【論文紹介】FUSE: A Hybrid Speech Enhancement System for Real-World Noisy Environments
騒音の大きな場所で、電話に出ようとしているところを想像してみてください。
そのような環境でも、通話の相手は、あなたが何を喋っているか理解してくれるでしょう。しかし、録音して後から聞き返してみると、とても酷い音になっているはずです。背景の音がうるさいですし、聞き取りにくい単語があり、音が変に歪んでいるかもしれません。“Speech Enhancement (音声強調)” の目的は、そのような音を、コンピュータによって綺麗にする (clean up) ことです。
私たちは、様々な言語や、多様なノイズに対応し、さらに、低品質な録音にも対応できる「ユニバーサル」な音声強調を行うことを目標に、「FUSE」というシステムを開発しました。今年6月にオランダのロッテルダムで開催された国際会議 Interspeech 2025 の URGENT 2025 Challenge に参加したこのシステムは、総合で3位となり、リスニング品質でトップレベルの成績を納めました。
このシステムを提案した論文 "FUSE: Universal Speech Enhancement using Multi-Stage Fusion of Sparse Compression and Token Generation Models for the URGENT 2025 Challenge" について、著者である Nabarun Goswami が解説します。
この記事で紹介する論文
この記事では、以下の論文について紹介します。
Nabarun Goswami, Tatsuya Harada. “FUSE: Universal Speech Enhancement using Multi-Stage Fusion of Sparse Compression and Token Generation Models for the URGENT 2025 Challenge”, Interspeech, 2025
取り組みの概要
私たちが参加した URGENT 2025 は、以下のような「実世界の条件」でシステムがきちんと動作するかを評価するためにデザインされました。
- 多言語(英語、ドイツ語、フランス語、スペイン語、中国語、そして日本語(テスト時のみ))
- 様々なノイズ(交通騒音、風切り音、クリッピング、帯域幅制限、パケットロス、コーデック、など)
- 録音品質やサンプリングレートの違い
私たちが主に取り組んだのは、以下のような疑問でした。
このような条件すべてに対応でき、しかも、クリーンかつ自然な音をうまく出せるような単一のシステムを構築できるだろうか?
既存の手法のほとんどは、「クリーン」「自然」のいずれかには優れていても、両方は満たしていない傾向にあります。
この論文で提案された手法・アルゴリズムなど
これまでの手法の課題
Speech Enhancement のモデルは、大きく2つのグループに分けることができます。
1)識別モデル
ノイズの載った音から、クリーンな音を、直接マッピングします。ノイズを除くことに長けており、高い SDR (Signal-to-Distortion Ratio) を達成できます。しかし、機械的で、過剰にフィルターをかけたような音になりがちです。
2)生成モデル
「自然な音声がどのように聞こえるべきか」をモデル化します。自然で、高品質な音を出力できますが、ハルシネーションを起こして内容を変てしまったり、元々の信号を歪めてしまったりすることがあり、SDR が低くなってしまいます。
つまり、「クリーンさ」と「自然さ」は綱引きの関係にあり、同時に達成するのが難しいのです。
私たちは、このどちらかを選ぶのではなく、両方を達成するべく、FUSE を開発しました。
提案手法「FUSE」の全体像
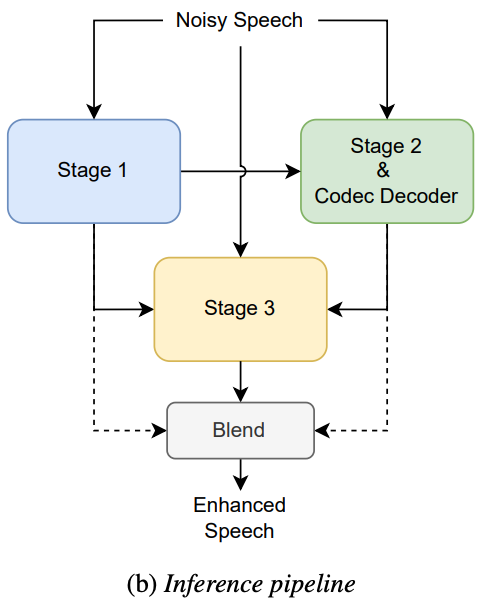
FUSE は、3ステージからなるパイプラインを持ちます。
第1ステージ: 強力なノイズ除去器(識別モデル)
第2ステージ: 高品質な音声強調器(生成モデル)
第3ステージ: ノイズの載った音(入力)と、第1ステージ、第2ステージをうまく融合させるためのモデル
FUSE の名称は、この最終ステージから来ています。各ステージの強みを融合する(Fuse は英語で「融合する」という意味)ことで、技術的に正確で、聴いていて心地よい音声を出力するのです。
FUSE の動作についての直感的な解説
FUSE の動作について、直感的にはどのようなものかをご説明します。
第1ステージ:クリーンにする
SCNet (Sparse Compression Network) というモデルを出発点としました。これは元は音源分離のために作られたモデルで、これを音声強調に応用しています。
私たちはオリジナルのモデルを改造して(リカレント層を Conformer 層に置き換えました)、より並列計算しやすく、短期的・長期的なパターンの両方をうまく補足できるようにしました。
このステージでは、モデルは「再構成品質」を良くするように最適化されています。厳密かつ数値的に、出力が「クリーンな音声」に可能な限り近づけているのです。

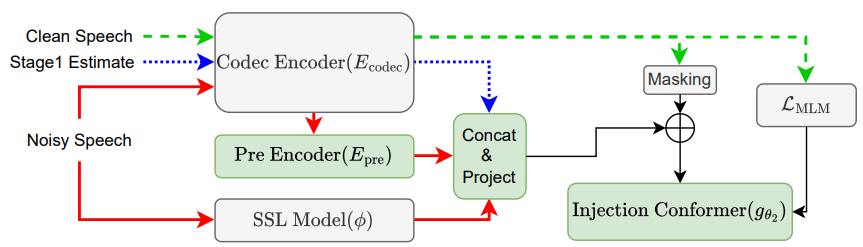
第2ステージ:自然に聴こえるようにする(トークンベースの生成モデル)
次のステージでは、私たちがこれまでに発表した成果である Ingection-Conformer を参考として生成モデルを用意しました。これは EDM-TTS という音声合成の手法に使われたものですが、ここでは音声強調に応用しています。
ニューラルなオーディオコーデックである DAC-44kHz に、クリーンな学習用オーディオを通します。このコーデックは、入力波形を離散的なトークンの列に変換します。このトークン列のいくつかをマスクして、マスクされた内容を予測するように学習を行います。つまりは、Masked Language Model (MLM) のオーディオ版です。このモデルは、ノイズの載った音や、第1ステージの予測結果、そしてノイズの多い入力のコーデック特徴量などを条件に使って学習します。
このステージは、SDR を直接に最大化しようとするのではなく、その代わり、リアルで、自然に聴こえるコーデックトークンを予測しようとします。これにより、第1ステージで過度になめらかになっている「豊かさ」、「高音域」、そして「より自然な声の響き」を回復します。
第3ステージ:全てをスマートに融合する
ここまでで、3つの信号が得られています。
- ノイズの多い入力
- 第1ステージの出力(クリーンだが、ややドライ)
- 第2ステージの出力(自然だが、SDR でやや劣る)
第3ステージでは、SCNet と同様のスタイルのモデルを使い、この3つの信号を入力として、以下の学習を行います。
時間周波数領域の各領域において、第1ステージ、第2ステージ、そしてオリジナルであるノイズの多い信号を、どの程度信用すべきか?
私たちは、複数の損失関数を組み合わせて、融合モデルを学習します。
- 再構成ロス(メルスペクトログラムと SI-SDR(Scale-Invariant Signal-to-Distortion Ratio、スケール不変な SDR))
- 話者の類似性
- 音素特徴量のマッチング
- UTMOS に基づいた損失
- UTMOS は、MOS を予測するモデルで、MOS は「平均オピニオン評点(Mean Opinion Score)」という、音声の品質を主観で評価する指標。
このとき、第1・第2ステージのモデルの内容は変更せず(frozen)、融合ネットワークのみ学習します。
この学習により、信号レベルの正確性と、聴いたときの品質とのバランスを取ることができます。
Challenge (コンペティション)の結果
私たちは、URGENT 2025 のデータセットで、FUSE の性能を評価しました。データセットは、以下のような内容です。
- 学習データ:2,500時間の音声(5言語)、550時間のノイズ、60,000 の室内インパルス応答
- 帯域幅制限、クリッピング、コーデック、パケットロス、そしてシミュレーションされた風切り音を含む「歪み」
性能評価のためには、3つの主なセットがあります。
- Validation set (シミュレーションにより作られたデータ)
- Non-blind test set (シミュレーションにより作られたデータで、正解の「クリーンな音声」も参加者に開示される)
- Blind test set (実録データと合成データが半分ずつ。日本語を含む)
以下に、私たちの FUSE を、チャレンジのベースライン手法や、トップの2システムと比較した結果の表を掲載します。* は識別モデルであることを示し、† はハイブリッドモデルであることを示しています。手法の後に続いている、カッコに入った数字は順位を表しています。

次に、チャレンジのリーダーボードです。これは、チャレンジの運営側が公開しているプレプリント( [Sach et al., 2025], https://arxiv.org/pdf/2507.11306 )から引用し、加工したものです。
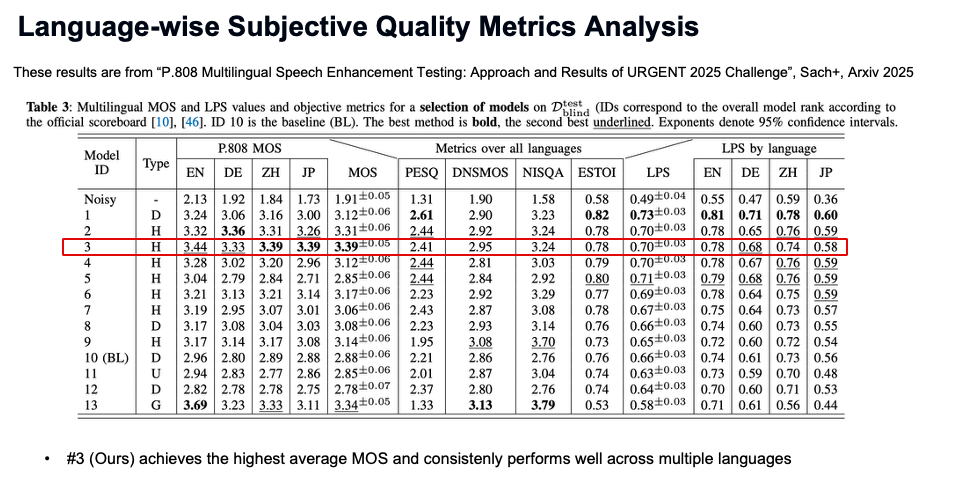
この公式結果において、私たちのチームは総合で3位となりました。
さらに、以下を達成しています。
- 非侵襲的品質指標(DNSMOS, NISQA, UTMOS)において、最高かそれに次ぐ性能
- 純粋に識別的なアプローチを使った第1位のシステムと比べても遜色ない SDR
- 学習データに含まれない日本語を含めて、高い MOS値
また、重要なポイントとして、以下のことが分かりました。
- 第1ステージのみ → 提案手法の各ステージを比べるなかで、SDR では最もよいが、知覚的な指標では劣る
- 第2ステージのみ → 知覚的な指標では素晴らしい性能だが、SDR は低い
- 第3ステージ + blending (S2 + S3) → 全体のバランスにおいてベスト
これにより、実験的に、私たちの設計が裏付けられました。つまり、識別的なアプローチと、生成的なアプローチ、そしてこれらを融合するモデルを組み合わせることで、どれか一つだけを使うよりも良い結果が得られるのです。
※なお、この記事では blending の説明は省略しましたが、信号の平均を取るシンプルなアプローチです。詳しく知りたい方は、ぜひ論文のほうをご確認いただけると幸いです。
今後の展望
日々の生活のなかで、FUSE のようなシステムは、以下のような点で役立つと考えられます。
- オンラインでの会議や授業
- ゲームのボイスチャット
- 電話やカメラでの録音
- 聴覚のサポートや補助器具
- ノイズの多い環境における音声認識や音声合成のフロントエンド
ただし、現時点では FUSE は品質に最適化されており、レイテンシについては最適化されていません。3ステージからなるパイプラインは、リアルタイム性が厳しく要求されるような状況には、今のところ重すぎるのです。
将来的な方向性として、以下のようなことを考えています。
- 3ステージの処理を、単一の軽量なモデルに圧縮、またはマージする
- ストリーミング向きのパイプラインを作る
- より効率的なトークン化や、より少ないコーデックレベルについて調査
- 音声強調を、音声認識や翻訳のタスクと組み合わせる

