が可視化できるため、不適切なコンテンツ生成抑止につながると考えられます。

