強化学習
強化学習とは
強化学習とは,試行錯誤を通して最適な挙動を学習する機械学習の一分野です. 囲碁や将棋のプロ棋士を破ったAIに用いられ,一躍社会的な注目を集めるようになりました. 最近では,言語の生成AIであるChatGPTの訓練にも強化学習が利用されています.
強化学習においては,試行錯誤をする環境,行動を定量的に評価するための報酬関数が与えられ,報酬関数の期待値を最大化するような方策を学習します. 通常の機械学習では,事前にデータセットが与えられ,そのデータセットをもちいてニューラルネットワークをはじめとするモデルを訓練します. 一方で強化学習では,学習に必要なデータを学習しているエージェントが,試行錯誤を通して自律的にデータを収集し,学習を行います. 事前に学習用データを準備せずとも学習を行えることから,強化学習は様々なタスクに用いられています.
関連研究
強化学習の分野では,最適な方策を学習するための様々なアルゴリズムが提案されてきました.中心的なテーマとして長年研究されてきたのが,いかに少ない試行錯誤でスキルを学習するか,という点になります. この問題に取り組むため,方策勾配[Williams,Machine Learning 1992]やQ学習[Watkins+, Machine Learning 1992]といった古典的なアルゴリズムに始まり,Soft Actor Critic[Haarnoja+, ICML2018]やTD3[Fujimoto+,ICML2018]といったactor-critic法などが開発されてきました. さらには,与えられたタスクに素早く適応するためのメタモデルを学習するメタ学習[Finn+,ICML2017]や,複数のタスクを同時に学習するマルチタスク強化学習[Kalashnikov+,CoRL2022], 過去の経験を新たなタスクの学習に活かそうとするオフライン強化学習[Levine+, arXiv 2020]など,様々なトピックが盛んに研究されています.
この研究室の独自性と成果
弊研究室では,強化学習において,多様な挙動を同時に学習するというアプローチに取り組んでいます. 強化学習においては,一つのタスクに対して,多くの場合複数の最適な挙動が存在することが知られています. 複数の最適な挙動を学習しておくと,環境やタスクに変化があった場合に,学習済みの挙動の中から適したものを選び出すだけで新たな環境やタスクに適応できます. 本研究室の最近の研究では,オフライン強化学習において複数の解を発見するためのアルゴリズムを開発しました[Osa&Harada, ICML2024]. 例えば,以下の図では,シミュレーション上のエージェントが歩くための挙動を複数発見しています.(z=[-1.64, -1.64]では片足でのケンケン,z=[0,0]では2足歩行,といった具合です.)
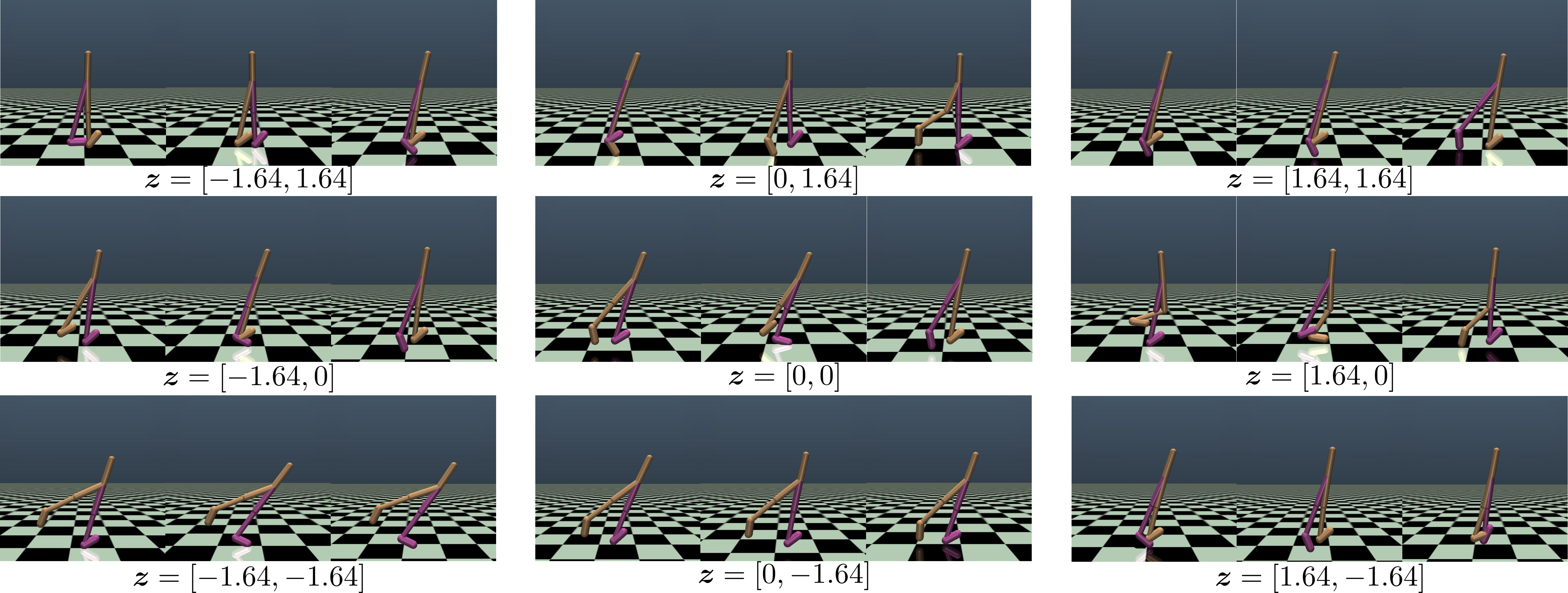
強化学習における多様な歩行の学習
エージェントの体の構造に変化があった場合にも,変化後のエージェントに適した歩き方を事前に学習した歩き方の中から選び出すことで,適応することができます. 人間は,過去の経験に基づいて,状況に合わせて様々な動きを使い分けています.この研究を進めていくことで,様々な挙動を状況に分ける,人間のような適応的なシステムを構築できると考えています.
多様な挙動を学習することのメリットとして、マルチエージェント強化学習において,他のエージェントの挙動の変化にロバストな方策を学習することに利用できることも挙げられます.
本研究室での最近の研究では、食事介護タスクを対象として,被介護者の多様な動きにロバストな方策を学習するため,被介護者の多様な動きを自律的に生成しつつ,介護ロボットの動きを学習する枠組みを提案しています[Osa&Harada, ICRA2024].
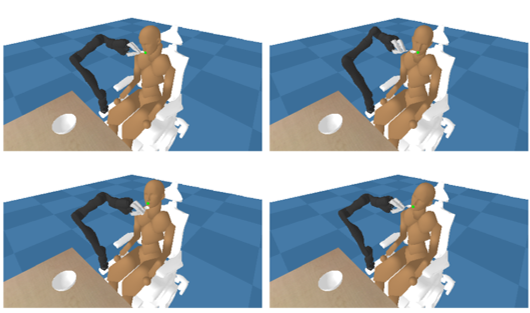
食事介護タスクにおける、被介護者の多様な動きにロバストな介護ロボットの方策の学習
今後の方向性
強化学習は機械学習全体の中でも,非常に論文が投稿数の多く,発展の速い分野の一つです. 学習に必要な時間は徐々に短くなっており,実世界への応用も範囲がますます拡大していく見込みです. 強化学習では試行錯誤をどのような「身体」で行ったかという点が大事になる点が,言語や画像などのタスクと大きく異なります. 言語や画像の生成AIと同様に,強化学習においても大規模モデルが登場[Brohan+, arXiv 2022]してきており, 本研究室でも,Open-X-Embodimentなどのプロジェクト[Open X-Embodiment Collaboration, ICRA2024]に参加し,データなどで貢献しています. しかしなお,小さなスケールで,特定の身体においてどれだけ短時間で学習できるかという点は,強化学習の研究において今後も重要であると考えられます.
参考文献
- Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning Vol. 8, pages 229–256, 1992.
- Christopher J. C. H. Watkins and Peter Dayan. Q-learning. Machine Learning, Vol. 8, pages 279–292, 1992.
- Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, Sergey Levine. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. Proceedings of the 35th International Conference on Machine Learning, PMLR 80:1861-1870, 2018.
- Scott Fujimoto, Herke Hoof, David Meger. Addressing Function Approximation Error in Actor-Critic Methods. Proceedings of the 35th International Conference on Machine Learning, PMLR 80:1587-1596, 2018.
- Chelsea Finn, Pieter Abbeel, Sergey Levine. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. Proceedings of the 34th International Conference on Machine Learning, PMLR 70:1126-1135, 2017.
- Dmitry Kalashnikov, Jake Varley, Yevgen Chebotar, Benjamin Swanson, Rico Jonschkowski, Chelsea Finn, Sergey Levine, Karol Hausman. Scaling Up Multi-Task Robotic Reinforcement Learning. Proceedings of the 5th Conference on Robot Learning, PMLR 164:557-575, 2022.
- Sergey Levine, Aviral Kumar, George Tucker, Justin Fu. Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems. arXiv, 2020.
- Takayuki Osa and Tatsuya Harada. Discovering Multiple Solutions from a Single Task in Offline Reinforcement Learning. Proceedings of the International Conference on Machine Learning (ICML), 2024.
- Takayuki Osa and Tatsuya Harada. Robustifying a Policy in Multi-Agent RL with Diverse Cooperative Behaviors and Adversarial Style Sampling for Assistive Tasks. Proceedings of the IEEE International Conference on Robotics and Automation, 2024 (arXiv).
- Anthony Brohan et al. RT-1: Robotics Transformer for Real-World Control at Scale. arXiv, 2022.
- Open X-Embodiment Collaboration (173 authors, including Takayuki Osa and Tatsuya Harada). Open X-Embodiment: Robotic Learning Datasets and RT-X Models. Proceedings of the IEEE International Conference on Robotics and Automation, 2024.