【論文紹介】Dr. RAW: Towards General High-Level Vision from RAW with Efficient Task Conditioning
標準的なコンピュータビジョンではRGB画像が一般的に使用されていますが、RAWデータを直接扱う方法も注目を集めています。2025年12月にアメリカのサンディエゴで開催された機械学習のトップカンファレンス Neural Information Processing Systems (NeurIPS) 2025で、私たちは、カメラの RAW データから物体検出やセグメンテーションなどの高度なビジョンタスクを効率的に実行するための統合フレームワーク「Dr. RAW」についての論文 "Dr. RAW: Towards General High-Level Vision from RAW with Efficient Task Conditioning" を発表しました。
このフレームワークにより、事前学習済みモデルにセンサーの事前情報を賢く組み込むことで、堅牢で汎用的な視覚システムを構築することが可能になります。
この記事では、著者の崔 子藤(Ziteng Cui)が、この論文について解説します *1。
この記事で紹介する論文
この記事では、以下の論文について紹介します。
Wenjun Huang*, Ziteng Cui* (*: co-first author), Yinqiang Zheng, Yirui He, Tatsuya Harada, Mohsen Imani Dr. RAW: Towards General High-Level Vision from RAW with Efficient Task Conditioning. NeurIPS 2025
論文の概要

図1:Dr. RAWは様々なタスクにおいて優れた性能を発揮します
標準的なコンピュータビジョンでは、カメラの画像処理パイプライン (Image Signal Processing, ISP) を経由した8ビットのRGB画像が一般的に使用されています。しかし、ISPはブラックボックスであり、トーンマッピングやノイズ除去の過程で、光の線形性やダイナミックレンジといった重要な物理情報を不可逆的に失わせてしまいます。処理前のRAWデータを直接扱えば、この問題は解決しますが、センサーの種類や照明条件によるデータのばらつきが大きいため、非常に扱いづらいという問題があります。
そこで私たちは、新しいフレームワーク 「Dr. RAW」 を提案しました。このフレームワークは、従来のISPを完全にバイパスし、カメラのRAWデータから「直接」、物体検出やセグメンテーションといった高度なビジョンタスクを、極めて効率的に実行するための統合フレームワークです。
この論文で提案された手法・アルゴリズムなど
コンピュータビジョンでRAWデータを扱う手法は、これまで、主に2つに分けることができました。
ISP依存型手法: 既存のISPの一部を最適化、またはニューラルネットワークに置き換えようとするアプローチです。計算コストが高く、最終的な出力画像のボトルネックに縛られます。
End-to-End RAW ネットワーク: RAWデータを直接モデルに入力する手法です。高い性能を出すためには、タスクやセンサーごとに巨大なバックボーンモデルを「フルファインチューニング(全結合学習)」する必要があり、計算コストと汎用性の面で大きな課題がありました。
これらの手法の課題を解決するため、Dr. RAW は以下の3つのコア技術を組み合わせた、パラメータ効率の良い(Tuning-efficient)フレームワークを提案します。
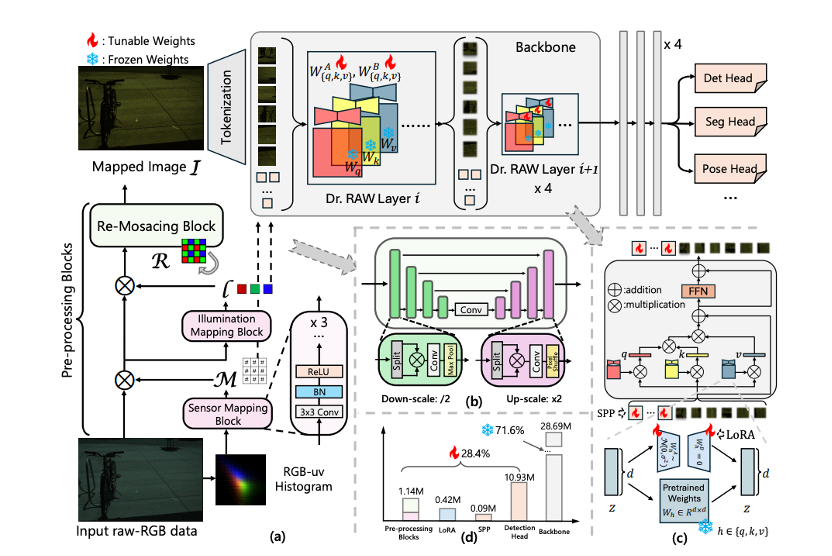
図2:Dr. RAWの全体像
軽量な前処理 (Lightweight Pre-processing): センサーごとに異なるRAWフォーマット(Bayer配列の違いなど)を吸収するため、センサーと照明のマッピング、および「リモザイク (Re-mosaicing)」を行い、データを統一フォーマット(RGBなど)に標準化します。
センサー事前プロンプト (Sensor Prior Prompts, SPP): モデルに対して「どのようなセンサーデータが入力されているか」を認識させるため、RAWピクセル分布の事前知識から生成された学習可能なプロンプト (SPP) をネットワークに注入します。
タスク固有の低ランク適応 (LoRA): 巨大なバックボーンネットワークの重みは凍結 (Frozen) したまま、主要なレイヤーに低ランク行列 (LoRA) のみを導入し、それを更新します。これにより、わずかなパラメータ更新で様々なタスクに適応させることが可能です。
実験結果

図3:複数のタスクにおける可視化結果
私たちは、多様な照明条件を含む NOD データセットを用いて、物体検出、セマンティックセグメンテーション、インスタンスセグメンテーション、パノプティックセグメンテーションの4つの主要タスクで Dr. RAW を評価しました。
結果は非常に優れたものでした。Dr. RAW は、Mask2Former のような完全にファインチューニングされた既存の強力なモデルを上回り、4つのタスクすべてで最先端 (SOTA) の性能を達成しました。 さらに重要なのは、これを全体のわずかなパラメータを更新するだけで実現したという、その圧倒的な効率性です。
まとめ
Dr. RAWは、物理世界を認識するために、重いISPやコストのかかる全モデルのファインチューニングが不要であることを証明しました。事前学習済みモデルにセンサーの事前知識を賢く組み込むことで、最も純粋な光のデータ (RAW) から、堅牢で汎用的な視覚システムを構築することが可能です。
脚注
*1 崔 子藤は、この論文の共同第一著者です。

