【論文紹介】A Theory of Learning Unified Model via Knowledge Integration from Label Space Varying Domains
「ドメイン適応(Domain Adaptation)」は、十分な教師情報がない目標のドメインでうまく働くモデルを、十分な教師ラベルを持つ別のドメインの情報を活用して作成する手法です。この手法は目覚ましい成功を収めていますが、既存のドメイン適応システムでは、複数のソースドメインから学習した知識を統合することを目指す場合に、問題設定を簡略する必要があり、現実問題にうまく対応できませんでした。2025年6月にアメリカのナッシュビル、Music City Center にて開催された国際会議 The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) 2025 では、実世界でしばしば出現する「ソースフリー」のシナリオに対応するためのアルゴリズムを提案する論文 “A Theory of Learning Unified Model via Knowledge Integration from Label Space Varying Domains” を発表しました。この成果により、将来的には、エッジデバイスなどで蓄積された知識を統合し、より性能の高いモデルを効率的に構築出来る事が期待されます。
この記事では、著者の張 徳軒(Dexuan Zhang)が、この論文について解説します。
この記事で紹介する論文
この記事では、以下の論文について紹介します。
Dexuan Zhang, Thomas Westfechtel, Tatsuya Harada. A Theory of Learning Unified Model via Knowledge Integration from Label Space Varying Domains. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025
論文の概要
既存のドメイン適応システムは、システムを活用する際に新しいクラスが出現する実世界の問題、特に、「少数のラベル付きターゲットデータが与えられているにもかかわらず、複数のソースドメインがラベル空間を共有せず、ソースフリーである(学習に用いたデータへのアクセスができない)」シナリオには適用することが困難です。これに対処するため、我々は挑戦的な問題である「マルチソース半教師ありオープンセットドメイン適応」について検討し、結合誤差を介した学習理論を提案することで、強いドメインシフトに効果的に対処するアルゴリズムを提案しました。このアルゴリズムをソースフリー問題に対応させるために、計算効率が高くアーキテクチャに柔軟なアテンションベースの特徴生成モジュールを導入します。様々なデータセットを用いた広範な実験により、提案アルゴリズムがベースラインに対して大幅に改善されることを実証しました。
この論文で提案された手法・アルゴリズムなど
問題設定
一般的に、ラベル付きサンプルが十分に存在する特定の分布で学習された教師あり学習のモデルは、データの分布が異なる新しい環境に適用しようとする場合、汎化に失敗することがよくあります(このような分布の違いを、「ドメインシフト」と呼びます)。ドメイン適応(DA)[1] アルゴリズムは、統計的学習または敵対的学習アプローチを用いて「ドメイン不変」の特徴空間を学習することにより、元々のドメインと新しいドメインのデータ分布を整合させることで、ドメインシフト問題に対処するアプローチです。元々のドメインのことをソースドメイン、新しいドメインのことをターゲットドメインと呼びます。
ドメイン適応アルゴリズムは目覚ましい成功を収めていますが、複数のソースドメインから学習した知識を統合することを目指す場合、実際のアプリケーションでは問題設定を緩和する必要があります。従来のDA手法は、複数のソースドメインが異なるラベル空間を持つケースをほとんどカバーできず、対応する学習理論はまだ提案されていませんでした。各ソースで異なるネットワークアーキテクチャとラベル空間でモデル学習を行う可能性があり、ソースフリーの状況まで考えた場合、解決策は限られてしまいます。この研究では、図1に示すように、さまざまなラベル空間を備えた、困難なマルチソースの半教師ありオープンセットドメイン適応問題(the multi-source semi-supervised open-set DA (MSODA))に取り組みました。
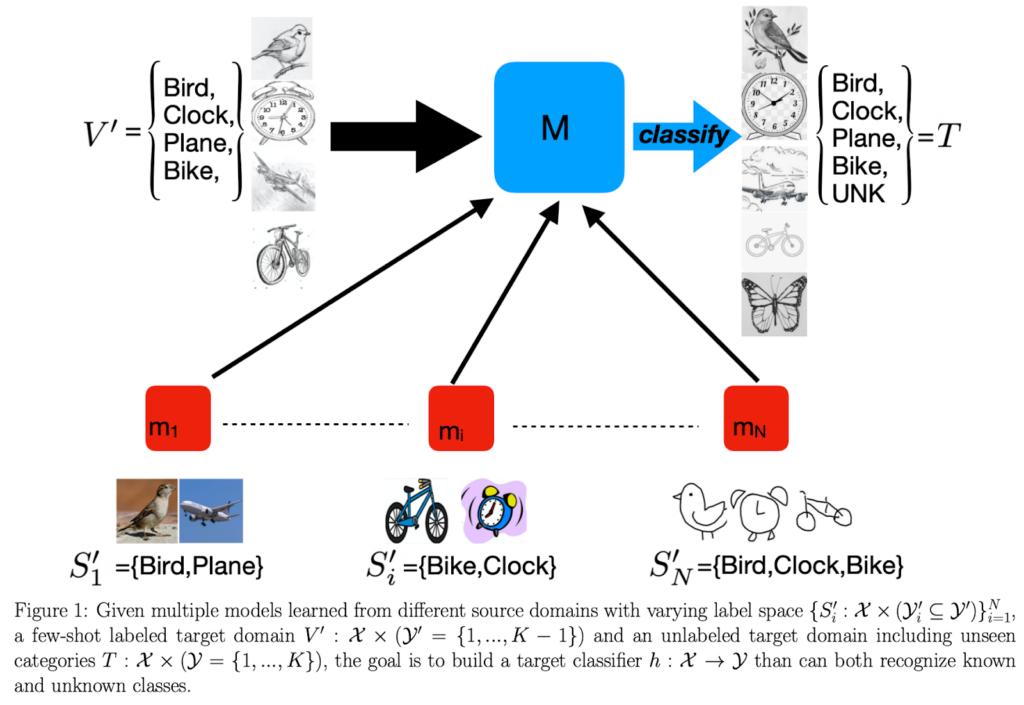
図1 マルチソースの半教師ありオープンセットドメイン適応問題(MSODA)の概念
学習理論
「教師なしドメイン適応(Unsupervised Domain Adaptation, UDA)」は、分布のアライメントを通じて、ターゲットドメインのラベルなしデータに効果的に適応する手法です。しかし、ドメインシフトが大きい場合、識別クラス境界の学習が困難になることがあります。その理由の1つは、多くの手法が、「結合誤差」(図2の Preliminary 1 に示す網掛け部分)が小さいと仮定してこれを無視し、領域不変表現の学習に重点を置いていることです。
従来の方法は、厳密な理論的保証が欠如しており、大規模なドメインシフトに対応できません。その限界を克服するために、我々は、大規模なドメインシフトで実行可能な新しい学習理論を提案しました。私たちは以前に発表した論文 [2] での提案内容を踏まえ、MSODAにおいて、ターゲットの誤差の上界が、各ドメインの相互結合誤差の上限によって定まることを、Theorem 1 のように示しました。ラベルありデータに対する分類誤差だけではなく、ドメイン間の相互分布シフトを効果的に削減し、ラベル付けされたドメインとラベル付けされていないドメインを一緒にアライメントすることができます。この理論は、従来の理論と違って、結合誤差が小さいという仮説に基づいてないため、ドメインシフトが大きい場合においても成立します。

図2 提案した学習理論
不一致ラベル空間における推論
DAにおいて、ターゲットドメインに「未知のクラス」が含まれる場合を、open-set問題と言います。この不一致ラベル空間における推論問題は、ターゲットドメインのドメインシフトを伴う PU 学習(Positive-Unlabeled 学習)と考えることができます [3]。従って、Theorem 1で必要なソースドメイン全体での期待値を、図3の式 (2) のように推測できます。PU 学習からドメイン適応にさらに拡張するために、未知クラスでの「予測不一致性 (Unknown Predictive Discrepancy) 」を定義します。既知クラスと未知クラスの特徴空間の分布がそれぞれソースとターゲットで一致した場合、ソースドメイン全体の期待値は、未知クラスの比率が同一という緩めな条件下で、実際のソースドメインの期待値とターゲットドメインの未知クラスの予測不一致性によって推測できます。

図3 「未知のクラス」が含まれる問題について、PU学習とみなすことができる
ソースフリーの知識移転に向けて
ソースフリードメイン適応 (Source-Free Domain Adaptation, SFDA) では、プライバシー保護等の観点から、ソースデータにアクセスができない場合を考えます。ドメイン適応にソースデータを用いず、事前学習済みのソースモデルだけを使います。既存のSFDA研究は、一般的に、データ中心法とモデル中心法に分類できます。モデル中心法は自己教師などの技術を採用し、データ中心法は画像ベースの再構成に重点を置いています。本研究では、新しいアテンションベースの特徴生成アルゴリズム(Attention-based feature generation, AFG)を提案します。この手法により、ラベルのないターゲットデータをアライメントするための情報(アンカー)を、ソースモデルに手を加えることなく、高効率に生み出すことができます。

図4 ソースフリーに対応するために、アテンションベースの特徴生成アルゴリズムを提案
実験結果
表1に示すように、1 ショット/3 ショットのラベル付きターゲットデータ (クラスあたり 1/3 サンプル) が与えられるという設定で、ソースデータが利用可能な場合と不可能な場合とに、提案手法(UMとUM+AFG)は従来手法の結果を一貫して上回りました。ベンチマークデータセットである Office-Home と DomainNet において、DA において持ちいられる評価指標である HOS の値を大きく向上させることがわかります。さらに、AFG を使用すると、ターゲットモデルは事前トレーニング済みのソースモデルとは異なるアーキテクチャをバックボーンとして使用できます。そのため、ソースモデルのアーキテクチャによってパフォーマンスが大きく制限されるモデル中心の手法とは異なり、ViT などの高度なアーキテクチャをターゲットモデルのバックボーンとして活用することで、パフォーマンスの更なる向上を期待できます。表2では、ターゲット バックボーンを ViT-B/16 に変更すると、ソースフリー条件での HOS スコアが高く、ResNet-50でソースデータを使用する結果よりも優れていることがわかり、AFG の利点が明らかになっています。

表1 実験結果
異なるアプローチの有効性を直感的に視覚化するために、ベースラインモデルと提案モデルから、Artタスク(Office-Home)とRealタスク(DomainNet)で特徴を抽出しました。特徴分布はその後、t-SNEで処理しました。図5の (a)-(h) が示すように、ベースラインと比較して、提案手法UMは、特にドメインシフトが大きい場合に、ソースとターゲット分布間のより良いアライメントを実現します。結合誤差の敵対的アライメントメカニズムの恩恵を受けることで、未知のターゲットデータのクラスター(緑)を含む抽出された特徴空間は、より識別的なクラスごとの決定境界を得られます。さらに、図5の (i)-(j) が示すように、提案手法はターゲットでの未知クラスの割合の変化などに対して、ロバストな性能を示し、一貫して安定的な学習結果が得られます。

図5 アプローチの有効性の可視化
結論
本研究では、ラベル空間に一貫性のない複数ソースの場合における半教師ありオープンセットドメインシフト問題に対し、結合誤差とマルチクラスPU学習に基づく新たな学習理論を導入することで対処しました。本手法は、計算効率と信頼性の高い性能を兼ね備えたアテンションベースの特徴生成によって、ソースフリーシナリオにも汎用化されます。複数のドメイン適応ベンチマークを用いて広範な実験を実施しました。本モデルは、ソースデータの種類に関わらず、ベースライン手法と比較して最高の性能を達成し、提案手法の有効性を実証しました。
「参考文献」
[1] Shai Ben-David, John Blitzer, Koby Crammer, AlexKulesza, Fernando Pereira, and Jennifer Vaughan. A theory of learning from different domains. Machine Learning, 2010.
[2] Dexuan Zhang, Thomas Westfechtel, and Tatsuya Harada. Unsupervised domain adaptation via minimized joint error. Transactions on Machine Learning Research, 2023.
[3] Dexuan Zhang, Thomas Westfechtel, and Tatsuya Harada. Open-set domain adaptation via joint error based multi-class positive and unlabeled learning. European Conference on Computer Vision, 2024.

