【論文紹介】ジョイント 誤差に基づくマルチクラスPU 学習によるオープンセットドメイン適応に関する研究
私たちの論文「Open-set Domain Adaptation via Joint Error based Multi-class Positive and Unlabeled Learning」では、オープンセット ドメイン適応のための新しい理論を提案しました。本論文では、PU 学習とジョイント エラーによるターゲット タスク全体のリスクを厳密に制限するエンドツーエンド アルゴリズムを提案し、幾つかのベンチマークでSOTAパーフォーマンスを達成できました。本稿では著者の張 徳軒がこの研究について解説します。本研究は2024年のThe 18th European Conference on Computer Vision (ECCV 2024)に採択されました。
問題設定
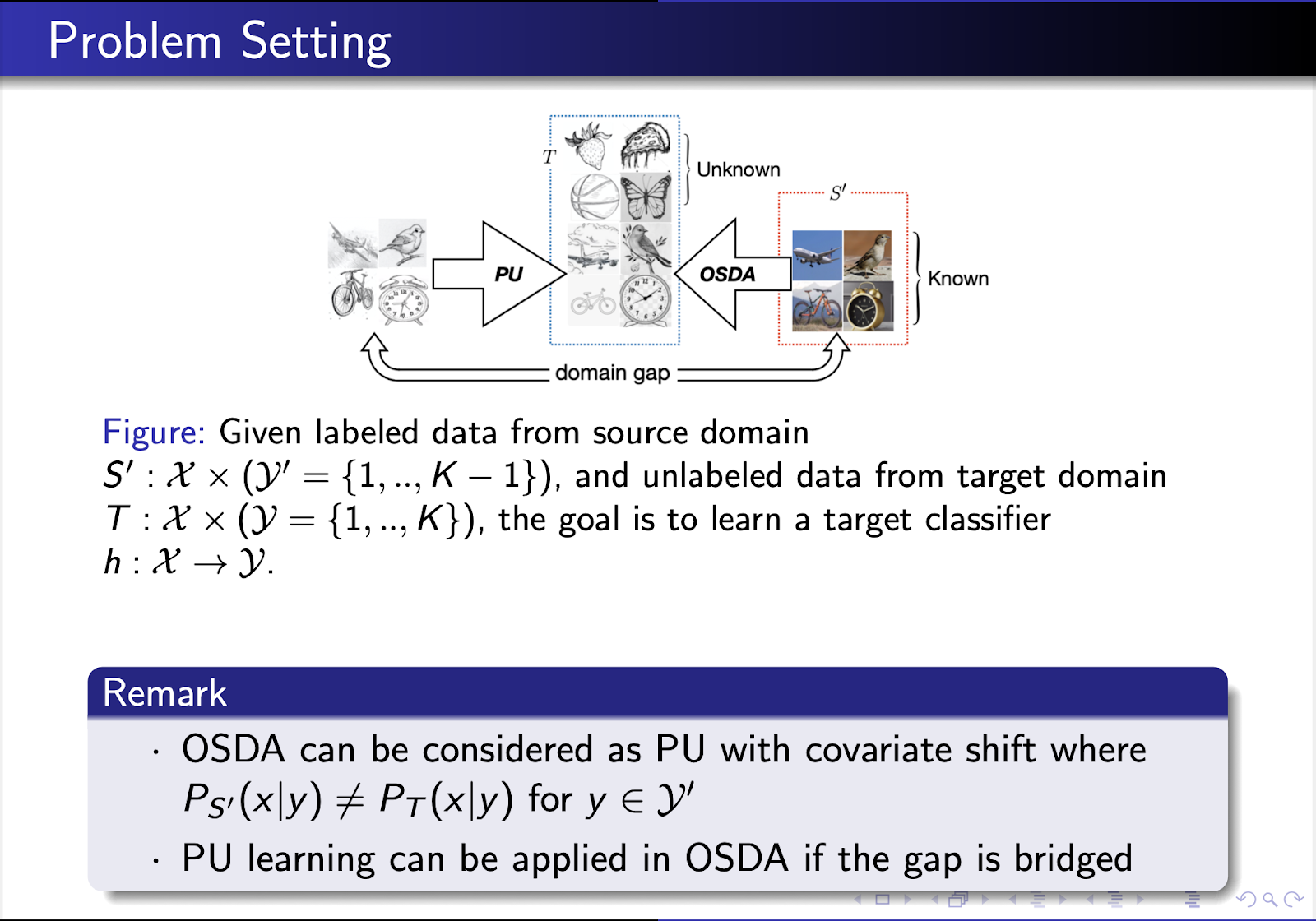
簡単に言うと、OSDA 問題は、ターゲット ドメインのドメイン シフトを伴う PU 学習と考えることができます。つまり、特徴空間のギャップを埋めることができれば、この問題は十分に確立された PU 学習理論によって対処できることになります。 PU 学習は、以前のいくつかの研究で OSDA に採用されています。ただし、それらのほとんどには未知のデータを分離するステップが含まれており、ターゲット ドメインからの真の既知データと推定された既知データの間のギャップにより、非効果的なターゲット エラーに関する目的関数しか得られない可能性があります。
学習理論

本研究ではまず、OSDA における大規模なラベルのシフトによって引き起こされる従来のアルゴリズムの問題に取り組むために、ジョイント誤差に基づいてターゲット誤差の上限を構築します。
[1] で証明されているように、特にラベル シフトが大きい場合 、周辺分布の位置合わせと小さなジョイント誤差の間にはトレードオフが存在します。これは、周辺分布のマッチングに基づく従来のアルゴリズムでは、ターゲット エラーが効果的に制限されないような大きなジョイント エラーが発生する可能性があることを意味します。対照的に、私たちの理論はジョイント誤差の上限を厳密に制限できます。
次に、ドメイン シフトに関係なく、実現可能な仮説 (小さいθ) を提唱します。これは、従来の仮定 (小さいλ) よりも一般的な場合に当てはまります。自明の説明として、小さなジョイント誤差には、両方のドメインの真のラベル付け関数を近似する仮説関数が必要です。ドメインのシフトが大きい場合 、小さなジョイント誤差が保持される可能性は低くなります。対照的に、私たちの仮定では、各近似ラベリング関数が対応する真のラベリング関数に近いことだけが必要です。
PUラーニング


特徴抽出器 g の導入により特徴空間の分布がマッチングされたと仮定することで PU 学習を活用し、ソース ドメイン全体の期待値を推測します。この結果を PU 学習からドメイン適応にさらに拡張するために、ソース ドメインの不一致性の期待値を推定するため未知クラスでの予測不一致性 (Unknown Predictive Discrepancy) を定義します。既知クラスと未知クラスの特徴空間の分布がそれぞれソースとターゲットで一致した場合、ソース ドメイン全体の期待値は、未知クラスの比率が同一という緩めな条件下で、実際のソース ドメインの期待値とターゲット ドメインの未知クラスの予測不一致性によって推測できます。
ソース ドメインでの学習誤差 は PU 学習から得られます。この理論を拡張してさらにソース ドメインでの不一致測定を定式化します。ここで重要な点は、未知のデータを完全に区別することは一般に不可能であるため、既知のデータと未知のデータの特徴分布が相互に重ならないであると仮定しないことです。さら 、既知クラスと未知クラスの精度のバランスをとるため、νT (h)に乗数を導入します。ここで、 νT (h)は、すべてのターゲット データを未知のクラスとして予測しようとします。
アルゴリズム
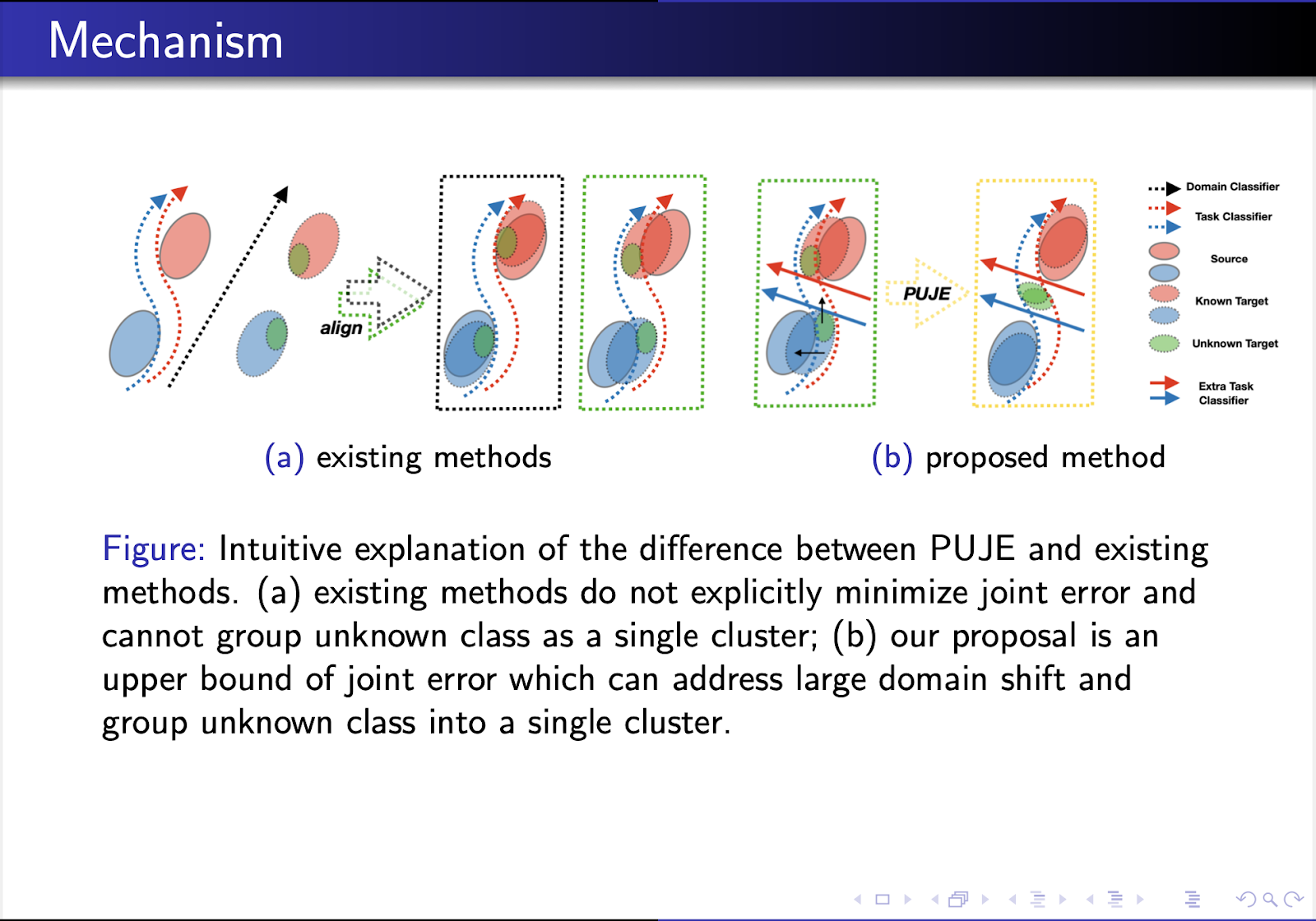
この図は、従来のアライメント メカニズムと比較して、アルゴリズム PUJE の中心的な概念を直感的に説明しています。このメカニズムでは、追加のタスク識別器を導入し、未知のクラスがソースから遠ざけられるように、2 つの識別器間の不一致を最小限に抑えるために特徴抽出器をトレーニングします。これによって、未知クラスのデータ(緑)を単一のクラスターにグループ化できるようになります。
[2] によると、ラベルのないデータの真ん中を突っ切る識別境界線を引く傾向があるエントロピー最小化とは異なり、一貫性正則化は、多様体を意識した決定境界を描くのに役立ちます。図 (b) では、識別器は不一致を最大化しようとしますが、特徴抽出器 g は不一致を最小化しようとします。その結果、ソース クラスターから遠く離れたラベルのないターゲット サンプルが外側に押し出され、分離された未知のクラスターが生じる可能性が高いです。
結果

PUJE アプローチの有効性を直感的に視覚化するために、ベースライン モデル (OSBP、PGL、ANNA) との比較として、ResNet-50 バックボーンを使用した Ar→Cl タスク (Office-Homeデータセット) および Syn2Real-O タスクで特徴を抽出しました。その後、特徴量分布を t-SNE [3] で処理しました。図 で示すように、ベースラインと比較して、私たちの手法 PUJE は、特にドメインのシフトが大きい場合に、ソース分布とターゲット分布の間でより良好な位置合わせを実現できています。ジョイント誤差を用いた敵対的アラインメント メカニズムの効果により、未知のターゲット データ(黒)のクラスターを含む抽出された特徴空間には、より識別的なクラスごとの決定境界を得ることができました。
参考文献
[1] On learning invariant representations for domain adaptation, Zhao et al., ICML 2019
[2] Realistic evaluation of deep semi-supervised learning algorithms, Oliver et al., NeurIPS 2018
[3] Visualizing Data using t-SNE, Maaten & Hinton , JMLR 2008

