【論文紹介】DEJIMA: 大規模な日本語画像キャプション・視覚的質問応答データセットの構築
近年、画像の内容を言葉で説明したり、画像について質問に答えたりする「Vision-and-Language(V&L)」と呼ばれるAI技術が急速に発展しています。こうした技術の性能は、学習に使える画像とテキストのペアのデータセットの質や量に大きく左右されます。ところが、日本語で使える大規模なデータセットはこれまでほとんど存在しませんでした。
今年5月に開催される国際会議 LREC 2026 にて、当研究室から、日本語の画像キャプション(画像の内容を文章で説明したもの)と VQA(Visual Question Answering:画像についての質問に回答するタスク)に使える大規模データセット「DEJIMA」を提案する論文を発表予定です。DEJIMA は、約388万組の画像とテキストのペアを含み、従来の日本語データセットの20倍以上の規模を達成しています。
この記事では、著者の勝部 駿貴(Toshiki Katsube)がこの研究について紹介します。
この記事で紹介する論文
この記事では、以下の論文について紹介します。
Toshiki Katsube, Taiga Fukuhara, Kenichiro Ando, Yusuke Mukuta, Kohei Uehara, Tatsuya Harada. DEJIMA: A Novel Large-scale Japanese Dataset for Image Captioning and Visual Question Answering. LREC 2026 (to appear)
背景:日本語V&Lデータセットの不足
画像を理解して自然な日本語で説明するモデルを作るには、大量の画像と日本語テキストの組み合わせが学習データとして必要です。しかし、既存の日本語V&Lデータセットにはそれぞれ課題がありました。
まず、人手でアノテーション(注釈付け)を行ったデータセットとしては STAIR Captions(約12万画像)や Japanese Visual Genome(約10万画像)があります。品質は高いのですが、規模が限られています。STAIR Captions は MS COCO という英語圏のデータセットに含まれる画像に日本語キャプションを付けたものなので、画像の内容自体は欧米の日常風景が中心です。
次に、英語のデータセットを機械翻訳したものもあります。規模は拡大できますが、翻訳特有の不自然な日本語になりがちで、日本の文化的な文脈も反映されません。
ウェブから自動収集したデータセットもありますが、ウェブ上のalt-text(画像の代替テキスト)にはノイズが多く、画像との対応が正確でないものも少なくありません。
つまり、「大規模」「日本語として自然」「日本文化を反映」「画像との対応が正確」という条件を同時に満たすデータセットがなかったのです。
提案手法:DEJIMAパイプライン
この問題を解決するため、私たちは DEJIMA(DEtection-based Japanese Image-text dataset for Multi-modal Analysis)という3段階のパイプラインを提案しました。
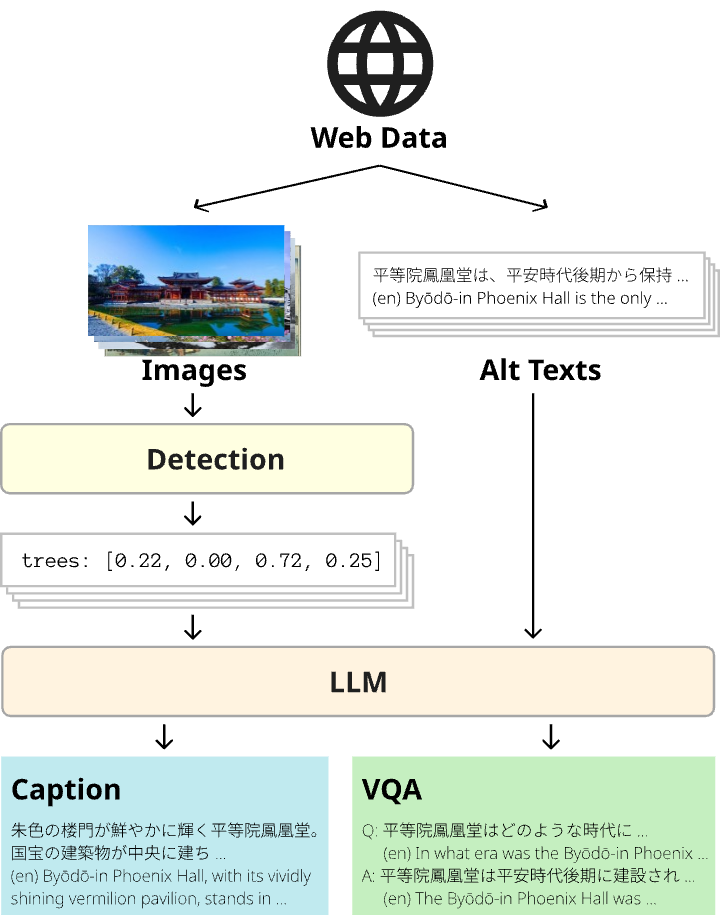
図1:DEJIMAのデータセット構築パイプライン。ウェブ収集、物体検出、LLMによるテキスト生成の3段階で構成される。
Stage 1:ウェブからの画像・テキスト収集
まず、Common Crawl(ウェブ全体のアーカイブ)から日本語のウェブページを抽出し、画像とそのalt-textを収集します。ただし、収集したデータをそのまま使うわけではありません。以下のような多段階のフィルタリングを行います。
- 言語フィルタ:日本語のテキストのみを残す
- 安全フィルタ:不適切なコンテンツを除去する
- 重複除去:同じ画像と同じテキストの組み合わせを排除する
- 意味的整合性チェック:画像とテキストの内容がかけ離れているものを、CLIPモデル(画像とテキストの類似度を計算するモデル)を使って除去する
このフィルタリングの結果、約388万組の画像とalt-textの組が残りました。
Stage 2:物体検出による視覚的証拠の抽出
次に、画像に何が写っているかを客観的に把握するために、物体検出を行います。具体的には、RAM(Recognize Anything Model)を使って画像中の物体を網羅的にタグ付けし、さらに Grounding DINO を使ってそれぞれの物体がどこにあるか(位置情報)を取得します。
この段階で得られた「画像中に何がどこにあるか」という情報が、次のテキスト生成の手がかりとなります。
Stage 3:LLMによるテキスト生成
最後に、大規模言語モデル(LLM)を使って、自然な日本語キャプションやVQAペア(質問と回答の組)を生成します。ここでのポイントは、Stage 1で得たalt-textと、Stage 2で得た物体検出の結果を両方LLMに入力することです。
alt-textには「平等院鳳凰堂」のような固有名詞や文化的な文脈が含まれていることが多く、物体検出の結果には「建物が画面中央にある」「木が左側にある」のような空間的な情報が含まれています。この2種類の情報を組み合わせることで、文化的に豊かで、かつ画像と矛盾のないテキストを生成できるようになります。

図2:DEJIMAデータセットの例。画像に対して、alt-text・物体検出情報を用いることによってキャプションやVQAが生成される。
データセットのバリエーション
入力情報の組み合わせによる効果を検証するため、以下のバリエーションを用意しています。
キャプション:
- DEJIMA-Cap-Simple:フィルタリング後のalt-textそのもの
- DEJIMA-Cap-Refined:alt-textをLLMで洗練したもの
- DEJIMA-Cap-Detection:物体検出結果のみからLLMで生成
- DEJIMA-Cap-All:alt-textと物体検出結果を両方使いLLMで生成
VQA:
- DEJIMA-VQA-Refined、DEJIMA-VQA-Detection、DEJIMA-VQA-All の3種
効率性
手作業でのアノテーションでは、MS COCOの場合に12万枚の画像に対して7万時間以上のクラウドワーカーの作業が必要でした。一方、DEJIMAのパイプラインでは約100万件のキャプションやVQAペアを、NVIDIA A100 GPUで約40時間で生成することができます。
データセットの特徴
規模
DEJIMA-Cap と DEJIMA-VQA はそれぞれ約388万組の画像テキストペアを含んでおり、これは STAIR Captions の約24倍、Japanese Visual Genome の約39倍の規模です。
日本らしさの表現
DEJIMA の大きな特徴は、画像そのものが日本のウェブサイトから収集されたものであるという点です。平等院鳳凰堂や白川郷の雪景色、歌舞伎役者、新幹線と富士山といった日本特有の画像が多く含まれており、キャプションにもそうした文化的な文脈が自然に反映されています。
表現カバレッジ
データセットがどの程度日本の視覚的な世界を網羅しているかを調べるため、日本国内の画像を集めた recruit-jp というデータセットを参照し、CLIP画像特徴量のPCA分布を分析しました。

図3:CLIP画像特徴量のPCA射影。DEJIMAは日本国内の画像分布(recruit-jp)の約79%をカバーしつつ、より広い領域にも分布が広がっている。
結果として、DEJIMA は recruit-jp の視覚領域の約79%をカバーしており、他の既存データセット(STAIR Captions: 43%、Japanese Visual Genome: 44%、MS COCO: 41%)と比べて圧倒的に高いカバレッジを示しました。
人間による品質評価
データセットの品質を評価するため、80名のクラウドワーカーによるペアワイズ比較(2つのデータセットからそれぞれサンプルを提示し、どちらが優れているかを判定)を実施しました。
キャプションの評価
DEJIMA-Cap-All を既存データセットと比較した結果、以下のことが分かりました。
- 画像の日本らしさ:MS COCO Translation に対して83%、STAIR Captions に対して74%の選好率で、DEJIMA が好まれた
- テキストの日本らしさ:MS COCO Translation に対して88%、STAIR Captions に対して78%の選好率
- テキストの自然さ:MS COCO Translation に対して87%の選好率
- 表現の豊かさ:MS COCO Translation に対して92%の選好率
一方、画像とテキストの整合性については、人手でアノテーションされた STAIR Captions のほうが高い精度を示しました(DEJIMA は21%の選好率)。人間が直接画像を見ながら書いたテキストには、正確さの面で自動生成がまだ追いついていない部分もあります。
VQAの評価
VQA についても同様の傾向が見られました。日本らしさや自然さでは DEJIMA が大幅に優れていますが、質問と回答の関連性や回答の正確さでは、人手データセットに及ばない部分もあります。
VLMの学習実験
構築したデータセットが実際にモデルの性能向上に寄与するかを検証するため、LLaVA と同様の2段階学習(Stage 1:キャプションによる画像とテキストの対応付け、Stage 2:VQA によるファインチューニング)を行い、日本語マルチモーダルベンチマークで評価しました。
ベンチマーク結果
2つのベンチマークで評価を行いました。
- JA-VLM-Bench-In-the-Wild:着物や東京タワーなど、広く知られた日本的な被写体に関する質問を扱うベンチマーク。DEJIMA-Cap-Simple と DEJIMA-VQA-Refined の組み合わせが最高スコア(3.12)を達成
- Heron-bench:特定の映画監督や歴史文書、あまり有名でない地域についてなど、より深い日本文化の知識を問うベンチマーク。DEJIMA-Cap-All と DEJIMA-VQA-All の組み合わせが最高スコア(52.26)を達成
Heron-bench での結果は特に注目に値します。既存の最良の組み合わせ(MS COCO Translation + Japanese Visual Genome)のスコアは33.94だったのに対し、DEJIMA-Cap-All + DEJIMA-VQA-All は52.26と大幅な向上を見せました。alt-textによる文化的文脈と物体検出による視覚的根拠の両方を活用することが、深い文化理解に不可欠であることを示しています。
VLM出力の人間評価
自動評価に加え、VLMの出力に対しても人間による評価を実施しました。DEJIMA-Cap-All & DEJIMA-VQA-All で学習したモデルの出力は、既存データセットで学習したモデルと比べて、日本語の自然さ(92%の選好率)や回答の正確さ(77%の選好率)で優れていることが確認されました。

図4:学習したVLMの出力例。「背景に見える山の名前は?」という質問に対し、DEJIMAで学習したモデルは正しく「羊蹄山」と回答できている。
今後の展望
DEJIMA は、日本語のV&Lモデルの発展に向けた大規模かつ高品質なデータセットです。ウェブからの大規模収集、物体検出による視覚的根拠の付与、LLMによる自然な日本語テキストの生成という3段階のパイプラインによって、規模・日本語としての自然さ・文化的な豊かさを両立しています。
今回提案したパイプラインは言語に依存しないため、日本語以外の言語にも応用が可能です。今後は、さらなるデータ規模の拡大や、画像とテキストの整合性のさらなる向上に取り組んでいく予定です。
データセット、構築パイプラインのコード、学習・評価コードはすべて公開しています。商用利用も可能なライセンスのもと公開していますので、研究だけでなく産業応用にも活用していただけます。詳細はプロジェクトページをご覧ください。

