2026 年発表論文概要
International Conference on Machine Learning, ICML 2026
Revisiting Regularized Policy Optimization for Stable and Efficient Reinforcement Learning in Two-Player Games
Kazuki Ota, Takayuki Osa, Motoki Omura, Tatsuya Harada
 ボードゲームをはじめとする二人ゲームは、強化学習における伝統的なベンチマークである。本研究では、逆向きのカルバックライブラー正則化とエントロピー正則化を用いた方策最適化手法を再訪し、この組み合わせを二人零和ゲームにおいて理論と実証の両面から解析した。理論面では、ゲーム理論における標準形ゲームと有限長ゲームという2つの理論設定において、方策更新則の安定性を調べた。さらに、新たな収束保証を与え、人工的に設定したゲームを用いた数値実験により理論結果を裏付けた。実証面では、この正則化方策最適化に基づく実用的なモデルフリー強化学習アルゴリズムを導出し、その学習効率を、どうぶつしょうぎ、ガードナー・チェス、囲碁、ヘックス、オセロの5つのボードゲームで包括的に評価した。実験結果から、提案手法は既存手法に比べて、各環境で高い訓練効率を示すことが分かった。
ボードゲームをはじめとする二人ゲームは、強化学習における伝統的なベンチマークである。本研究では、逆向きのカルバックライブラー正則化とエントロピー正則化を用いた方策最適化手法を再訪し、この組み合わせを二人零和ゲームにおいて理論と実証の両面から解析した。理論面では、ゲーム理論における標準形ゲームと有限長ゲームという2つの理論設定において、方策更新則の安定性を調べた。さらに、新たな収束保証を与え、人工的に設定したゲームを用いた数値実験により理論結果を裏付けた。実証面では、この正則化方策最適化に基づく実用的なモデルフリー強化学習アルゴリズムを導出し、その学習効率を、どうぶつしょうぎ、ガードナー・チェス、囲碁、ヘックス、オセロの5つのボードゲームで包括的に評価した。実験結果から、提案手法は既存手法に比べて、各環境で高い訓練効率を示すことが分かった。
International Conference on Acoustics, Speech and Signal Processing, ICASSP 2026
Hybrid Speech Enhancement with Discriminative and Codec Token Prediction Models Guided by Cleaned SSL Features for the ICASSP 2026 Urgent Challenge
Nabarun Goswami, Tatsuya Harada
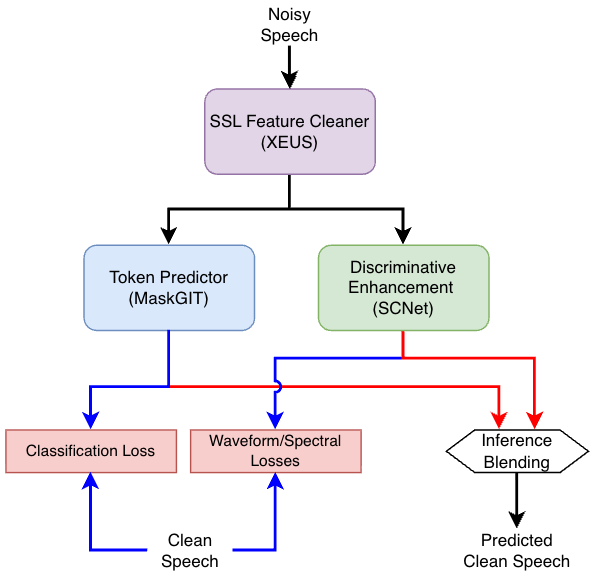 本稿では、ICASSP 2026 URGENTチャレンジに向けたハイブリッド音声強調システムを提案する。本システムは、識別型音声強調モデルと、ニューラルオーディオコーデック領域で動作する生成型トークン予測モデルを組み合わせたものである。これら両モデルは、SSL(自己教師あり学習)モデルの初期層に適用されたパラレルアダプタを介して抽出された、ノイズ除去済みのSSL特徴量を条件として動作する。最終的な強調波形は、識別型モデルおよび生成型モデルの出力結果を融合させることで生成される。本システムは、URGENT2025のデータのみを用いて学習されており、今回新たに導入された音声カテゴリのデータには一切触れていないにもかかわらず、優れた汎化能力を発揮した。その結果、客観評価フェーズでは第3位、最終的な主観評価においては第2位という成績を収めた。
本稿では、ICASSP 2026 URGENTチャレンジに向けたハイブリッド音声強調システムを提案する。本システムは、識別型音声強調モデルと、ニューラルオーディオコーデック領域で動作する生成型トークン予測モデルを組み合わせたものである。これら両モデルは、SSL(自己教師あり学習)モデルの初期層に適用されたパラレルアダプタを介して抽出された、ノイズ除去済みのSSL特徴量を条件として動作する。最終的な強調波形は、識別型モデルおよび生成型モデルの出力結果を融合させることで生成される。本システムは、URGENT2025のデータのみを用いて学習されており、今回新たに導入された音声カテゴリのデータには一切触れていないにもかかわらず、優れた汎化能力を発揮した。その結果、客観評価フェーズでは第3位、最終的な主観評価においては第2位という成績を収めた。
Reinforcement Learning Conference, RLC 2026
Learning the Supports for Categorical Critic in Reinforcement Learning
Jen-Yen Chang, Takayuki Osa, Tatsuya Harada
価値関数は、actor-critic 型の深層強化学習において不可欠な構成要素である。従来、価値関数はブートストラップされたターゲット値に対する平均二乗誤差(MSE)を最小化する回帰問題として学習されてきた。一方、分布型 RL では、分布型 Bellman 作用素に基づいてリターンの分布をモデル化する。本研究では、価値ベースのカテゴリカル分布型 RL における近年の手法である Gaussian Histogram Loss(HL-Gauss)を検討する。HL-Gauss は、ターゲット分布と予測ヒストグラムの間のクロスエントロピーを最小化することで、価値推定を分類問題として定式化する手法である。しかし、その有望性にもかかわらず、ヒストグラムに基づく損失を RL に適用する際には本質的な課題が存在する。特に、固定された support 区間を事前に定義する必要がある点が大きな問題である。RL タスクにおけるターゲット値は通常、非定常かつ確率的であるため、この事前設定はしばしば困難である。本研究では、support の下限および上限を事前に与えるのではなく、動的に学習する手法を提案する。我々は、これらの境界をカテゴリカルなリターン分布の近似と同時に学習する目的関数を導出し、この目的関数が平均二乗 Bellman 誤差の上界を形成することを示す。さらに理論解析により、この上界は HL-Gauss における非学習型 support の上界よりもタイトであることを示す。実験的には、提案目的関数により support 区間の安定した適応が可能となり、連続制御タスクにおけるカテゴリカル critic RL アルゴリズムの性能が向上することを示す。
Transactions on Pattern Analysis and Machine Intelligence, TPAMI 2026
RAW-Adapter: Adapting Pre-trained Visual Model to Camera RAW Images and A Benchmark
Ziteng Cui, Jianfei Yang, Tatsuya Harada
 コンピュータビジョン分野では、視覚モデルの事前学習の主流はsRGB画像を活用する手法へと大きく移り変わりました。これは、入手の容易さと保存に必要な容量の小ささに起因します。しかし、カメラのRAW画像には、多様な実世界シーンにおける物理的な詳細情報が豊富に保持されています。それにもかかわらず、RAWデータを直接利用する既存の視覚認識手法の多くは、画像信号処理(image signal processing, ISP)段階を後続のネットワークモジュールと統合するにとどまっており、モデルレベルでの相乗効果の可能性が見過ごされがちです。
自然言語処理およびコンピュータビジョンにおけるアダプタベースの手法の最近の進展を踏まえ、我々は「RAW-Adapter」を提案します。これは、RAW入力を調整するための入力レベルのアダプタとして学習可能なISPモジュールを組み込んだ、新しいフレームワークです。同時に、モデルレベルのアダプタを採用し、ISP処理と高レベルの下流アーキテクチャをシームレスに橋渡しします。さらに、RAW-Adapterは、様々なコンピュータビジョンフレームワークに適用可能な汎用フレームワークとして機能します。
コンピュータビジョン分野では、視覚モデルの事前学習の主流はsRGB画像を活用する手法へと大きく移り変わりました。これは、入手の容易さと保存に必要な容量の小ささに起因します。しかし、カメラのRAW画像には、多様な実世界シーンにおける物理的な詳細情報が豊富に保持されています。それにもかかわらず、RAWデータを直接利用する既存の視覚認識手法の多くは、画像信号処理(image signal processing, ISP)段階を後続のネットワークモジュールと統合するにとどまっており、モデルレベルでの相乗効果の可能性が見過ごされがちです。
自然言語処理およびコンピュータビジョンにおけるアダプタベースの手法の最近の進展を踏まえ、我々は「RAW-Adapter」を提案します。これは、RAW入力を調整するための入力レベルのアダプタとして学習可能なISPモジュールを組み込んだ、新しいフレームワークです。同時に、モデルレベルのアダプタを採用し、ISP処理と高レベルの下流アーキテクチャをシームレスに橋渡しします。さらに、RAW-Adapterは、様々なコンピュータビジョンフレームワークに適用可能な汎用フレームワークとして機能します。
さらに、我々はRAW-Benchを導入します。これは、明度劣化、気象効果、ぼやけ、カメラ画像の劣化、カメラの色応答の変動など、17種類のRAWベースの一般的な画像欠陥を組み込んだものです。このベンチマークを用いて、RAW-Adapterの性能を、最先端(SOTA)のISP手法やその他のRAWベースの高レベルビジョンアルゴリズムと体系的に比較します。さらに、RAW-Adapterの性能をさらに向上させ、ドメイン外(out-of-domain, OOD)の汎化能力を改善するためのRAWベースのデータ拡張戦略を提案します。広範な実験により、RAW-Adapterの有効性と効率性が実証され、多様なシナリオにおけるその堅牢な性能が明らかになりました。
Transactions on Machine Learning Research, TMLR 2026
Contrastive VQ Priors for Multi-Class Plaque Segmentation via SAM Adaptation
Yizhe Ruan, Yusuke Kurose, Junichi Iho, Yoji Tokunaga, Makoto Horie, Yusaku Hayashi, Keisuke Nishizawa, Yasushi Koyama, Tatsuya Harada
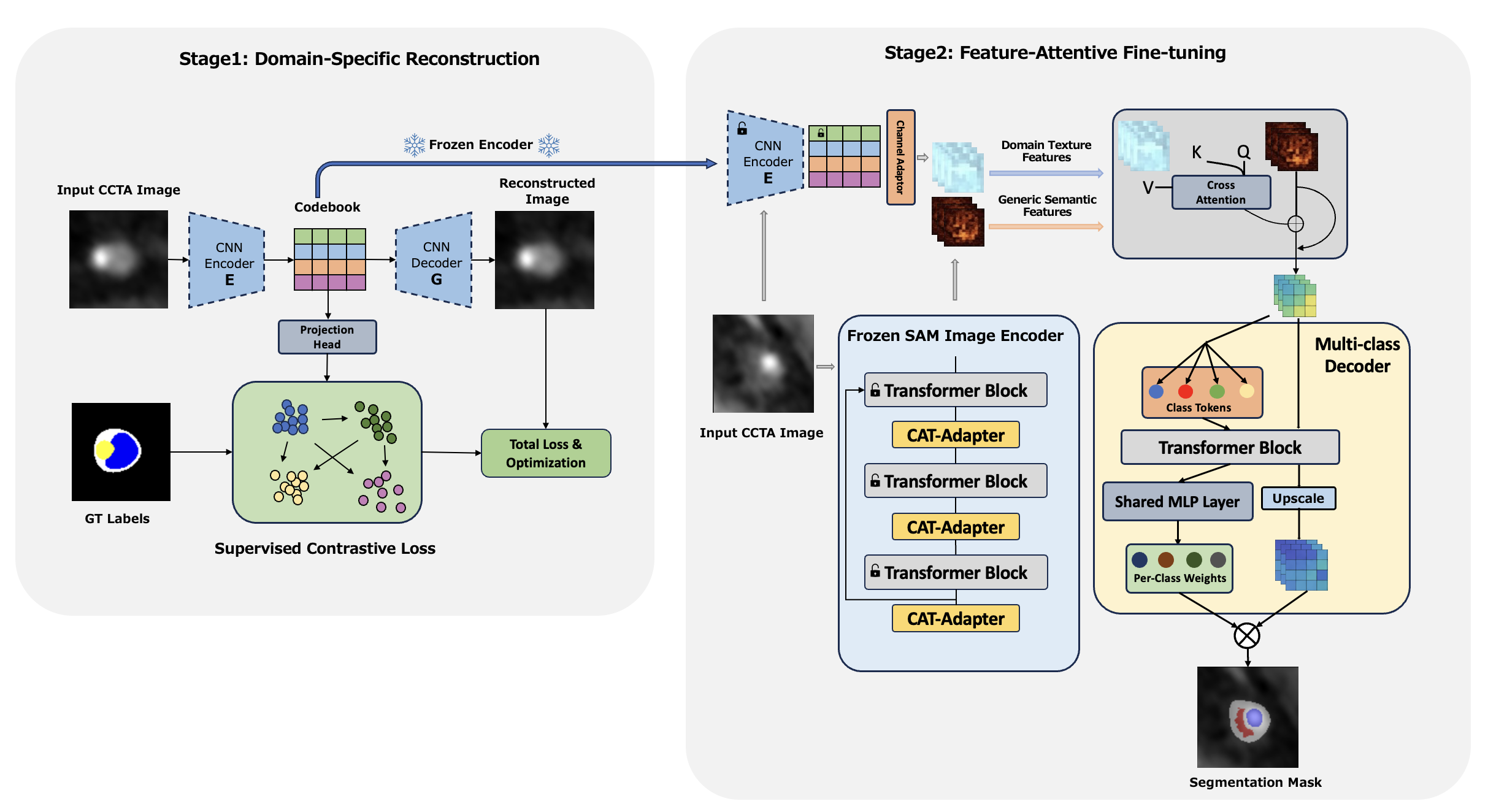 冠動脈CT血管造影(CCTA)におけるプラーク亜型の高精度なセグメンテーションは臨床的に重要である一方、実際には依然として困難である。これは、アノテーションが限られていることに加え、非石灰化病変の視覚的手がかりが微弱であり、かつ症例間で大きく変動するためである。一方で、SAM のようなセグメンテーション基盤モデルは大規模事前学習によって高い頑健性を獲得しているが、その利点は、特に多クラスのプラーク分類において、単純な fine-tuning では private CCTA タスクへ必ずしも安定して転移しない。そこで本研究では、タスク固有かつテクスチャに着目した事前情報を SAM の特徴表現に注入することで、SAM のセグメンテーション頑健性を private CCTA 設定へ転移するためのターゲット指向の戦略を提案する。本手法は二段階から構成される。まず第一段階では、vector-quantized autoencoder を用いて private CCTA データから離散潜在事前分布を学習し、さらに supervised contrastive learning により困難なクラス境界を強調するようその表現を構造化する。次に第二段階では、この事前情報を query-based feature-aware cross-attention モジュールを介して SAM ベースのエンコーダに融合し、プラーク分類に適した multi-class head / decoder によって出力を行う。この private CCTA コホートにおいて、提案手法は比較対象のベースラインを上回る全体性能を示し、とりわけ vessel wall と non-calcified plaque で最も大きな改善が得られた。さらにアブレーション実験により、クラス構造化された事前分布、query-based fusion、および multi-class decoding の各要素が、この設定における最終性能にそれぞれ寄与していることが示された。
冠動脈CT血管造影(CCTA)におけるプラーク亜型の高精度なセグメンテーションは臨床的に重要である一方、実際には依然として困難である。これは、アノテーションが限られていることに加え、非石灰化病変の視覚的手がかりが微弱であり、かつ症例間で大きく変動するためである。一方で、SAM のようなセグメンテーション基盤モデルは大規模事前学習によって高い頑健性を獲得しているが、その利点は、特に多クラスのプラーク分類において、単純な fine-tuning では private CCTA タスクへ必ずしも安定して転移しない。そこで本研究では、タスク固有かつテクスチャに着目した事前情報を SAM の特徴表現に注入することで、SAM のセグメンテーション頑健性を private CCTA 設定へ転移するためのターゲット指向の戦略を提案する。本手法は二段階から構成される。まず第一段階では、vector-quantized autoencoder を用いて private CCTA データから離散潜在事前分布を学習し、さらに supervised contrastive learning により困難なクラス境界を強調するようその表現を構造化する。次に第二段階では、この事前情報を query-based feature-aware cross-attention モジュールを介して SAM ベースのエンコーダに融合し、プラーク分類に適した multi-class head / decoder によって出力を行う。この private CCTA コホートにおいて、提案手法は比較対象のベースラインを上回る全体性能を示し、とりわけ vessel wall と non-calcified plaque で最も大きな改善が得られた。さらにアブレーション実験により、クラス構造化された事前分布、query-based fusion、および multi-class decoding の各要素が、この設定における最終性能にそれぞれ寄与していることが示された。
Language Resources and Evaluation Conference, LREC 2026
DEJIMA: A Novel Large-scale Japanese Dataset for Image Captioning and Visual Question Answering
Toshiki Katsube, Taiga Fukuhara, Kenichiro Ando, Yusuke Mukuta, Kohei Uehara, Tatsuya Harada
 本研究は、日本語のVision-and-Language(V&L)モデリングにおける高品質かつ大規模なリソースの不足という課題に取り組むものである。私たちは、大規模なWebデータ収集に加え、厳格なフィルタリングおよび重複排除、物体検出に基づくエビデンス抽出、さらにグラウンディング制約下での大規模言語モデル(LLM)による精緻化を統合した、スケーラブルかつ再現可能なパイプラインを提案する。
このパイプラインを用いて、画像キャプションデータセット(DEJIMA-Cap)およびVQAデータセット(DEJIMA-VQA)という2つのリソースを構築した。いずれも388万件の画像テキスト対を含み、既存の日本語V&Lデータセットを大幅に上回る規模を有している。
人手評価の結果、DEJIMAは翻訳ベースや手作業によるアノテーションで構築されたデータセットと比較して、日本らしさ(Japaneseness)および言語的自然さの両面で大幅に高い評価を示した。一方で、事実整合性については人手アノテーションコーパスと同等の水準を維持していることが確認された。さらに、画像特徴分布の定量分析により、DEJIMAが日本特有の多様な視覚領域を幅広くカバーしていることが示され、言語的・文化的代表性を視覚的側面からも補完していることが明らかとなった。
DEJIMAで学習したモデルは、複数の日本語マルチモーダルベンチマークにおいて一貫した性能向上を示し、文化的に根ざした大規模リソースがモデル性能向上において重要な役割を果たすことを実証した。
本パイプラインで使用したすべてのデータソースおよびモジュールは商用利用可能なライセンスのもとで構成されており、私たちはデータセットおよび関連メタデータを公開することで、日本語V&Lモデリングにおける今後の研究および産業応用を促進することを目指す。
本研究は、日本語のVision-and-Language(V&L)モデリングにおける高品質かつ大規模なリソースの不足という課題に取り組むものである。私たちは、大規模なWebデータ収集に加え、厳格なフィルタリングおよび重複排除、物体検出に基づくエビデンス抽出、さらにグラウンディング制約下での大規模言語モデル(LLM)による精緻化を統合した、スケーラブルかつ再現可能なパイプラインを提案する。
このパイプラインを用いて、画像キャプションデータセット(DEJIMA-Cap)およびVQAデータセット(DEJIMA-VQA)という2つのリソースを構築した。いずれも388万件の画像テキスト対を含み、既存の日本語V&Lデータセットを大幅に上回る規模を有している。
人手評価の結果、DEJIMAは翻訳ベースや手作業によるアノテーションで構築されたデータセットと比較して、日本らしさ(Japaneseness)および言語的自然さの両面で大幅に高い評価を示した。一方で、事実整合性については人手アノテーションコーパスと同等の水準を維持していることが確認された。さらに、画像特徴分布の定量分析により、DEJIMAが日本特有の多様な視覚領域を幅広くカバーしていることが示され、言語的・文化的代表性を視覚的側面からも補完していることが明らかとなった。
DEJIMAで学習したモデルは、複数の日本語マルチモーダルベンチマークにおいて一貫した性能向上を示し、文化的に根ざした大規模リソースがモデル性能向上において重要な役割を果たすことを実証した。
本パイプラインで使用したすべてのデータソースおよびモジュールは商用利用可能なライセンスのもとで構成されており、私たちはデータセットおよび関連メタデータを公開することで、日本語V&Lモデリングにおける今後の研究および産業応用を促進することを目指す。
IEEE International Conference on Robotics and Automation, ICRA 2026
Unsupervised Domain Adaptation for Robust Imitation Learning under Visual Perturbations
Yasuhiro Kato, Thomas Westfechtel, Jen-Yen Chang, Naoki Morihira, Akinobu Hayashi, Tatsuya Harada, Takayuki Osa
 視覚情報に基づくロボットマニピュレーションシステムは、視覚入力におけるドメインシフトの影響により、しばしば性能劣化に直面する。データ拡張は強化学習において広く用いられているが、模倣学習への適用に関しては比較的十分な研究がなされていない。我々の予備実験は、単に拡張技術を導入するだけでは模倣学習において効果的な改善が得られないことを示している。この課題に対処するため、本研究では二段階の学習プロセスを提案する。第一段階では、データ拡張を活用した敵対的特徴学習フレームワークを構築し、ドメインシフトに対する頑健性を向上させる。第二段階では、容易に収集可能な画像データのみを用いて目標環境にモデルを適応させる教師なしドメイン適応手法を導入する。ロボットタスクにおいては、視覚的ドメインシフトは初期観測のみから検出可能であることが多い。新規ドメインにおいて行動ラベル付きの完全なエピソードを収集することは高コストであるため、初期画像のみを用いた適応はデータ収集コストを大幅に削減する。この目的のため、本研究では目標ドメインの初期観測のみに依存し、ラベル付きデモンストレーションを必要としない適応戦略を開発する。シミュレーションおよび実機ロボット実装の双方における実験結果は、提案手法がソースドメインの性能を保持しつつ、照明条件の変動、背景の変更、環境的妨害要因を含む視覚的摂動に対して強化された耐性を示すことを実証している。
視覚情報に基づくロボットマニピュレーションシステムは、視覚入力におけるドメインシフトの影響により、しばしば性能劣化に直面する。データ拡張は強化学習において広く用いられているが、模倣学習への適用に関しては比較的十分な研究がなされていない。我々の予備実験は、単に拡張技術を導入するだけでは模倣学習において効果的な改善が得られないことを示している。この課題に対処するため、本研究では二段階の学習プロセスを提案する。第一段階では、データ拡張を活用した敵対的特徴学習フレームワークを構築し、ドメインシフトに対する頑健性を向上させる。第二段階では、容易に収集可能な画像データのみを用いて目標環境にモデルを適応させる教師なしドメイン適応手法を導入する。ロボットタスクにおいては、視覚的ドメインシフトは初期観測のみから検出可能であることが多い。新規ドメインにおいて行動ラベル付きの完全なエピソードを収集することは高コストであるため、初期画像のみを用いた適応はデータ収集コストを大幅に削減する。この目的のため、本研究では目標ドメインの初期観測のみに依存し、ラベル付きデモンストレーションを必要としない適応戦略を開発する。シミュレーションおよび実機ロボット実装の双方における実験結果は、提案手法がソースドメインの性能を保持しつつ、照明条件の変動、背景の変更、環境的妨害要因を含む視覚的摂動に対して強化された耐性を示すことを実証している。
The Fourteenth International Conference on Learning Representations, ICLR 2026
R2-Dreamer: Redundancy-Reduced World Models without Decoders or Augmentation
Naoki Morihira, Amal Nahar, Kartik Bharadwaj, Kato Yasuhiro, Akinobu Hayashi, Tatsuya Harada
 画像ベースのモデルベース強化学習(MBRL)における主要な課題の一つは、不要な視覚的詳細からタスクに不可欠な情報を抽出した表現を学習することにある。再構成ベースの手法は有望ではあるが、背景などタスクに関係のない広範な領域にリソースを浪費してしまうことが多い。対して、デコーダーを用いない手法はデータ拡張を活用することで頑健な表現を学習するが、表現の崩壊を防ぐためにこうした外部の正則化に依存することが汎用性を制限していた。本研究では、データ拡張に頼ることなく崩壊を防ぐ内部正則化として機能する自己教師あり学習の目的関数を備えた、デコーダーレスMBRLフレームワーク「R2-Dreamer」を提案する。本手法の核心はBarlow Twinsに着想を得た特徴の冗長性削減にあり、既存のフレームワークへ容易に統合が可能である。DeepMind Control SuiteおよびMeta-Worldを用いた実験において、R2-DreamerはDreamerV3やTD-MPC2といった強力なベースラインに匹敵する性能を示しつつ、DreamerV3比で1.59倍高速な学習を実現した。さらに、タスクに関連するオブジェクトが極めて小さいDMC-Subtleにおいては、大幅な性能向上を達成した。これらの結果は、効果的な内部正則化が、汎用性が高く高性能なデコーダーレスMBRLを可能にすることを示唆している。
画像ベースのモデルベース強化学習(MBRL)における主要な課題の一つは、不要な視覚的詳細からタスクに不可欠な情報を抽出した表現を学習することにある。再構成ベースの手法は有望ではあるが、背景などタスクに関係のない広範な領域にリソースを浪費してしまうことが多い。対して、デコーダーを用いない手法はデータ拡張を活用することで頑健な表現を学習するが、表現の崩壊を防ぐためにこうした外部の正則化に依存することが汎用性を制限していた。本研究では、データ拡張に頼ることなく崩壊を防ぐ内部正則化として機能する自己教師あり学習の目的関数を備えた、デコーダーレスMBRLフレームワーク「R2-Dreamer」を提案する。本手法の核心はBarlow Twinsに着想を得た特徴の冗長性削減にあり、既存のフレームワークへ容易に統合が可能である。DeepMind Control SuiteおよびMeta-Worldを用いた実験において、R2-DreamerはDreamerV3やTD-MPC2といった強力なベースラインに匹敵する性能を示しつつ、DreamerV3比で1.59倍高速な学習を実現した。さらに、タスクに関連するオブジェクトが極めて小さいDMC-Subtleにおいては、大幅な性能向上を達成した。これらの結果は、効果的な内部正則化が、汎用性が高く高性能なデコーダーレスMBRLを可能にすることを示唆している。
Rethinking Policy Diversity in Ensemble Policy Gradient in Large-Scale Reinforcement Learning
Naoki Shitanda, Motoki Omura, Tatsuya Harada, Takayuki Osa
 数万規模の並列環境に強化学習をスケールさせるには、単一方策が持つ探索能力の限界を克服する必要がある。そこで近年、複数の方策を用いて多様なサンプルを収集するアンサンブル型方策勾配法は、探索を促進する手法として提案されてきた。しかし、過度な探索は探索の質を低下させたり、学習の安定性を損なったりする可能性があるため、探索空間を単に広げるだけでは必ずしも学習能力の向上につながらない。本研究では、方策アンサンブルにおける方策間の多様性が学習効率に与える影響を理論的に解析し、方策間の KL 制約によって多様性を制御する Coupled Policy Optimization(CPO)を提案する。提案手法は効果的な探索を可能にし、複数のデクスタラスマニピュレーションタスクにおいて、サンプル効率および最終性能の両面で SAPG、PBT、PPO といった強力なベースラインを上回る性能を示した。さらに、学習中の方策多様性および有効サンプルサイズの解析から、フォロワー方策がリーダー方策の周囲に自然に分布することが明らかになり、構造化された効率的な探索行動が自発的に創発していることが示された。これらの結果は、適切に制御された多様な探索こそが、アンサンブル型方策勾配法において安定かつサンプル効率の高い学習を達成する鍵であることを示している。
数万規模の並列環境に強化学習をスケールさせるには、単一方策が持つ探索能力の限界を克服する必要がある。そこで近年、複数の方策を用いて多様なサンプルを収集するアンサンブル型方策勾配法は、探索を促進する手法として提案されてきた。しかし、過度な探索は探索の質を低下させたり、学習の安定性を損なったりする可能性があるため、探索空間を単に広げるだけでは必ずしも学習能力の向上につながらない。本研究では、方策アンサンブルにおける方策間の多様性が学習効率に与える影響を理論的に解析し、方策間の KL 制約によって多様性を制御する Coupled Policy Optimization(CPO)を提案する。提案手法は効果的な探索を可能にし、複数のデクスタラスマニピュレーションタスクにおいて、サンプル効率および最終性能の両面で SAPG、PBT、PPO といった強力なベースラインを上回る性能を示した。さらに、学習中の方策多様性および有効サンプルサイズの解析から、フォロワー方策がリーダー方策の周囲に自然に分布することが明らかになり、構造化された効率的な探索行動が自発的に創発していることが示された。これらの結果は、適切に制御された多様な探索こそが、アンサンブル型方策勾配法において安定かつサンプル効率の高い学習を達成する鍵であることを示している。
Cross-Embodiment Offline Reinforcement Learning for Heterogeneous Robot Datasets
Haruki Abe, Takayuki Osa, Yusuke Mukuta, Tatsuya Harada
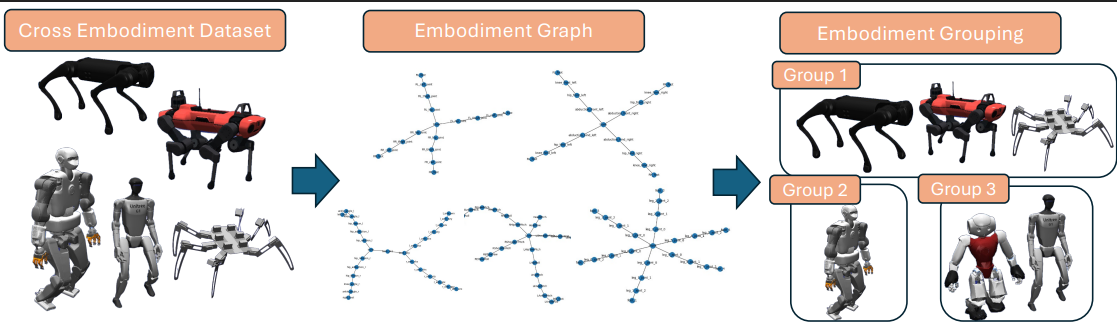 スケーラブルなロボット方策の事前学習は、各プラットフォームごとに高品質なデモンストレーションを収集するコストが高いことによって阻害されてきた。本研究では、オフライン強化学習とクロスエンボディメント学習を統合することで、この問題に対処する。オフライン強化学習は、専門家データに加えて大量のサブオプティマル(最適ではない)データも活用できる。一方、クロスエンボディメント学習は、多様な形態を持つロボットから得られる多様なの軌跡を集約し、普遍的なロボット制御の事前知識を獲得する。私たちは、このオフライン強化学習とクロスエンボディメントの枠組みを体系的に分析し、その強みと限界を原理的に理解できるようにした。この枠組みを評価するため、16種類の異なるロボットプラットフォームにまたがるロコモーションデータセット群を構築した。実験により、この統合アプローチはサブオプティマルな軌跡を豊富に含むデータセットでの事前学習において特に有効であり、純粋なbehavior cloningを上回ることを確認した。しかし、サブオプティマルデータの割合やロボット種類数が増えるにつれて、形態の違いに起因する勾配の衝突が学習を阻害し始めることも観測された。これを緩和するため、ロボットを形態的な類似性に基づいてクラスタリングし、各グループの勾配でモデルを更新する「エンボディメントに基づくグルーピング戦略」を導入する。この単純で静的なグルーピングにより、ロボット間の衝突が大幅に減少し、既存の衝突解決手法よりも優れた性能を示した。
スケーラブルなロボット方策の事前学習は、各プラットフォームごとに高品質なデモンストレーションを収集するコストが高いことによって阻害されてきた。本研究では、オフライン強化学習とクロスエンボディメント学習を統合することで、この問題に対処する。オフライン強化学習は、専門家データに加えて大量のサブオプティマル(最適ではない)データも活用できる。一方、クロスエンボディメント学習は、多様な形態を持つロボットから得られる多様なの軌跡を集約し、普遍的なロボット制御の事前知識を獲得する。私たちは、このオフライン強化学習とクロスエンボディメントの枠組みを体系的に分析し、その強みと限界を原理的に理解できるようにした。この枠組みを評価するため、16種類の異なるロボットプラットフォームにまたがるロコモーションデータセット群を構築した。実験により、この統合アプローチはサブオプティマルな軌跡を豊富に含むデータセットでの事前学習において特に有効であり、純粋なbehavior cloningを上回ることを確認した。しかし、サブオプティマルデータの割合やロボット種類数が増えるにつれて、形態の違いに起因する勾配の衝突が学習を阻害し始めることも観測された。これを緩和するため、ロボットを形態的な類似性に基づいてクラスタリングし、各グループの勾配でモデルを更新する「エンボディメントに基づくグルーピング戦略」を導入する。この単純で静的なグルーピングにより、ロボット間の衝突が大幅に減少し、既存の衝突解決手法よりも優れた性能を示した。
WACV 2026
Semi-supervised Domain Adaptation via Mutual Alignment through Joint Error.
Dexuan Zhang, Thomas Westfechtel, Tatsuya Harada
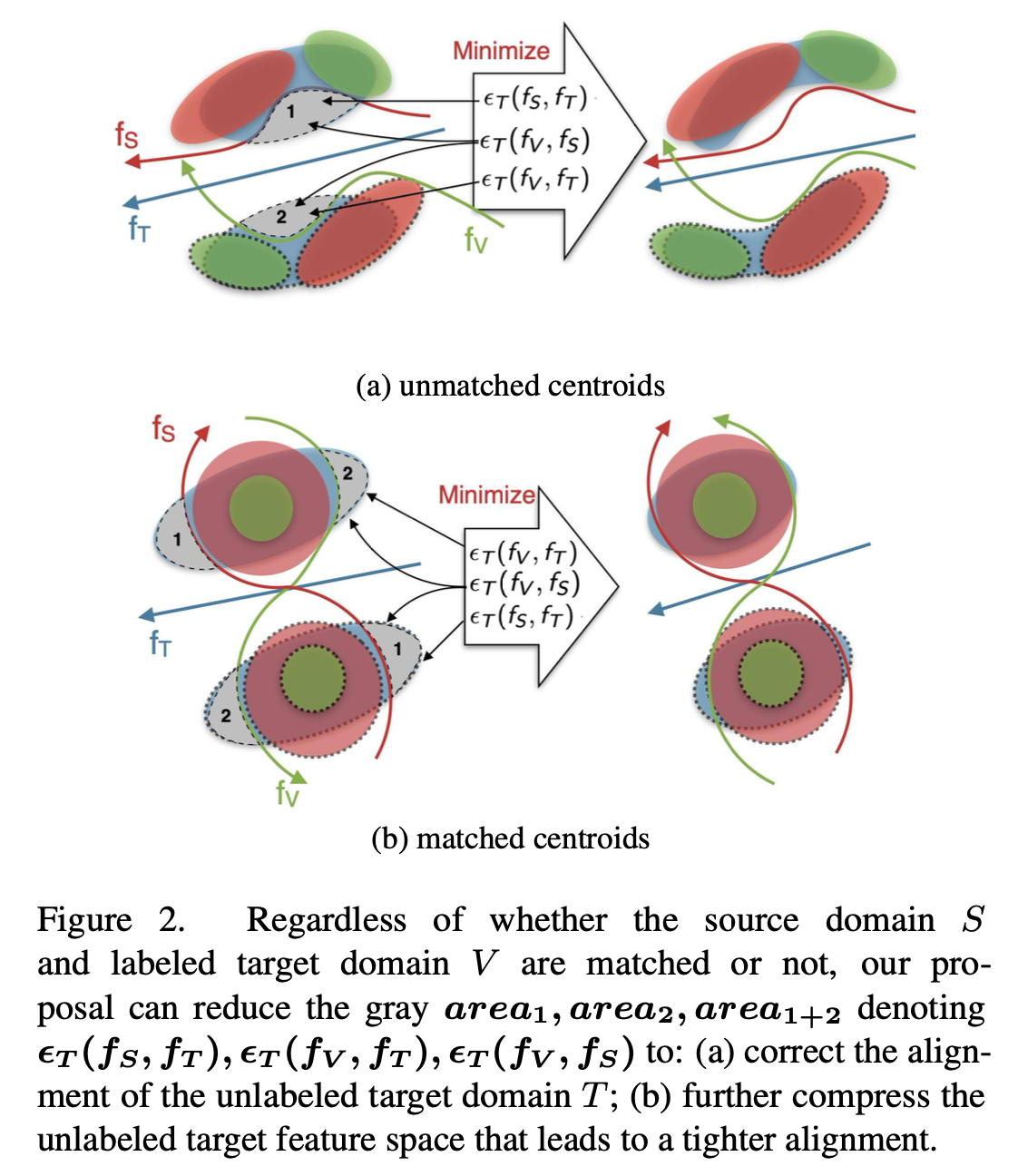 教師なし領域適応のための既存の手法のほとんどは、領域不変表現の学習に重点を置いています。しかし、最近の研究では、大きな領域シフト下での周辺分布の調整と結合誤差とのトレードオフにより、ターゲット領域での汎化性能が低下する可能性があることが示されています。少数のラベル付きターゲットデータポイントは適応品質を向上させますが、ラベル付きターゲットデータとラベルなしターゲットデータ間の分布シフトは見落とされがちです。そこで、ラベル付きドメインとラベルなしドメインのペア間の相互分布シフトを削減できる、半教師あり領域適応における結合誤差に対処するための新しい学習理論を提案します。さらに、仮説間の距離測定を導入することで、アルゴリズムと理論における損失関数の不一致を解消します。広範な実験により、特に大きな領域シフトとラベル付きターゲットデータが不足しているシナリオにおいて、私たちの手法は一貫してベースラインアプローチよりも優れていることが実証されています。
教師なし領域適応のための既存の手法のほとんどは、領域不変表現の学習に重点を置いています。しかし、最近の研究では、大きな領域シフト下での周辺分布の調整と結合誤差とのトレードオフにより、ターゲット領域での汎化性能が低下する可能性があることが示されています。少数のラベル付きターゲットデータポイントは適応品質を向上させますが、ラベル付きターゲットデータとラベルなしターゲットデータ間の分布シフトは見落とされがちです。そこで、ラベル付きドメインとラベルなしドメインのペア間の相互分布シフトを削減できる、半教師あり領域適応における結合誤差に対処するための新しい学習理論を提案します。さらに、仮説間の距離測定を導入することで、アルゴリズムと理論における損失関数の不一致を解消します。広範な実験により、特に大きな領域シフトとラベル付きターゲットデータが不足しているシナリオにおいて、私たちの手法は一貫してベースラインアプローチよりも優れていることが実証されています。
SceneProp: Combining Neural Network and Markov Random Field for Scene-Graph Grounding.
Keita Otani, Tatsuya Harada
 複数の物体間の位置関係が文章から与えられたとき、それぞれの名詞が画像中のどの物体を指すかを特定(グラウンディング)することは、視覚と言語の対応付けにおいて重要な課題です。従来のフレーズ・グラウンディング手法は単一物体の特定には優れていますが、複雑な関係情報を扱うための構造的な帰納バイアスを欠いており、記述が詳細になるほど性能が低下する問題がありました。
この課題に対処するため、私たちは物体とその関係をグラフ構造で表す「シーングラフ・グラウンディング」に着目しました。しかし既存手法は、この表現を十分に活かせておらず、関係が増えるほどかえって性能が落ちるという問題を抱えていました。
そこで私たちは SceneProp を提案します。SceneProp はシーングラフ・グラウンディングをマルコフ確率場(MRF)の最大事後確率(MAP)推論問題として再定式化し、グラフ全体を対象とした大域的な推論によって、すべての関係を同時に満たす最適な対応付けを求めます。また、Belief Propagation を深層学習フレームワーク上で自動微分可能に実装することで、エンドツーエンドでの学習を実現しました。
4つのベンチマークでの実験により、SceneProp は既存手法を大幅に上回る精度を示しました。特に、関係情報が増えるほど精度が向上するという特徴を初めて実証し、詳細な関係性がグラウンディング性能を高めることを示しました。
複数の物体間の位置関係が文章から与えられたとき、それぞれの名詞が画像中のどの物体を指すかを特定(グラウンディング)することは、視覚と言語の対応付けにおいて重要な課題です。従来のフレーズ・グラウンディング手法は単一物体の特定には優れていますが、複雑な関係情報を扱うための構造的な帰納バイアスを欠いており、記述が詳細になるほど性能が低下する問題がありました。
この課題に対処するため、私たちは物体とその関係をグラフ構造で表す「シーングラフ・グラウンディング」に着目しました。しかし既存手法は、この表現を十分に活かせておらず、関係が増えるほどかえって性能が落ちるという問題を抱えていました。
そこで私たちは SceneProp を提案します。SceneProp はシーングラフ・グラウンディングをマルコフ確率場(MRF)の最大事後確率(MAP)推論問題として再定式化し、グラフ全体を対象とした大域的な推論によって、すべての関係を同時に満たす最適な対応付けを求めます。また、Belief Propagation を深層学習フレームワーク上で自動微分可能に実装することで、エンドツーエンドでの学習を実現しました。
4つのベンチマークでの実験により、SceneProp は既存手法を大幅に上回る精度を示しました。特に、関係情報が増えるほど精度が向上するという特徴を初めて実証し、詳細な関係性がグラウンディング性能を高めることを示しました。