2024 年発表論文概要
Neurocomputing
Defender of privacy and fairness: Tiny but reversible generative model via mutually collaborative knowledge distillation
Sissi Xiaoxiao Wu , Zehong Huang , Zhicong Liang , Lin Gu, Tatsuya Harada, Zheng Li, Yingying Zhu
 大量のデータを共有して強力な人工知能(AI)モデルを訓練することは、プライバシーや公平性に関する懸念を引き起こします。従来の可逆的な匿名化技術は、プライバシー保護や公平性の向上に非常に効果的ですが、これらの技術は複雑な可逆生成モデルに依存しているため、クラウドや画像の元データと独立したサーバー上でのみ実行可能です。例えば、データ送信中に盗聴などのプライバシー侵害のリスクがある可能性があります。そこで、私たちは新しい「相互協調的知識蒸留戦略」を提案しました。これにより、小型で可逆な生成モデルを訓練し、埋め込み型デバイスでプライバシーに敏感なデータを匿名化できるシステムを構築することが可能になります。このシステムにより、データの送信元からプライバシー保護とセキュリティ強化が実現します。提案した相互協調的知識蒸留法では、生成モデルの可逆性を活用します。具体的には、教師エンコーダーと生徒デコーダー、または教師デコーダーと生徒エンコーダーをペアにし、元の画像空間や潜在空間を再構築することで、生徒モデルを訓練します。この方法により、小型化された生徒モデルがデバイスに組み込めるようになります。私たちのシステムは、NVIDIA Jetson TX2デバイスでリアルタイム動作するように設計されており、評価実験では、顔画像の匿名化によるプライバシー保護と公平性の向上が確認されています。また、下流タスクへの影響を最小限に抑えることも実証されました。コードはGitHubで公開予定です。
大量のデータを共有して強力な人工知能(AI)モデルを訓練することは、プライバシーや公平性に関する懸念を引き起こします。従来の可逆的な匿名化技術は、プライバシー保護や公平性の向上に非常に効果的ですが、これらの技術は複雑な可逆生成モデルに依存しているため、クラウドや画像の元データと独立したサーバー上でのみ実行可能です。例えば、データ送信中に盗聴などのプライバシー侵害のリスクがある可能性があります。そこで、私たちは新しい「相互協調的知識蒸留戦略」を提案しました。これにより、小型で可逆な生成モデルを訓練し、埋め込み型デバイスでプライバシーに敏感なデータを匿名化できるシステムを構築することが可能になります。このシステムにより、データの送信元からプライバシー保護とセキュリティ強化が実現します。提案した相互協調的知識蒸留法では、生成モデルの可逆性を活用します。具体的には、教師エンコーダーと生徒デコーダー、または教師デコーダーと生徒エンコーダーをペアにし、元の画像空間や潜在空間を再構築することで、生徒モデルを訓練します。この方法により、小型化された生徒モデルがデバイスに組み込めるようになります。私たちのシステムは、NVIDIA Jetson TX2デバイスでリアルタイム動作するように設計されており、評価実験では、顔画像の匿名化によるプライバシー保護と公平性の向上が確認されています。また、下流タスクへの影響を最小限に抑えることも実証されました。コードはGitHubで公開予定です。
2024 IEEE-RAS 23rd International Conference on Humanoid Robots (Humanoids) 2024 (Oral)
Latent Space Curriculum Reinforcement Learning in High-Dimensional Contextual Spaces and Its Application to Robotic Piano Playing
Haruki Abe, Takayuki Osa, Motoki Omura, Jen-Yen Chang, Tatsuya Harada
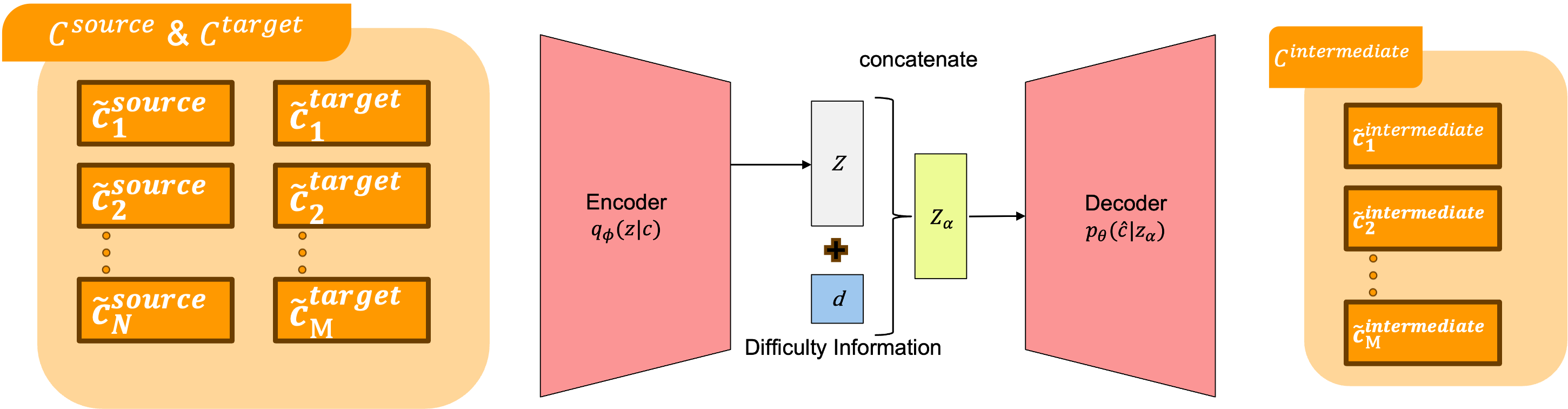 カリキュラム強化学習(CRL)は、ロボットハンドの操作のような複雑なタスクにおいて最適なポリシーを学習することを可能にします。しかし、時間的に連続した目標を持つ高次元のコンテキストを持つタスクでは、従来の研究は計算コストの増加や学習を促進するための適切なカリキュラムの作成が困難であるという問題に直面していました。そこで本研究では、高次元のコンテキストを適切にセグメント化し、生成モデルを用いて学習する新しいCRL手法を提案します。さらに、生成モデルに難易度情報を組み込むことで、学習をさらに強化する方法も提案します。最後に、提案手法がRoboPianistにおける複雑なタスクでの学習を大幅に改善することを実験的に確認しました。
カリキュラム強化学習(CRL)は、ロボットハンドの操作のような複雑なタスクにおいて最適なポリシーを学習することを可能にします。しかし、時間的に連続した目標を持つ高次元のコンテキストを持つタスクでは、従来の研究は計算コストの増加や学習を促進するための適切なカリキュラムの作成が困難であるという問題に直面していました。そこで本研究では、高次元のコンテキストを適切にセグメント化し、生成モデルを用いて学習する新しいCRL手法を提案します。さらに、生成モデルに難易度情報を組み込むことで、学習をさらに強化する方法も提案します。最後に、提案手法がRoboPianistにおける複雑なタスクでの学習を大幅に改善することを実験的に確認しました。
IEEE/CVF Winter Conference on Applications of Computer Vision(WACV) 2025
Combining inherent knowledge of vision-language models with unsupervised domain adaptation through weak-strong guidance
Thomas Westfechtel, Dexuan Zhang, Tatsuya Harada
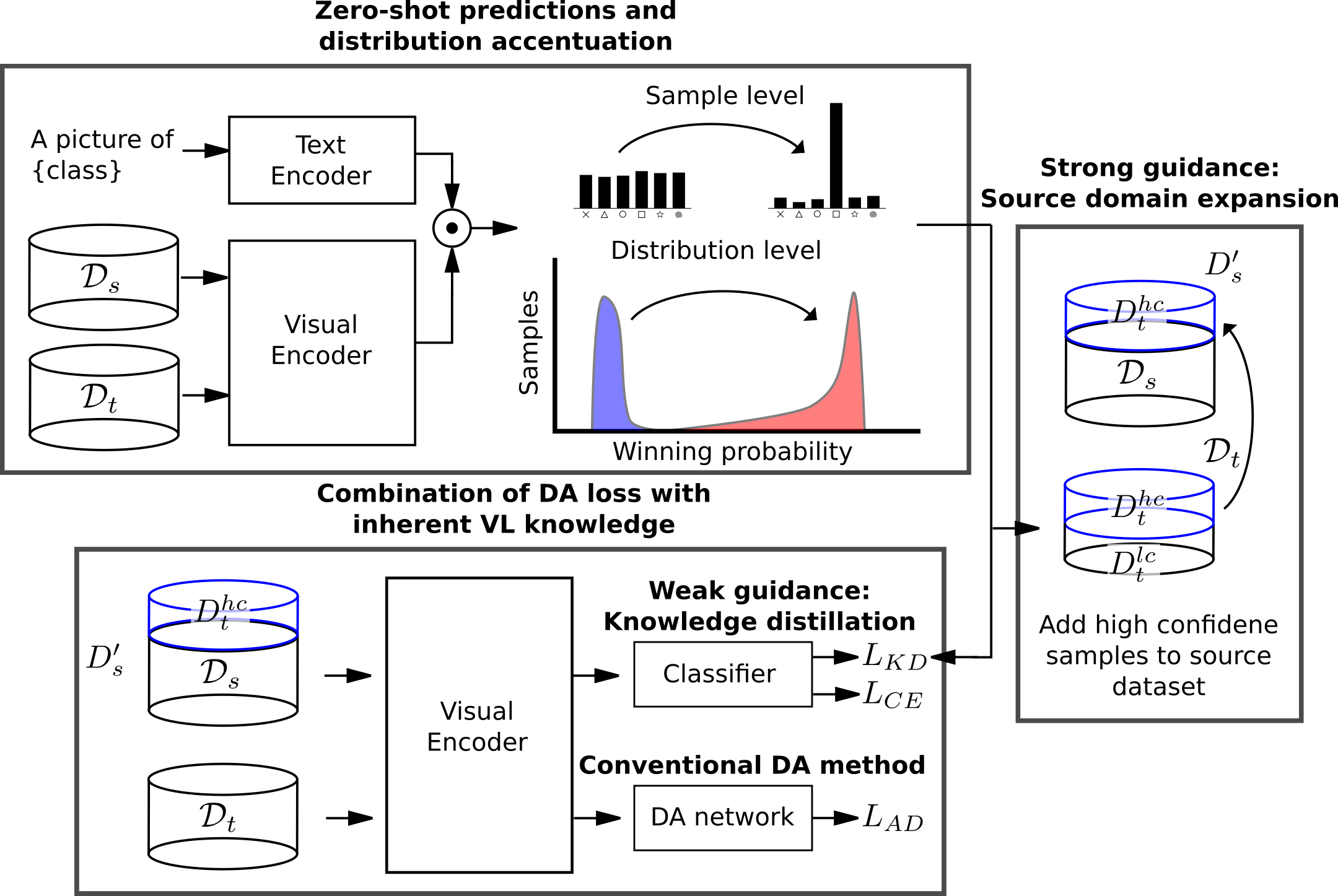 教師なし領域適応(UDA)は、ラベル付けされたソースデータセットを活用し、その知識を類似しているが異なるターゲットデータセットに転送することで、データのラベル付けという面倒な作業を克服しようとするものである。一方、現在の視覚言語モデルは、顕著なゼロショット予測能力を示す。本研究では、UDAによって得られた知識を、視覚言語モデルが本来持っている知識と組み合わせる。
ソースとターゲットのデータセットを整合させるためにゼロショット予測を用いる、強弱ガイダンス学習スキームを導入する。強いガイダンスのために、我々はソースデータセットをターゲットデータセットの最も信頼できるサンプルで拡張する。さらに、弱いガイダンスとして知識蒸留損失を採用する。強いガイダンスはハードラベルを用いるが、ターゲットデータセットから最も確信度の高い予測にのみ適用される。逆に弱いガイダンスはデータセット全体に適用されるが、ソフトラベルを使用する。弱いガイダンスは、(調整された)ゼロショット予測による知識蒸留損失として実装される。我々は、本手法が視覚言語モデルに対する即応的適応技術を補完し、その恩恵を受けることを示す。
我々は3つのベンチマーク(OfficeHome、VisDA、DomainNet)で実験とアブレーション研究を行い、最先端の手法を凌駕した。我々のアブレーション研究はさらに、我々のアルゴリズムの様々な構成要素の貢献を実証する。
教師なし領域適応(UDA)は、ラベル付けされたソースデータセットを活用し、その知識を類似しているが異なるターゲットデータセットに転送することで、データのラベル付けという面倒な作業を克服しようとするものである。一方、現在の視覚言語モデルは、顕著なゼロショット予測能力を示す。本研究では、UDAによって得られた知識を、視覚言語モデルが本来持っている知識と組み合わせる。
ソースとターゲットのデータセットを整合させるためにゼロショット予測を用いる、強弱ガイダンス学習スキームを導入する。強いガイダンスのために、我々はソースデータセットをターゲットデータセットの最も信頼できるサンプルで拡張する。さらに、弱いガイダンスとして知識蒸留損失を採用する。強いガイダンスはハードラベルを用いるが、ターゲットデータセットから最も確信度の高い予測にのみ適用される。逆に弱いガイダンスはデータセット全体に適用されるが、ソフトラベルを使用する。弱いガイダンスは、(調整された)ゼロショット予測による知識蒸留損失として実装される。我々は、本手法が視覚言語モデルに対する即応的適応技術を補完し、その恩恵を受けることを示す。
我々は3つのベンチマーク(OfficeHome、VisDA、DomainNet)で実験とアブレーション研究を行い、最先端の手法を凌駕した。我々のアブレーション研究はさらに、我々のアルゴリズムの様々な構成要素の貢献を実証する。
Physiology-aware PolySnake For Coronary Vessel Segmentation
Yizhe Ruan, Lin Gu ,Yusuke Kurose , Junichi Iho, Youji Tokunaga, Makoto Horie, Yusaku Hayashi, Keisuke Nishizawa, Yasushi Koyama,Tatsuya Harada
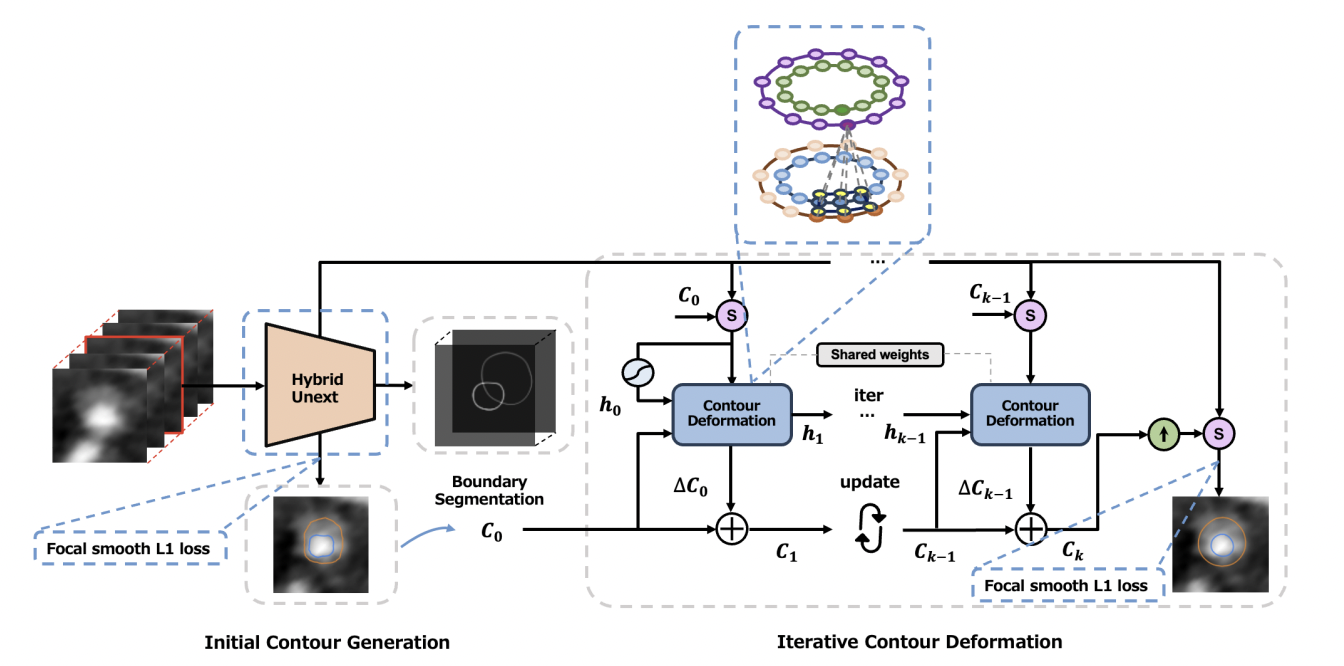 冠動脈疾患(CAD)は重大な健康リスクをもたらし、効果的な治療を可能にするために早期発見の必要性を強調しています。冠状動脈コンピュータ断層撮影血管造影法 (CCTA) イメージングを利用したコンピュータ支援の検出および診断システムは、CAD 検出において有望であることが実証されています。深層学習の最近の進歩により、これらの技術を使用して CCTA 画像からの CAD 検出を自動化することへの関心が高まっています。冠状血管の正確なセグメンテーションは、CCTA 画像を使用した CAD 検出および診断にとって非常に重要です。自動 CAD 検出におけるディープラーニングの有望なパフォーマンスにもかかわらず、特に不健康な血管内に存在するプラークの不均衡に対処する際には課題が残っています。
この論文では、冠状動脈の生理機能を明確に考慮した冠状血管セグメンテーションへの新しいアプローチを紹介します。生理学を意識したパイプラインは 3 つの主要なコンポーネントで構成されています。 まず、隣接するスライス間の 3D 空間関係を組み込むことで動脈境界をセグメント化し、初期境界輪郭を予測するハイブリッド Unext アーキテクチャを設計しました。次に、反復輪郭変形のためのマルチクラス円形畳み込みを提案し、最初の輪郭ペアの反復改良を通じて動脈壁の内側と外側の境界のよく接続された輪郭ペアを生成します。さらに、不健康な血管内のプラークによって引き起こされる暗黙的なクラスの不均衡に対処するために、焦点のスムーズな L1 損失を導入し、初期輪郭の精度を明示的に制限して、関係を認識したポリ スネーク ネットワークの堅牢性を強化します。既存のアプローチとの比較および広範な評価により、私たちの方法が各ステップでモデルのパフォーマンスを大幅に向上させ、最終的に冠状血管セグメンテーションで最先端のパフォーマンスを達成することが実証されました。
冠動脈疾患(CAD)は重大な健康リスクをもたらし、効果的な治療を可能にするために早期発見の必要性を強調しています。冠状動脈コンピュータ断層撮影血管造影法 (CCTA) イメージングを利用したコンピュータ支援の検出および診断システムは、CAD 検出において有望であることが実証されています。深層学習の最近の進歩により、これらの技術を使用して CCTA 画像からの CAD 検出を自動化することへの関心が高まっています。冠状血管の正確なセグメンテーションは、CCTA 画像を使用した CAD 検出および診断にとって非常に重要です。自動 CAD 検出におけるディープラーニングの有望なパフォーマンスにもかかわらず、特に不健康な血管内に存在するプラークの不均衡に対処する際には課題が残っています。
この論文では、冠状動脈の生理機能を明確に考慮した冠状血管セグメンテーションへの新しいアプローチを紹介します。生理学を意識したパイプラインは 3 つの主要なコンポーネントで構成されています。 まず、隣接するスライス間の 3D 空間関係を組み込むことで動脈境界をセグメント化し、初期境界輪郭を予測するハイブリッド Unext アーキテクチャを設計しました。次に、反復輪郭変形のためのマルチクラス円形畳み込みを提案し、最初の輪郭ペアの反復改良を通じて動脈壁の内側と外側の境界のよく接続された輪郭ペアを生成します。さらに、不健康な血管内のプラークによって引き起こされる暗黙的なクラスの不均衡に対処するために、焦点のスムーズな L1 損失を導入し、初期輪郭の精度を明示的に制限して、関係を認識したポリ スネーク ネットワークの堅牢性を強化します。既存のアプローチとの比較および広範な評価により、私たちの方法が各ステップでモデルのパフォーマンスを大幅に向上させ、最終的に冠状血管セグメンテーションで最先端のパフォーマンスを達成することが実証されました。
Transactions on Machine Learning Research (TMLR), 2024
Offline Deep Reinforcement Learning for Visual Distractions via Domain Adversarial Training
Jen-Yen Chang, Thomas Westfectel, Takayuki Osa, Tatsuya Harada.
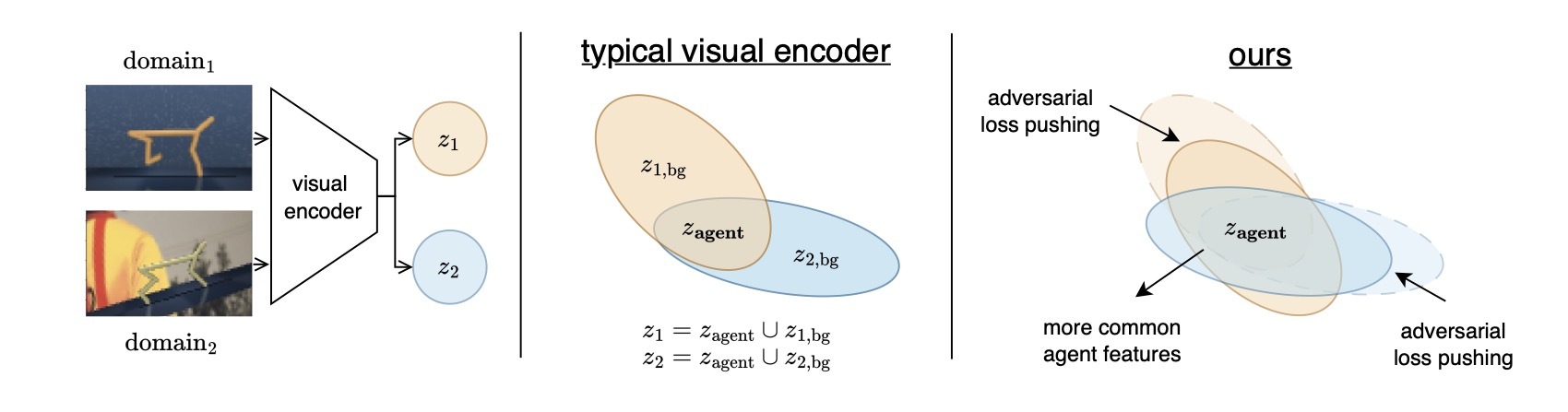 近年、オフライン強化学習(offline RL)の研究は、主に物体の身体の姿勢情報(固有感覚、proprioceptive states)を基にした学習が主流でした。しかし、現実世界では、すべての物体の固有感覚を正確に把握するのは困難です。特に、事前に収集した学習データのみで学習するoffline RLでは、この問題が顕著になります。そのため、画像などの生のデータから学習できるRLエージェントの必要があります。ただし、最近の研究では、評価環境が訓練環境と大きく異なる場合、視覚的な余計な情報(visual distractions)がRLエージェントの性能を大きく下げることが分りました。画像を扱うvisual offline RLにおいて特に重要です。本研究では、この視覚的な余計な情報(visual distractions)の問題を解決するために、敵対的アプローチを提案しました。私たちの敵対的アプローチは、visual distractionsに対してよりロバストな特徴を学習するエージェントを訓練することです。さらに、既存研究のV-D4RLのvisual distractionsデータセットを拡張し、より多くのロコモーションタスクを含まれたデータセットを提案しました。私たちの提案手法は、様々な視覚的集中妨害が存在する環境において、V-D4RLと提案されたデータセットの両方におけるタスクで既存の手法を上回る性能を示しました。Code, Link
近年、オフライン強化学習(offline RL)の研究は、主に物体の身体の姿勢情報(固有感覚、proprioceptive states)を基にした学習が主流でした。しかし、現実世界では、すべての物体の固有感覚を正確に把握するのは困難です。特に、事前に収集した学習データのみで学習するoffline RLでは、この問題が顕著になります。そのため、画像などの生のデータから学習できるRLエージェントの必要があります。ただし、最近の研究では、評価環境が訓練環境と大きく異なる場合、視覚的な余計な情報(visual distractions)がRLエージェントの性能を大きく下げることが分りました。画像を扱うvisual offline RLにおいて特に重要です。本研究では、この視覚的な余計な情報(visual distractions)の問題を解決するために、敵対的アプローチを提案しました。私たちの敵対的アプローチは、visual distractionsに対してよりロバストな特徴を学習するエージェントを訓練することです。さらに、既存研究のV-D4RLのvisual distractionsデータセットを拡張し、より多くのロコモーションタスクを含まれたデータセットを提案しました。私たちの提案手法は、様々な視覚的集中妨害が存在する環境において、V-D4RLと提案されたデータセットの両方におけるタスクで既存の手法を上回る性能を示しました。Code, Link
The Thirty-Eighth Annual Conference on Neural Information Processing Systems (NeurIPS), 2024
Generalizable and Animatable Gaussian Head Avatar
Xuangeng Chu, Tatsuya Harada
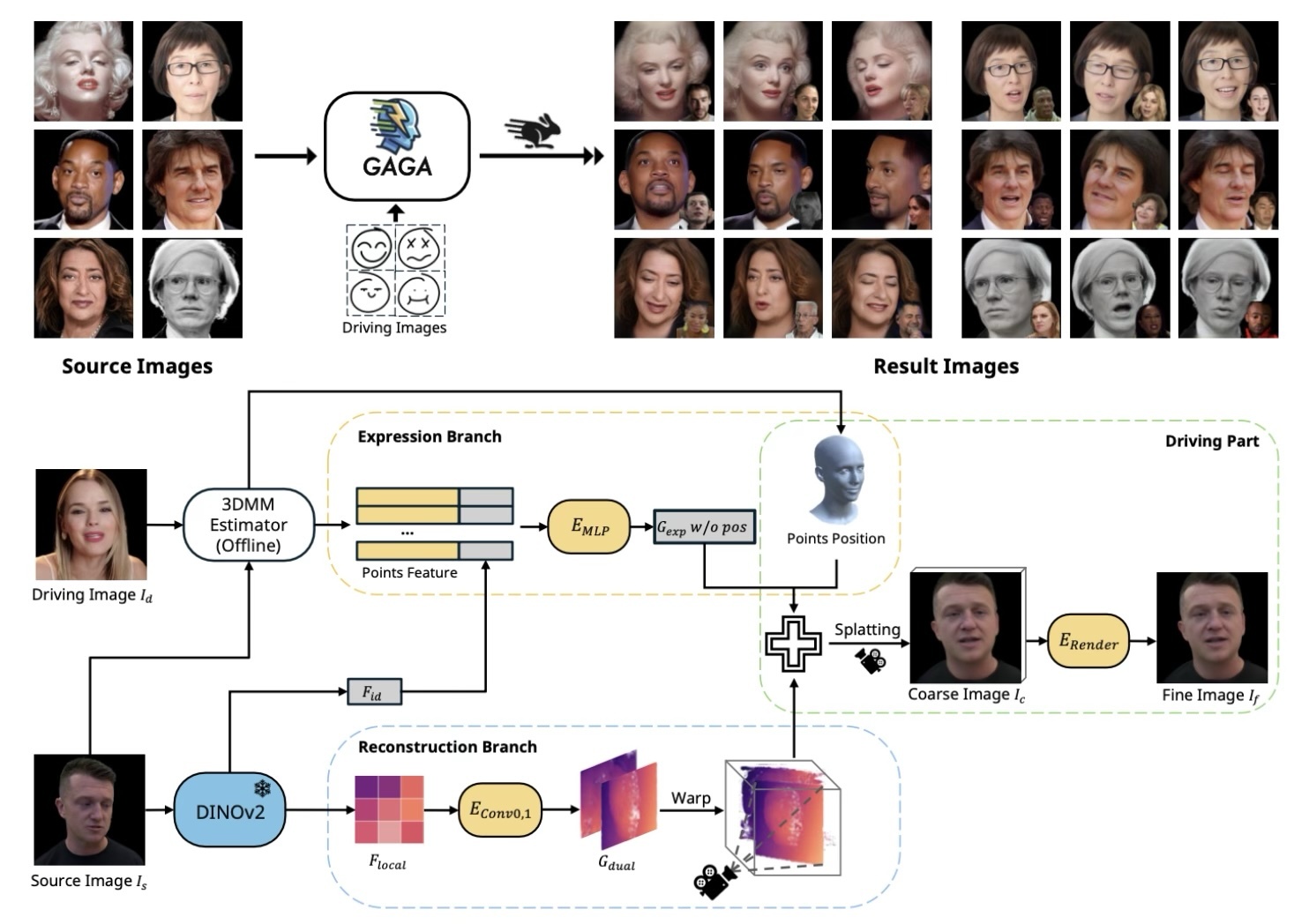 私たちは、初めて一般化可能な3DGSベースのヘッドアバター再構築フレームワークを提案します。従来の方法はニューラルラジアンスフィールドに依存しており、レンダリングに多大なコストがかかり、再現速度が遅いという問題がありました。これらの制約に対処するために、我々は単一の画像から単一のフォワードパスで3Dガウシアンのパラメータを生成します。本研究の主な革新点は、アイデンティティと顔の細部を捉えた高精細な3Dガウシアンを生成するために提案されたデュアルリフティング手法にあります。さらに、グローバルな画像特徴と3D変形モデルを活用して、表情をコントロールするための3Dガウシアンを構築します。トレーニング後、我々のモデルは特定の最適化を行わずに見たことのないアイデンティティを再構築し、リアルタイムの速度で再現レンダリングを実行することができます。実験結果は、我々の手法が再構築の質や表情の正確さにおいて従来の方法と比較して優れた性能を示すことを明らかにしています。我々の手法は、今後の研究の新たなベンチマークを確立し、デジタルアバターの応用を前進させることができると信じています。
私たちは、初めて一般化可能な3DGSベースのヘッドアバター再構築フレームワークを提案します。従来の方法はニューラルラジアンスフィールドに依存しており、レンダリングに多大なコストがかかり、再現速度が遅いという問題がありました。これらの制約に対処するために、我々は単一の画像から単一のフォワードパスで3Dガウシアンのパラメータを生成します。本研究の主な革新点は、アイデンティティと顔の細部を捉えた高精細な3Dガウシアンを生成するために提案されたデュアルリフティング手法にあります。さらに、グローバルな画像特徴と3D変形モデルを活用して、表情をコントロールするための3Dガウシアンを構築します。トレーニング後、我々のモデルは特定の最適化を行わずに見たことのないアイデンティティを再構築し、リアルタイムの速度で再現レンダリングを実行することができます。実験結果は、我々の手法が再構築の質や表情の正確さにおいて従来の方法と比較して優れた性能を示すことを明らかにしています。我々の手法は、今後の研究の新たなベンチマークを確立し、デジタルアバターの応用を前進させることができると信じています。
ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia 2024 (SIGGRAPH ASIA)
Style-NeRF2NeRF: 3D Style Transfer from Style-Aligned Multi-View Images
Haruo Fujiwara, Yusuke Mukuta, Tatsuya Harada
 本論文では、2D画像拡散モデルの事前知識を活用したシンプルかつ効果的な3Dシーンのスタイル転写パイプラインを提案しています。
まず元シーンの再構成に使用した多視点画像に対し、深度マップで条件付けされた画像生成パイプラインによる2Dスタイル転写を適用します。次に、得られたスタイル変換済み多視点画像を用いて元シーンのNeRFの追加学習を行います。
前段の多視点スタイル転写では、目標とする画風を表すテキストプロンプトを入力として受け取り、生成画像間で注意機構行列を共有することでスタイルの統一された画像変換を行うような深度条件付き拡散モデルを利用します。
後段では、前段で得られたスタイル転写済みの多視点画像を教師データとして、学習済画像認識モデル(VGG19)の特徴量分布がNeRFのレンダリング画像と一致するようにスライス・ワッサースタイン距離損失関数に基づいたNeRFの追加学習を行い、3Dスタイル転写を達成します。
このように本手法はスタイル転写プロセスが多視点画像の2Dスタイル転写とNeRF追加学習による3Dスタイル転写の二段階に分かれていることから、ユーザがNeRFの更新前に様々なプロンプトを試せることも利点のひとつになっています。
実験によって本手法が従来手法と比較しても多様かつ高品質な3Dスタイル転写を実現できることが示されています。
本論文では、2D画像拡散モデルの事前知識を活用したシンプルかつ効果的な3Dシーンのスタイル転写パイプラインを提案しています。
まず元シーンの再構成に使用した多視点画像に対し、深度マップで条件付けされた画像生成パイプラインによる2Dスタイル転写を適用します。次に、得られたスタイル変換済み多視点画像を用いて元シーンのNeRFの追加学習を行います。
前段の多視点スタイル転写では、目標とする画風を表すテキストプロンプトを入力として受け取り、生成画像間で注意機構行列を共有することでスタイルの統一された画像変換を行うような深度条件付き拡散モデルを利用します。
後段では、前段で得られたスタイル転写済みの多視点画像を教師データとして、学習済画像認識モデル(VGG19)の特徴量分布がNeRFのレンダリング画像と一致するようにスライス・ワッサースタイン距離損失関数に基づいたNeRFの追加学習を行い、3Dスタイル転写を達成します。
このように本手法はスタイル転写プロセスが多視点画像の2Dスタイル転写とNeRF追加学習による3Dスタイル転写の二段階に分かれていることから、ユーザがNeRFの更新前に様々なプロンプトを試せることも利点のひとつになっています。
実験によって本手法が従来手法と比較しても多様かつ高品質な3Dスタイル転写を実現できることが示されています。
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
Frequency-aware Feature Fusion for Dense Image Prediction
Linwei Chen, Ying Fu, Lin Gu, Chenggang Yan, Tatsuya Harada, and Gao Huang
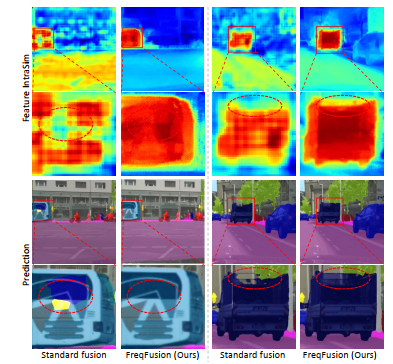 密な画像予測タスクでは、強力なカテゴリ情報と高解像度での正確な空間境界の詳細を持つ特徴が求められます。これを達成するために、現代の階層モデルでは、しばしば特徴融合が使用され、深い層からの粗い特徴をアップサンプルし、低いレベルからの高解像度の特徴と直接加算しています。本論文では、物体内で急激な変動が生じ、融合された特徴値が異なることで、カテゴリ内の不整合が発生することを観察しました。これは高周波数の特徴が乱されることによるものです。また、融合された特徴の境界がぼやけており、正確な高周波成分が不足しているため、境界の位置がずれることも確認しました。これらの観察結果をもとに、適応型ローパスフィルタ生成器、オフセット生成器、適応型ハイパスフィルタ生成器を統合したFrequency-Aware Feature Fusion(FreqFusion)を提案します。適応型ローパスフィルタ生成器は、物体内の高周波成分を減衰させ、アップサンプリング時のカテゴリ内の不整合を減少させるために空間的に変化するローパスフィルタを予測します。オフセット生成器は、大きな不整合のある特徴や細い境界を、再サンプリングを通じてより一貫性のある特徴に置き換えることで、特徴の一貫性を改善します。また、適応型ハイパスフィルタ生成器は、ダウンサンプリング中に失われた高周波の詳細な境界情報を強化します。包括的な視覚化と定量的な分析により、FreqFusionが特徴の一貫性を効果的に向上させ、物体の境界を鮮明にすることが示されました。さまざまな密な予測タスクにおいて実施した広範な実験により、その有効性が確認されました。コードはhttps://github.com/Linwei-Chen/で公開されています。
密な画像予測タスクでは、強力なカテゴリ情報と高解像度での正確な空間境界の詳細を持つ特徴が求められます。これを達成するために、現代の階層モデルでは、しばしば特徴融合が使用され、深い層からの粗い特徴をアップサンプルし、低いレベルからの高解像度の特徴と直接加算しています。本論文では、物体内で急激な変動が生じ、融合された特徴値が異なることで、カテゴリ内の不整合が発生することを観察しました。これは高周波数の特徴が乱されることによるものです。また、融合された特徴の境界がぼやけており、正確な高周波成分が不足しているため、境界の位置がずれることも確認しました。これらの観察結果をもとに、適応型ローパスフィルタ生成器、オフセット生成器、適応型ハイパスフィルタ生成器を統合したFrequency-Aware Feature Fusion(FreqFusion)を提案します。適応型ローパスフィルタ生成器は、物体内の高周波成分を減衰させ、アップサンプリング時のカテゴリ内の不整合を減少させるために空間的に変化するローパスフィルタを予測します。オフセット生成器は、大きな不整合のある特徴や細い境界を、再サンプリングを通じてより一貫性のある特徴に置き換えることで、特徴の一貫性を改善します。また、適応型ハイパスフィルタ生成器は、ダウンサンプリング中に失われた高周波の詳細な境界情報を強化します。包括的な視覚化と定量的な分析により、FreqFusionが特徴の一貫性を効果的に向上させ、物体の境界を鮮明にすることが示されました。さまざまな密な予測タスクにおいて実施した広範な実験により、その有効性が確認されました。コードはhttps://github.com/Linwei-Chen/で公開されています。
IEEE Transactions on Medical Imaging
A New Benchmark: Clinical Uncertainty and Severity Aware Labeled Chest X-Ray Images with Multi-Relationship Graph Learning
Mengliang Zhang, Xinyue Hu, Lin Gu, Liangchen Liu, Kazuma Kobayashi, Tatsuya Harada, Yan Yan, Ronald M. Summers, and Yingying Zhu
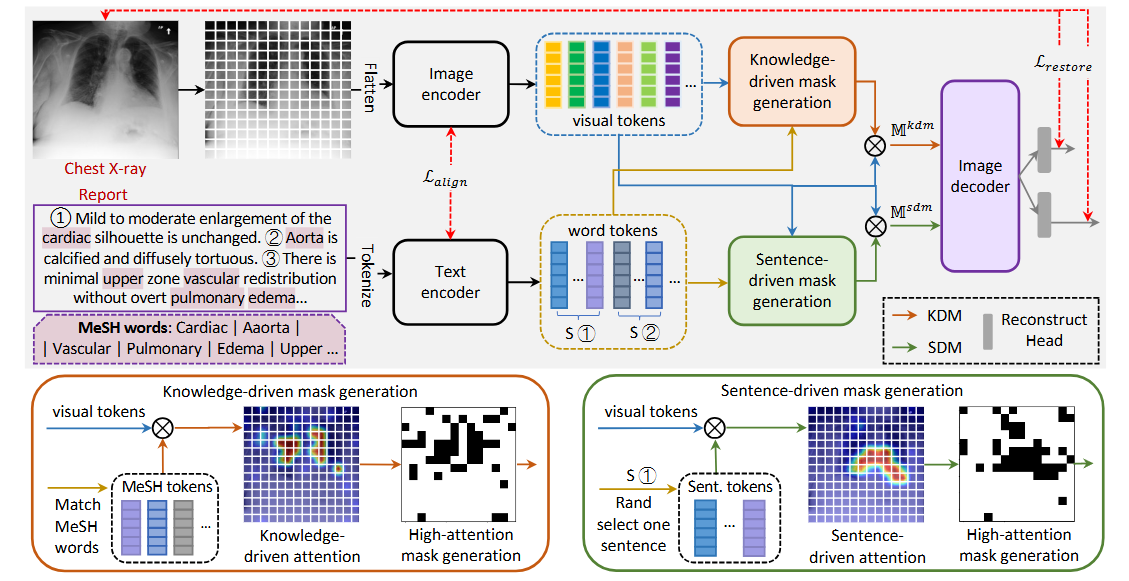 胸部X線撮影(CXR)は、心肺疾患を検出するために臨床現場で頻繁に利用されています。しかし、経験豊富な放射線科医であっても、観察された異常に関する深刻度や不確実性に対して異なる評価を下すことがあります。これまでの研究では、臨床ノートを用いてCXR画像診断のための深層学習モデルをトレーニングするために異常ラベルを抽出する試みがなされてきましたが、これらの方法では異なるラベルに関連する深刻度や不確実性の差異を無視する傾向がありました。本研究では、放射線科医の不確実性や深刻度の評価を取り入れた臨床テキストデータに基づく新しいCXR画像データセットを構築しました。このデータセットを用いて、空間的および意味的な関係を活用し、専門家の不確実性を専用の損失関数で対処するマルチリレーションシップグラフ学習フレームワークを提案しました。我々の研究は、CXR画像診断における性能および診断モデルの解釈可能性の大幅な向上を示しており、既存の最先端手法を凌駕しています。抽出した疾患の深刻度と不確実性に関するデータセットのアドレスは、Link です。
胸部X線撮影(CXR)は、心肺疾患を検出するために臨床現場で頻繁に利用されています。しかし、経験豊富な放射線科医であっても、観察された異常に関する深刻度や不確実性に対して異なる評価を下すことがあります。これまでの研究では、臨床ノートを用いてCXR画像診断のための深層学習モデルをトレーニングするために異常ラベルを抽出する試みがなされてきましたが、これらの方法では異なるラベルに関連する深刻度や不確実性の差異を無視する傾向がありました。本研究では、放射線科医の不確実性や深刻度の評価を取り入れた臨床テキストデータに基づく新しいCXR画像データセットを構築しました。このデータセットを用いて、空間的および意味的な関係を活用し、専門家の不確実性を専用の損失関数で対処するマルチリレーションシップグラフ学習フレームワークを提案しました。我々の研究は、CXR画像診断における性能および診断モデルの解釈可能性の大幅な向上を示しており、既存の最先端手法を凌駕しています。抽出した疾患の深刻度と不確実性に関するデータセットのアドレスは、Link です。
Medical Image Analysis
Rethinking masked image modeling for medical image representation
Yutong Xie, Lin Gu, Tatsuya Harada, Jianpeng Zhang, Yong Xia, Qi Wu
 Masked Image Modeling (MIM)は、自己教師あり学習の一形態で、アノテーションが付いていないデータを使って画像表現を改善することでコンピュータビジョン分野で大きな成功を収めています。従来のMIMでは、画像全体からランダムにサンプリングする手法が一般的に用いられています。しかし、このランダムなマスキング手法は、自然画像とは異なる特性を持つ医療画像には必ずしも適していない可能性があります。特に病理学における医療画像では、病変に関連する特徴は非常に稀で局所的であり、その他の領域は正常で識別が困難です。また、医療画像には病変の位置を直接示すレポートが付随することが多いです。これに着目し、我々はMasked medical Image Modeling(MedIM)という新しいアプローチを提案します。これは、放射線レポートを用いてマスキングをガイドし、画像の情報量の多い領域を復元することで、ネットワークが医療画像からより強力なセマンティック表現を探索するよう促す初の研究です。
また、このアプローチは大規模言語モデル(LLM)とも関連しています。近年、医療分野に特化したLLMは、放射線レポートやその他のテキストデータから臨床情報を抽出し、診断支援を行うために活用されています。しかし、これらのLLMが正確で意味のある予測を行うためには、高品質でセマンティックな画像表現が必要です。MedIMは、レポートと画像を融合させ、LLMが処理できるより豊かな情報を提供することを目指しています。このようにして、LLMが医療画像の解釈や診断の質を向上させることに貢献できます。
我々は、知識駆動型マスキング(KDM)と文章駆動型マスキング(SDM)の2つの相互に補完的なマスキング戦略を導入します。KDMは、放射線レポートに特有のMedical Subject Headings (MeSH) 用語を使用して、症状の手がかりをMeSH用語(例: 心臓、浮腫、血管、肺)にマッピングし、マスク生成をガイドします。放射線レポートがさまざまな所見を詳述した複数の文で構成されることを考慮し、SDMは文レベルの情報を統合して、マスキング対象となる重要な領域を特定します。MedIMは、KDMとSDMモジュールからのマスキングに基づいて画像を再構築し、包括的で豊かな医療画像表現を促進します。
我々の大規模な実験では、マルチラベル・クラス画像分類、気胸セグメンテーション、医療画像レポート解析を含む7つの下流タスクにおいて、レポートガイドによるマスキングを行ったMedIMが競争力のある性能を達成することを示しました。我々の手法は、ImageNetでの事前学習、MIMベースの事前学習、および医療画像レポートでの事前学習手法を大幅に上回る結果を示しました。
Masked Image Modeling (MIM)は、自己教師あり学習の一形態で、アノテーションが付いていないデータを使って画像表現を改善することでコンピュータビジョン分野で大きな成功を収めています。従来のMIMでは、画像全体からランダムにサンプリングする手法が一般的に用いられています。しかし、このランダムなマスキング手法は、自然画像とは異なる特性を持つ医療画像には必ずしも適していない可能性があります。特に病理学における医療画像では、病変に関連する特徴は非常に稀で局所的であり、その他の領域は正常で識別が困難です。また、医療画像には病変の位置を直接示すレポートが付随することが多いです。これに着目し、我々はMasked medical Image Modeling(MedIM)という新しいアプローチを提案します。これは、放射線レポートを用いてマスキングをガイドし、画像の情報量の多い領域を復元することで、ネットワークが医療画像からより強力なセマンティック表現を探索するよう促す初の研究です。
また、このアプローチは大規模言語モデル(LLM)とも関連しています。近年、医療分野に特化したLLMは、放射線レポートやその他のテキストデータから臨床情報を抽出し、診断支援を行うために活用されています。しかし、これらのLLMが正確で意味のある予測を行うためには、高品質でセマンティックな画像表現が必要です。MedIMは、レポートと画像を融合させ、LLMが処理できるより豊かな情報を提供することを目指しています。このようにして、LLMが医療画像の解釈や診断の質を向上させることに貢献できます。
我々は、知識駆動型マスキング(KDM)と文章駆動型マスキング(SDM)の2つの相互に補完的なマスキング戦略を導入します。KDMは、放射線レポートに特有のMedical Subject Headings (MeSH) 用語を使用して、症状の手がかりをMeSH用語(例: 心臓、浮腫、血管、肺)にマッピングし、マスク生成をガイドします。放射線レポートがさまざまな所見を詳述した複数の文で構成されることを考慮し、SDMは文レベルの情報を統合して、マスキング対象となる重要な領域を特定します。MedIMは、KDMとSDMモジュールからのマスキングに基づいて画像を再構築し、包括的で豊かな医療画像表現を促進します。
我々の大規模な実験では、マルチラベル・クラス画像分類、気胸セグメンテーション、医療画像レポート解析を含む7つの下流タスクにおいて、レポートガイドによるマスキングを行ったMedIMが競争力のある性能を達成することを示しました。我々の手法は、ImageNetでの事前学習、MIMベースの事前学習、および医療画像レポートでの事前学習手法を大幅に上回る結果を示しました。
The 35th British Machine Vision Conference, BMVC 2024
Discovering an Image-Adaptive Coordinate System for Photography Processing
Ziteng Cui, Lin Gu, Tatsuya Harada
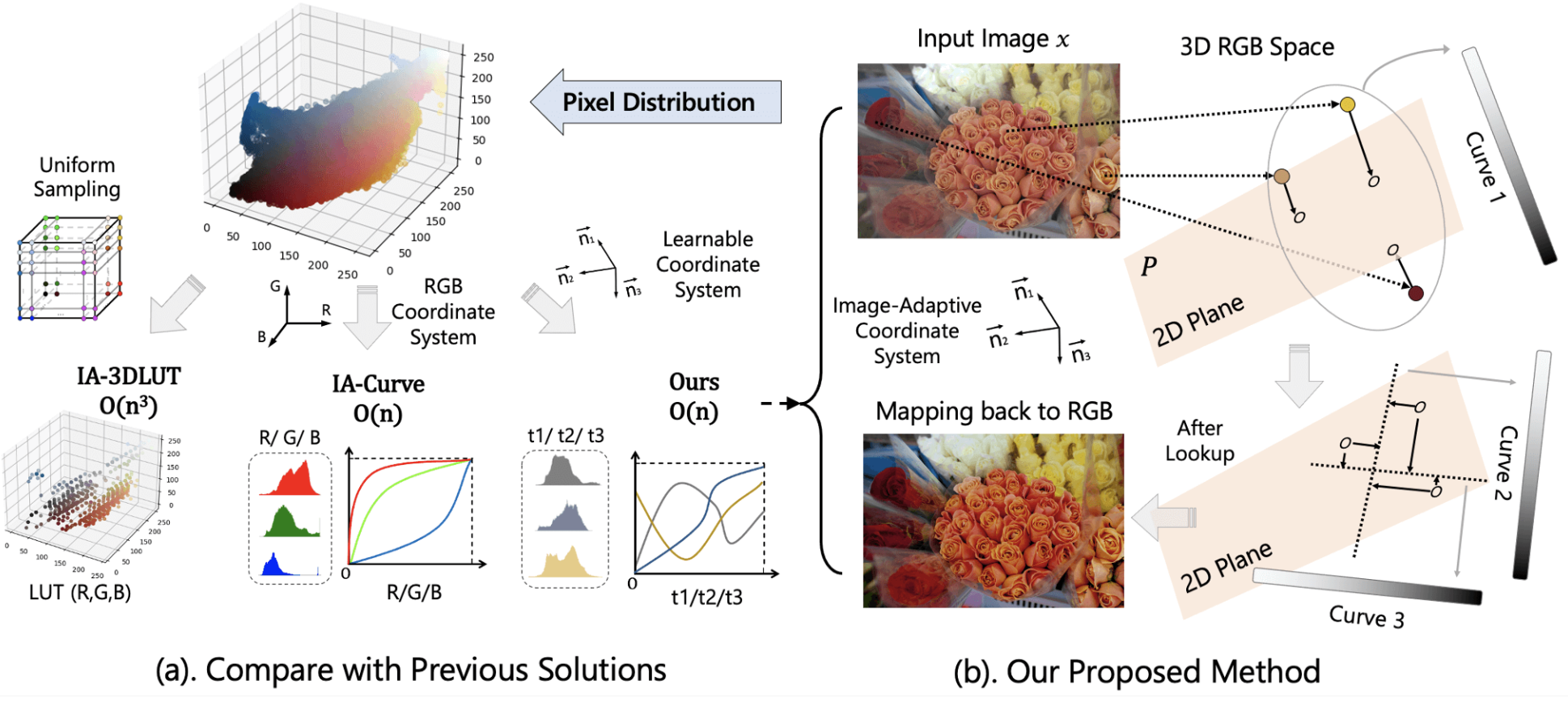 曲線およびルックアップテーブル(LUT)ベースの方法は、ピクセルをターゲット出力に直接マッピングするため、リアルタイムの写真処理に非常に効率的です。しかし、完全なRGB空間マッピングを学習するための極めて複雑なメモリ要件のため、既存の方法は、3次元格子をサンプリングして3次元LUTを構築するか、RGBチャンネルで3つの別々の曲線(1次元LUT)に分解します。ここでは、新しいアルゴリズムIACを提案します。これは、曲線操作を実行する前にRGB色空間内で画像適応型の笛卡尔座標系を学習します。このエンドツーエンドで訓練可能なアプローチにより、同時に学習された画像適応型座標系と曲線を使用して画像を効率的に調整することができます。実験結果は、このシンプルな戦略が、写真リタッチ、露出訂正、ホワイトバランス編集を含む様々な写真処理タスクで、最新の(SOTA)性能を達成していることを示しています。同時に軽量な設計と高速な推論速度を維持しています。
曲線およびルックアップテーブル(LUT)ベースの方法は、ピクセルをターゲット出力に直接マッピングするため、リアルタイムの写真処理に非常に効率的です。しかし、完全なRGB空間マッピングを学習するための極めて複雑なメモリ要件のため、既存の方法は、3次元格子をサンプリングして3次元LUTを構築するか、RGBチャンネルで3つの別々の曲線(1次元LUT)に分解します。ここでは、新しいアルゴリズムIACを提案します。これは、曲線操作を実行する前にRGB色空間内で画像適応型の笛卡尔座標系を学習します。このエンドツーエンドで訓練可能なアプローチにより、同時に学習された画像適応型座標系と曲線を使用して画像を効率的に調整することができます。実験結果は、このシンプルな戦略が、写真リタッチ、露出訂正、ホワイトバランス編集を含む様々な写真処理タスクで、最新の(SOTA)性能を達成していることを示しています。同時に軽量な設計と高速な推論速度を維持しています。
Medical Image Analysis
OInterpretable Medical Image Visual Question Answering via Multi-Modal Relationship Graph Learning
Xinyue Hu, Lin Gu, Kazuma Kobayashi, Qiyuan An, Qingyu Chen, Zhiyong Lu, Chang Su, Tatsuya Harada, Yingying Zhu
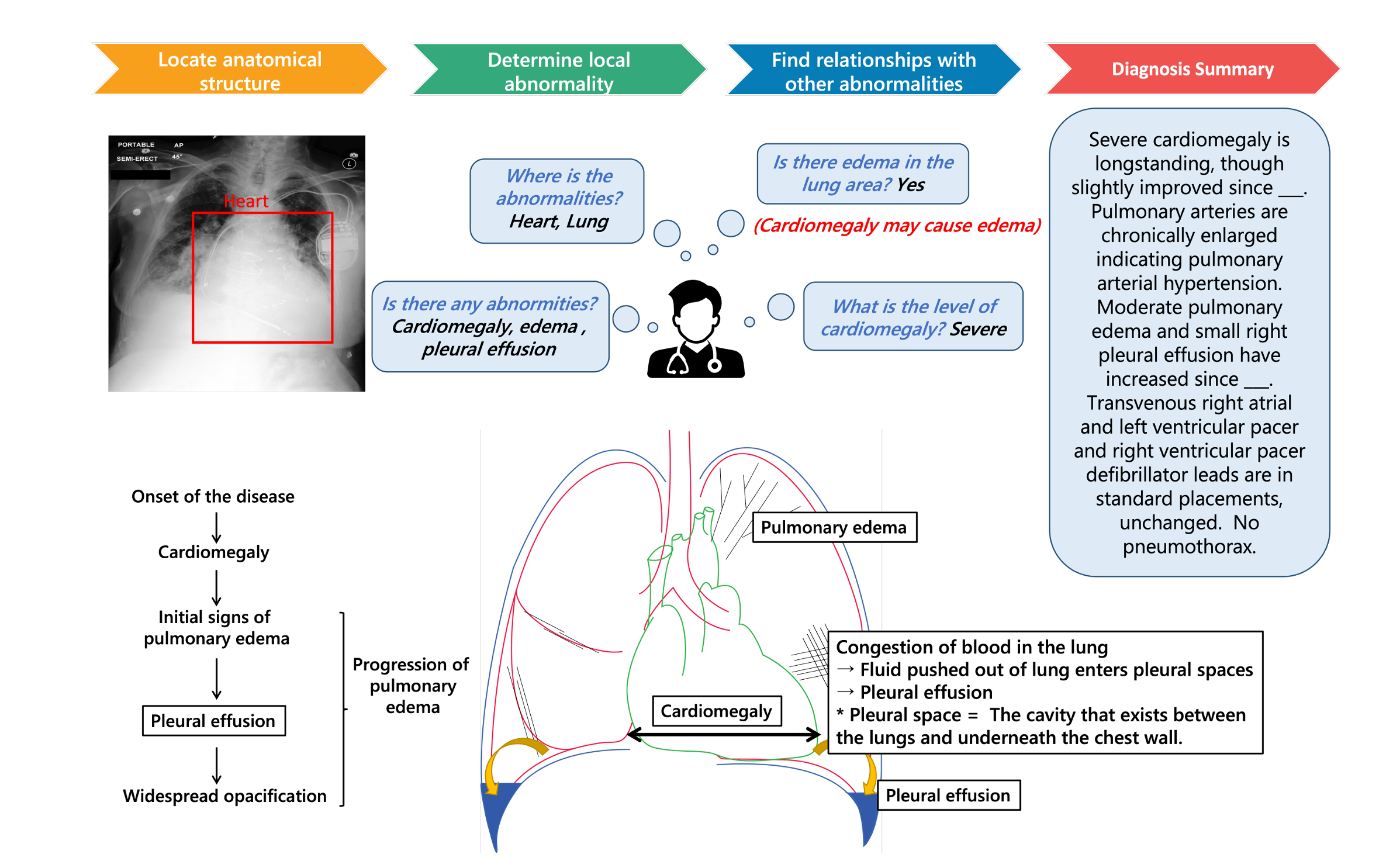 医療用視覚質問応答(VQA)は、入力された医療画像に関して臨床的に関連する質問に答えることを目的としています。この技術は、医療専門家の効率を向上させるだけでなく、特に資源の乏しい国々における公衆衛生システムの負担を軽減する可能性を秘めています。現在の医療VQA方法は、医療画像をエンコードし、視覚的特徴と質問との対応関係を学習する傾向にありますが、画像の空間的、意味的、医療的な知識を活用することは少ないです。これは主に、現在の医療VQAデータセットのサイズが小さく、簡単な質問しか含まれていないことに起因しています。そのため、まず胸部X線画像に焦点を当てた包括的で大規模な医療VQAデータセットを収集しました。我々のデータセットには、病気の名前、位置、レベル、タイプなどの詳細な関係が含まれています。このデータセットに基づいて、画像領域、質問、および意味ラベルに対して、空間的関係、意味的関係、暗黙的関係の3つの異なる関係グラフを構築することで、新しいベースライン手法を提案します。異なる質問に対する答えとグラフ推論経路が学習されます。
医療用視覚質問応答(VQA)は、入力された医療画像に関して臨床的に関連する質問に答えることを目的としています。この技術は、医療専門家の効率を向上させるだけでなく、特に資源の乏しい国々における公衆衛生システムの負担を軽減する可能性を秘めています。現在の医療VQA方法は、医療画像をエンコードし、視覚的特徴と質問との対応関係を学習する傾向にありますが、画像の空間的、意味的、医療的な知識を活用することは少ないです。これは主に、現在の医療VQAデータセットのサイズが小さく、簡単な質問しか含まれていないことに起因しています。そのため、まず胸部X線画像に焦点を当てた包括的で大規模な医療VQAデータセットを収集しました。我々のデータセットには、病気の名前、位置、レベル、タイプなどの詳細な関係が含まれています。このデータセットに基づいて、画像領域、質問、および意味ラベルに対して、空間的関係、意味的関係、暗黙的関係の3つの異なる関係グラフを構築することで、新しいベースライン手法を提案します。異なる質問に対する答えとグラフ推論経路が学習されます。
The European Conference on Computer Vision, ECCV 2024
Open-set Domain Adaptation via Joint Error based Multi-class Positive and Unlabeled Learning
Dexuan Zhang, Thomas Westfechtel, Tatsuya Harada
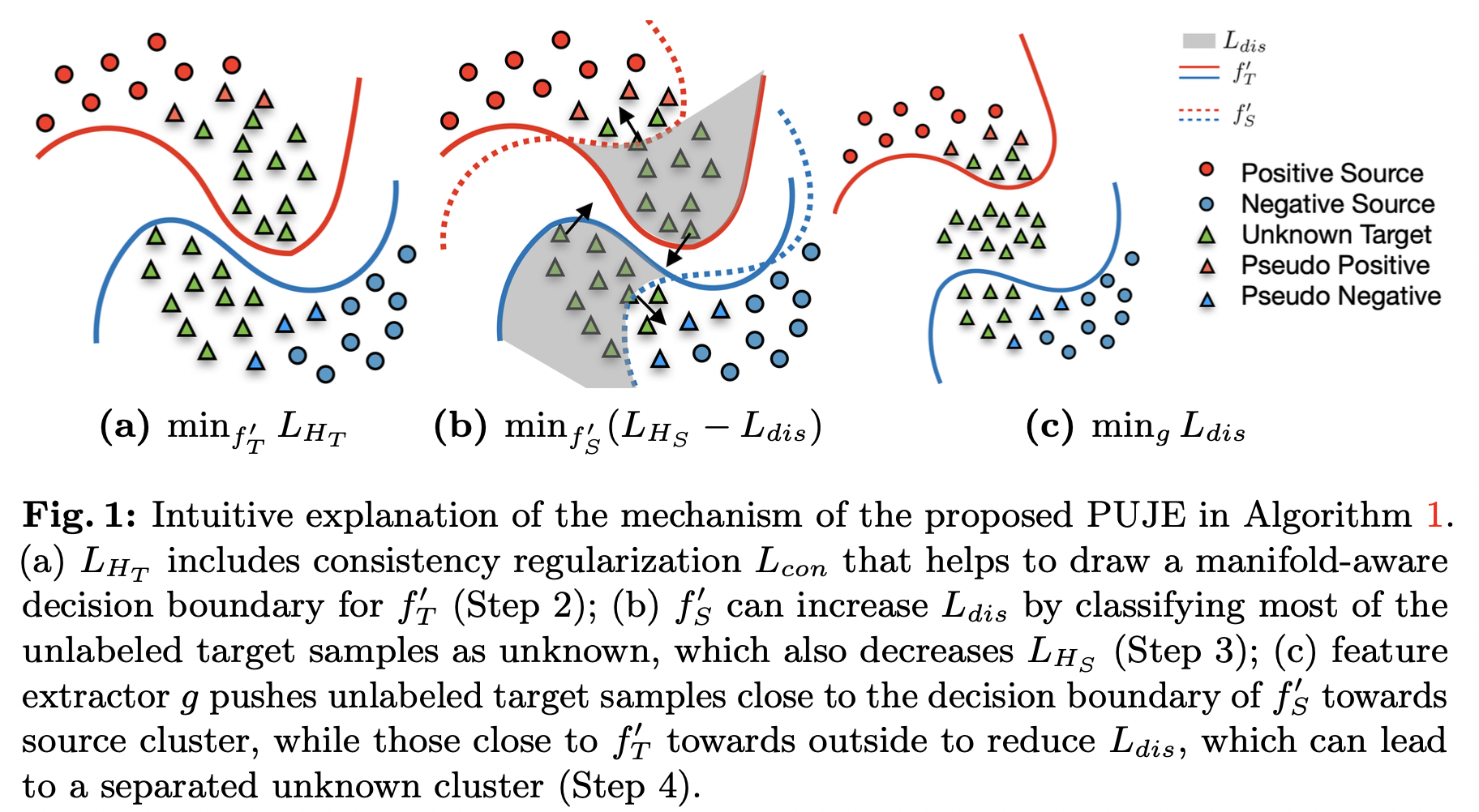 オープンセットドメイン適応は、より現実的な問題として、ターゲットデータにソースデータには存在しない未知のクラスが含まれる場合のドメインシフトに対する学習アルゴリズムの汎化パフォーマンスを向上させることを目的としています。ほとんどの既存のアルゴリズムでは、ヒューリスティックな未知のクラス分離を考慮したクローズドセットドメイン適応を採用しています。したがって、真の分布とヒューリスティックから推測されるサンプルとの間にギャップがあるため、汎化誤差を厳密に制限することはできません。この論文では、PUラーニングの学習理論とドメイン適応によるジョイントエラーによってターゲットタスク全体のリスクを厳密に制限するアルゴリズムを提案します。さまざまなデータセットに対する広範な実験により、オープンセットのドメイン適応ベースラインに対して、提案手法の有効性が実証されました。
オープンセットドメイン適応は、より現実的な問題として、ターゲットデータにソースデータには存在しない未知のクラスが含まれる場合のドメインシフトに対する学習アルゴリズムの汎化パフォーマンスを向上させることを目的としています。ほとんどの既存のアルゴリズムでは、ヒューリスティックな未知のクラス分離を考慮したクローズドセットドメイン適応を採用しています。したがって、真の分布とヒューリスティックから推測されるサンプルとの間にギャップがあるため、汎化誤差を厳密に制限することはできません。この論文では、PUラーニングの学習理論とドメイン適応によるジョイントエラーによってターゲットタスク全体のリスクを厳密に制限するアルゴリズムを提案します。さまざまなデータセットに対する広範な実験により、オープンセットのドメイン適応ベースラインに対して、提案手法の有効性が実証されました。
RAW-Adapter: Adapting Pre-trained Visual Model to Camera RAW Images
Ziteng Cui, Tatsuya Harada
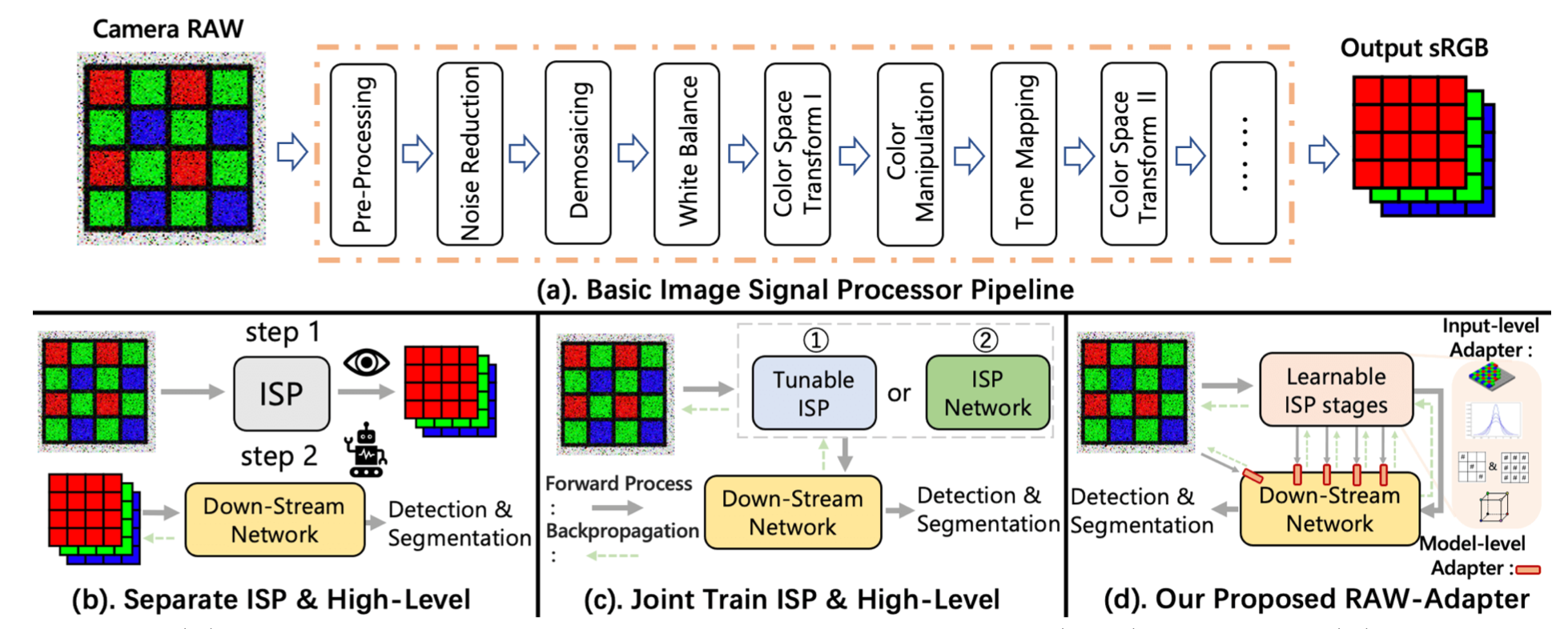 sRGB画像は、取得の容易さと効率的な保存のため、現在コンピュータビジョン研究における視覚モデルの事前学習において主流の選択となっています。一方、RAW画像の利点は、実世界の可変な照明条件下での豊富な物理情報にあります。カメラのRAWデータに直接基づくコンピュータビジョンタスクにおいて、ほとんどの既存の研究は画像信号プロセッサ(ISP)とバックエンドネットワークの統合手法を採用していますが、ISPステージとその後のネットワーク間の相互作用能力をしばしば見落としています。
NLPおよびCV分野で進行中のアダプター研究に着想を得て、sRGB事前学習モデルをカメラRAWデータに適応させることを目的とした新しいアプローチ「RAW-Adapter」を紹介します。RAW-Adapterは、学習可能なISPステージを用いてRAW入力を調整する入力レベルのアダプターと、ISPステージとその後の高レベルネットワーク間の接続を構築するモデルレベルのアダプターで構成されています。
さらに、RAW-Adapterはさまざまなコンピュータビジョンフレームワークで使用できる汎用的なフレームワークです。異なる照明条件下での豊富な実験により、我々のアルゴリズムが最先端(SOTA)の性能を発揮し、さまざまな実世界および合成データセットにおいてその有効性と効率性を示しました。Code
sRGB画像は、取得の容易さと効率的な保存のため、現在コンピュータビジョン研究における視覚モデルの事前学習において主流の選択となっています。一方、RAW画像の利点は、実世界の可変な照明条件下での豊富な物理情報にあります。カメラのRAWデータに直接基づくコンピュータビジョンタスクにおいて、ほとんどの既存の研究は画像信号プロセッサ(ISP)とバックエンドネットワークの統合手法を採用していますが、ISPステージとその後のネットワーク間の相互作用能力をしばしば見落としています。
NLPおよびCV分野で進行中のアダプター研究に着想を得て、sRGB事前学習モデルをカメラRAWデータに適応させることを目的とした新しいアプローチ「RAW-Adapter」を紹介します。RAW-Adapterは、学習可能なISPステージを用いてRAW入力を調整する入力レベルのアダプターと、ISPステージとその後の高レベルネットワーク間の接続を構築するモデルレベルのアダプターで構成されています。
さらに、RAW-Adapterはさまざまなコンピュータビジョンフレームワークで使用できる汎用的なフレームワークです。異なる照明条件下での豊富な実験により、我々のアルゴリズムが最先端(SOTA)の性能を発揮し、さまざまな実世界および合成データセットにおいてその有効性と効率性を示しました。Code
Artificial Intelligence In Medicine
Can Physician Judgment Enhance Model Trustworthiness? A Case Study on Predicting Pathological Lymph Nodes in Rectal Cancer
Kazuma Kobayashi, Yasuyuki Takamizawa, Mototaka Miyake, Sono Ito, Lin Gu, Tatsuya Nakatsuka, Yu Akagi, Tatsuya Harada, Yukihide Kanemitsu, Ryuji Hamamoto
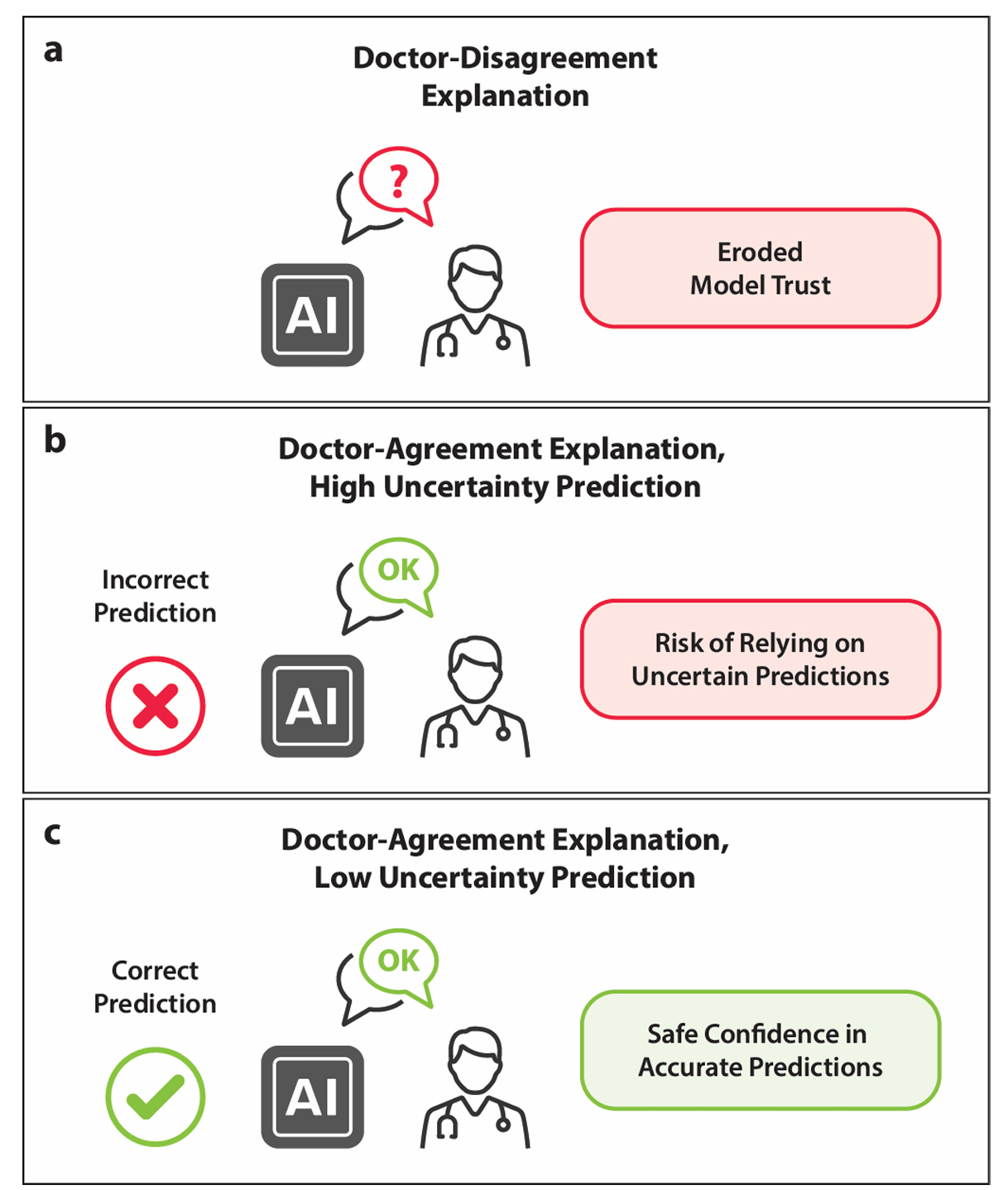 説明可能性は、医学における人工知能の信頼性を向上させる鍵です。しかし、説明可能なモデルが臨床決定に実際にどれほど役立つかについては、いくつかの問題が残っています。まず、効果的な説明可能性が医療従事者に提供すべき実際的な利益を定量的に評価するための評価フレームワークに関する合意が欠けています。次に、医師中心の説明可能性の評価は限られています。さらに、トランスフォーマーベースのモデルに組み込まれた注意メカニズムが説明手法として有用であるかどうかは不明です。私たちは、優れた注意マップが医師が注目する情報と一致し、予測の不確実性を減少させ、モデルの信頼性を向上させる可能性があると仮定しました。私たちは臨床データと磁気共鳴画像を用いて直腸癌のリンパ節転移を予測するためにマルチモーダルトランスフォーマーを使用し、最先端の技術を通じて視覚化された注意マップが医師の理解とどれほど一致するかを調査しました。予測確率の分散などのメタレベルの情報を用いてモデルの不確実性を推定し、一致度を定量化しました。この一致度が不確実性を減少させるかどうかを評価した結果、顕著な効果は見られませんでした。結論として、このケーススタディは、注意マップがモデルの信頼性を向上させるという予想される利益を確認することはできませんでした。表面的な説明は、医師が不確かな予測に依存するよう誤解を招く可能性があるため、逆効果となる可能性があります。したがって、説明メカニズムの現在の状態を過大評価すべきではありません。臨床決定に真に有益な説明可能性メカニズムを特定することが重要です。
説明可能性は、医学における人工知能の信頼性を向上させる鍵です。しかし、説明可能なモデルが臨床決定に実際にどれほど役立つかについては、いくつかの問題が残っています。まず、効果的な説明可能性が医療従事者に提供すべき実際的な利益を定量的に評価するための評価フレームワークに関する合意が欠けています。次に、医師中心の説明可能性の評価は限られています。さらに、トランスフォーマーベースのモデルに組み込まれた注意メカニズムが説明手法として有用であるかどうかは不明です。私たちは、優れた注意マップが医師が注目する情報と一致し、予測の不確実性を減少させ、モデルの信頼性を向上させる可能性があると仮定しました。私たちは臨床データと磁気共鳴画像を用いて直腸癌のリンパ節転移を予測するためにマルチモーダルトランスフォーマーを使用し、最先端の技術を通じて視覚化された注意マップが医師の理解とどれほど一致するかを調査しました。予測確率の分散などのメタレベルの情報を用いてモデルの不確実性を推定し、一致度を定量化しました。この一致度が不確実性を減少させるかどうかを評価した結果、顕著な効果は見られませんでした。結論として、このケーススタディは、注意マップがモデルの信頼性を向上させるという予想される利益を確認することはできませんでした。表面的な説明は、医師が不確かな予測に依存するよう誤解を招く可能性があるため、逆効果となる可能性があります。したがって、説明メカニズムの現在の状態を過大評価すべきではありません。臨床決定に真に有益な説明可能性メカニズムを特定することが重要です。
AI for Content Creation Workshop @ CVPR 2024
The Lost Melody: Empirical Observations on Text-to-Video Generation From A Storytelling Perspective
Andrew Shin, Yusuke Mori, Kunitake Kaneko
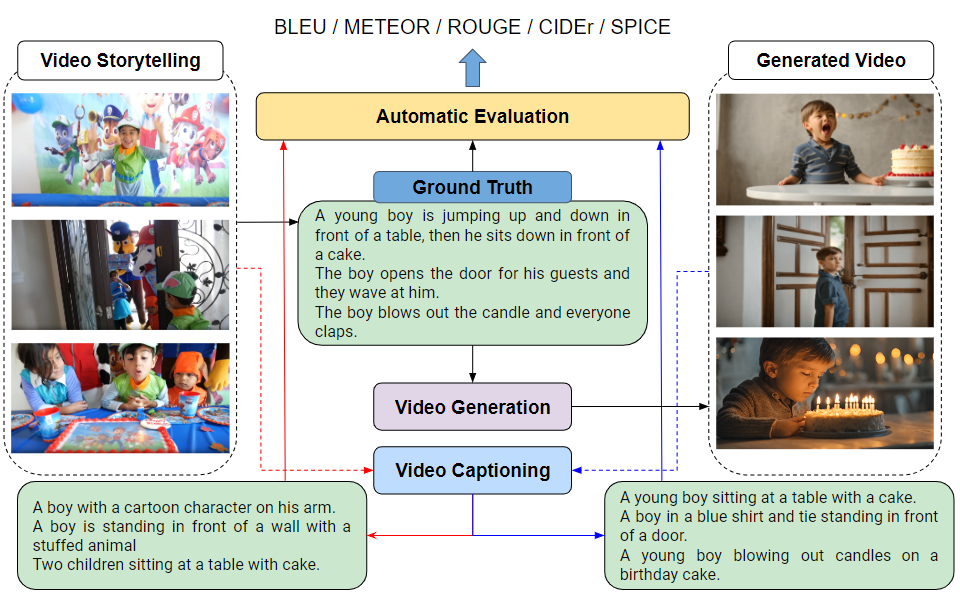 Text-to-video generation task has witnessed a notable progress, with the generated outcomes reflecting the text prompts with high fidelity and impressive visual qualities. However, current text-to-video generation models are invariably focused on conveying the visual elements of a single scene, and have so far been indifferent to another important potential of the medium, namely a storytelling. In this paper, we examine text-to-video generation from a storytelling perspective, which has been hardly investigated, and make empirical remarks that spotlight the limitations of current text-to-video generation scheme. We also propose an evaluation framework for storytelling aspects of videos, and discuss the potential future directions.
Text-to-video generation task has witnessed a notable progress, with the generated outcomes reflecting the text prompts with high fidelity and impressive visual qualities. However, current text-to-video generation models are invariably focused on conveying the visual elements of a single scene, and have so far been indifferent to another important potential of the medium, namely a storytelling. In this paper, we examine text-to-video generation from a storytelling perspective, which has been hardly investigated, and make empirical remarks that spotlight the limitations of current text-to-video generation scheme. We also propose an evaluation framework for storytelling aspects of videos, and discuss the potential future directions.
In Proceedings of the Reinforcement Learning Conference (RLC), 2024
Stabilizing Extreme Q-learning by Maclaurin Expansion
Motoki Omura, Takayuki Osa, Yusuke Mukuta, Tatsuya Harada
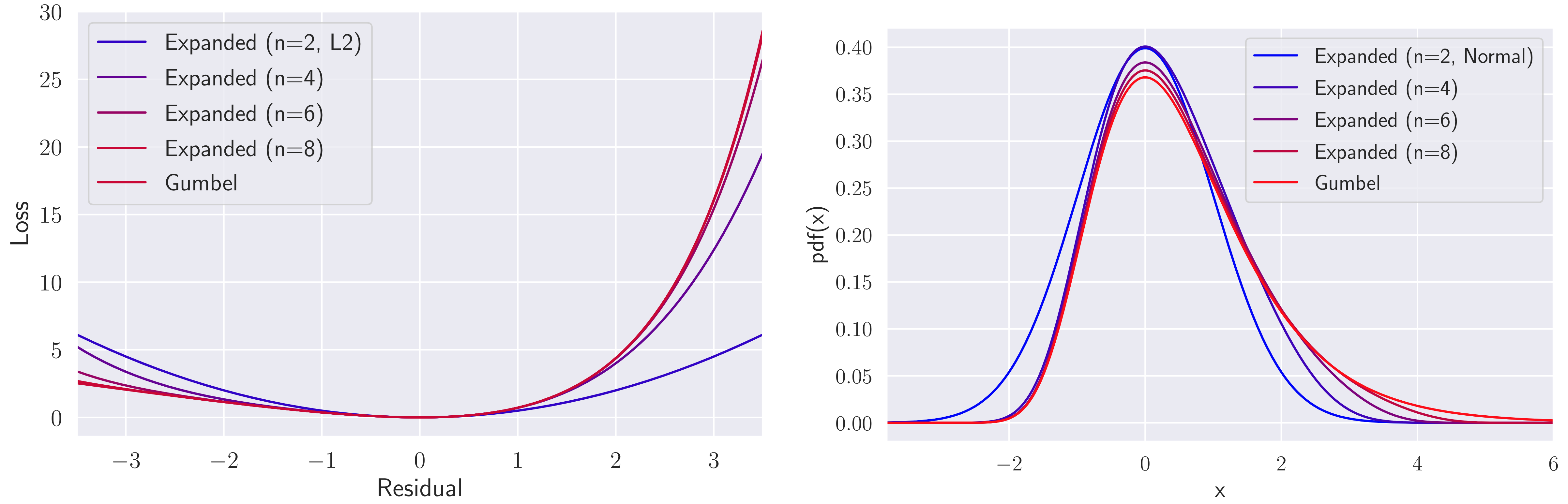 Extreme Q-learning (XQL) では、誤差分布として仮定されるガンベル分布を用いてガンベル回帰を行います。これにより、out-of-distributionな行動をサンプリングせずに価値関数を学習することができ、主にオフラインRLで優れた性能を示しています。しかし、損失関数の指数項が不安定性を引き起こすことや、誤差分布がガンベル分布から逸脱する可能性などの問題が残っていました。そこで、我々は安定性を向上させるためにMaclaurin Expanded Extreme Q-learningを提案します。この方法では、XQLの損失関数にマクローリン展開を適用することで、大きな誤差に対する安定性を高めます。また、展開次数に基づいて誤差分布の仮定を正規分布からガンベル分布に調整することが可能です。我々の方法は、XQLが以前不安定だったDM ControlのオンラインRLタスクでの学習を大幅に安定化させます。さらに、XQLが既に優れた結果を示していたD4RLのいくつかのオフラインRLタスクにおいても性能を向上させました。
Extreme Q-learning (XQL) では、誤差分布として仮定されるガンベル分布を用いてガンベル回帰を行います。これにより、out-of-distributionな行動をサンプリングせずに価値関数を学習することができ、主にオフラインRLで優れた性能を示しています。しかし、損失関数の指数項が不安定性を引き起こすことや、誤差分布がガンベル分布から逸脱する可能性などの問題が残っていました。そこで、我々は安定性を向上させるためにMaclaurin Expanded Extreme Q-learningを提案します。この方法では、XQLの損失関数にマクローリン展開を適用することで、大きな誤差に対する安定性を高めます。また、展開次数に基づいて誤差分布の仮定を正規分布からガンベル分布に調整することが可能です。我々の方法は、XQLが以前不安定だったDM ControlのオンラインRLタスクでの学習を大幅に安定化させます。さらに、XQLが既に優れた結果を示していたD4RLのいくつかのオフラインRLタスクにおいても性能を向上させました。
第27回 画像の認識・理解シンポジウム (MIRU2024), 口頭発表論文, 査読付き
スパイキングニューラルネットワークによる画像生成拡散モデル
Ryo Watanabe, Yusuke Mukuta, Tatsuya Harada
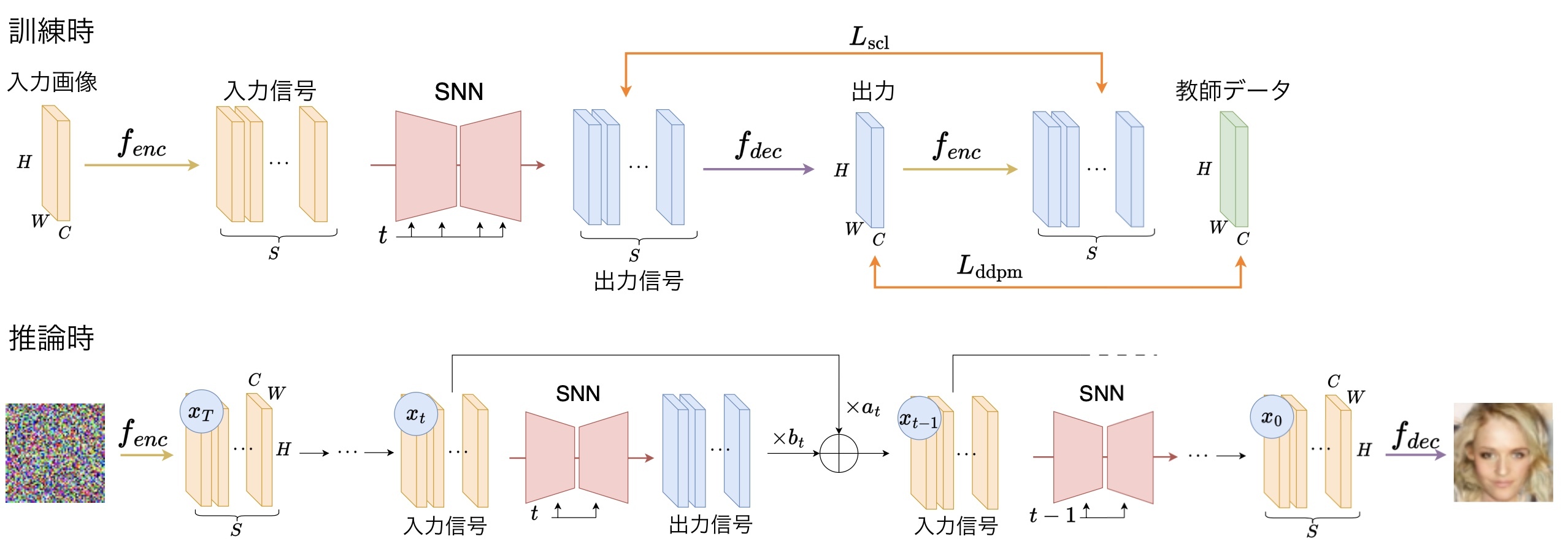 スパイキングニューラルネットワーク(SNN)はその計算効率の高さから近年注目を集めている.拡散モデルは拡散過程の逆過程を学習する生成モデルであり,高性能な画像生成が可能だが計算コストが高い.そこで本研究では,提案するシナプス電流学習(SCL)によりSNNのみで完結する拡散モデルを実現した.実験では提案手法が既存の画像生成手法より優れていることを示し,ANNに比べ消費電力が小さいことを確認した.
スパイキングニューラルネットワーク(SNN)はその計算効率の高さから近年注目を集めている.拡散モデルは拡散過程の逆過程を学習する生成モデルであり,高性能な画像生成が可能だが計算コストが高い.そこで本研究では,提案するシナプス電流学習(SCL)によりSNNのみで完結する拡散モデルを実現した.実験では提案手法が既存の画像生成手法より優れていることを示し,ANNに比べ消費電力が小さいことを確認した.
2nd Workshop on MAD-Games: Multi-Agent Dynamic Games, ICRA 2024
RallySim : Simulated Environment with Continuous Control for Turn-based Multi-agent Reinforcement Learning
Shun Yoshikawa, Yusuke Mukuta, Takayuki Osa, Tatsuya Harada
 マルチエージェント強化学習は、プレイヤー間で協力的、競争的な相互作用があるようなタスクにおいてエージェント訓練する有望な手法と考えられてきた。複数のゲームがすでにマルチエージェントの問題して使われ、既存の強化学習手法をマルチエージェントの枠組みで使うことで満足のいく挙動をするエージェントを訓練できることが研究で示されている。しかし、既存のマルチエージェントのタスクは、行動空間が高々ゲームのコントローラの入力程度で、小さく、離散的であるという点で、難易度が控えめになっている。複雑な連続的制御を伴うマルチエージェントのタスクがより多く必要だ。本論文では、ラリースポーツから着想を得たタスクをエージェントが行う、RallySimという独自のマルチエージェント環境を点庵する。このタスクでは、コート上に配置された2体のロボットのプレイヤーが手先効果器でボールを打つことの応酬を実現することが求められる。これには、運動技術と戦略の両方を伴い、これは既存のタスクにはない要素である。我々はRallySimのタスクにおいてエージェントを訓練するために、階層型強化学習を使用し、評価結果において、これが、従来手法で訓練さたエージェントの性能を上回ることが示された。Link
マルチエージェント強化学習は、プレイヤー間で協力的、競争的な相互作用があるようなタスクにおいてエージェント訓練する有望な手法と考えられてきた。複数のゲームがすでにマルチエージェントの問題して使われ、既存の強化学習手法をマルチエージェントの枠組みで使うことで満足のいく挙動をするエージェントを訓練できることが研究で示されている。しかし、既存のマルチエージェントのタスクは、行動空間が高々ゲームのコントローラの入力程度で、小さく、離散的であるという点で、難易度が控えめになっている。複雑な連続的制御を伴うマルチエージェントのタスクがより多く必要だ。本論文では、ラリースポーツから着想を得たタスクをエージェントが行う、RallySimという独自のマルチエージェント環境を点庵する。このタスクでは、コート上に配置された2体のロボットのプレイヤーが手先効果器でボールを打つことの応酬を実現することが求められる。これには、運動技術と戦略の両方を伴い、これは既存のタスクにはない要素である。我々はRallySimのタスクにおいてエージェントを訓練するために、階層型強化学習を使用し、評価結果において、これが、従来手法で訓練さたエージェントの性能を上回ることが示された。Link
Index Terms—Multi-Agent Systems, Deep Reinforcement Learning
Proceeding of the International Conference on Machine Learning (ICML), 2024
Discovering Multiple Solutions from a Single Task in Offline Reinforcement Learning
Takayuki Osa and Tatsuya Harada
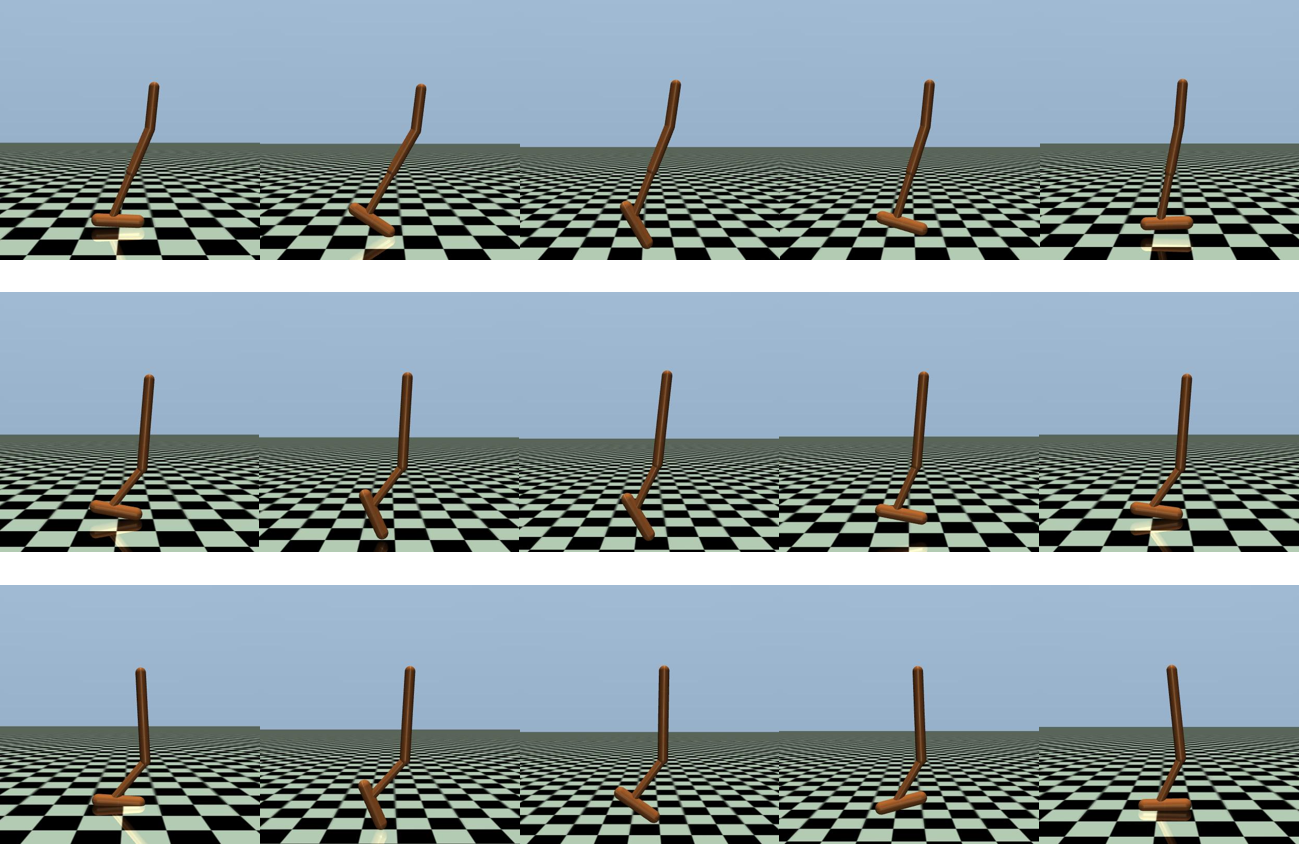 最近のオンライン強化学習に関する研究では、一つのタスクから複数の行動を学習することで、新しい環境へのfew-shot適応などが可能になることが示されています。オフライン強化学習においても同様の利点が期待されるものの、複数の解を学習するための適切な方法はこれまでの研究では十分に検討されていませんでした。
そこで本研究では、オフライン強化学習において複数の解を学習できるアルゴリズムを提案し、そのパフォーマンスを実証的に調査しました。実験の結果、提案されたアルゴリズムは、オフライン強化学習において定性的かつ定量的に異なる複数の解を学習できることが示されました。
最近のオンライン強化学習に関する研究では、一つのタスクから複数の行動を学習することで、新しい環境へのfew-shot適応などが可能になることが示されています。オフライン強化学習においても同様の利点が期待されるものの、複数の解を学習するための適切な方法はこれまでの研究では十分に検討されていませんでした。
そこで本研究では、オフライン強化学習において複数の解を学習できるアルゴリズムを提案し、そのパフォーマンスを実証的に調査しました。実験の結果、提案されたアルゴリズムは、オフライン強化学習において定性的かつ定量的に異なる複数の解を学習できることが示されました。
Transactions of the International Society for Music Information Retrieval (ISMIR), April 2024
The Sound Demixing Challenge 2023 – Music Demixing Track
Fabbro, Giorgio and Uhlich, Stefan and Lai, Chieh-Hsin and Choi, Woosung and Martínez-Ramírez, Marco and Liao, Weihsiang and Gadelha, Igor and Ramos, Geraldo and Hsu, Eddie and Rodrigues, Hugo and Stöter, Fabian-Robert and Défossez, Alexandre and Luo, Yi and Yu, Jianwei and Chakraborty, Dipam and Mohanty, Sharada and Solovyev, Roman and Stempkovskiy, Alexander and Habruseva, Tatiana and Goswami, Nabarun and Harada, Tatsuya and Kim, Minseok and Lee, Jun Hyung and Dong, Yuanliang and Zhang, Xinran and Liu, Jiafeng and Mitsufuji, Yuki
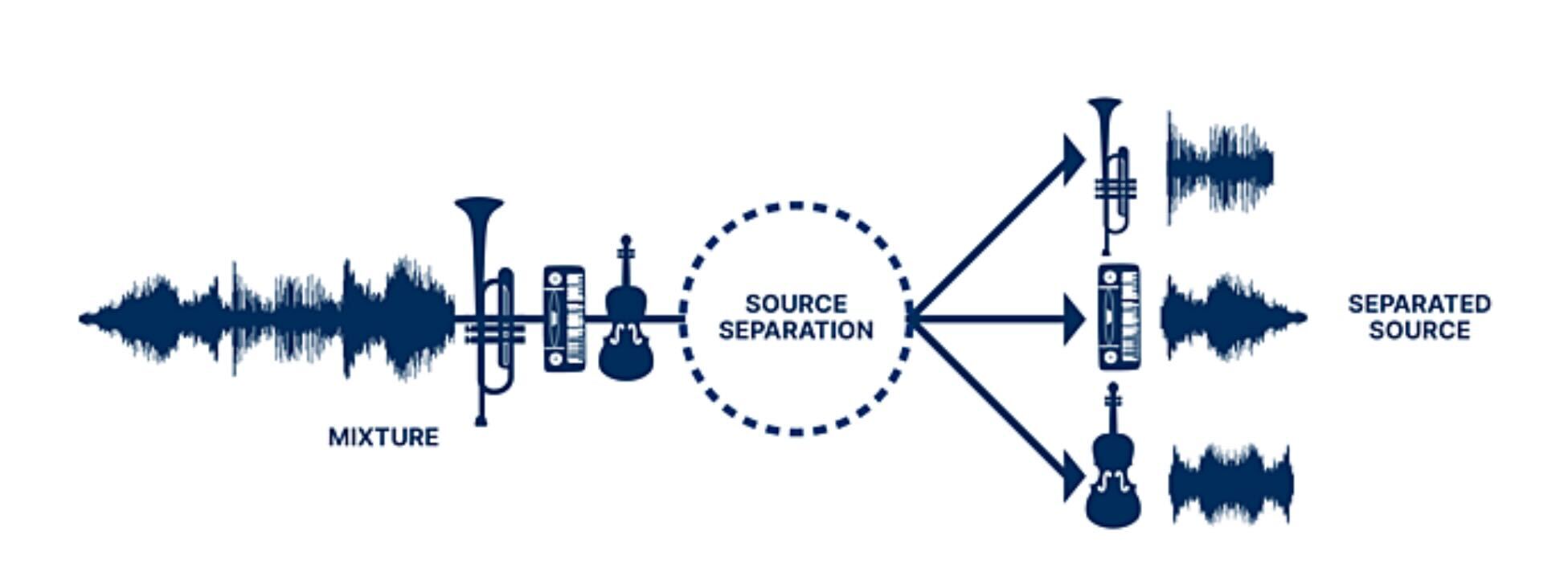 This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers and musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions. Link
This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers and musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions. Link
Proceedings of the IEEE International Conferences on Robotics and Automation (ICRA), 2024
Robustifying a Policy in Multi-Agent RL with Diverse Cooperative Behavior and Adversarial Style Sampling for Assistive Tasks
Takayuki Osa and Tatsuya Harada
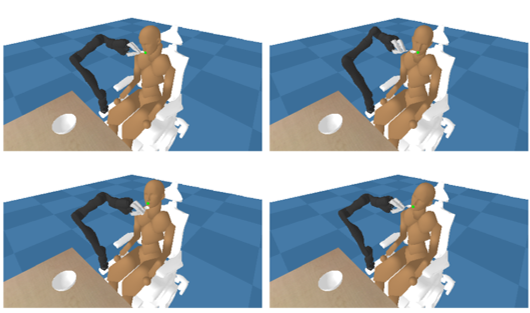 運動機能障害を抱える方々への支援は、ロボットスシステムの有望な応用先の一つです。既存研究では、食事の介護動作をマルチエージェント強化学習として定式化することで、被介護者の動きに合わせた動作をロボットが獲得できることが示されています。しかし、従来研究の手法では、被介護者の動きのタイプが変わると、ロボットがその動きに対応するためには再度の学習が必要となっていました。そこで本研究では、多様な被介護者の動きを自律的に生成し、多様な被介護者の動きに合わせて動作するロバストな動きをロボットに学習させる枠組みを提案しています。
運動機能障害を抱える方々への支援は、ロボットスシステムの有望な応用先の一つです。既存研究では、食事の介護動作をマルチエージェント強化学習として定式化することで、被介護者の動きに合わせた動作をロボットが獲得できることが示されています。しかし、従来研究の手法では、被介護者の動きのタイプが変わると、ロボットがその動きに対応するためには再度の学習が必要となっていました。そこで本研究では、多様な被介護者の動きを自律的に生成し、多様な被介護者の動きに合わせて動作するロバストな動きをロボットに学習させる枠組みを提案しています。
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration (173 authors, including Takayuki Osa, Yujin Tang, and Tatsuya Harada)
 大容量で多様なデータセットで訓練されたモデルは、効率的に様々な応用に取り組む上で注目すべき成功を収めています。このOpen X-Embodimentというプロジェクトでは、世界中の研究機関からロボットの動作データを収集し、マルチモーダルなモデルを訓練するという試みが行われました。21の機関の協力により収集された22台の異なるロボットからデータから、527のスキル(160,266のタスク)を含むデータセットを構築しました。これを用い、RT-Xというマルチモーダルなモデルを訓練し、複数の研究機関の異なるロボットにおいて動作することを確認しました。本研究室も、このプロジェクトに参加し、データを提供しています。
大容量で多様なデータセットで訓練されたモデルは、効率的に様々な応用に取り組む上で注目すべき成功を収めています。このOpen X-Embodimentというプロジェクトでは、世界中の研究機関からロボットの動作データを収集し、マルチモーダルなモデルを訓練するという試みが行われました。21の機関の協力により収集された22台の異なるロボットからデータから、527のスキル(160,266のタスク)を含むデータセットを構築しました。これを用い、RT-Xというマルチモーダルなモデルを訓練し、複数の研究機関の異なるロボットにおいて動作することを確認しました。本研究室も、このプロジェクトに参加し、データを提供しています。
The 12th International Conference on Learning Representations (ICLR), 2024
GPAvatar: Generalizable and Precise Head Avatar from Image(s)
Xuangeng Chu, Yu Li, Ailing Zeng, Tianyu Yang, Lijian Lin, Yunfei Liu, Tatsuya Harada
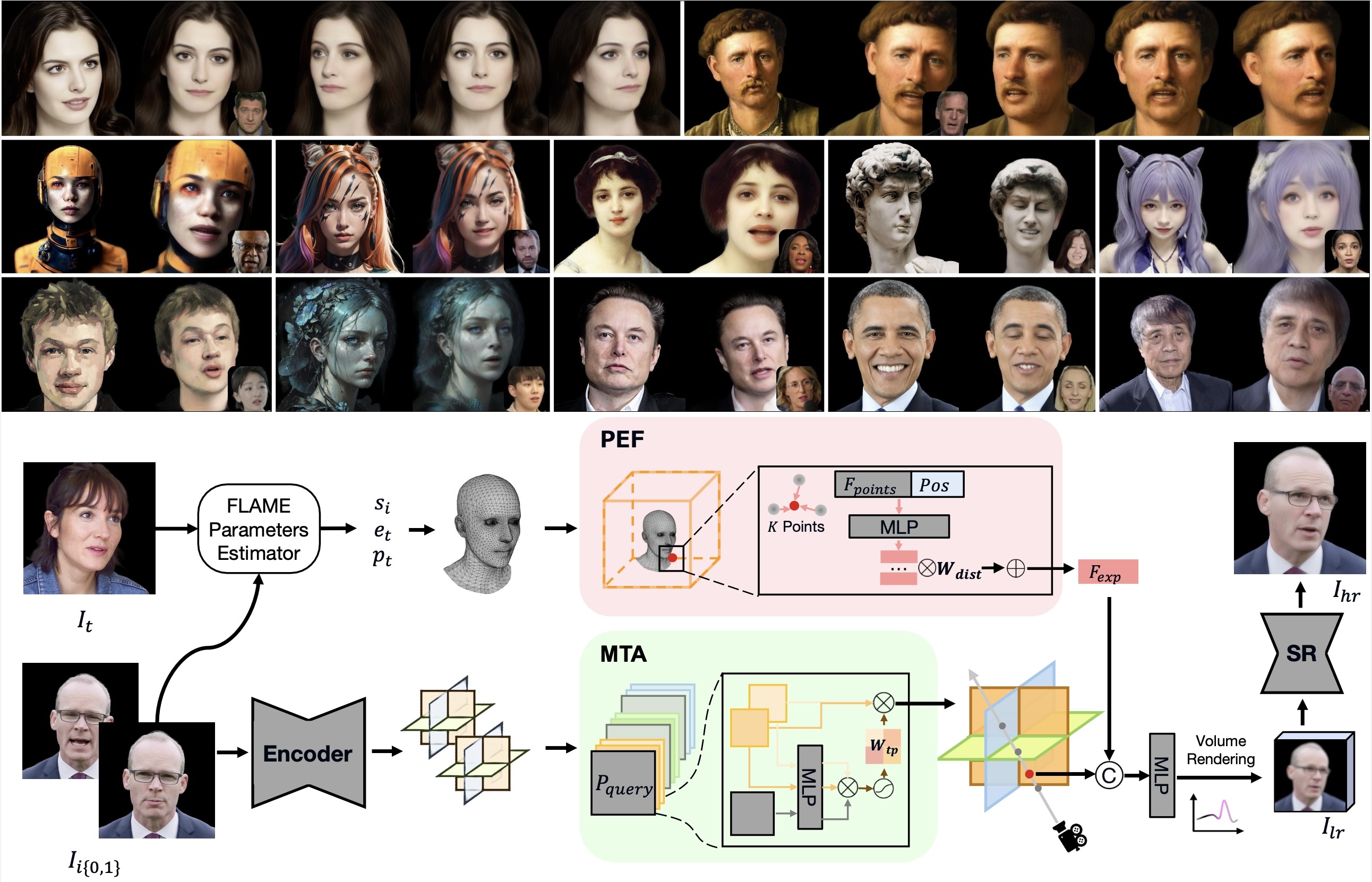 ヘッドアバターの再構築は、仮想現実、オンライン会議、ゲーム、映画産業などでの応用において非常に注目されています。この分野の基本的な目標は、ヘッドアバターを忠実に再現し、表情やポーズを正確に制御することです。既存の方法は、2Dベースのワーピング、メッシュベース、およびニューラルレンダリングのアプローチに分類され、複数の視点の一貫性の維持、非顔情報の統合、新しいアイデンティティへの一般化において課題があります。本論文では、GPAvatarというフレームワークを提案し、1回の順方向のパスで1枚または複数の画像から3Dヘッドアバターを再構築します。この作業の鍵となるアイデアは、ポイントクラウドによって駆動される動的なポイントベースの表現フィールドを導入し、表情を正確かつ効果的に捉えることです。さらに、複数の入力画像からの情報を活用するために、Tri-planesカノニカルフィールドにMulti Tri-planes Attention(MTA)フュージョンモジュールを使用しています。提案された方法は、忠実なアイデンティティの再構築、正確な表現の制御、および多視点の一貫性を実現し、自由視点のレンダリングや新しい視点の合成において有望な結果を示しています。
ヘッドアバターの再構築は、仮想現実、オンライン会議、ゲーム、映画産業などでの応用において非常に注目されています。この分野の基本的な目標は、ヘッドアバターを忠実に再現し、表情やポーズを正確に制御することです。既存の方法は、2Dベースのワーピング、メッシュベース、およびニューラルレンダリングのアプローチに分類され、複数の視点の一貫性の維持、非顔情報の統合、新しいアイデンティティへの一般化において課題があります。本論文では、GPAvatarというフレームワークを提案し、1回の順方向のパスで1枚または複数の画像から3Dヘッドアバターを再構築します。この作業の鍵となるアイデアは、ポイントクラウドによって駆動される動的なポイントベースの表現フィールドを導入し、表情を正確かつ効果的に捉えることです。さらに、複数の入力画像からの情報を活用するために、Tri-planesカノニカルフィールドにMulti Tri-planes Attention(MTA)フュージョンモジュールを使用しています。提案された方法は、忠実なアイデンティティの再構築、正確な表現の制御、および多視点の一貫性を実現し、自由視点のレンダリングや新しい視点の合成において有望な結果を示しています。
The 12th International Conference on Learning Representations (ICLR), 2024
GPAvatar: Generalizable and Precise Head Avatar from Image(s)
Xuangeng Chu, Yu Li, Ailing Zeng, Tianyu Yang, Lijian Lin, Yunfei Liu, Tatsuya Harada
Head avatar reconstruction, crucial for applications in virtual reality, online meetings, gaming, and film industries, has garnered substantial attention within the computer vision community. The fundamental objective of this field is to faithfully recreate the head avatar and precisely control expressions and postures. Existing methods, categorized into 2D-based warping, mesh-based, and neural rendering approaches, present challenges in maintaining multi-view consistency, incorporating non-facial information, and generalizing to new identities. In this paper, we propose a framework named GPAvatar that reconstructs 3D head avatars from one or several images in a single forward pass. The key idea of this work is to introduce a dynamic point-based expression field driven by a point cloud to precisely and effectively capture expressions. Furthermore, we use a Multi Tri-planes Attention (MTA) fusion module in tri-planes canonical field to leverage information from multiple input images. The proposed method achieves faithful identity reconstruction, precise expression control, and multi-view consistency, demonstrating promising results for free-viewpoint rendering and novel view synthesis.
Medical Image Analysis
Sketch-based semantic retrieval of medical images
Kazuma Kobayashi, Lin Gu, Ryuichiro Hataya, Takaaki Mizuno, Mototaka Miyake, Hirokazu Watanabe, Masamichi Takahashi, Yasuyuki Takamizawa, Yukihiro Yoshida, Satoshi Nakamura, Nobuji Kouno, Amina Bolatkan, Yusuke Kurose, Tatsuya Harada, Ryuji Hamamoto
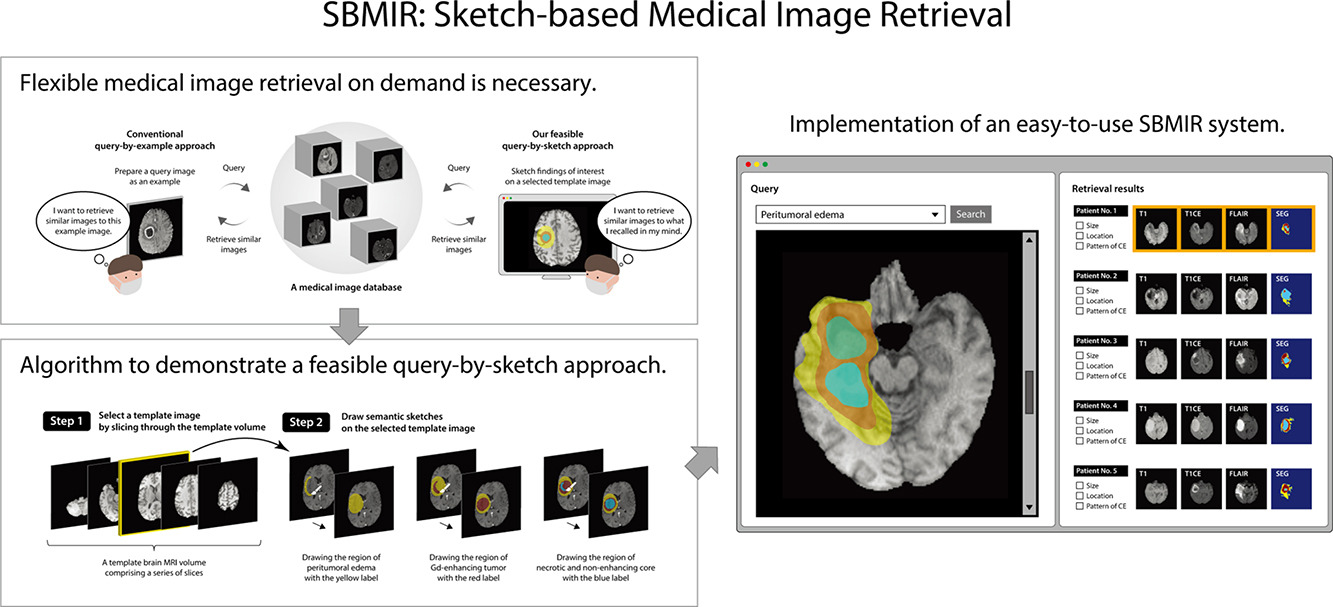 The volume of medical images stored in hospitals is rapidly increasing; however, the utilization of these accumulated medical images remains limited. Existing content-based medical image retrieval (CBMIR) systems typically require example images, leading to practical limitations, such as the lack of customizable, fine-grained image retrieval, the inability to search without example images, and difficulty in retrieving rare cases. In this paper, we introduce a sketch-based medical image retrieval (SBMIR) system that enables users to find images of interest without the need for example images. The key concept is feature decomposition of medical images, which allows the entire feature of a medical image to be decomposed into and reconstructed from normal and abnormal features. Building on this concept, our SBMIR system provides an easy-to-use two-step graphical user interface: users first select a template image to specify a normal feature and then draw a semantic sketch of the disease on the template image to represent an abnormal feature. The system integrates both types of input to construct a query vector and retrieves reference images. For evaluation, ten healthcare professionals participated in a user test using two datasets. Consequently, our SBMIR system enabled users to overcome previous challenges, including image retrieval based on fine-grained image characteristics, image retrieval without example images, and image retrieval for rare cases. Our SBMIR system provides on-demand, customizable medical image retrieval, thereby expanding the utility of medical image databases.
The volume of medical images stored in hospitals is rapidly increasing; however, the utilization of these accumulated medical images remains limited. Existing content-based medical image retrieval (CBMIR) systems typically require example images, leading to practical limitations, such as the lack of customizable, fine-grained image retrieval, the inability to search without example images, and difficulty in retrieving rare cases. In this paper, we introduce a sketch-based medical image retrieval (SBMIR) system that enables users to find images of interest without the need for example images. The key concept is feature decomposition of medical images, which allows the entire feature of a medical image to be decomposed into and reconstructed from normal and abnormal features. Building on this concept, our SBMIR system provides an easy-to-use two-step graphical user interface: users first select a template image to specify a normal feature and then draw a semantic sketch of the disease on the template image to represent an abnormal feature. The system integrates both types of input to construct a query vector and retrieves reference images. For evaluation, ten healthcare professionals participated in a user test using two datasets. Consequently, our SBMIR system enabled users to overcome previous challenges, including image retrieval based on fine-grained image characteristics, image retrieval without example images, and image retrieval for rare cases. Our SBMIR system provides on-demand, customizable medical image retrieval, thereby expanding the utility of medical image databases.
IJCV Special Issue on Multimodal Learning
Learning by Asking Questions for Knowledge-based Novel Object Recognition
Motoki Omura, Takayuki Osa, Yusuke Mukuta, Tatsuya Harada
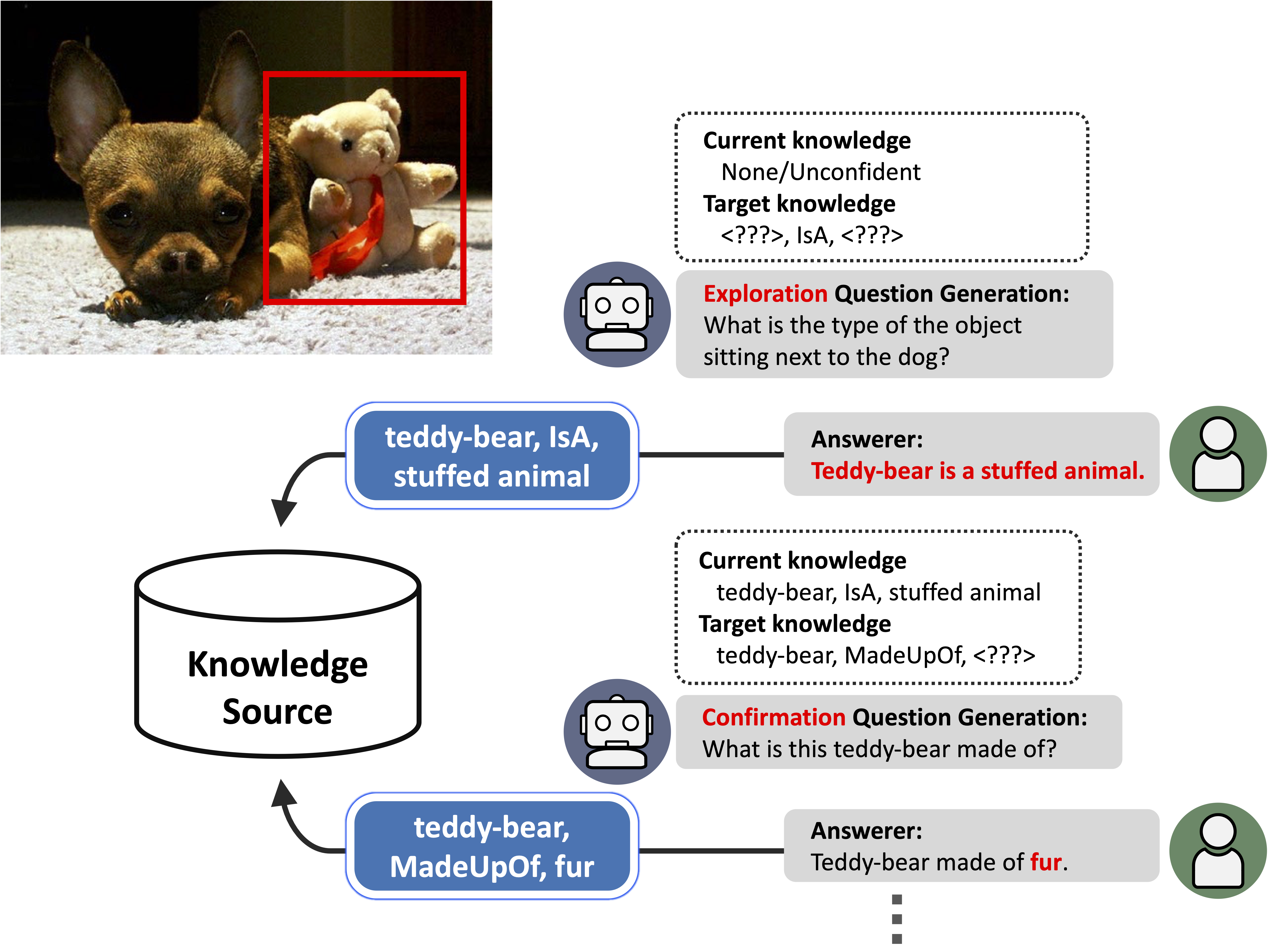 通常の画像認識モデルは,訓練データに存在しないカテゴリの物体(未知物体)を認識することはできませんが,これは画像認識システムの実世界応用における大きな課題となります.本研究では,質問生成を通じて自律的に未知物体に関する知識を獲得し,適応的に学習を行うシステムを実現します.提案したパイプラインは,知識に基づいた物体認識を行う物体認識モジュール,新しい知識を取得するための質問を生成する質問生成モジュール,そして質問の方策を決定する方策決定モジュールによって構成されます.方策決定モジュールでは,強化学習によって「どのような質問を生成すれば未知物体に関する知識を効率よく獲得できるか」を決定します.このパイプラインを用いることで,未知の物体が含まれる画像について,その物体を認識するためにもっとも適した質問を自動的に生成し,知識を獲得して新規物体認識を行うことができます.
通常の画像認識モデルは,訓練データに存在しないカテゴリの物体(未知物体)を認識することはできませんが,これは画像認識システムの実世界応用における大きな課題となります.本研究では,質問生成を通じて自律的に未知物体に関する知識を獲得し,適応的に学習を行うシステムを実現します.提案したパイプラインは,知識に基づいた物体認識を行う物体認識モジュール,新しい知識を取得するための質問を生成する質問生成モジュール,そして質問の方策を決定する方策決定モジュールによって構成されます.方策決定モジュールでは,強化学習によって「どのような質問を生成すれば未知物体に関する知識を効率よく獲得できるか」を決定します.このパイプラインを用いることで,未知の物体が含まれる画像について,その物体を認識するためにもっとも適した質問を自動的に生成し,知識を獲得して新規物体認識を行うことができます.
AAAI Conference on Artificial Intelligence (AAAI-24)
Symmetric Q-Learning: Reducing Skewness of Bellman Error in Online Reinforcement Learning
Motoki Omura, Takayuki Osa, Yusuke Mukuta, Tatsuya Harada
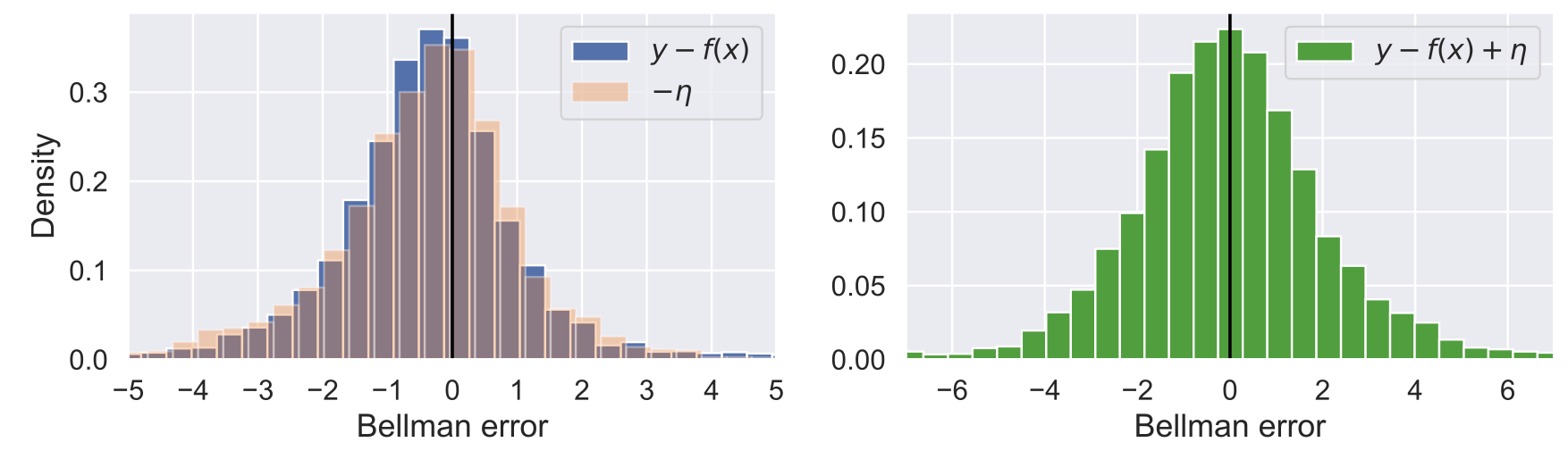 深層強化学習において、状態と行動を評価するために価値関数の推定が不可欠です。価値関数は主に最小二乗法を用いて訓練され、これは暗黙のうちに誤差分布が正規分布であることを前提としています。しかし、最近の研究によると、価値関数を訓練する際の誤差分布は、ベルマン演算子によって歪み、最小二乗法の正規誤差分布の仮定に違反することが示唆されています。これに対処するために、私たちは Symmetric Q-learning と呼ばれる方法を提案しました。これは、平均ゼロの分布から生成されたノイズを目標値に加えて、ガウス誤差分布を生成します。提案された方法はMuJoCoの連続行動制御ベンチマークタスクで評価され、誤差分布の歪みを減少させ、最先端の強化学習方法のサンプル効率を改善しました。
深層強化学習において、状態と行動を評価するために価値関数の推定が不可欠です。価値関数は主に最小二乗法を用いて訓練され、これは暗黙のうちに誤差分布が正規分布であることを前提としています。しかし、最近の研究によると、価値関数を訓練する際の誤差分布は、ベルマン演算子によって歪み、最小二乗法の正規誤差分布の仮定に違反することが示唆されています。これに対処するために、私たちは Symmetric Q-learning と呼ばれる方法を提案しました。これは、平均ゼロの分布から生成されたノイズを目標値に加えて、ガウス誤差分布を生成します。提案された方法はMuJoCoの連続行動制御ベンチマークタスクで評価され、誤差分布の歪みを減少させ、最先端の強化学習方法のサンプル効率を改善しました。
Aleth-NeRF: Illumination Adaptive NeRF with Concealing Field Assumption
Ziteng Cui, Lin Gu, Xiao Sun, Xianzheng Ma, Yu Qiao, Tatsuya Harada
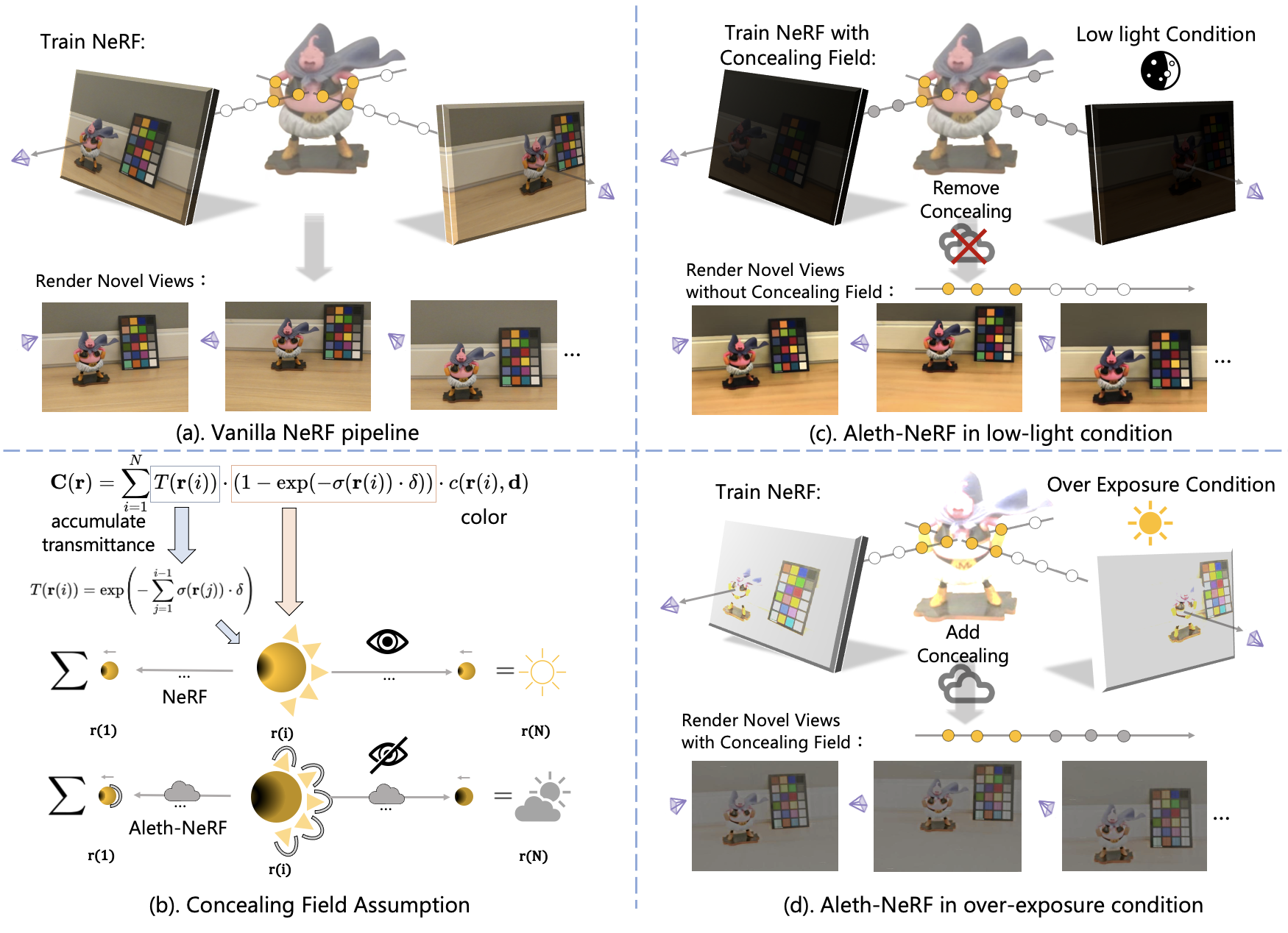 標準のNeRFのパラダイムは、ビューア中心の方法論を採用し、照明と物質の反射の側面を3Dポイントからの発光に絡め取ります。この単純なレンダリングアプローチは、低照明や過曝光などの不利な照明条件でキャプチャされた画像を正確にモデリングする際に課題を提供します。古代ギリシャの発光理論に触発され、視覚知覚を目から発せられる光線の結果として位置づけるものとして、私たちは従来のNeRFフレームワークをわずかに改良します。この改良は、NeRFを厳しい照明条件下でトレーニングし、非監視学習で通常の明るい条件で新しい視点を生成することを目指しています。私たちは「Concealing Field」という概念を導入し、周囲の空気に透過値を割り当てて照明効果を考慮します。暗いシナリオでは、物体の発光が標準の照明レベルを維持すると仮定しますが、レンダリングプロセス中に空気を通過すると減衰します。Concealing Fieldは、NeRFに対して暗い状況でも物体の適切な密度と色の推定を学習させるようにします。同様に、Concealing Fieldはレンダリング段階での過曝光した発光を軽減できます。さらに、評価用に厳しい照明条件下でキャプチャされた包括的なマルチビューデータセットも紹介します。
標準のNeRFのパラダイムは、ビューア中心の方法論を採用し、照明と物質の反射の側面を3Dポイントからの発光に絡め取ります。この単純なレンダリングアプローチは、低照明や過曝光などの不利な照明条件でキャプチャされた画像を正確にモデリングする際に課題を提供します。古代ギリシャの発光理論に触発され、視覚知覚を目から発せられる光線の結果として位置づけるものとして、私たちは従来のNeRFフレームワークをわずかに改良します。この改良は、NeRFを厳しい照明条件下でトレーニングし、非監視学習で通常の明るい条件で新しい視点を生成することを目指しています。私たちは「Concealing Field」という概念を導入し、周囲の空気に透過値を割り当てて照明効果を考慮します。暗いシナリオでは、物体の発光が標準の照明レベルを維持すると仮定しますが、レンダリングプロセス中に空気を通過すると減衰します。Concealing Fieldは、NeRFに対して暗い状況でも物体の適切な密度と色の推定を学習させるようにします。同様に、Concealing Fieldはレンダリング段階での過曝光した発光を軽減できます。さらに、評価用に厳しい照明条件下でキャプチャされた包括的なマルチビューデータセットも紹介します。
Winter Conference on Applications of Computer Vision (WACV), 2024
Gradual Source Domain Expansion for Unsupervised Domain Adaptation
Thomas Westfechtel, Hao-Wei Yeh, Dexuan Zhang, Tatsuya Harada
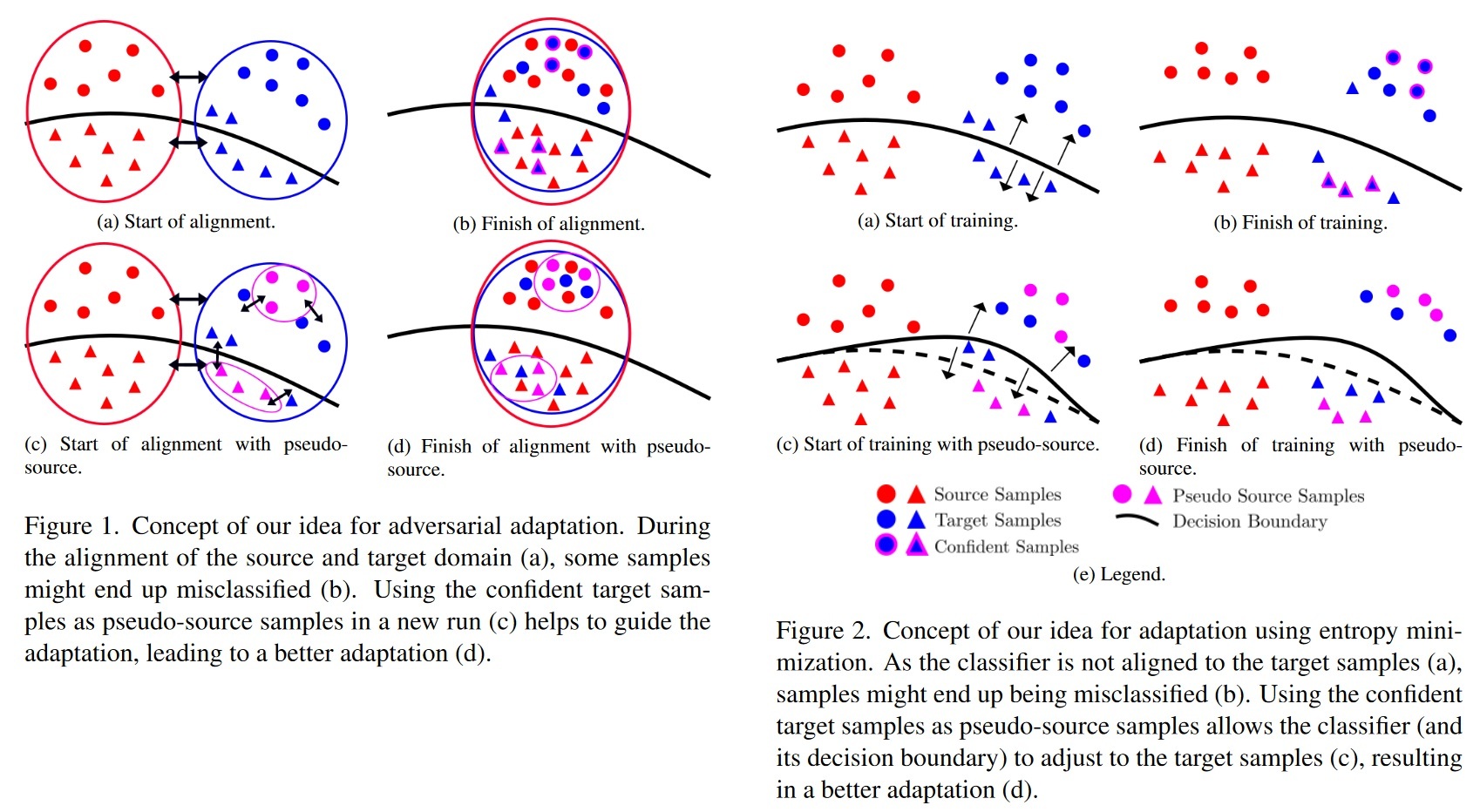 教師なし領域適応(UDA)は、大量のラベル付きデータを持つソースデータセットから、ラベル付きデータのないターゲットデータセットに知識を転送することで、大量のラベル付きデータセットの必要性を克服しようとするものである。多くのラベル付きデータを持つソース・データセットから、ラベル付きデータを持たないターゲット・データセットに知識を転送することで、大規模なラベル付きデータセットの必要性を克服しようとするものである。ターゲット領域にはラベルがないため、初期段階でのミスアライメントが後工程に伝播し、エラーの蓄積につながる可能性がある。この問題を克服するために、我々は漸進的ソースドメイン拡張(GSDE)アルゴリズムを提案する。GSDE は UDA タスクをゼロから数回訓練し、その都度ネットワークの重みを再初期化するが、その都度ソースデータセットをターゲットデータで拡張する。特に、前回の実行で最もスコアの高かったターゲットデータは、それぞれの擬似ラベルを持つ擬似ソースサンプルとして採用される。この戦略を用いることで、擬似ソースサンプルは、新しいトレーニングの開始から、前回の実行から抽出された知識を直接導入する。これにより、特に初期の学習エポックにおいて、2 つの領域をより良く整合させることができる。本研究では、まず強力なベースラインネットワークを導入し、それに我々の GSDE 戦略を適用する。我々は 3 つのベンチマーク(Office-31、OfficeHome、DomainNet)で実験とアブレーション研究を行い、最先端の手法を凌駕した。さらに、提案する GSDE 戦略が、様々な最先端の UDA アプローチの精度を改善できることを示す。
教師なし領域適応(UDA)は、大量のラベル付きデータを持つソースデータセットから、ラベル付きデータのないターゲットデータセットに知識を転送することで、大量のラベル付きデータセットの必要性を克服しようとするものである。多くのラベル付きデータを持つソース・データセットから、ラベル付きデータを持たないターゲット・データセットに知識を転送することで、大規模なラベル付きデータセットの必要性を克服しようとするものである。ターゲット領域にはラベルがないため、初期段階でのミスアライメントが後工程に伝播し、エラーの蓄積につながる可能性がある。この問題を克服するために、我々は漸進的ソースドメイン拡張(GSDE)アルゴリズムを提案する。GSDE は UDA タスクをゼロから数回訓練し、その都度ネットワークの重みを再初期化するが、その都度ソースデータセットをターゲットデータで拡張する。特に、前回の実行で最もスコアの高かったターゲットデータは、それぞれの擬似ラベルを持つ擬似ソースサンプルとして採用される。この戦略を用いることで、擬似ソースサンプルは、新しいトレーニングの開始から、前回の実行から抽出された知識を直接導入する。これにより、特に初期の学習エポックにおいて、2 つの領域をより良く整合させることができる。本研究では、まず強力なベースラインネットワークを導入し、それに我々の GSDE 戦略を適用する。我々は 3 つのベンチマーク(Office-31、OfficeHome、DomainNet)で実験とアブレーション研究を行い、最先端の手法を凌駕した。さらに、提案する GSDE 戦略が、様々な最先端の UDA アプローチの精度を改善できることを示す。