【論文紹介】Intend to Move: A Multimodal Dataset for Intention-Aware Human Motion Understanding
Embodied AIや人間行動理解の分野において、人間がどのように動き、周囲とどう関わるかを理解することは、AIシステムが人間と共生し、協調するために不可欠な技術です。2025年12月にアメリカのサンディエゴで開催された機械学習のトップカンファレンス Neural Information Processing Systems (NeurIPS) 2025では、人間の動作の背後にある「意図」に着目した大規模マルチモーダルデータセット「Intend to Move (I2M)」を提案する論文 "Intend to Move: A Multimodal Dataset for Intention-Aware Human Motion Understanding" を発表しました。
この成果により、AIは人間の動作を単なる関節の動きとしてだけでなく、「なぜそう動くのか」という意図と紐づけて学習することが可能になります。将来的には、人間の意図を汲み取って先回りして手助けするロボットや、高度な対人インタラクションを行うAIの実現に役立つ可能性があります。
この記事では、著者の馬上凌(Ryo Umagami)が、この論文について解説します。
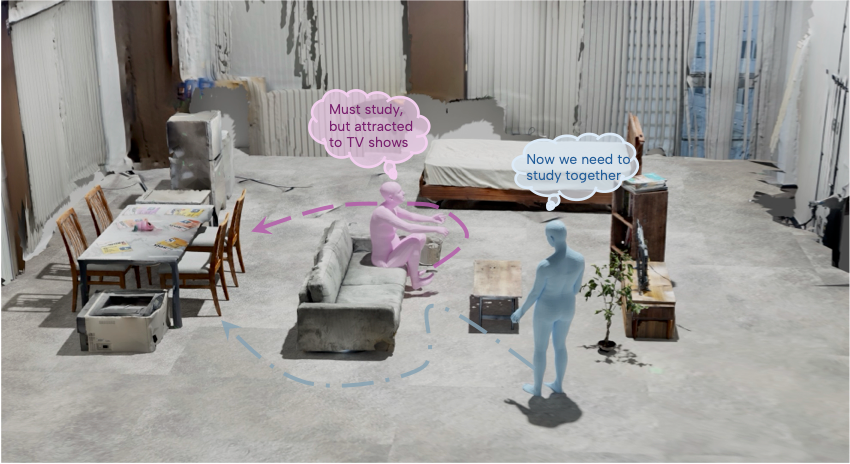
図1: 提案した「Intend to Move」データセットの概要。
実世界の複雑な環境の中で、人間の動作と「なぜそうするのか (意図)」が紐づけられている
この記事で紹介する論文
この記事では、以下の論文について紹介します。
Ryo Umagami, Liu Yue, Xuangeng Chu, Ryuto Fukushima, Tetsuya Narita, Yusuke Mukuta, Tomoyuki Takahata, Jianfei Yang, Tatsuya Harada. Intend to Move: A Multimodal Dataset for Intention-Aware Human Motion Understanding. Advances in Neural Information Processing Systems (NeurIPS), 2025
論文の概要
これまでのAIによる人間の動作モデリングは、主に「どう動いているか (What/How)」に焦点が当てられてきました。具体的には、関節の軌跡や姿勢の変化を物理的に捉えることです。しかし、私たち人間が動くとき、そこには必ず「なぜ動くのか (Why)」という理由が存在します。「喉が渇いたから」水を飲むのか、「部屋を片付けたいから」ボトルを片付けるのかによって、同じ「ボトルを掴む」という動作でも、その文脈や後の行動は異なります。
既存のデータセットは、実験室のような何もない空間で、「歩く」「座る」といった短い動作を記録したものが主流でした。これでは、AIが人間の意図を汲み取ったサポートや、曖昧な状況での適切な判断を学習することが困難です。
そこで本研究では、人間の「意図」と「動作」を紐づけ、リアルな家庭環境下でのインタラクションを含んだ新しい大規模データセット「Intend to Move (I2M)」を構築・公開しました。
この論文で提案された手法・アルゴリズムなど
1. 意図 (Intention) の言語化
I2Mデータセットの最大の特徴は、すべての動作に対して「テキストによる意図の説明」が付与されていることです。従来の「冷蔵庫を開けて飲む」といった動作描写ではなく、「喉が渇いた (The person is thirsty)」 といった動機そのものが記述されています。これにより、AIは動作の表面的な形だけでなく、その背後にある目的を学習することが可能になります。
2. 豊富なマルチモーダルデータ
リアルな家庭環境 (10.1時間分、215シーケンス)において、2人の人物によるインタラクションを、以下のように多様なモダリティで収録しています。
- RGB-D映像: 4視点からの同期されたカラーおよび深度映像。
- 3D人体動作: SMPLモデルを用いた高精度な3Dポーズデータ。
- 3Dシーン情報: 環境全体の点群データ (Point Cloud)および3Dメッシュ。
- 意図テキスト: 各フレームに同期した意図の言語アノテーション。
これらのデータがすべて同期されているため、画像、3D空間、言語、動作を統合的に扱う研究に適しています。

図2: I2Mに含まれるデータの種類。(a) 3D動作、(b) マルチビューRGB-D映像、(c) 3Dシーンの点群とメッシュ、(d) 意図テキスト
3. 提案手法
I2Mデータセットの有用性を検証するため、意図に基づいて動作を生成するベースライン手法も提案しました。具体的には以下の図にあるような、AffordMotion (Wang et al., CVPR 2024)を拡張した拡散モデルベースの手法です 。このモデルは、過去の動作やシーンの点群情報に加え、「意図テキスト」や「RGB画像」を条件として入力することで、周囲の環境と本人の意図の両方を考慮した自然な未来動作を生成します。
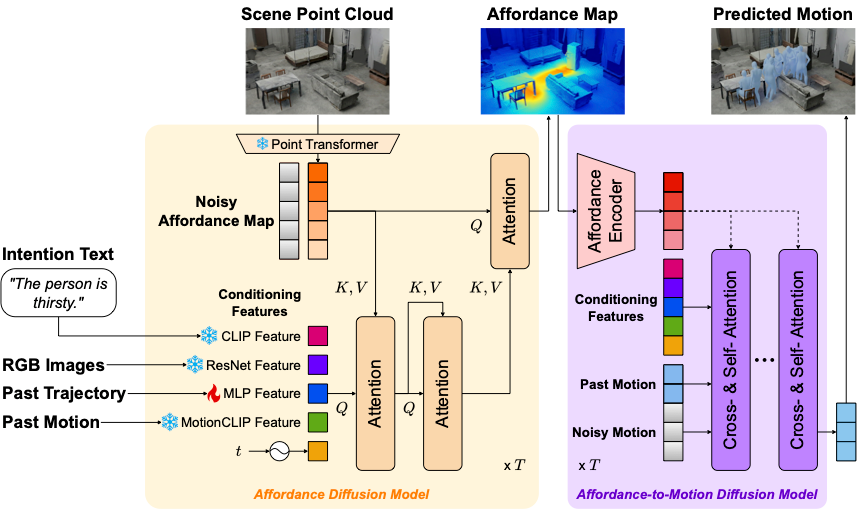
図3: 提案手法のパイプライン
実験結果
私たちはI2Mデータセットを用いて、「テキストで記述された意図」から人間の将来の動作を生成する実験を行いました。
その結果、提案モデルは与えられた意図を汲み取り、文脈に沿った適切な動作を生成することに成功しました。例えば、「パートナーから物を受け取る」という意図に対しては相手に近づいて手を伸ばす動作が、「弁当を取り出したい」という意図に対しては冷蔵庫に向かって手をかける動作などが生成され、高レベルな「意図」が具体的な「動作」として反映されていることが確認できました。

図4: 意図に基づいた動作生成の例。濃いピンクは入力モーション、薄い紫は生成されたモーションを示す。(a)「パートナーから物を受け取る」、(b)「弁当を取り出したい」、という意図に対し、適切な動作が生成されている。
今後の展望
Intend to Move (I2M)データセットは、AIが単に動きを模倣する段階から、その背後にある「理由」を理解する段階へと進むための基盤となります。このデータセットが活用されることで、ユーザーの意図を察してサポートするロボットや、人間とスムーズに協調できるAIなど、より人間に寄り添う技術の発展が期待されます。

