【研究紹介 #01】“自ら学び習熟するロボット”の実現に向けた強化学習の活用

原田・髙畑・長・椋田研究室の研究を紹介するインタビュー連載。第1回となる今回は、ロボットとAIの融合領域を研究する長 隆之(おさ たかゆき)先生に話をききました。
長 隆之
東京大学大学院情報理工学系研究科付属 情報理工学教育研究センター
知能社会創造研究部門 准教授
ロボットの制御や自動化を支える技術「強化学習」

―まずは、先生の研究テーマを教えてください。
長:わたしが取り組んでいるのはロボットとAIの融合領域で、「ロボットをどう動かすか」、そしてそこに「どうAIを組み込むか」が中心のトピックとなっています。
中でも主な研究対象は、AI技術を支える機械学習のひとつ「強化学習」です。強化学習とは、試行錯誤の経験から自動的に最適な戦略を学びとる学習のこと。
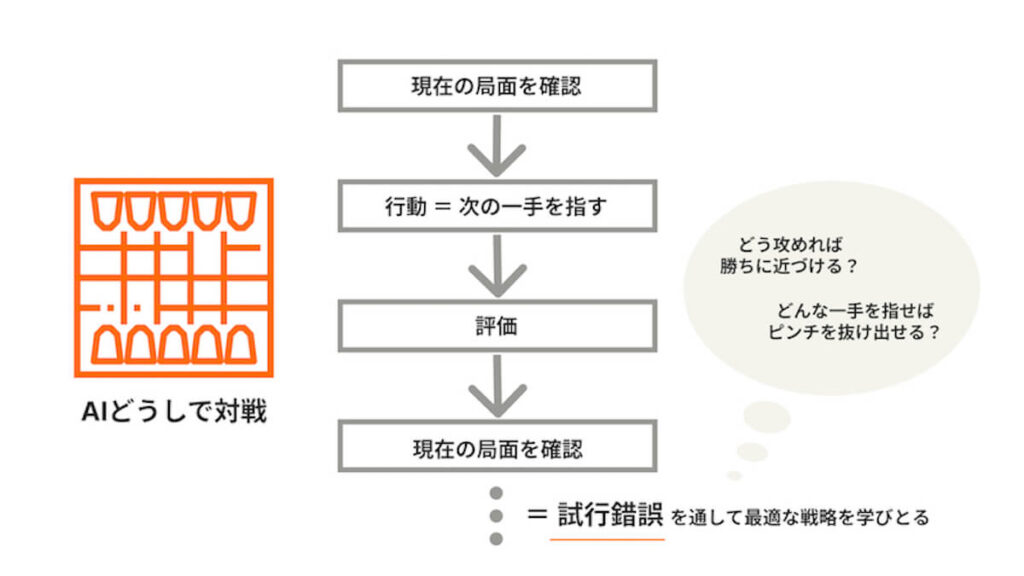
将棋や囲碁のプロフェッショナルにAIが勝利して話題になりましたが、ここでAIがよりよい一手を選択することを支えているのが強化学習なのです。
強化学習を適用することでロボットが試行錯誤を通して歩けるようになったり、手でさまざまなものを操れるようになったり……それらを当たり前のこととして実現するための研究をしています。
―「“ロボット×AI”による自動化」を研究テーマに選んだのはなぜですか?
長:修士課程にいた頃に、「手術ロボットの自動化」をテーマとする研究を目にしたことが大きなきっかけです。その研究では、人が実演した動きをモデルにロボットが “糸を結ぶ” 動作を自動で行っていて。仮に糸の位置が少しずれたとしても、ロボット自身で自動的に軌道修正をして、正しく動作を完了できていたんです。
そんな様子を見て、単純にすごいなと。私もこのような研究をやってみたいと感じたことを機に、学習や自動化というテーマに惹き込まれていきました。
ロボット “ならでは” の学習のあり方を追い求めて
―今取り組んでいる研究内容を、くわしく教えてください。
長:「強化学習を実社会に適用すること」をひとつの大きな課題として、企業さまと共に研究を進めています。
例えば本田技術研究所さまと取り組んでいるのは、「多指ハンド」と呼ばれる指がたくさんあるロボットに、器用な動きを強化学習で身につけさせる研究です。
ものをしっかりと握ったり、持ち替えたりする動きを多指ハンドに行わせ、狙った動きになったかどうかを人間が評価=点数化。その点数が高くなるように試行錯誤を繰り返させていきます。
また小松製作所さまとは、ショベルカーやブルドーザーの自動化に強化学習をどう活かすか、というテーマで研究を行ってきました。
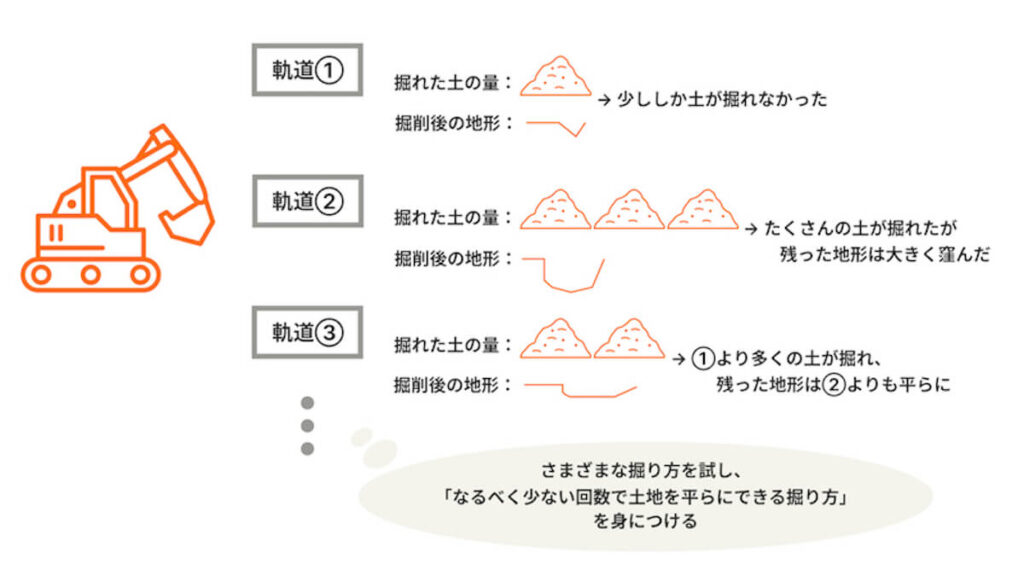
ターゲットとなる土地をなるべく効率よく平らにするために、さまざまな方法での掘削を建機に試させて。「どれだけ多くの土が掘れたか」「掘った跡が平らになったか」などの評価を行いながら、適切な動きを学習させています。
―研究の醍醐味は、どんなところにあると思いますか?
長:「いろいろな動きを試して身につける」という強化学習のあり方は、人間が動作を身につけるときに自然と行うアプローチと似通っていると思っていて。
わたしが強化学習のアルゴリズムを考えるときは、自分の子どもがおもちゃの遊び方を身につけていく様子を見ながら「人間はどうやって学習しているんだろうか」と思いを巡らせることが出発点になっているんです。
ただ一方で、人間とロボットとでは脳みその構造も違うため、人間が行う学習が必ずしも “ロボットにとって最適な形” だとは限りませんよね。人間はとても効率よくいろいろなことを学んでいますから、全く同じことをロボットにさせるのは難しい、とも言えます。
そんな前提をふまえて、ロボット “ならでは” の学習のあり方を数式で表現してプログラムに落とし込み、実行に移して試行錯誤する。その過程こそが研究の難しさであり、醍醐味でもあるのかなと思っています。

強化学習の適用で、みんなが幸せに暮らせる便利な社会を“当たり前”に
―研究において、今後チャレンジしたいことを教えてください。
長:身のまわりでロボットが使われたり、ショベルカーやブルドーザーが自動で動いたり……そんな出来事が近い将来 “当たり前” になるように。研究を通して「強化学習を本当に世の中で使える技術にする」ことに挑戦し、貢献していきたいと思っています。
―実現に向けて、どんなことが課題になると思いますか?
長:実世界とシミュレーションのギャップ、でしょうか。
最適な掘削の動きを学ぶためにショベルカーでひたすらに地面を掘り続けていては、いつかはショベルカーが壊れてしまいますから、強化学習ではシミュレーションの世界で試行錯誤をさせます。ただ、シミュレーションで得た経験をそのまま現実の世界に移して、同じように動かすことはとても難しいんですよね。
研究している技術を現実のシステムに載せるためには、この実世界とシミュレーションのギャップを縮めなければいけない、というのが研究者みんなで共有している課題感です。
―先生が考える、その解決策とは?
長:“子どもと大人の違い” がヒントになるのではないかと、わたしは考えています。子どもが何度も何度も練習しないとできなかったことでも、大人は人がやっている様子を見て2,3度試すだけで習得できた、というケースは多くあります。
ここでの子どもと大人の最も大きな違いは、肉体的なものというよりは “経験” なのかなと。では、その経験をどう活用すれば2,3度の試行錯誤で新たなスキルを学習できるのか、というテーマに挑戦したいなと思っています。
すでにそういった研究分野も存在しますが、まだ現実のシステムに適用できるレベルには至っていないため、わたしなりの方法でこれから取り組んでいければと思います。
| 【この研究テーマに応用される知識】 ■微分積分 AIと言っても、その本質は高校で学ぶような「関数」であることが多く、微分積分が頻繁に登場します。 ■確率論 強化学習では「このような動作をすると、大体このくらいの点数が得られるはずだ」という予測を、高校数学の確率論で学ぶ「期待値」で表現します。 高校で学ぶ数学は、大学に入ってから使う数学の基礎になるものです。基本的な部分をしっかり勉強しておくと、後で役に立つのではないかと思います。 |

取材・文・写真=原田・髙畑・長・椋田研究室広報担当

