【論文紹介】SceneProp: Combining Neural Network and Markov Random Field for Scene-Graph Grounding
視覚グラウンディング(visual grounding)は、文章などの特定物体を指し示す記述から画像内の対象物を特定するタスクであり、ロボット操作における指示文の理解や、対象物の特定が不可欠な画像に対する質問応答など、さまざまな応用において重要な役割を果たします。 当研究室から発表された論文 "SceneProp: Combining Neural Network and Markov Random Field for Scene-Graph Grounding" では、文章の代わりに物体間の関係性を構造化した形式を用いることにより、GPT-4o など既存の手法では不可能だった複雑なグラウンディングを可能にしました。 本論文は、主要なコンピュータビジョンの国際学会のひとつであるWinter Conference on Applications of Computer Vision (WACV) 2026にて発表されました。
この成果により、ロボットにおいて指示文へ追従する精度の向上や、視覚言語モデルと組み合わせることにより、さらなる画像に対する質問応答の性能向上が期待できます。
この記事では、著者の尾谷圭太(Keita Otani)がこの論文について解説します。
この記事で紹介する論文
この記事では、以下の論文について紹介します。
Keita Otani, Tatsuya Harada SceneProp: Combining Neural Network and Markov Random Field for Scene-Graph Grounding. The IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). 2026
論文の概要
近年、視覚グラウンディング(visual grounding)モデルやGPT-4o[1]に代表される視覚言語モデルが、有望な結果を示しています。 しかしながら、「タブレットを持つ人物の隣でペンを持っている女性」のような複数の人物や物体が関連し合うような指示文に対する応答には、複数の物体/人物が混ざりあった答えを返すなど、依然として課題が残されています。
- GPT-4oによる結果:複数の人の特徴が混ざりあった結果を出している

- Grounding DINO[2]による結果:ほとんど物体/人物間の関係性を考慮できてない
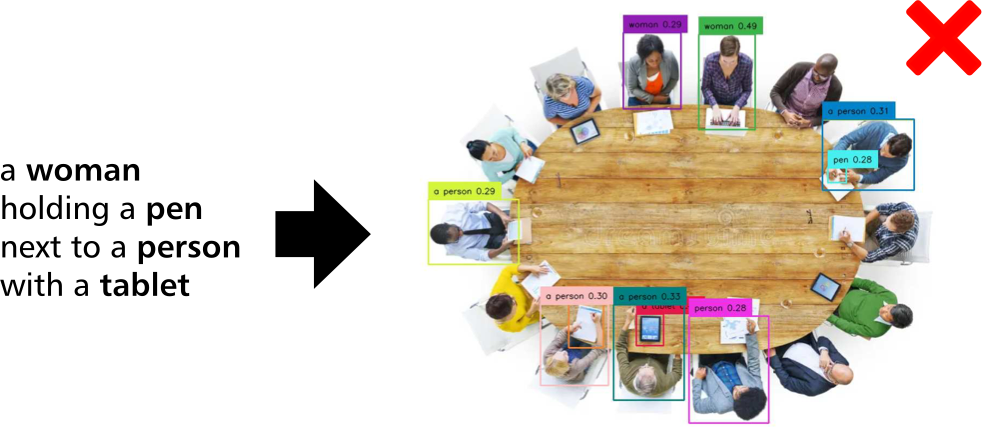
本研究では、文章の代わりに物体/人物とその関係性をグラフ構造で表す「シーングラフ」という表現方法を採用し、関係の構造を明示的に捉えてグラウンディングすることを可能にしました。テキストから物体の位置を特定することを フレーズグラウンディング (Phrase Grounding) 呼ぶのに対し、このシーングラフを用いるこのタスクを シーングラフグラウンディング(Scene-Graph Grounding) と呼びます。 また、ニューラルネットワークの手法においてグラフ構造はグラフニューラルネットワーク(GNN)で扱うことが一般的ですが、複雑なグラフ構造では性能が劣化することが知られていました[3]。
本研究ではグラウンディングを「グラフ上のエネルギー最小化問題」として捉え直し、マルコフ確率場(Markov Random Field; MRF)という枠組みを使って解くことにより、GNNの問題を克服しました。
- SceneProp(本研究)による結果:正しい人物が特定できている

この論文で提案された手法・アルゴリズムなど
入出力
本研究では、あらかじめ物体/人物の間の関係性がグラフ構造で与えられているという前提で、画像中から各物体/人物の位置を特定することを目的としています。
入力
- 画像
- クエリグラフ
- ノード(頂点)が物体/人物を表し、エッジ(辺)が関係性を表す
出力
- 各物体(グラフ中のノード)に対応するバウンディングボックス
パイプライン
本手法では、まず候補領域(下図の左下のバウンディングボックス)を大量に出力します。 その後、出力された候補領域の中からグラフの各頂点に最も適切なものを選択します。 この候補領域の選択にMRFを使用しているところが、本手法の最も新しい点です。
全体のパイプラインは以下のようになっています。
- 通常の物体検出器(本手法ではDyHead)を用い、大量の候補領域を出力する。
- 各候補領域に対する特徴量と位置エンコードを連結し、領域特徴を作成する。
- クエリグラフに含まれるそれぞれの物体カテゴリについて、各候補領域がそのカテゴリに属する確率を出力する。
- クエリグラフに含まれるそれぞれの関係性カテゴリについて、候補領域のすべての組み合わせについて、その関係性を持つ確率を出力する。
- 3, 4で得られた確率値に対して、どの物体にどの候補領域を割り当てるのが尤もらしいかを計算する。この計算はクエリグラフと同じ形を持つMRFを作成し、MRFのパラメータに3, 4で得た確率値を当てはめることによってなされる。

GNNは層を深くすると過剰平滑化(Over-Smoothing)という問題が発生し、ノードの特徴が消えてしまう現象が発生します。 そのため層数を深く出来ないという問題があり、近隣の情報のみしか利用できず、全体最適な割り当てを得ることが不可能でした。 本手法はこうした現象の発生しないMRFを用いることにより、従来のGNNでは不可能だった全体最適な割り当てを見つけることを可能としています。
実験結果
定量評価
4つのデータセットを使用し、正解が上位N番目以内に入っているか(Recall)という指標を用いて評価を行いました。
- Recall@1 (R@1): 最も確信度の高い出力が正解である割合
- Recall@5 (R@5): 上位5番目以内に正解が含まれている割合
結果、視覚言語モデルやフレーズグラウンディングモデルを、実験に用いた全てのデータセットにおいて上回ったほか、既存のシーングラフグラウンディングを行うGNNベースの手法であるVL-MPAGよりも高い性能を達成しました。
| Type | Model | VG-FO [3] | VG150 [7] | COCO-Stuff [8] | GQA [9] | #params | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@1 | R@5 | R@1 | R@5 | R@1 | R@5 | |||
| 視覚言語モデル | Florence-2-L [6] | 19.6 | - | 19.0 | - | 18.5 | - | 10.2 | - | 770M |
| フレーズグラウンディング (テキストからの物体位置特定) | MDETR [4] | 25.4 | 44.8 | 27.0 | 45.3 | 30.1 | 47.9 | - | - | 169M |
| GLIP-T [5] | 31.1 | 51.3 | 30.4 | 50.3 | 45.9 | 80.4 | 23.6 | 49.8 | 232M | |
| GroundingDINO [2] | 32.0 | 48.5 | 31.6 | 47.9 | 47.3 | 80.4 | 25.4 | 47.0 | 172M | |
| シーングラフグラウンディング (グラフからの物体位置特定) | VL-MPAG (GNNベース) [3] | 36.0 | 63.3 | 33.6 | 59.9 | 36.3 | 58.4 | 5.2 | 18.7 | 69M |
| SceneProp (Ours; MRFベース) | 46.6 | 67.1 | 43.7 | 68.4 | 68.2 | 88.9 | 53.6 | 68.2 | 34M | |
またクエリグラフが複雑になったときの性能を評価するため、クエリグラフ中の関係性の数、すなわちグラフの辺の数ごとの評価を行いました。 以下の図は横軸に関係性の数、縦軸をRecallとしたグラフです。
先行研究は関係性の数が増えると問題の複雑性が増すため性能が低下しますが、私達の手法は逆に性能が向上します。 これは、関係性は物体の位置を決定するための大事な"ヒント"であり、ヒントが増えると性能が向上するという、あるべき姿が達成されたものだと思われます。

定性評価
他モデルとの比較
以下の例は似たような人物が二人写っているためにGrounding DINOやVL-MPAGがグラウンディングに失敗してしまう例です。 一方でScenePropはすべての関係性を満たすような組み合わせを見つけることに成功しています。
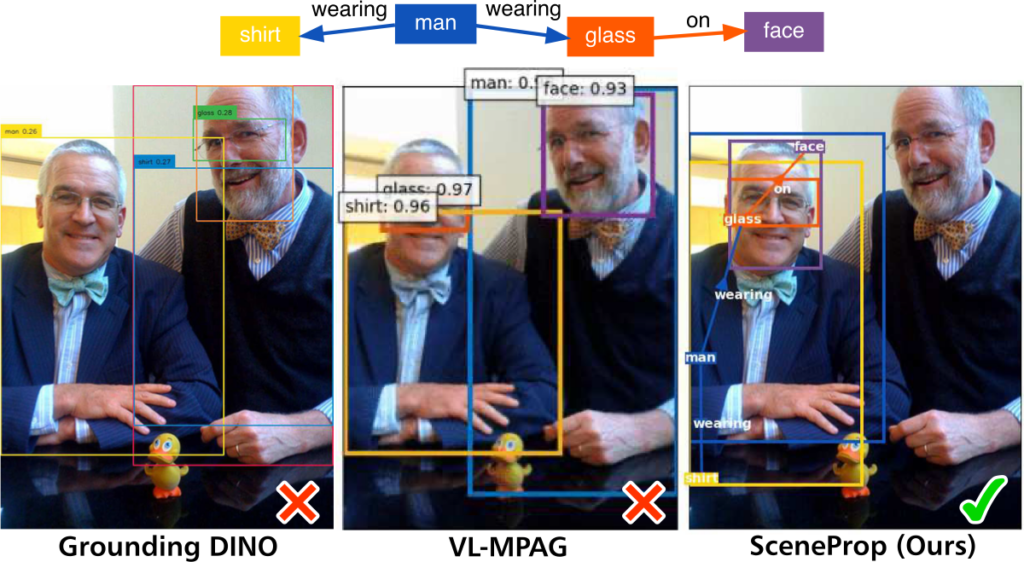
推論結果サンプル(成功例)
以下はVG-FOの評価セットをScenePropで推論した結果です。 クエリグラフが複雑であっても正しくグラウンディングできていることが定性的にも見て取れます。

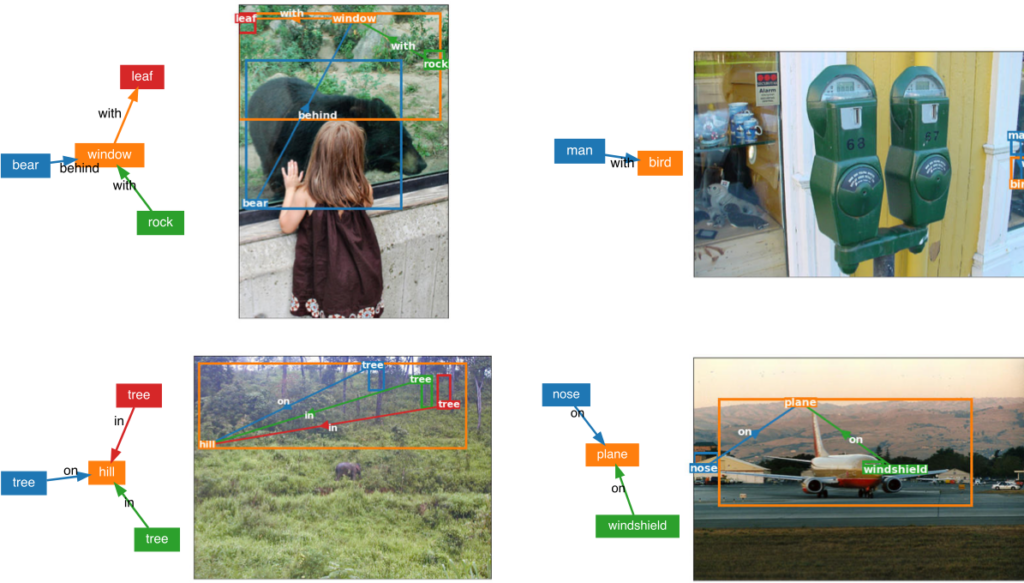
推論結果サンプル(失敗例)
左下と左上の例は、境界が曖昧な物体の位置特定が不正確になるという失敗例です。この問題は多くの物体検出器と共通する失敗となっています。 右上の例では、難しい視覚条件により誤ったグラウンディングが生じるパターンで、小さく反射の多い対象のため「男性」と「鳥」を正しく特定できていません。 右下の例では、"nose"と"plane"の概念の対応付けが難しく、誤りが生じています。
まとめ
本記事では、物体/人物とそれらの関係性をグラフ構造で表す「シーングラフ」という表現方法を採用した、物体の位置特定(グラウンディング)する研究を紹介しました。 MRFをニューラルネットワークと組み合わせることで、全ての関係性を同時に満たすような位置特定ができるようになりました。 ChatGPTに代表される視覚言語モデルなど、既存モデルが持つ弱点を克服する上で、重要な研究になったと考えています。
参考文献
[1] Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024.
[2] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In Proceedings of the European Conference on Computer Vision (ECCV). Springer, 2024.
[3] Aditay Tripathi, Anand Mishra, and Anirban Chakraborty. Grounding scene graphs on natural images via visio-lingual message passing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 4380–4389, 2023
[4] Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. Mdetr - modulated detection for end-to-end multi-modal understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 1780–1790, 2021.
[5] Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
[6] Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a unified representation for a variety of vision tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4818–4829, 2024.
[7] Danfei Xu, Yuke Zhu, Christopher B. Choy, and Li Fei-Fei. Scene graph generation by iterative message passing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[8] Holger Caesar, Jasper R. R. Uijlings, and Vittorio Ferrari. Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1209–1218, 2018.
[9] Drew A. Hudson, and Christopher D. Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019.

