2025 年発表論文概要
NeurIPS 2025
Intend to Move: A Multimodal Dataset for Intention-Aware Human Motion Understanding.
Ryo Umagami, Liu Yue, Xuangeng Chu, Ryuto Fukushima, Tetsuya Narita, Yusuke Mukuta, Tomoyuki Takahata, Jianfei Yang, Tatsuya Harada
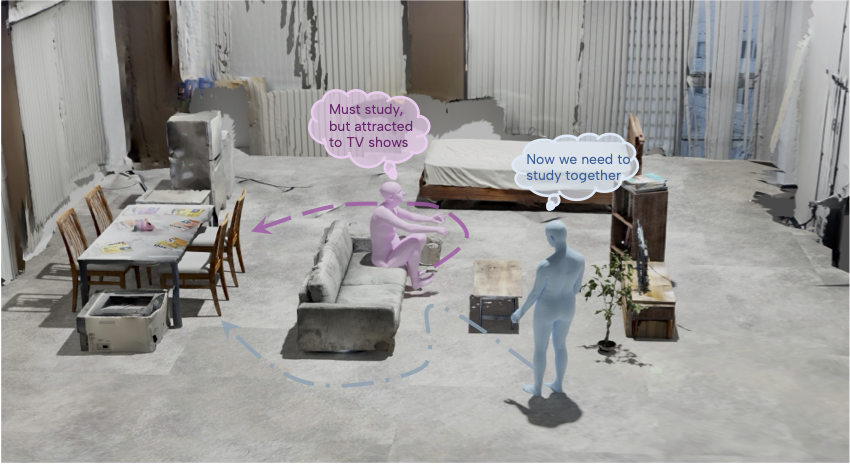 人間の動作は本質的に意図を伴うものですが、これまでの動作モデリングのパラダイムの多くは低次の運動学に焦点を当てており、行動を駆動する意味論的かつ因果的な要因を見落としています。既存のデータセットもまた、静的なシーンにおける短く文脈から切り離された動作を捉えるにとどまり、Embodied reasoningのための基盤をほとんど提供できていないという点で、研究の進展を妨げています。これらの限界に対処するため、本研究では、意図に基づいた動作モデリングのための大規模マルチモーダルデータセット「Intend to Move (I2M)」を提案します。I2Mには、動的でリアルな家庭環境において記録された計10.1時間の2人組の3D動作シーケンスが含まれており、多視点RGB-Dビデオ、3Dシーン形状、および各参加者の刻々と変化する意図に対する言語アノテーションが付与されています。ベンチマーク実験の結果、現在の動作モデルには根本的な課題があることが明らかになりました。すなわち、高次の目標を、物理的かつ社会的に整合性の取れた動作へと変換することができていないのです。このように、I2Mは単なるデータセットとしてだけでなく、Embodied Intelligenceのベンチマークとしても機能し、人間の動作の背後にある意図を推論・予測し、それに基づいて行動できるモデルの研究を可能にします。
人間の動作は本質的に意図を伴うものですが、これまでの動作モデリングのパラダイムの多くは低次の運動学に焦点を当てており、行動を駆動する意味論的かつ因果的な要因を見落としています。既存のデータセットもまた、静的なシーンにおける短く文脈から切り離された動作を捉えるにとどまり、Embodied reasoningのための基盤をほとんど提供できていないという点で、研究の進展を妨げています。これらの限界に対処するため、本研究では、意図に基づいた動作モデリングのための大規模マルチモーダルデータセット「Intend to Move (I2M)」を提案します。I2Mには、動的でリアルな家庭環境において記録された計10.1時間の2人組の3D動作シーケンスが含まれており、多視点RGB-Dビデオ、3Dシーン形状、および各参加者の刻々と変化する意図に対する言語アノテーションが付与されています。ベンチマーク実験の結果、現在の動作モデルには根本的な課題があることが明らかになりました。すなわち、高次の目標を、物理的かつ社会的に整合性の取れた動作へと変換することができていないのです。このように、I2Mは単なるデータセットとしてだけでなく、Embodied Intelligenceのベンチマークとしても機能し、人間の動作の背後にある意図を推論・予測し、それに基づいて行動できるモデルの研究を可能にします。
Dr. RAW: Towards General High-Level Vision from RAW with Efficient Task Conditioning.
Wenjun Huang*, Ziteng Cui* (*: co-first author), Yinqiang Zheng, Yirui He, Tatsuya Harada, Mohsen Imani
 私たちは Dr.RAW を紹介します。これは、カメラのRAWデータを直接扱う高次のコンピュータビジョンタスクに向けた、統合的かつチューニング効率の高いフレームワークです。従来手法が画像信号処理(ISP)パイプラインの最適化や、各タスクごとにネットワーク全体のファインチューニングを必要としたのに対し、Dr.RAWは最小限のパラメータ更新とバックボーン重みの固定によって、最先端の性能を達成します。
入力段階では、センサーと照明のマッピング、さらにリモザイシングを含む軽量な前処理を施し、センサー差異や光環境の違いに起因するデータ不整合を低減します。ネットワークレベルでは、Sensor Prior Prompts (SPP) とタスク特化型の Low-Rank Adaptation (LoRA) という2つのモジュールを通じてタスク適応を実現します。SPPは、RAW画素分布の事前知識に基づく学習可能プロンプトを用いてネットワークにセンサー認識的な条件付けを注入し、LoRAはバックボーンの主要層において低ランク行列のみを更新することで効率的なタスク特化型チューニングを可能にします。
わずかなチューニングにもかかわらず、Dr.RAW は4つのRAWベースタスク(物体検出、セマンティックセグメンテーション、インスタンスセグメンテーション、姿勢推定)において、さまざまな照明条件を含む9つのデータセットで優れた結果を示しました。RAWの持つ物理的手がかりとパラメータ効率的手法を融合することで、Dr.RAWはRAWベースのビジョンシステムを前進させ、高精度と計算効率を同時に実現します。私たちはソースコードを公開予定です。
私たちは Dr.RAW を紹介します。これは、カメラのRAWデータを直接扱う高次のコンピュータビジョンタスクに向けた、統合的かつチューニング効率の高いフレームワークです。従来手法が画像信号処理(ISP)パイプラインの最適化や、各タスクごとにネットワーク全体のファインチューニングを必要としたのに対し、Dr.RAWは最小限のパラメータ更新とバックボーン重みの固定によって、最先端の性能を達成します。
入力段階では、センサーと照明のマッピング、さらにリモザイシングを含む軽量な前処理を施し、センサー差異や光環境の違いに起因するデータ不整合を低減します。ネットワークレベルでは、Sensor Prior Prompts (SPP) とタスク特化型の Low-Rank Adaptation (LoRA) という2つのモジュールを通じてタスク適応を実現します。SPPは、RAW画素分布の事前知識に基づく学習可能プロンプトを用いてネットワークにセンサー認識的な条件付けを注入し、LoRAはバックボーンの主要層において低ランク行列のみを更新することで効率的なタスク特化型チューニングを可能にします。
わずかなチューニングにもかかわらず、Dr.RAW は4つのRAWベースタスク(物体検出、セマンティックセグメンテーション、インスタンスセグメンテーション、姿勢推定)において、さまざまな照明条件を含む9つのデータセットで優れた結果を示しました。RAWの持つ物理的手がかりとパラメータ効率的手法を融合することで、Dr.RAWはRAWベースのビジョンシステムを前進させ、高精度と計算効率を同時に実現します。私たちはソースコードを公開予定です。
SIGGRAPH Asia 2025
ARTalk: Speech-Driven 3D Head Animation via Autoregressive Model
Xuangeng Chu, Nabarun Goswami, Ziteng Cui, Hanqin Wang, Tatsuya Harada
 音声から3D顔アニメーションを生成する本技術は、音声クリップから3Dヘッドモデルのリアルな口の動きや表情を生み出すことを目的としています。既存の拡散モデルは自然なモーションを生成できますが、その生成速度の遅さが応用の可能性を制限しています。本論文では、音声からマルチスケールのモーションコードブックへのマッピングを学習することで、高い同期性を持つ唇の動き、リアルな頭部の姿勢、そして目の瞬きをリアルタイムで生成する、新しい自己回帰モデルを提案します。さらに、本モデルはサンプルのモーションシーケンスを使用することで、未知の発話スタイルにも適応でき、学習時に見られなかった個人特有のスタイルを持つ3Dトーキングアバターの作成を可能にします。広範な評価とユーザー調査により、我々の手法が唇の同期性と知覚される品質において、既存のアプローチを上回ることが示されました。
音声から3D顔アニメーションを生成する本技術は、音声クリップから3Dヘッドモデルのリアルな口の動きや表情を生み出すことを目的としています。既存の拡散モデルは自然なモーションを生成できますが、その生成速度の遅さが応用の可能性を制限しています。本論文では、音声からマルチスケールのモーションコードブックへのマッピングを学習することで、高い同期性を持つ唇の動き、リアルな頭部の姿勢、そして目の瞬きをリアルタイムで生成する、新しい自己回帰モデルを提案します。さらに、本モデルはサンプルのモーションシーケンスを使用することで、未知の発話スタイルにも適応でき、学習時に見られなかった個人特有のスタイルを持つ3Dトーキングアバターの作成を可能にします。広範な評価とユーザー調査により、我々の手法が唇の同期性と知覚される品質において、既存のアプローチを上回ることが示されました。
Pacific Graphics 2025
Improved 3D Scene Stylization via Text-Guided Generative Image Editing with Region-Based Control
Haruo Fujiwara, Yusuke Mukuta, Tatsuya Harada
 2D画像生成モデルの豊富な事前知識を活用した、テキスト指示による3Dシーンの編集とスタイル変換に関する近年の進歩は、有望な成果を示しています。しかし、高品質なスタイル変換と視点間の一貫性を同時に確保することは未だに同タスクに残された課題となっています。さらに、セマンティックな対応関係を保ちながら、シーン内の異なる領域やオブジェクトにスタイルを個別適用することはこれまで容易ではありませんでした。
これらの問題に対処するために、視点間の一貫性を維持しつつ3Dシーンのスタイル変換品質をさらに向上させ、追加機能として領域制御されたスタイル転写を実現する手法を提案します。
本手法では、元のマルチビュー画像からスタイル変換されたマルチビュー2D画像を用いて初期の3D表現を追加訓練することにより、3Dスタイル変換を最終的に実現します。そのため、スタイル変換されたマルチビュー画像におけるスタイルの一貫性を視点間で確保することが極めて重要です。
これを達成するために、一枚の手本となる参照画像のアテンションを他視点と共有しながら、マルチビュー生成を行う深度条件付き拡散モデルパイプラインを活用します。
これにより、異なる視点間でスタイルを効果的に統一することが可能になります。加えて、近年の3Dインペインティング手法に着想を得て、複数の深度マップのグリッドを単一の参照画像として利用することで、スタイル変換された画像間の視点間における一貫性をさらに強化することが可能になります。
最後に、多領域重要度重み付きスライス・ワッサースタイン距離損失(Multi-Region Importance-Weighted Sliced Wasserstein Distance Loss)を提案します。これにより、既存モデルから得られるセグメンテーションマスクを用いて、画像の個別の領域にスタイルを適用することが可能になります。この追加機能により、スタイル転写の忠実度を向上させ、シーンの異なる領域間で異なるスタイルを混合することも可能になることが示されています。
2D画像生成モデルの豊富な事前知識を活用した、テキスト指示による3Dシーンの編集とスタイル変換に関する近年の進歩は、有望な成果を示しています。しかし、高品質なスタイル変換と視点間の一貫性を同時に確保することは未だに同タスクに残された課題となっています。さらに、セマンティックな対応関係を保ちながら、シーン内の異なる領域やオブジェクトにスタイルを個別適用することはこれまで容易ではありませんでした。
これらの問題に対処するために、視点間の一貫性を維持しつつ3Dシーンのスタイル変換品質をさらに向上させ、追加機能として領域制御されたスタイル転写を実現する手法を提案します。
本手法では、元のマルチビュー画像からスタイル変換されたマルチビュー2D画像を用いて初期の3D表現を追加訓練することにより、3Dスタイル変換を最終的に実現します。そのため、スタイル変換されたマルチビュー画像におけるスタイルの一貫性を視点間で確保することが極めて重要です。
これを達成するために、一枚の手本となる参照画像のアテンションを他視点と共有しながら、マルチビュー生成を行う深度条件付き拡散モデルパイプラインを活用します。
これにより、異なる視点間でスタイルを効果的に統一することが可能になります。加えて、近年の3Dインペインティング手法に着想を得て、複数の深度マップのグリッドを単一の参照画像として利用することで、スタイル変換された画像間の視点間における一貫性をさらに強化することが可能になります。
最後に、多領域重要度重み付きスライス・ワッサースタイン距離損失(Multi-Region Importance-Weighted Sliced Wasserstein Distance Loss)を提案します。これにより、既存モデルから得られるセグメンテーションマスクを用いて、画像の個別の領域にスタイルを適用することが可能になります。この追加機能により、スタイル転写の忠実度を向上させ、シーンの異なる領域間で異なるスタイルを混合することも可能になることが示されています。
24th International Conference on Humanoid Robots (Humanoids 2025)
Few-shot Imitation Learning by Variable-length Trajectory Retrieval from a Large and Diverse Dataset
Tomoyuki Araki, Yusuke Mukuta, Takayuki Osa, Tatsuya Harada
 模倣学習は、ロボットに複雑なスキルを習得させるための有効な枠組みですが、通常は多数のラベル付きデモンストレーションを必要とし、その収集には多くの手間とコストがかかります。一方で、多様な軌道を含む大規模なラベルなしデータセットは比較的容易に入手できるため、こうしたデータを活用して、少数のデモから学習を可能にする手法が注目されています。その有力なアプローチのひとつが、ラベルなしデータセットの中から、デモンストレーションに類似した軌道を検索して活用する方法です。しかし、既存の検索ベースの手法は、フレーム単位の比較や固定長の軌道埋め込みに依存しているため、行動の時間的な構造を適切に捉えることが難しく、実行速度の違いに対する汎化にも限界があります。 本研究では、こうした課題に対応するため、自己注意機構(Self-Attention)を用いて可変長の軌道を埋め込み、系列情報を捉えることで、意味的に類似した行動をよりロバストに検索できる手法を提案します。提案手法では、少数のデモンストレーションをもとにラベルなしデータセットから関連する軌道を抽出し、それらをデモンストレーションと併用してエージェントの学習に利用することで、データ収集コストを削減します。 大規模かつ多様なデータセットを用いた実験により、本手法が、現実的な条件下において、既存の検索ベースの模倣学習手法よりも高い検索精度とタスク成功率を実現できることを示しました。
模倣学習は、ロボットに複雑なスキルを習得させるための有効な枠組みですが、通常は多数のラベル付きデモンストレーションを必要とし、その収集には多くの手間とコストがかかります。一方で、多様な軌道を含む大規模なラベルなしデータセットは比較的容易に入手できるため、こうしたデータを活用して、少数のデモから学習を可能にする手法が注目されています。その有力なアプローチのひとつが、ラベルなしデータセットの中から、デモンストレーションに類似した軌道を検索して活用する方法です。しかし、既存の検索ベースの手法は、フレーム単位の比較や固定長の軌道埋め込みに依存しているため、行動の時間的な構造を適切に捉えることが難しく、実行速度の違いに対する汎化にも限界があります。 本研究では、こうした課題に対応するため、自己注意機構(Self-Attention)を用いて可変長の軌道を埋め込み、系列情報を捉えることで、意味的に類似した行動をよりロバストに検索できる手法を提案します。提案手法では、少数のデモンストレーションをもとにラベルなしデータセットから関連する軌道を抽出し、それらをデモンストレーションと併用してエージェントの学習に利用することで、データ収集コストを削減します。 大規模かつ多様なデータセットを用いた実験により、本手法が、現実的な条件下において、既存の検索ベースの模倣学習手法よりも高い検索精度とタスク成功率を実現できることを示しました。
第28回 画像の認識・理解シンポジウム (MIRU2025), 口頭発表論文, 査読付き
高品質な日本語マルチモーダルデータセットのスケーラブルな構築手法に関する研究
Toshiki katsube, Taiga Fukuhara, Kohei Uehara, Kenichiro Ando, Yusuke Mukuta, Tatsuya harada
 近年,機械学習技術の進歩により視覚情報と言語情報を統合して処理するVision & Language(V&L)モデルの発展がめざましいです。V&Lモデルの学習のためには,テキストとデータがペアになったV&Lデータセットが必要であるが,日本語など英語以外の言語のデータセットは量的にも質的にも不足しています.
本研究では,日本特有の知識や文化を反映した,高品質な画像キャプションデータセットをスケーラブルに構築する手法を提案しました.提案手法は,画像とaltテキストのダウンロード,画像に含まれる物体の検出,LLMによるaltテキストの整形の三段階に分かれます.LLMによってテキストを整形することにより,従来の自動で構築されたデータセットよりも高品質なデータセット構築を可能にしました.構築したデータセットを用いてV&Lモデルを学習し,V&Lモデルの日本語性能の向上に寄与することを確認しました.
近年,機械学習技術の進歩により視覚情報と言語情報を統合して処理するVision & Language(V&L)モデルの発展がめざましいです。V&Lモデルの学習のためには,テキストとデータがペアになったV&Lデータセットが必要であるが,日本語など英語以外の言語のデータセットは量的にも質的にも不足しています.
本研究では,日本特有の知識や文化を反映した,高品質な画像キャプションデータセットをスケーラブルに構築する手法を提案しました.提案手法は,画像とaltテキストのダウンロード,画像に含まれる物体の検出,LLMによるaltテキストの整形の三段階に分かれます.LLMによってテキストを整形することにより,従来の自動で構築されたデータセットよりも高品質なデータセット構築を可能にしました.構築したデータセットを用いてV&Lモデルを学習し,V&Lモデルの日本語性能の向上に寄与することを確認しました.
Interspeech 2025
FUSE: Universal Speech Enhancement using Multi-Stage Fusion of Sparse
Compression and Token Generation Models for the URGENT 2025 Challenge
Nabarun Goswami, Tatsuya Harada
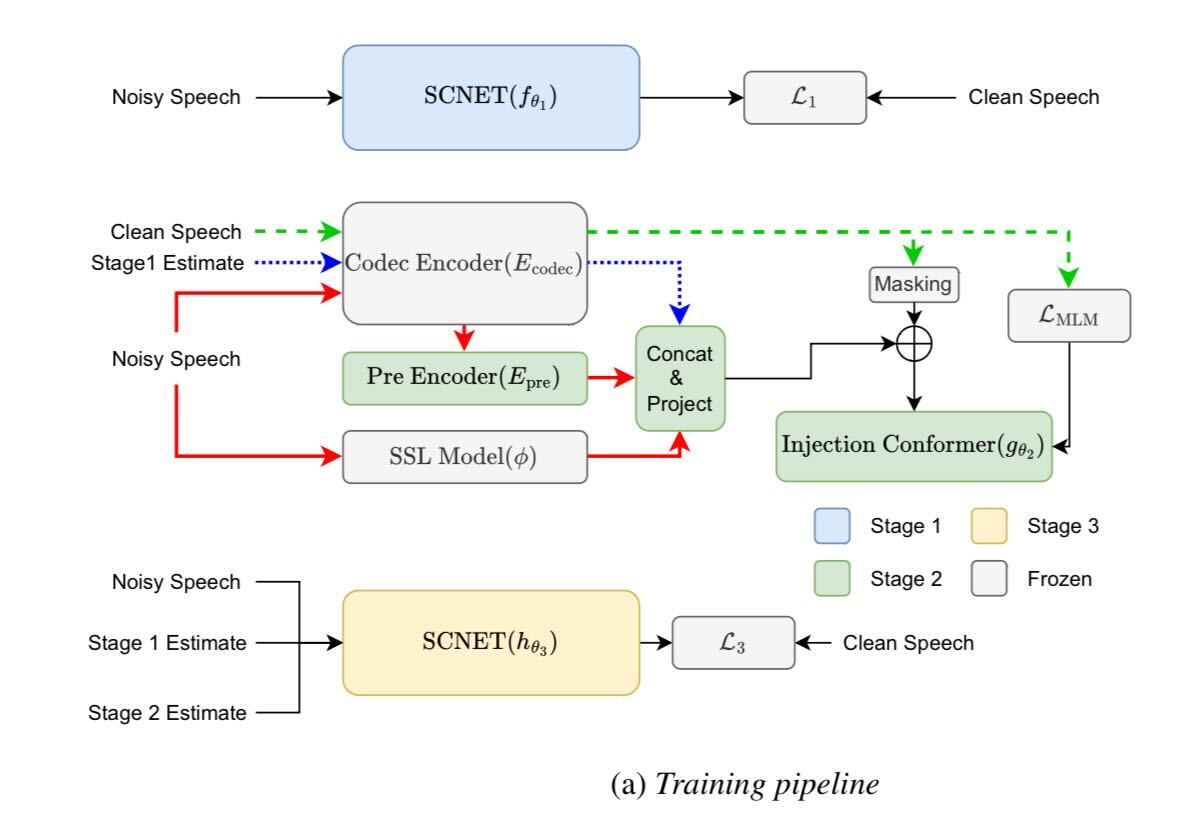 Interspeech 2025 URGENT Challenge向けに設計された、ユニバーサルな音声強調のための多段階フレームワークを提案します。このシステムはまず、スパース圧縮ネットワークを用いて音源をロバストに分離し、ノイズの多い入力から初期のクリーンな音声推定値を抽出します。次に、効率的なマスク予測生成モデルを用いて、自己教師あり特徴量を活用し、ニューラルオーディオコーデックから得られた音響トークンに対してマスク言語モデリング目標を最適化することで、音声品質を改善します。最終段階では、融合ネットワークが最初の2段階の出力を元のノイズ信号と統合し、信号忠実度と知覚品質の両方をバランスよく改善します。さらに、複数の時間シフト予測を集約するシフトトリックと出力ブレンディングを組み合わせることで、パフォーマンスがさらに向上します。可変サンプリングレートと多様な歪みタイプを持つ困難な多言語データセットを用いた実験結果により、このアプローチの有効性が検証されています。
Interspeech 2025 URGENT Challenge向けに設計された、ユニバーサルな音声強調のための多段階フレームワークを提案します。このシステムはまず、スパース圧縮ネットワークを用いて音源をロバストに分離し、ノイズの多い入力から初期のクリーンな音声推定値を抽出します。次に、効率的なマスク予測生成モデルを用いて、自己教師あり特徴量を活用し、ニューラルオーディオコーデックから得られた音響トークンに対してマスク言語モデリング目標を最適化することで、音声品質を改善します。最終段階では、融合ネットワークが最初の2段階の出力を元のノイズ信号と統合し、信号忠実度と知覚品質の両方をバランスよく改善します。さらに、複数の時間シフト予測を集約するシフトトリックと出力ブレンディングを組み合わせることで、パフォーマンスがさらに向上します。可変サンプリングレートと多様な歪みタイプを持つ困難な多言語データセットを用いた実験結果により、このアプローチの有効性が検証されています。
Transactions on Machine Learning Research (TMLR), 2025
Enhancing Plaque Segmentation in CCTA with Prompt- based Diffusion Data Augmentation
Yizhe Ruan, Xuangeng Chu, Ziteng Cui, Yusuke Kurose, Junichi Iho, Yoji Tokunaga, Makoto Horie, Yusaku Hayashi, Keisuke Nishizawa, Yasushi Koyama, Tatsuya Harada
 冠動脈CT血管造影(CCTA)は、冠動脈疾患(CAD)の非侵襲的評価に不可欠です。しかし、アテローム性動脈硬化プラークの正確なセグメンテーションは、データの希少性、深刻なクラス不均衡、そして石灰化プラークと非石灰化プラーク間の著しい多様性のため、依然として困難な課題です。DiffTumorの腫瘍合成とPromptIRの適応的修復フレームワークに着想を得て、我々はマルチクラスの病変合成のためのプロンプト条件付き拡散モデルである「PromptLesion」を提案します。単一クラスの手法とは異なり、我々のアプローチは拡散生成プロセス内に病変特有のプロンプトを統合し、合成データにおける多様性と解剖学的な忠実性を向上させます。我々は、プライベートなCCTAデータセットと、公開データセットを用いた多臓器(腎臓、肝臓、膵臓)の腫瘍セグメンテーションタスクでPromptLesionを検証し、ベースライン手法と比較して優れた性能を達成しました。我々のプロンプト誘導による合成データ拡張を用いて学習させたモデルは、プラークと腫瘍の両方のセグメンテーションにおいて、ダイス類似係数(DSC)スコアを大幅に改善しました。広範な評価とアブレーション研究により、プロンプトによる条件付けの有効性が確認されています。
冠動脈CT血管造影(CCTA)は、冠動脈疾患(CAD)の非侵襲的評価に不可欠です。しかし、アテローム性動脈硬化プラークの正確なセグメンテーションは、データの希少性、深刻なクラス不均衡、そして石灰化プラークと非石灰化プラーク間の著しい多様性のため、依然として困難な課題です。DiffTumorの腫瘍合成とPromptIRの適応的修復フレームワークに着想を得て、我々はマルチクラスの病変合成のためのプロンプト条件付き拡散モデルである「PromptLesion」を提案します。単一クラスの手法とは異なり、我々のアプローチは拡散生成プロセス内に病変特有のプロンプトを統合し、合成データにおける多様性と解剖学的な忠実性を向上させます。我々は、プライベートなCCTAデータセットと、公開データセットを用いた多臓器(腎臓、肝臓、膵臓)の腫瘍セグメンテーションタスクでPromptLesionを検証し、ベースライン手法と比較して優れた性能を達成しました。我々のプロンプト誘導による合成データ拡張を用いて学習させたモデルは、プラークと腫瘍の両方のセグメンテーションにおいて、ダイス類似係数(DSC)スコアを大幅に改善しました。広範な評価とアブレーション研究により、プロンプトによる条件付けの有効性が確認されています。
HyperVQ: MLR-based Vector Quantization in Hyperbolic Space
Nabarun Goswami, Yusuke Mukuta, Tatsuya Harada
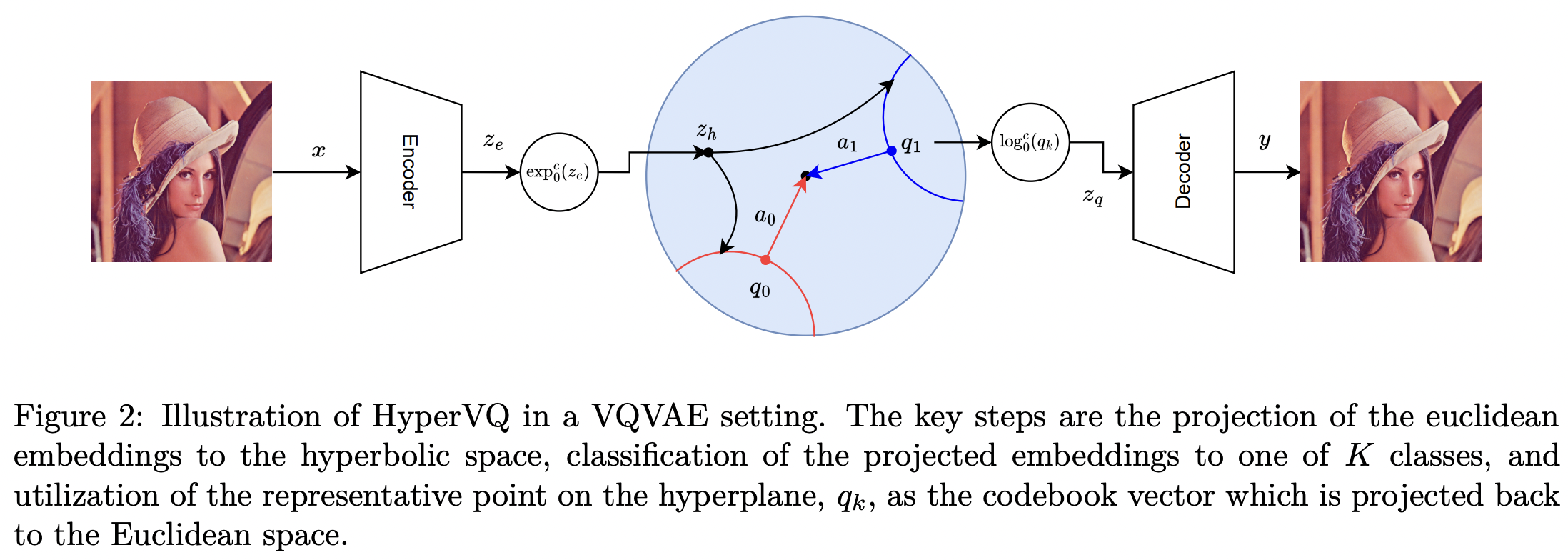 トークン化されたデータで動作するモデルの成功により、特に入力が自然に連続する視覚および聴覚タスクにおいて、効果的なトークン化手法の必要性が高まっています。一般的な解決策は、VQ変分オートエンコーダ(VQVAE)内でベクトル量子化(VQ)を使用し、ユークリッド空間における埋め込みをクラスタリングすることで入力を離散トークンに変換することです。しかし、ユークリッド埋め込みは、多項式体積増加による非効率的なパッキングと分離の制限に悩まされるだけでなく、コードブックベクトルの小さなサブセットのみが有効に活用されるコードブック崩壊も発生しやすい傾向があります。これらの制限に対処するため、我々はHyperVQを導入します。これは、VQを双曲型多項式ロジスティック回帰(MLR)問題として定式化し、双曲型空間における指数関数的な体積増加を利用して崩壊を軽減し、クラスターの分離性を向上させる新しいアプローチです。さらに、HyperVQはコードブックベクトルを双曲型決定超平面の幾何学的表現として表現することで、分離した堅牢な潜在表現を促進します。私たちの実験では、HyperVQ は生成タスクと再構築タスクでは従来の VQ に匹敵し、識別性能ではそれを上回り、より効率的で分離したコードブックを生成することが実証されています。
トークン化されたデータで動作するモデルの成功により、特に入力が自然に連続する視覚および聴覚タスクにおいて、効果的なトークン化手法の必要性が高まっています。一般的な解決策は、VQ変分オートエンコーダ(VQVAE)内でベクトル量子化(VQ)を使用し、ユークリッド空間における埋め込みをクラスタリングすることで入力を離散トークンに変換することです。しかし、ユークリッド埋め込みは、多項式体積増加による非効率的なパッキングと分離の制限に悩まされるだけでなく、コードブックベクトルの小さなサブセットのみが有効に活用されるコードブック崩壊も発生しやすい傾向があります。これらの制限に対処するため、我々はHyperVQを導入します。これは、VQを双曲型多項式ロジスティック回帰(MLR)問題として定式化し、双曲型空間における指数関数的な体積増加を利用して崩壊を軽減し、クラスターの分離性を向上させる新しいアプローチです。さらに、HyperVQはコードブックベクトルを双曲型決定超平面の幾何学的表現として表現することで、分離した堅牢な潜在表現を促進します。私たちの実験では、HyperVQ は生成タスクと再構築タスクでは従来の VQ に匹敵し、識別性能ではそれを上回り、より効率的で分離したコードブックを生成することが実証されています。
EDM-TTS: Efficient Dual-Stage Masked Modeling for Alignment-Free Text-to-Speech Synthesis
Nabarun Goswami, Hanqin Wang, Tatsuya Harada
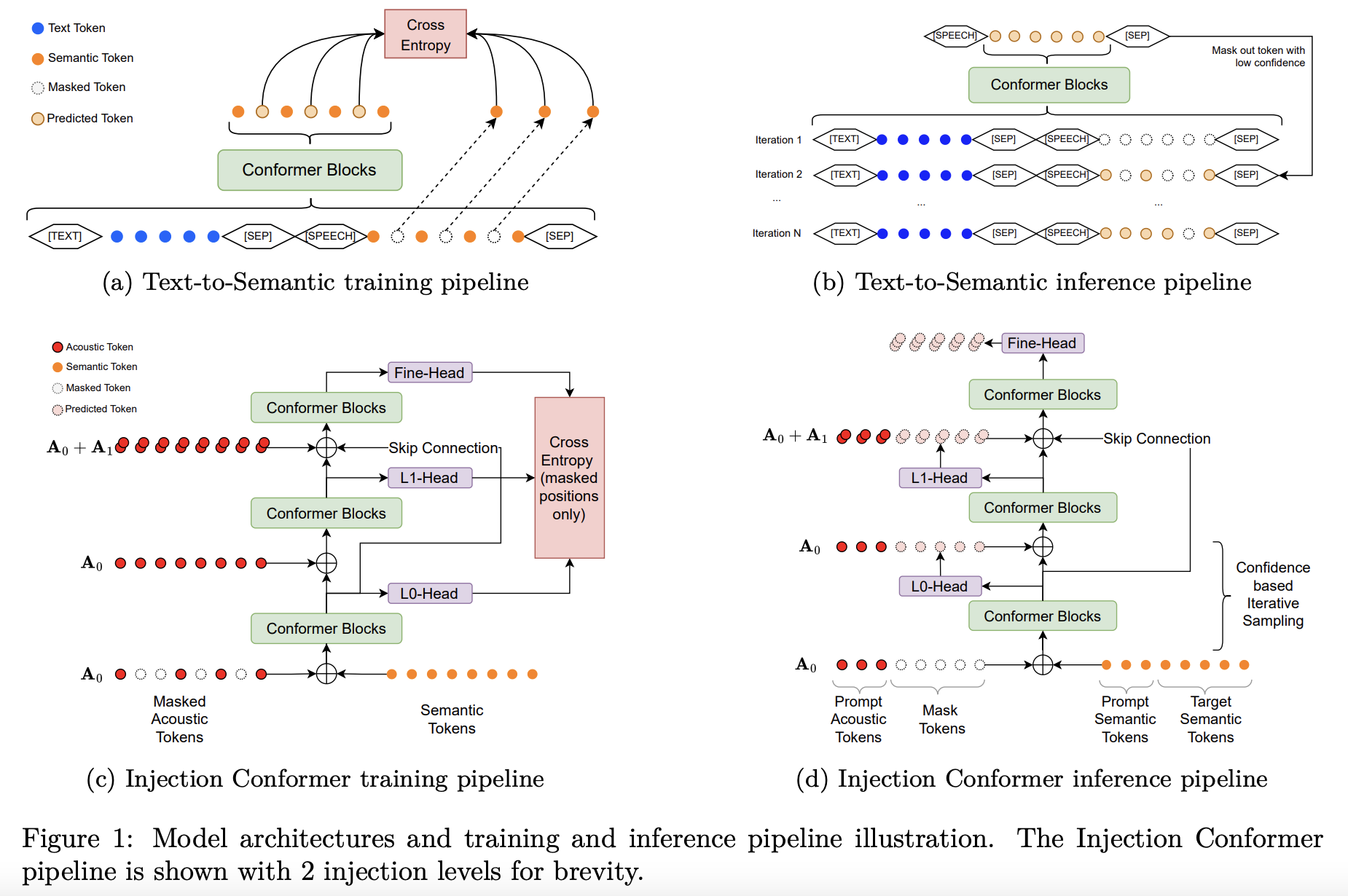 トークン化音声モデリングは、ゼロショットテキスト音声合成(TTS)機能を大幅に向上させました。事実上の最も一般的なアプローチは、テキストから意味情報への変換(T2S)と、それに続く意味情報から音響情報への変換(S2A)という2段階のプロセスです。
文献では、これらの両方の段階において、自己回帰(AR)法と非自己回帰(NAR)法がいくつか検討されています。ARモデルは最先端の性能を達成しますが、トークンごとの生成は推論の効率を低下させます。一方、NAR法はより効率的ですが、中間表現をアップサンプリングするために明示的なアライメントが必要であり、より自然な韻律を実現するモデルの能力に制約が生じます。
これらの問題を克服するために、我々は、T2Sステージにアライメントフリーのマスク生成アプローチを採用し、明示的なアライナーの制約を克服しながらNAR法の効率性を維持する効率的なデュアルステージMasked TTS (EDM-TTS)モデルを提案します。S2Aステージでは、異なる音響量子化レベル間の条件依存性を効果的にモデル化し、マスク言語モデリング目標によって最適化された、新しいInjection Conformerアーキテクチャを使用した革新的なNARアプローチを導入し、ゼロショット音声生成を可能にします。
評価では、EDM-TTSの優れた推論効率だけでなく、最先端の高品質ゼロショット音声品質、自然さ、話者類似性も実証しました。
トークン化音声モデリングは、ゼロショットテキスト音声合成(TTS)機能を大幅に向上させました。事実上の最も一般的なアプローチは、テキストから意味情報への変換(T2S)と、それに続く意味情報から音響情報への変換(S2A)という2段階のプロセスです。
文献では、これらの両方の段階において、自己回帰(AR)法と非自己回帰(NAR)法がいくつか検討されています。ARモデルは最先端の性能を達成しますが、トークンごとの生成は推論の効率を低下させます。一方、NAR法はより効率的ですが、中間表現をアップサンプリングするために明示的なアライメントが必要であり、より自然な韻律を実現するモデルの能力に制約が生じます。
これらの問題を克服するために、我々は、T2Sステージにアライメントフリーのマスク生成アプローチを採用し、明示的なアライナーの制約を克服しながらNAR法の効率性を維持する効率的なデュアルステージMasked TTS (EDM-TTS)モデルを提案します。S2Aステージでは、異なる音響量子化レベル間の条件依存性を効果的にモデル化し、マスク言語モデリング目標によって最適化された、新しいInjection Conformerアーキテクチャを使用した革新的なNARアプローチを導入し、ゼロショット音声生成を可能にします。
評価では、EDM-TTSの優れた推論効率だけでなく、最先端の高品質ゼロショット音声品質、自然さ、話者類似性も実証しました。
Proceedings of the Reinforcement Learning Conference (RLC), 2025
Offline Reinforcement Learning with Wasserstein Regularization via Optimal Transport Maps
Motoki Omura, Yusuke Mukuta, Kazuki Ota, Takayuki Osa, Tatsuya Harada
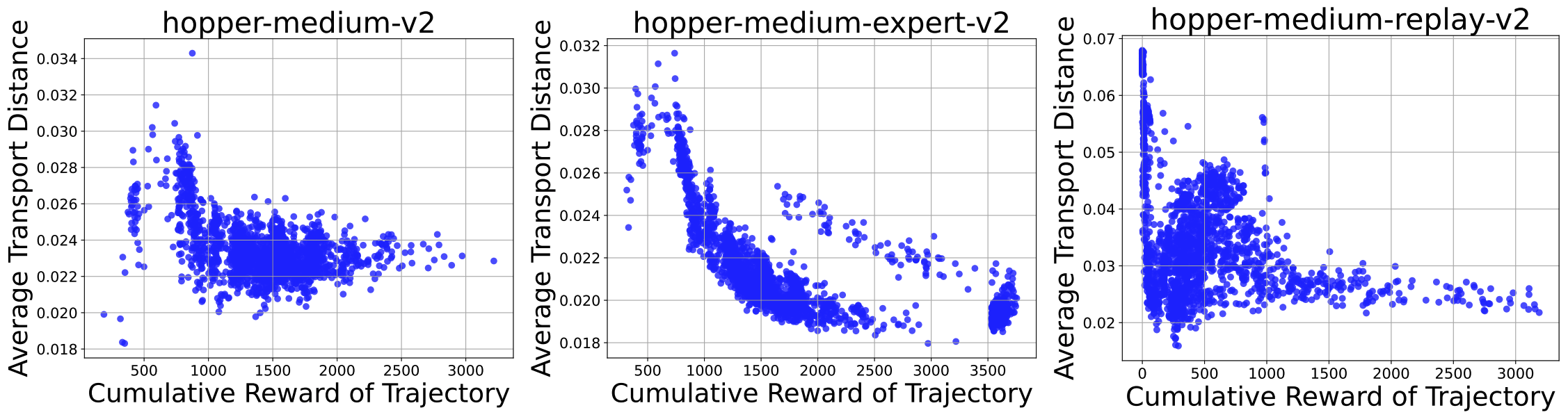 オフライン強化学習(RL)は、静的なデータセットから最適な方策を学習することを目的としており、特にロボティクスのようにデータ収集が高コストな状況で有用です。オフラインRLにおける大きな課題の一つは「分布のずれ」であり、これは学習された方策がデータセットの分布から逸脱し、分布外の信頼性の低い行動を引き起こす可能性があるという問題です。この問題を緩和するために、正則化が用いられています。多くの既存手法では、f-ダイバージェンスなどの密度比に基づく指標を正則化に使用していますが、本研究では、分布外データに対しても頑健で、行動間の類似性を捉えるワッサースタイン距離を用いた手法を提案します。本手法では、Input Convex Neural Networks(ICNNs)を用いて最適輸送写像をモデル化し、識別器を使わずにワッサースタイン距離を計算することで、敵対的学習を回避し、安定した学習を可能にします。本手法は、D4RLベンチマークデータセットにおいて、広く使われている既存手法と同等またはそれ以上の性能を示しました。
オフライン強化学習(RL)は、静的なデータセットから最適な方策を学習することを目的としており、特にロボティクスのようにデータ収集が高コストな状況で有用です。オフラインRLにおける大きな課題の一つは「分布のずれ」であり、これは学習された方策がデータセットの分布から逸脱し、分布外の信頼性の低い行動を引き起こす可能性があるという問題です。この問題を緩和するために、正則化が用いられています。多くの既存手法では、f-ダイバージェンスなどの密度比に基づく指標を正則化に使用していますが、本研究では、分布外データに対しても頑健で、行動間の類似性を捉えるワッサースタイン距離を用いた手法を提案します。本手法では、Input Convex Neural Networks(ICNNs)を用いて最適輸送写像をモデル化し、識別器を使わずにワッサースタイン距離を計算することで、敵対的学習を回避し、安定した学習を可能にします。本手法は、D4RLベンチマークデータセットにおいて、広く使われている既存手法と同等またはそれ以上の性能を示しました。
Proceedings of the International Conference on Machine Learning (ICML), 2025
Gradual Transition from Bellman Optimality Operator to Bellman Operator in Online Reinforcement Learning
Motoki Omura, Kazuki Ota, Takayuki Osa, Yusuke Mukuta, Tatsuya Harada
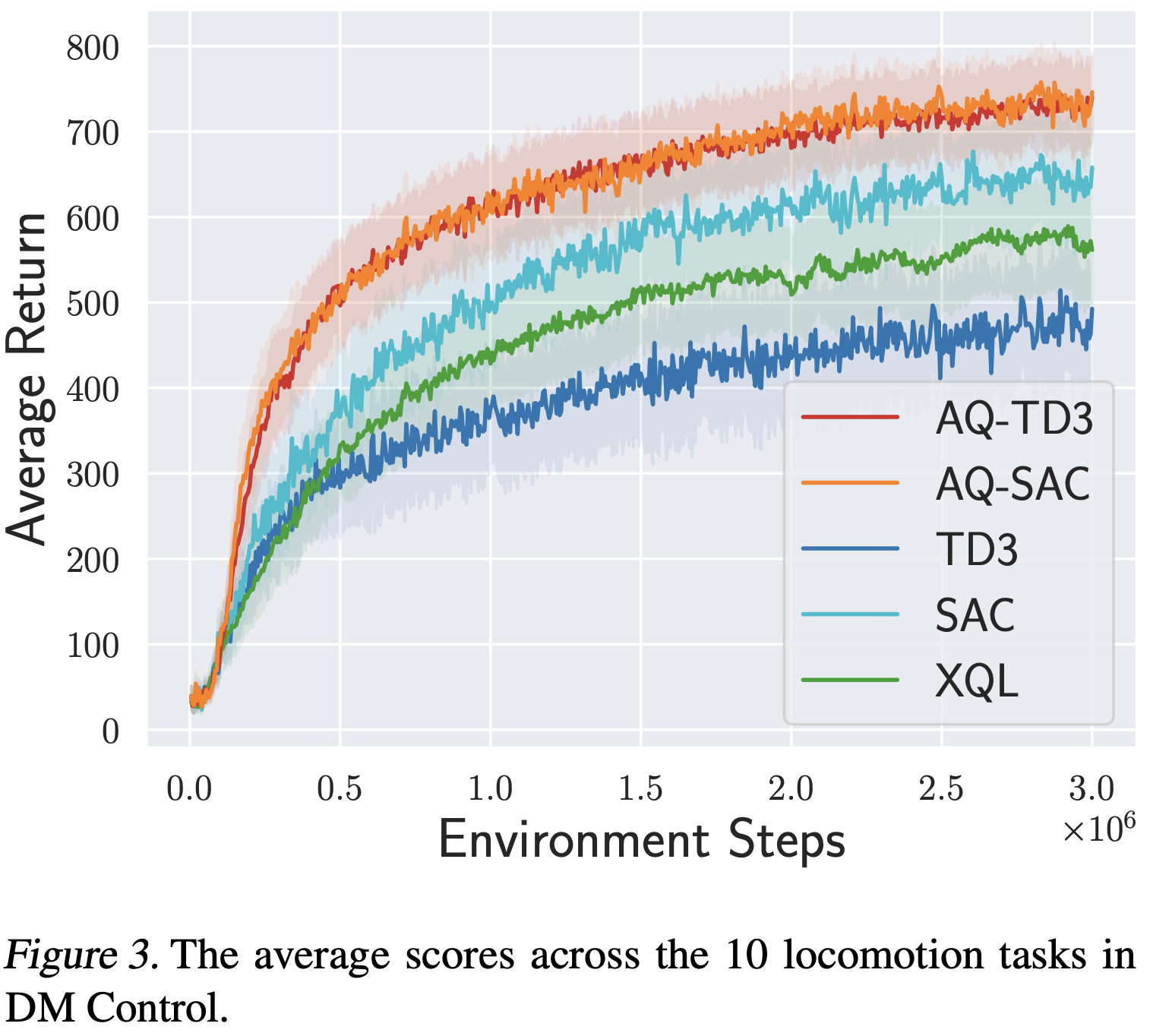 連続行動空間においては、Actor-critic 法がオンライン強化学習で広く用いられています。しかし、一般にベルマン最適作用素を用いて最適価値関数をモデル化する離散行動空間向けのRLアルゴリズムとは異なり、連続動作向けのRLアルゴリズムでは通常、現在の方策に対するQ値をベルマン作用素を用いてモデル化します。こうした連続行動向けアルゴリズムは方策の更新のみに依存して性能を向上させるため、サンプル効率が低いという問題があります。本研究では、Actor-critic の枠組みにベルマン最適作用素を取り入れる有効性を検証します。単純な環境での実験により、最適値のモデル化が学習を加速する一方で、過大評価バイアスを招くことが示されました。これに対処するために、本研究ではベルマン最適作用素からベルマン作用素へ徐々に移行する減衰手法を提案し、学習の加速とバイアスの緩和を両立させます。我々の手法は、TD3およびSACと組み合わせることで、多様な歩行および操作タスクにおいて既存手法を大きく上回る性能を示し、最適性に関連するハイパーパラメータに対するロバスト性も向上することが確認されました。
連続行動空間においては、Actor-critic 法がオンライン強化学習で広く用いられています。しかし、一般にベルマン最適作用素を用いて最適価値関数をモデル化する離散行動空間向けのRLアルゴリズムとは異なり、連続動作向けのRLアルゴリズムでは通常、現在の方策に対するQ値をベルマン作用素を用いてモデル化します。こうした連続行動向けアルゴリズムは方策の更新のみに依存して性能を向上させるため、サンプル効率が低いという問題があります。本研究では、Actor-critic の枠組みにベルマン最適作用素を取り入れる有効性を検証します。単純な環境での実験により、最適値のモデル化が学習を加速する一方で、過大評価バイアスを招くことが示されました。これに対処するために、本研究ではベルマン最適作用素からベルマン作用素へ徐々に移行する減衰手法を提案し、学習の加速とバイアスの緩和を両立させます。我々の手法は、TD3およびSACと組み合わせることで、多様な歩行および操作タスクにおいて既存手法を大きく上回る性能を示し、最適性に関連するハイパーパラメータに対するロバスト性も向上することが確認されました。
The IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025
A Theory of Learning Unified Model via Knowledge Integration from Label Space Varying Domains
Dexuan Zhang, Thomas Westfechtel, Tatsuya Harada
 既存のドメイン適応システムは、実装時に新しいクラスが現れる現実世界の問題に適用する際、特に、ラベル付きターゲットデータがいくつか与えられているにもかかわらず、複数のソースドメインがラベルスペースを共有しないソースフリーシナリオに関しては現状比較的に困難です。これに対処するために、私たちは挑戦的な問題設定、つまりマルチソースの半教師ありオープンセットドメイン適応を検討し、ジョイントエラーによる学習理論を提案し、強力なドメインシフトに効果的に取り組みます。アルゴリズムをソースフリーのケースに一般化するために、計算効率が高く、アーキテクチャが柔軟なアテンションを用いた特徴生成モジュールを導入します。さまざまなデータセットでの広範な実験により、提案されたアルゴリズムがベースラインよりも大幅に改善されていることが証明されています。
既存のドメイン適応システムは、実装時に新しいクラスが現れる現実世界の問題に適用する際、特に、ラベル付きターゲットデータがいくつか与えられているにもかかわらず、複数のソースドメインがラベルスペースを共有しないソースフリーシナリオに関しては現状比較的に困難です。これに対処するために、私たちは挑戦的な問題設定、つまりマルチソースの半教師ありオープンセットドメイン適応を検討し、ジョイントエラーによる学習理論を提案し、強力なドメインシフトに効果的に取り組みます。アルゴリズムをソースフリーのケースに一般化するために、計算効率が高く、アーキテクチャが柔軟なアテンションを用いた特徴生成モジュールを導入します。さまざまなデータセットでの広範な実験により、提案されたアルゴリズムがベースラインよりも大幅に改善されていることが証明されています。
Luminance-GS: Adapting 3D Gaussian Splatting to Challenging Lighting Conditions with View-Adaptive Curve Adjustment
Ziteng Cui, Xuangeng Chu, Tatsuya Harada
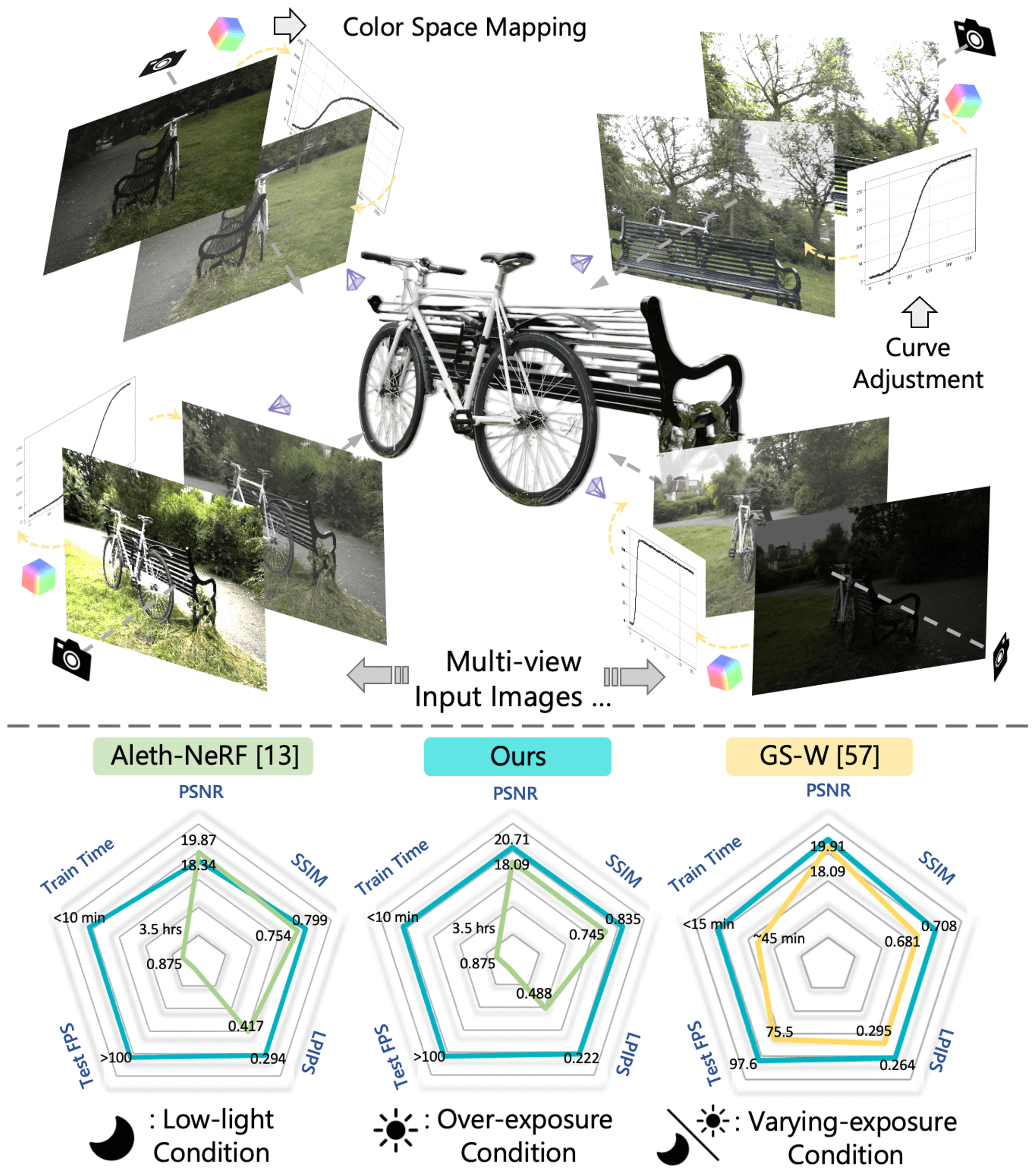 多様な実世界の照明条件下で高品質な写真を撮影することは困難です。自然光(例:低照度)やカメラの露出設定(例:露光時間)は、画像品質に強く影響を与えます。この問題は、マルチビュー環境ではさらに深刻になり、各視点ごとに異なる照明条件や画像信号処理(ISP)設定が適用されるため、視点間で輝度の不整合が生じます。これらの照明劣化や視点ごとの変動は、NeRFおよび3D Gaussian Splatting(3DGS)に基づく新規視点合成(NVS)フレームワークにとって大きな課題となります。
この課題に対処するため、本研究では Luminance-GS を提案します。Luminance-GS は、3DGS を用いて多様で困難な照明条件下でも高品質な新規視点合成を実現する新しいアプローチです。本手法では、視点ごとの色空間マッピングと視点適応型のカーブ調整を採用することで、3DGS の明示的表現を変更することなく、低照度、過露光、露出変動など、さまざまな照明条件下で最先端(SOTA)の結果を達成します。従来の NeRF および 3DGS ベースラインと比較して、Luminance-GS は再構成品質を向上させながら、リアルタイムなレンダリング速度を提供します。ソースコードも公開予定です。
多様な実世界の照明条件下で高品質な写真を撮影することは困難です。自然光(例:低照度)やカメラの露出設定(例:露光時間)は、画像品質に強く影響を与えます。この問題は、マルチビュー環境ではさらに深刻になり、各視点ごとに異なる照明条件や画像信号処理(ISP)設定が適用されるため、視点間で輝度の不整合が生じます。これらの照明劣化や視点ごとの変動は、NeRFおよび3D Gaussian Splatting(3DGS)に基づく新規視点合成(NVS)フレームワークにとって大きな課題となります。
この課題に対処するため、本研究では Luminance-GS を提案します。Luminance-GS は、3DGS を用いて多様で困難な照明条件下でも高品質な新規視点合成を実現する新しいアプローチです。本手法では、視点ごとの色空間マッピングと視点適応型のカーブ調整を採用することで、3DGS の明示的表現を変更することなく、低照度、過露光、露出変動など、さまざまな照明条件下で最先端(SOTA)の結果を達成します。従来の NeRF および 3DGS ベースラインと比較して、Luminance-GS は再構成品質を向上させながら、リアルタイムなレンダリング速度を提供します。ソースコードも公開予定です。
The Thirteenth International Conference on Learning Representations, ICLR 2025
T2V2: A Unified Non-Autoregressive Model for Speech Recognition and Synthesis via Multitask Learning
Nabarun Goswami, Hanqin Wang, Tatsuya Harada
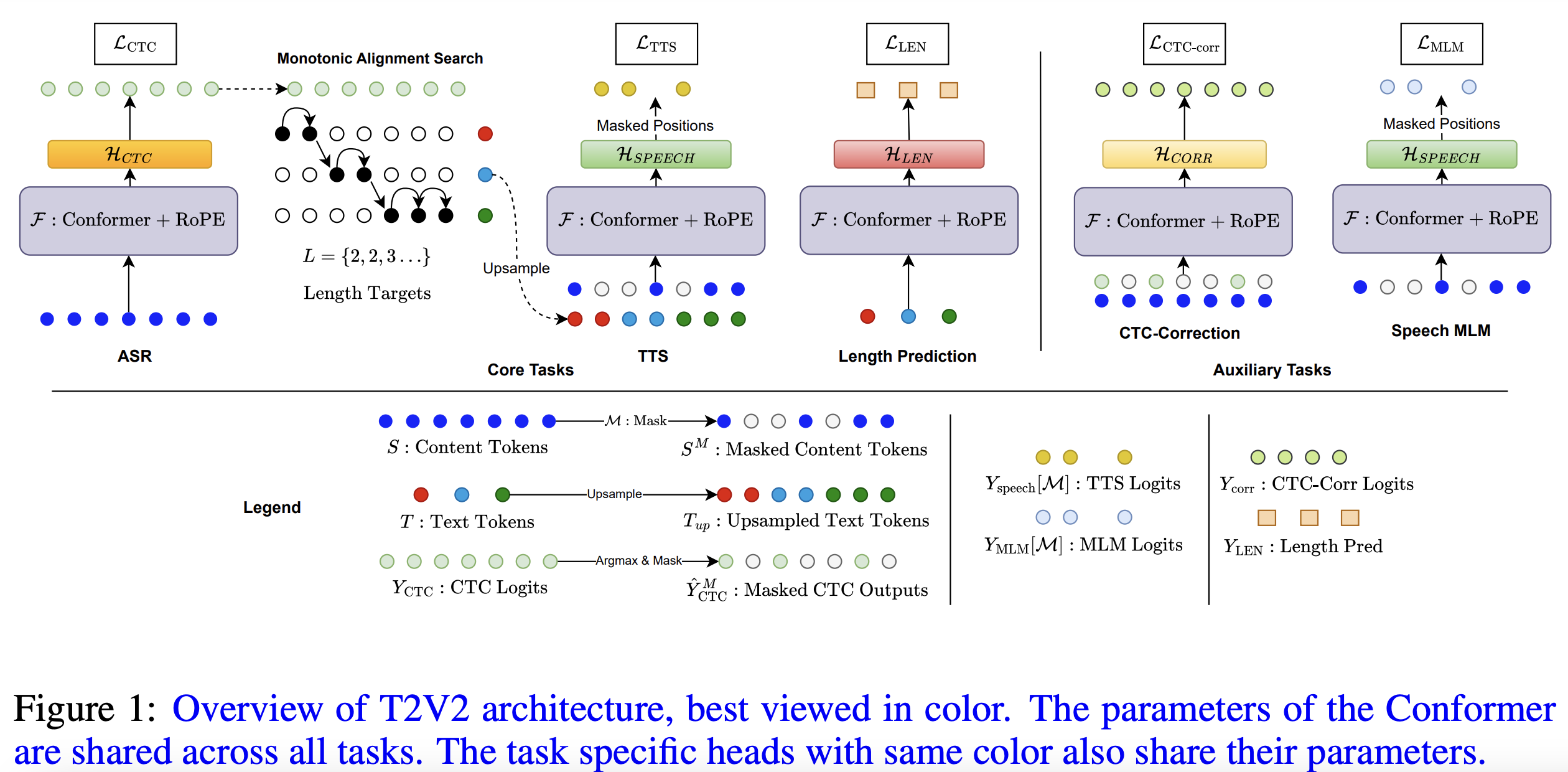 自動音声認識 (ASR) とテキスト読み上げ (TTS) 合成の両方を同じフレームワーク内で実行できる統合非自己回帰モデルである T2V2 (Text to Voice および Voice to Text) を紹介します。T2V2 は、回転位置埋め込みを備えた共有 Conformer バックボーンを使用してこれらのコアタスクを効率的に処理します。ASR はコネクショニスト時間分類 (CTC) 損失を使用してトレーニングされ、TTS はマスク言語モデリング (MLM) 損失を使用してトレーニングされます。モデルは離散トークンで動作し、音声トークンは自己教師学習モデルからの特徴のクラスタリングによって生成されます。パフォーマンスをさらに向上させるために、補助タスクを導入します。音声埋め込みからのコンテキスト情報を使用して生の ASR 出力を改良する CTC エラー訂正と、分類子を使用しないガイダンスで TTS を改善できるようにする無条件音声 MLM です。私たちの方法は自己完結型で、中間 CTC 出力を利用して、外部アライナーに依存せずに Monotonic Alignment Search を使用してテキストと音声をアラインメントします。 T2V2 フレームワークの有効性を検証するために広範な実験評価を実施し、TTS タスクで最先端のパフォーマンスと離散 ASR で競争力のあるパフォーマンスを達成しました。
自動音声認識 (ASR) とテキスト読み上げ (TTS) 合成の両方を同じフレームワーク内で実行できる統合非自己回帰モデルである T2V2 (Text to Voice および Voice to Text) を紹介します。T2V2 は、回転位置埋め込みを備えた共有 Conformer バックボーンを使用してこれらのコアタスクを効率的に処理します。ASR はコネクショニスト時間分類 (CTC) 損失を使用してトレーニングされ、TTS はマスク言語モデリング (MLM) 損失を使用してトレーニングされます。モデルは離散トークンで動作し、音声トークンは自己教師学習モデルからの特徴のクラスタリングによって生成されます。パフォーマンスをさらに向上させるために、補助タスクを導入します。音声埋め込みからのコンテキスト情報を使用して生の ASR 出力を改良する CTC エラー訂正と、分類子を使用しないガイダンスで TTS を改善できるようにする無条件音声 MLM です。私たちの方法は自己完結型で、中間 CTC 出力を利用して、外部アライナーに依存せずに Monotonic Alignment Search を使用してテキストと音声をアラインメントします。 T2V2 フレームワークの有効性を検証するために広範な実験評価を実施し、TTS タスクで最先端のパフォーマンスと離散 ASR で競争力のあるパフォーマンスを達成しました。