2023 年発表論文概要
Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023.
Detection Based Part-level Articulated Object Reconstruction from Single RGBD Image
Yuki Kawana, Tatsuya Harada
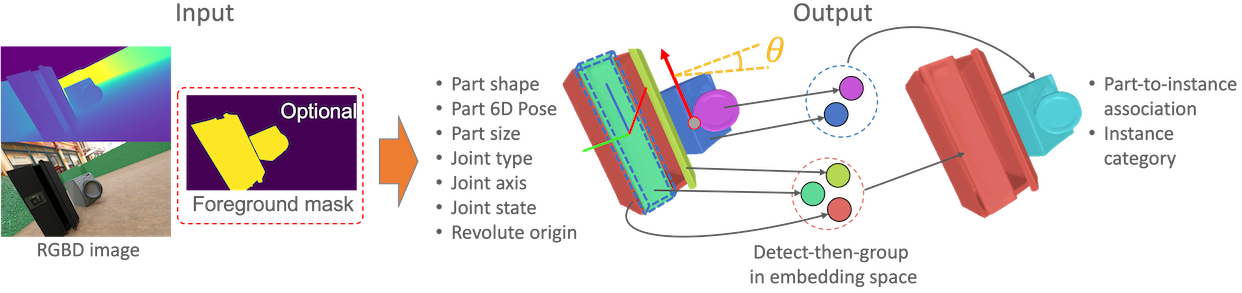 我々は、1 枚の RGBD 画像から複数のマルチカテゴリな人工関節物体を再構成するための、エンドツーエンドで学習可能な手法を提案する。先行研究は予め定義されたパーツ数を持つ人工関節物体に焦点を当て、インスタンスレベルの潜在空間の学習を行っていた。対して、本手法では検出されたパーツの組み合わせとしてインスタンスを表現する、パーツレベルの潜在空間表現を用いた新しいアプローチを提案する。この detect-then-group アプローチは、多様なパーツ構造や様々なパーツ数を持つインスタンスを効果的に扱うことができる。しかし、検出を用いたエンドツーエンド手法では誤検出、様々なパーツサイズやスケール、モデルサイズの増大といった問題に直面する。これらの問題に対処するため、我々は、1)誤検出を抑制しつつ検出性能を向上させる、パーツの動きを考慮した検出パーツ候補の推論時における統合方法、2)様々なパーツサイズやスケールに対応するための、パーツ形状学習のための異方性スケール正規化、3)モデルサイズを維持しつつパーツ検出を向上させるための特徴量空間と出力空間の横断的なリファインメント方法を提案する。SAPIEN データセットを用いた評価により、本手法が、従来の手法では扱えなかった様々な構造を持つ複数のインスタンスの再構成を可能にし、形状再構成とパーツの関節パラメータの推定において先行研究よりも優れていることを示す。また、実データへの汎化性を示す。
我々は、1 枚の RGBD 画像から複数のマルチカテゴリな人工関節物体を再構成するための、エンドツーエンドで学習可能な手法を提案する。先行研究は予め定義されたパーツ数を持つ人工関節物体に焦点を当て、インスタンスレベルの潜在空間の学習を行っていた。対して、本手法では検出されたパーツの組み合わせとしてインスタンスを表現する、パーツレベルの潜在空間表現を用いた新しいアプローチを提案する。この detect-then-group アプローチは、多様なパーツ構造や様々なパーツ数を持つインスタンスを効果的に扱うことができる。しかし、検出を用いたエンドツーエンド手法では誤検出、様々なパーツサイズやスケール、モデルサイズの増大といった問題に直面する。これらの問題に対処するため、我々は、1)誤検出を抑制しつつ検出性能を向上させる、パーツの動きを考慮した検出パーツ候補の推論時における統合方法、2)様々なパーツサイズやスケールに対応するための、パーツ形状学習のための異方性スケール正規化、3)モデルサイズを維持しつつパーツ検出を向上させるための特徴量空間と出力空間の横断的なリファインメント方法を提案する。SAPIEN データセットを用いた評価により、本手法が、従来の手法では扱えなかった様々な構造を持つ複数のインスタンスの再構成を可能にし、形状再構成とパーツの関節パラメータの推定において先行研究よりも優れていることを示す。また、実データへの汎化性を示す。
International Conference on Computer Vision (ICCV) 2023
Name Your Colour For the Task: Artificially Discover Colour Naming via Colour Quantisation Transformer
Shenghan Su, Lin Gu, Yue Yang, Zenghui Zhang, Tatsuya Harada
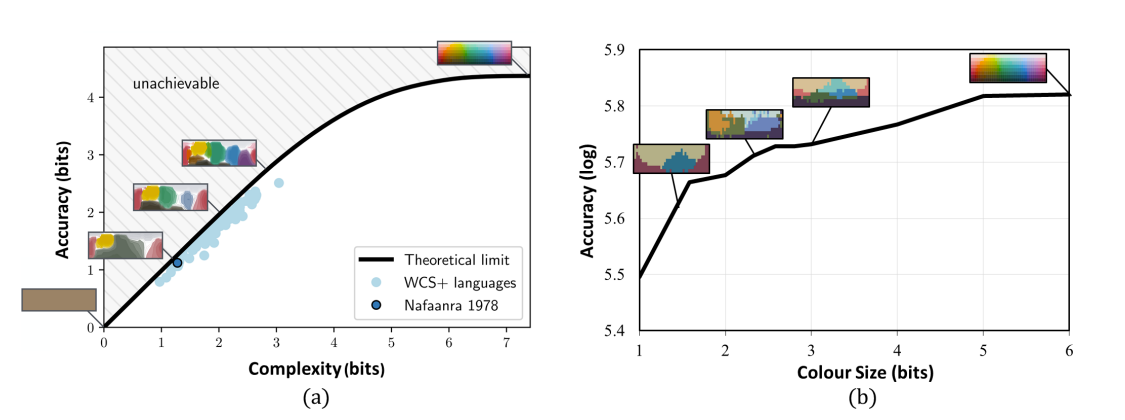 長い間続いてきた理論は、色の名前付けシステムが、効率的なコミュニケーションと知覚メカニズムの双方の圧力の下で進化するというものです。この理論は、ナファーンラ語の四十年間の歴史的なデータを分析するなど、言語学的な研究を含めてますます支持されています。このことから、機械学習が通信効率を最適化することにより、類似した色の名前付けシステムを進化・発見することができるかどうかを探求する動機を得ました。
私たちは、新しい色量子化トランスフォーマー、CQFormer を提案します。この CQFormer は、色空間を量子化する一方で、量子化された画像の機械認識の精度を維持します。RGB 画像が与えられると、注釈ブランチはそれをインデックスマップにマッピングし、その後、色パレットを用いて量子化された画像を生成します。一方、パレットブランチはキーポイント検出方式を使用して、色パレットから適切な色を全体の色空間の中から見つけ出します。色の注釈との相互作用により、CQFormer は機械ビジョンの精度と色の知覚構造(例:明確で安定した色分布)とのバランスを取ることができます。興味深いことに、私たちは人間の言語間の基本色用語と私たちの人工的な色システムの間で一貫した進化パターンを観察することさえあります。さらに、私たちの色量子化手法は、画像の圧縮を効果的に行いながら、分類や検出などの高レベルの認識タスクにおいて高い性能を維持する効率的な量子化手法を提供します。豊富な実験により、極めて低ビットレートの色でも私たちの手法が優れた性能を示し、画像からネットワークのアクティベーションまでを量化するために量化ネットワークに統合する可能性を示しています。
長い間続いてきた理論は、色の名前付けシステムが、効率的なコミュニケーションと知覚メカニズムの双方の圧力の下で進化するというものです。この理論は、ナファーンラ語の四十年間の歴史的なデータを分析するなど、言語学的な研究を含めてますます支持されています。このことから、機械学習が通信効率を最適化することにより、類似した色の名前付けシステムを進化・発見することができるかどうかを探求する動機を得ました。
私たちは、新しい色量子化トランスフォーマー、CQFormer を提案します。この CQFormer は、色空間を量子化する一方で、量子化された画像の機械認識の精度を維持します。RGB 画像が与えられると、注釈ブランチはそれをインデックスマップにマッピングし、その後、色パレットを用いて量子化された画像を生成します。一方、パレットブランチはキーポイント検出方式を使用して、色パレットから適切な色を全体の色空間の中から見つけ出します。色の注釈との相互作用により、CQFormer は機械ビジョンの精度と色の知覚構造(例:明確で安定した色分布)とのバランスを取ることができます。興味深いことに、私たちは人間の言語間の基本色用語と私たちの人工的な色システムの間で一貫した進化パターンを観察することさえあります。さらに、私たちの色量子化手法は、画像の圧縮を効果的に行いながら、分類や検出などの高レベルの認識タスクにおいて高い性能を維持する効率的な量子化手法を提供します。豊富な実験により、極めて低ビットレートの色でも私たちの手法が優れた性能を示し、画像からネットワークのアクティベーションまでを量化するために量化ネットワークに統合する可能性を示しています。
Transactions on Machine Learning Research
Unsupervised Domain Adaptation via Minimized Joint Error
Dexuan Zhang, Thomas Westfechtel, Tatsuya Harada
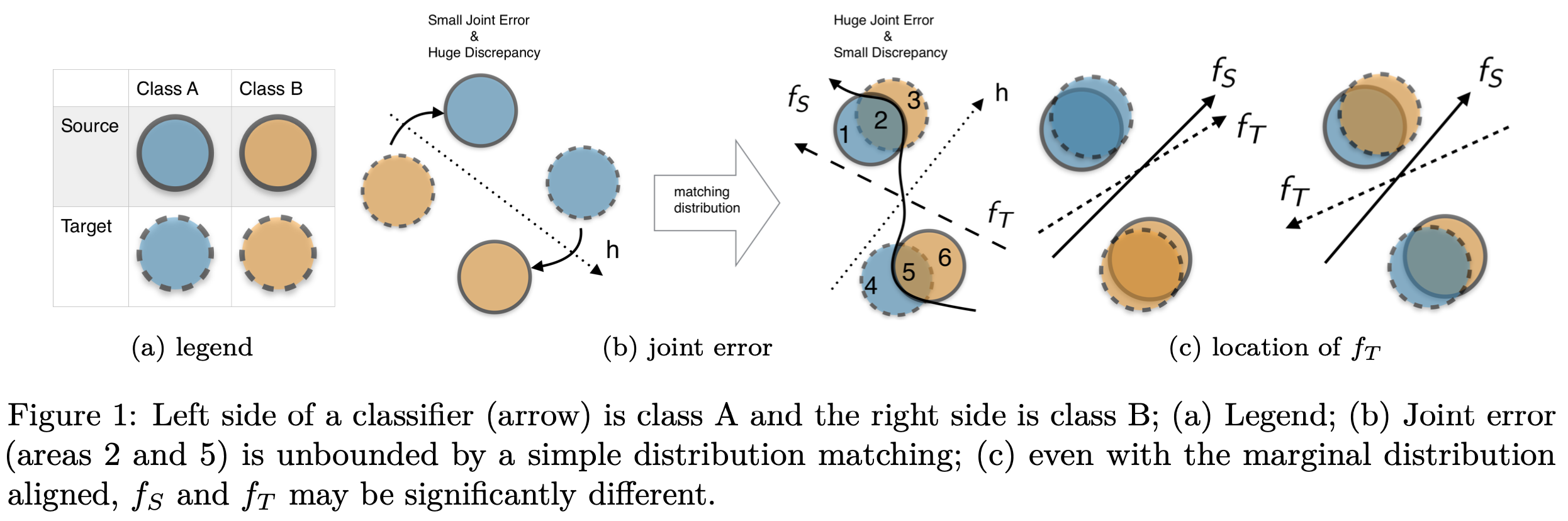 教師なしドメイン適応では、完全にラベル付けされたソースドメインから、ラベル付けされたデータが利用できない別のターゲット ドメインに知識が転送されます。一部の研究者は、知識を伝達する際の目標誤差の上限を提案しています。たとえば、Ben-David et al. (2010)はソースでの誤差と周辺分布間の距離を同時に最小化することに基づく理論を確立しました。しかし、ほとんどの研究では、ジョイントエラーは扱いにくいため無視されています。この研究では、特にドメインギャップが大きい場合、ジョイントエラーがドメイン適応問題に不可欠である事を主張します。この問題に対処するために、ジョイントエラーの上限に関連する新しい目的関数を提案します。さらに、ソース/疑似ターゲットラベルに基づく仮説空間を採用し、検索空間を削減してこの誤差上限をさらに厳しくすることができます。仮説間の非類似性を測定するために、敵対的学習の不安定性を軽減するために新しいクロスマージン距離を定義します。さらに、提案手法がドメイン適応ベンチマークで画像分類精度のパフォーマンスを向上させることを示す様々な実験結果を提示します。
教師なしドメイン適応では、完全にラベル付けされたソースドメインから、ラベル付けされたデータが利用できない別のターゲット ドメインに知識が転送されます。一部の研究者は、知識を伝達する際の目標誤差の上限を提案しています。たとえば、Ben-David et al. (2010)はソースでの誤差と周辺分布間の距離を同時に最小化することに基づく理論を確立しました。しかし、ほとんどの研究では、ジョイントエラーは扱いにくいため無視されています。この研究では、特にドメインギャップが大きい場合、ジョイントエラーがドメイン適応問題に不可欠である事を主張します。この問題に対処するために、ジョイントエラーの上限に関連する新しい目的関数を提案します。さらに、ソース/疑似ターゲットラベルに基づく仮説空間を採用し、検索空間を削減してこの誤差上限をさらに厳しくすることができます。仮説間の非類似性を測定するために、敵対的学習の不安定性を軽減するために新しいクロスマージン距離を定義します。さらに、提案手法がドメイン適応ベンチマークで画像分類精度のパフォーマンスを向上させることを示す様々な実験結果を提示します。
Invariant Feature Coding using Tensor Product Representation
Yusuke Mukuta, Tatsuya Harada
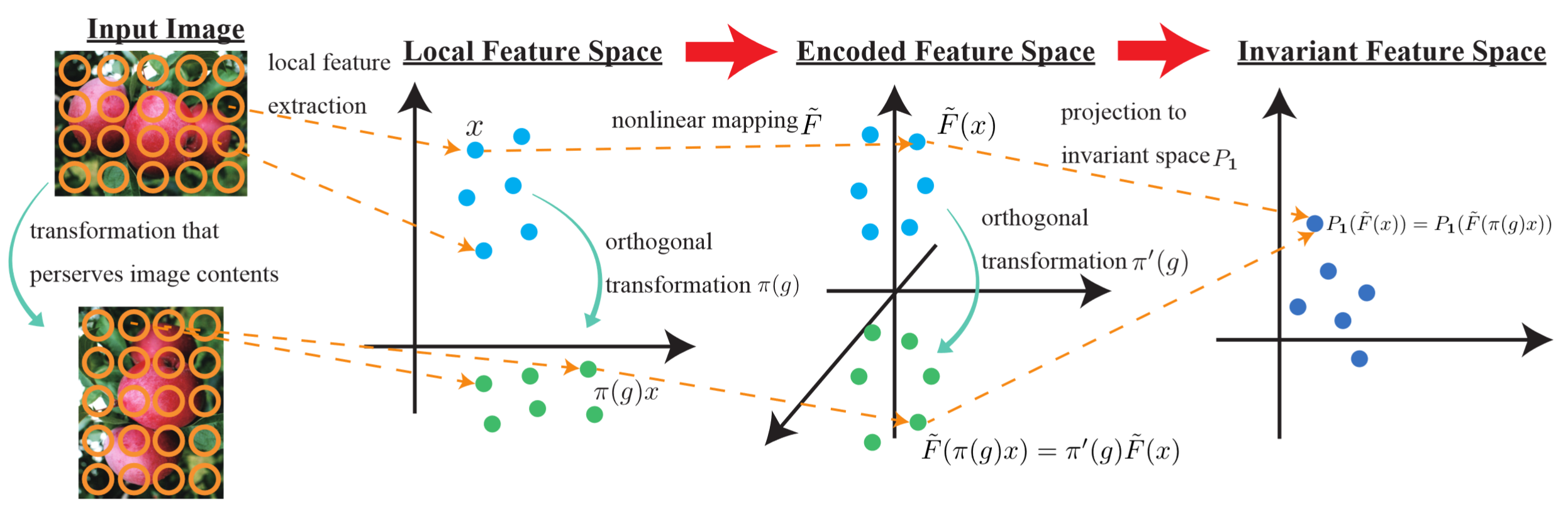 本論文では、有限群で表現される変換に対する不変性を利用した新しい特徴量コーディング手法を提案しました。まず我々は、線形 SVM のような凸識別損失最小化を用いて線形分類器の学習を行う時、群による変換に不変な特徴ベクトル成分が十分な識別情報を含むことを証明しました。この結果に基づき、多くの特徴量コーディング手法で一般的に用いられている主成分分析や k-means クラスタリングと、大域的特徴抽出関数に対して、群の作用を明示的に考慮した新しいモデルを提案しました。大域的特徴抽出関数は一般に複雑な非線形関数になりますが、これらの関数を基本的な表現のテンソル積表現として構成することによりこの空間上の群作用が容易に計算できるようになり、その結果不変な特徴関数を明示的の形が得られます。
本論文では、有限群で表現される変換に対する不変性を利用した新しい特徴量コーディング手法を提案しました。まず我々は、線形 SVM のような凸識別損失最小化を用いて線形分類器の学習を行う時、群による変換に不変な特徴ベクトル成分が十分な識別情報を含むことを証明しました。この結果に基づき、多くの特徴量コーディング手法で一般的に用いられている主成分分析や k-means クラスタリングと、大域的特徴抽出関数に対して、群の作用を明示的に考慮した新しいモデルを提案しました。大域的特徴抽出関数は一般に複雑な非線形関数になりますが、これらの関数を基本的な表現のテンソル積表現として構成することによりこの空間上の群作用が容易に計算できるようになり、その結果不変な特徴関数を明示的の形が得られます。
IEEE Robotics and Automation Letters
Learning Adaptive Policies for Autonomous Excavation Under Various Soil Conditions by Adversarial Domain Sampling
Takayuki Osa, Naoto Osajima, Masanori Aizawa, Tatsuya Harada
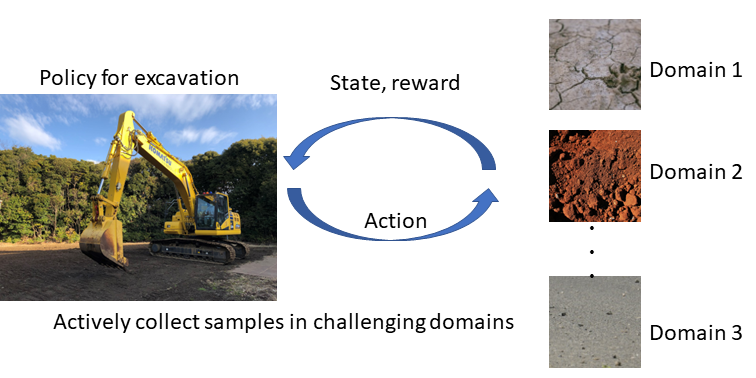 ショベルカーによる掘削作業は,建設現場等で多く行われる作業であり,これを自動化できれば,労働力不足に対する解決策になると考えられます.本研究では,深層強化学習をこのタスクに適用し,深度画像からショベルカーによる掘削軌道を計画することのできるモデルを訓練する枠組みを開発しています.この論文では特に,多様な土質に対応するためのモデルを獲得するための枠組みを提案しています.土質が変われば,効率よく掘削するための手順も変わりますが,効率の良い掘削を学習するための難易度も変わります.このような難易度にばらつきがある場合のマルチタスク学習を,敵対的学習の考え方を用いて安定的に行う手法を開発しました.
ショベルカーによる掘削作業は,建設現場等で多く行われる作業であり,これを自動化できれば,労働力不足に対する解決策になると考えられます.本研究では,深層強化学習をこのタスクに適用し,深度画像からショベルカーによる掘削軌道を計画することのできるモデルを訓練する枠組みを開発しています.この論文では特に,多様な土質に対応するためのモデルを獲得するための枠組みを提案しています.土質が変われば,効率よく掘削するための手順も変わりますが,効率の良い掘削を学習するための難易度も変わります.このような難易度にばらつきがある場合のマルチタスク学習を,敵対的学習の考え方を用いて安定的に行う手法を開発しました.
Medical Image Computing and Computer-Assisted Intervention (MICCAI 2023)
Towards AI-driven radiology education: A self-supervised segmentation-based framework for high-precision medical image editing
Kazuma Kobayashi, Lin Gu, Ryuichiro Hataya, Mototaka Miyake, Yasuyuki Takamizawa, Sono Ito, Hirokazu Watanabe, Yukihiro Yoshida, Hiroki Yoshimura, Tatsuya Harada, yuji Hamamoto
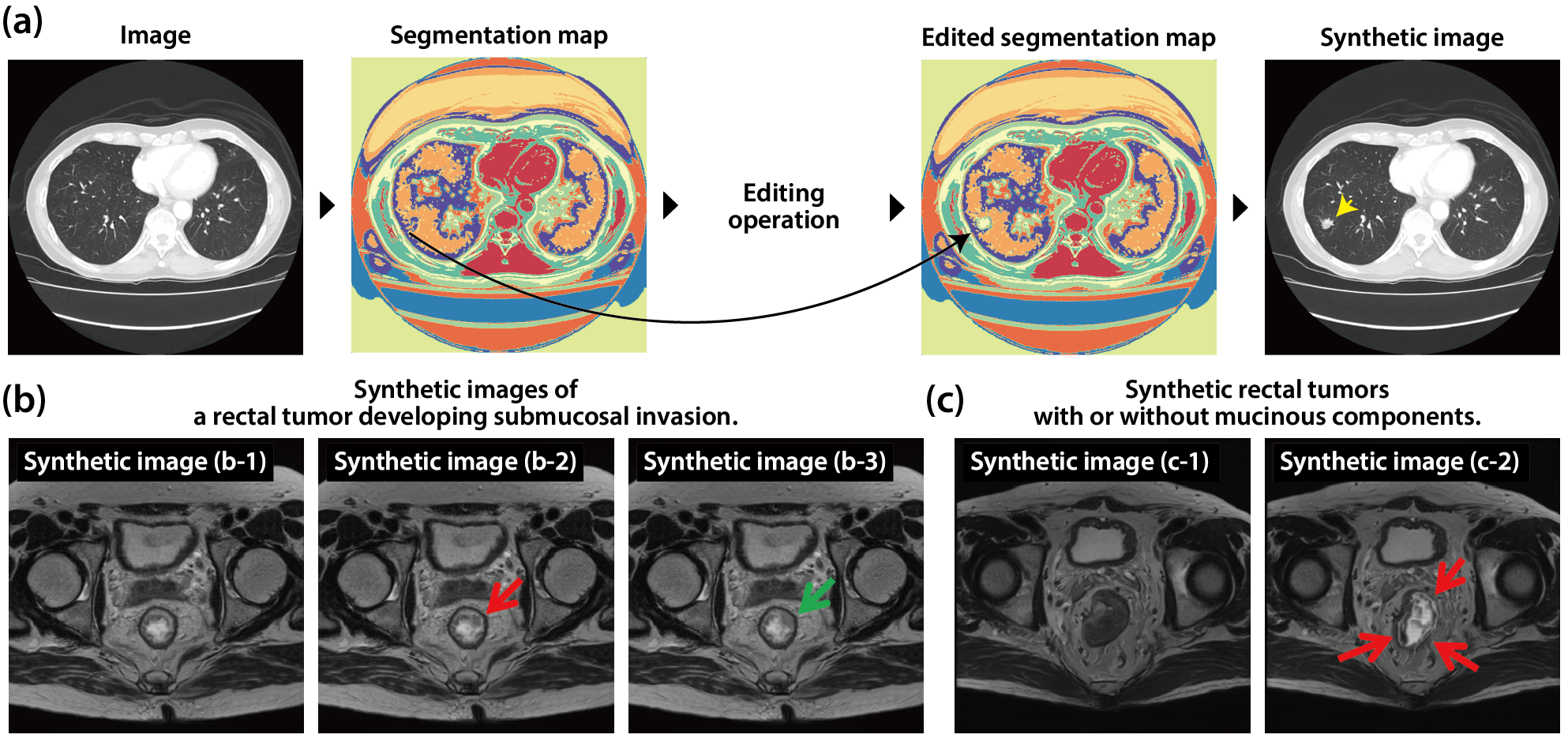 細かい特徴を持つ医用画像を画像編集によって生成することは、医師や深層学習モデルの訓練に有用です。ただし、画像編集技術には通常、大規模で手動で注釈付けされたラベルが必要であり、細かい解剖学的要素に対しては手間がかかり、また精度が低い場合があります。ここでは、自己教師あり学習によって獲得したセグメンテーションラベルを利用して、ユーザーが任意の解剖学的要素を編集できるアルゴリズムを提案します。私たちは、光度変換と幾何学的変換の不変性を保証する制約下で、ピクセル単位のクラスタリングを実現する自己教師あり医用画像セグメンテーションの効率的なアルゴリズムを開発しました。それを骨盤 MRI データセットと胸部 CT データセットの 2 つのデータセットに適用しました。得られたセグメンテーションマップはユーザーによって編集され、それを復号化することで、詳細な所見を持つ医用画像が生成されます。複数のライセンス医師の評価によれば、編集された医用画像は実際の画像とほとんど区別がつかず、特定の疾患特徴も正確に再現されました。これは、医師の訓練と診断支援のための潜在能力を示しています。
細かい特徴を持つ医用画像を画像編集によって生成することは、医師や深層学習モデルの訓練に有用です。ただし、画像編集技術には通常、大規模で手動で注釈付けされたラベルが必要であり、細かい解剖学的要素に対しては手間がかかり、また精度が低い場合があります。ここでは、自己教師あり学習によって獲得したセグメンテーションラベルを利用して、ユーザーが任意の解剖学的要素を編集できるアルゴリズムを提案します。私たちは、光度変換と幾何学的変換の不変性を保証する制約下で、ピクセル単位のクラスタリングを実現する自己教師あり医用画像セグメンテーションの効率的なアルゴリズムを開発しました。それを骨盤 MRI データセットと胸部 CT データセットの 2 つのデータセットに適用しました。得られたセグメンテーションマップはユーザーによって編集され、それを復号化することで、詳細な所見を持つ医用画像が生成されます。複数のライセンス医師の評価によれば、編集された医用画像は実際の画像とほとんど区別がつかず、特定の疾患特徴も正確に再現されました。これは、医師の訓練と診断支援のための潜在能力を示しています。
MedIM: Boost Medical Image Representation via Radiology Report-guided Masking
Yutong Xie, Lin Gu , Tatsuya Harada, Jianpeng Zhang, Yong Xia, Qi Wu
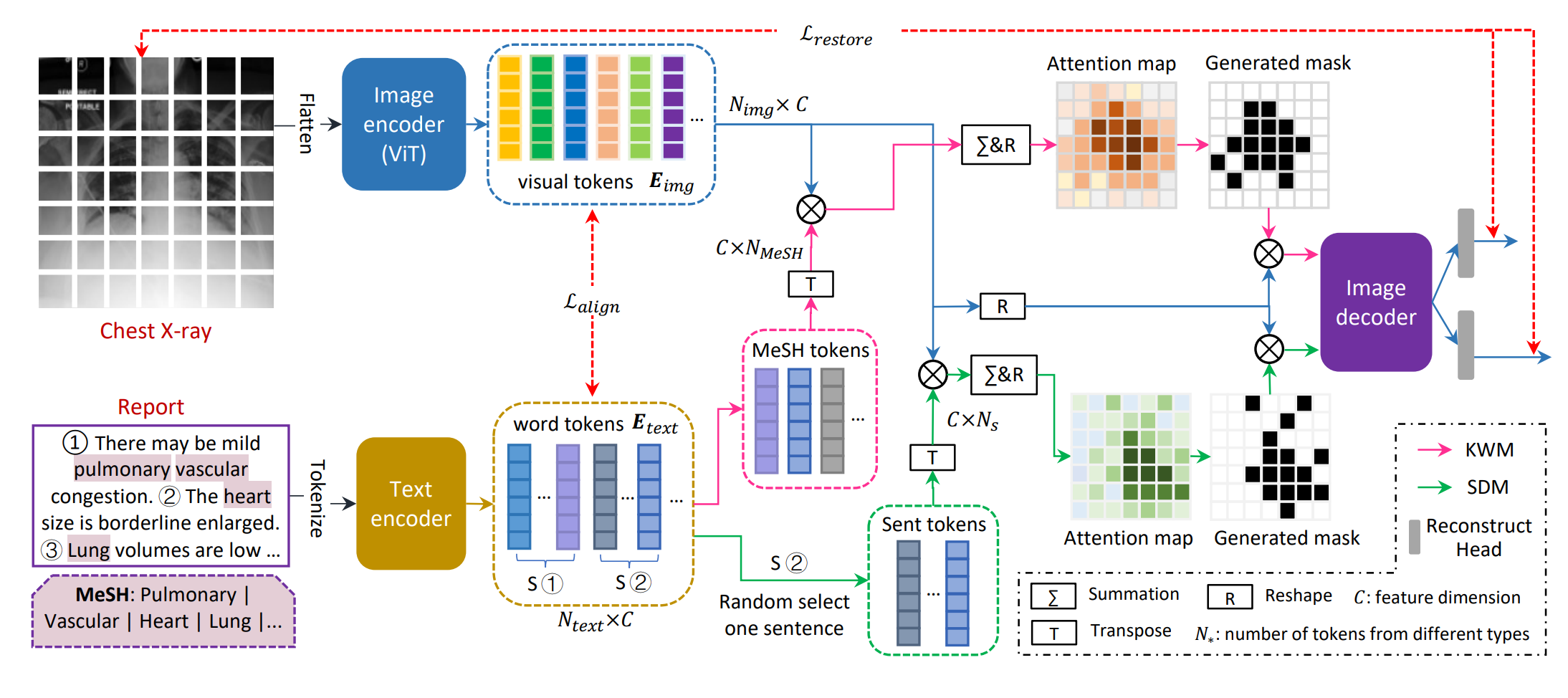 マスク画像モデリング(MIM)に基づく事前トレーニングは、画像パッチをランダムにマスクし、再構築することで、限られた注釈付きデータを使用して画像表現の改善の可能性を示しています。ただし、ランダムなマスキングは医療画像には適していない場合があります。本論文では、医療画像モデリング(MedIM)という新しいアプローチを提案します。これは、放射線報告によってガイドされた識別領域をマスクし再構築する、私たちの知る限りでは初めての研究です。これにより、ネットワークが医療画像からより強力な意味的表現を探索することが促されます。私たちは、2 つの相互包括的なマスキング戦略、知識語に基づくマスキング(KWM)および文に基づくマスキング(SDM)を導入します。KWM は、放射線報告に固有のメディカルサブジェクトヘッディング(MeSH)単語を使用して、MeSH 単語にマッピングされた識別的な手がかりを特定し、マスク生成をガイドします。SDM は、レポートには通常、異なる所見を説明する複数の文があることを考慮し、文レベルの情報を統合してマスク生成のための識別的な領域を特定します。MedIM は、KWM と SDM によって同時にマスクされた画像を復元することにより、より堅牢かつ代表的な医療視覚表現を実現します。私たちの広範な実験は、多ラベル/クラスの画像分類、医療画像セグメンテーション、医療画像テキスト分析をカバーし、レポートによるマスキングを使用した MedIM が競争力のあるパフォーマンスを実現することを示しています。私たちの手法は、ImageNet の事前トレーニング、MIM ベースの事前トレーニング、および医療画像レポートの事前トレーニングの対応手法を大幅に上回ります。ソースコードと事前トレーニング済みモデルは公開されます。
マスク画像モデリング(MIM)に基づく事前トレーニングは、画像パッチをランダムにマスクし、再構築することで、限られた注釈付きデータを使用して画像表現の改善の可能性を示しています。ただし、ランダムなマスキングは医療画像には適していない場合があります。本論文では、医療画像モデリング(MedIM)という新しいアプローチを提案します。これは、放射線報告によってガイドされた識別領域をマスクし再構築する、私たちの知る限りでは初めての研究です。これにより、ネットワークが医療画像からより強力な意味的表現を探索することが促されます。私たちは、2 つの相互包括的なマスキング戦略、知識語に基づくマスキング(KWM)および文に基づくマスキング(SDM)を導入します。KWM は、放射線報告に固有のメディカルサブジェクトヘッディング(MeSH)単語を使用して、MeSH 単語にマッピングされた識別的な手がかりを特定し、マスク生成をガイドします。SDM は、レポートには通常、異なる所見を説明する複数の文があることを考慮し、文レベルの情報を統合してマスク生成のための識別的な領域を特定します。MedIM は、KWM と SDM によって同時にマスクされた画像を復元することにより、より堅牢かつ代表的な医療視覚表現を実現します。私たちの広範な実験は、多ラベル/クラスの画像分類、医療画像セグメンテーション、医療画像テキスト分析をカバーし、レポートによるマスキングを使用した MedIM が競争力のあるパフォーマンスを実現することを示しています。私たちの手法は、ImageNet の事前トレーニング、MIM ベースの事前トレーニング、および医療画像レポートの事前トレーニングの対応手法を大幅に上回ります。ソースコードと事前トレーニング済みモデルは公開されます。
Pattern Recognition
Correlated and individual feature learning with contrast-enhanced MR for malignancy characterization of hepatocellular carcinoma
Yunling Li, Shangxuan Li, Hanqiu Ju, Tatsuya Harada, Honglai Zhang, Ting Duan, Guangyi Wang, Lijuan Zhang, Lin Gu, Wu Zhou
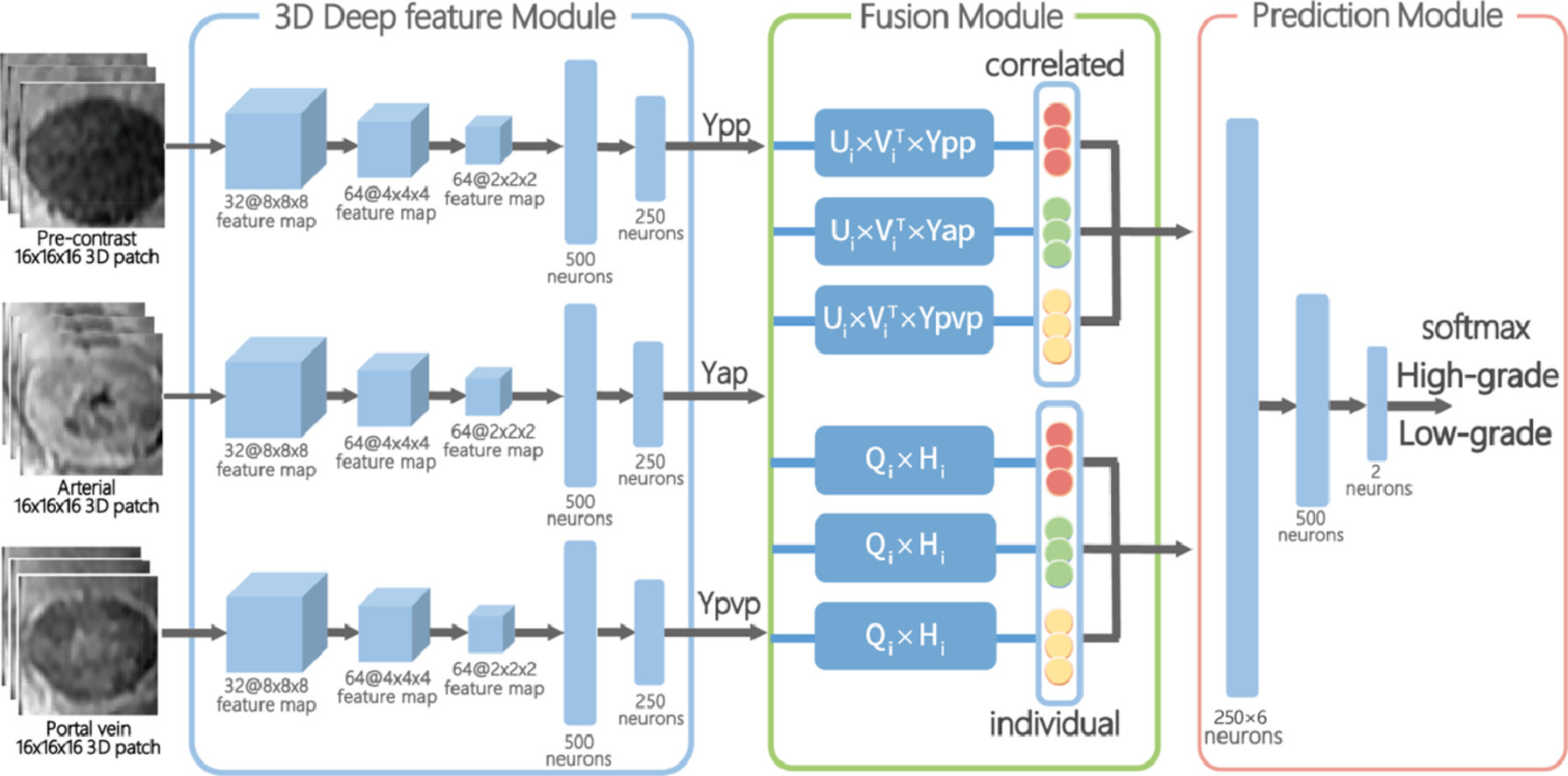 肝細胞癌(HCC)の悪性度の特性評価は、患者管理と予後予測において非常に重要です。本研究では、コントラスト強調 MR(磁気共鳴)から HCC の悪性度を特徴づけるためのエンドツーエンドの相関および個別の特徴学習フレームワークを提案します。事前コントラスト、動脈、および門脈のフェーズから、フレームワークは同時かつ明示的に、悪性度グレードに特異的な特徴と共有可能な特徴の両方を学習します。本研究では、117 例の組織学的に証明された HCC を持つ 112 人の連続した患者のコントラスト強調 MR を評価しました。実験結果は、動脈フェーズが門脈フェーズおよび事前コントラストフェーズよりも優れた結果を示すことを示しました。さらに、フェーズ固有の要素は共有可能な要素よりも優れた識別能力を示します。最後に、抽出された共有可能な特徴と個別の特徴要素を組み合わせることで、従来の特徴融合手法よりも明らかに優れたパフォーマンスが得られました。また、t-SNE 分析および特徴スコアリング分析を実施し、提案された方法の悪性度特性評価の効果を定性的に評価しました。
肝細胞癌(HCC)の悪性度の特性評価は、患者管理と予後予測において非常に重要です。本研究では、コントラスト強調 MR(磁気共鳴)から HCC の悪性度を特徴づけるためのエンドツーエンドの相関および個別の特徴学習フレームワークを提案します。事前コントラスト、動脈、および門脈のフェーズから、フレームワークは同時かつ明示的に、悪性度グレードに特異的な特徴と共有可能な特徴の両方を学習します。本研究では、117 例の組織学的に証明された HCC を持つ 112 人の連続した患者のコントラスト強調 MR を評価しました。実験結果は、動脈フェーズが門脈フェーズおよび事前コントラストフェーズよりも優れた結果を示すことを示しました。さらに、フェーズ固有の要素は共有可能な要素よりも優れた識別能力を示します。最後に、抽出された共有可能な特徴と個別の特徴要素を組み合わせることで、従来の特徴融合手法よりも明らかに優れたパフォーマンスが得られました。また、t-SNE 分析および特徴スコアリング分析を実施し、提案された方法の悪性度特性評価の効果を定性的に評価しました。
SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2023)
Expert Knowledge-Aware Image Difference Graph Representation Learning for Difference-Aware Medical Visual Question Answering
Xinyue Hu, Lin Gu, Qiyuan An, Zhang Mengliang, Liangchen Liu, Kazuma Kobayashi, Tatsuya Harada, Ronald M. Summers, Yingying Zhu
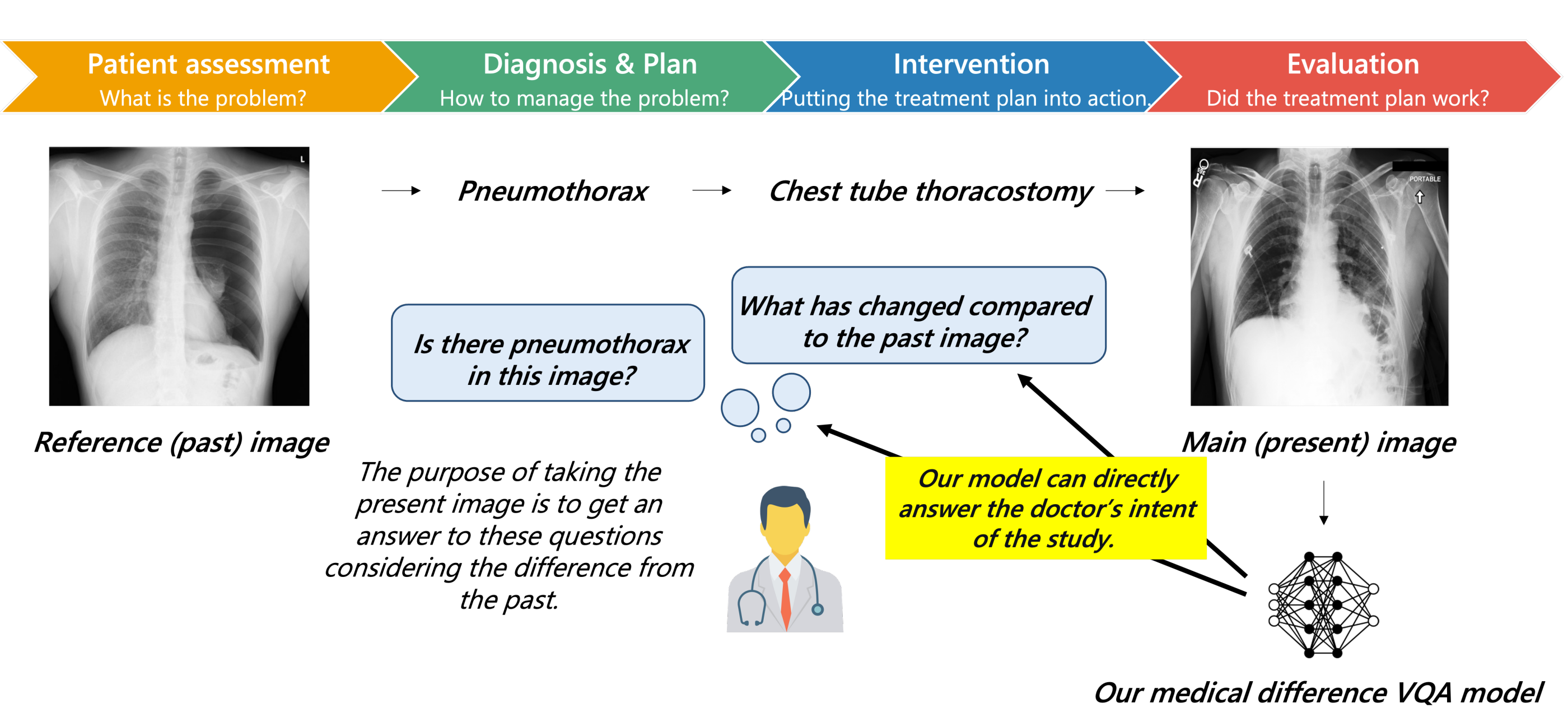 私たちは、新しい胸部 X 線異なる視覚的質問応答(VQA)タスクを提案します。このタスクでは、メイン画像と参照画像のペアが与えられ、病気に関するいくつかの質問と、さらに重要なこととして、それらの間の違いについて答えようとします。これは、診断医の診断手法と一致しており、レポートをまとめる前に現在の画像を参照画像と比較する実践を反映しています。私たちは、MIMIC-Diff-VQA という新しいデータセットを収集しました。このデータセットには、109,790 対のメイン画像と参照画像に関する 698,739 の QA ペアが含まれています。既存の医療 VQA データセットと比較して、私たちの質問は臨床専門家が使用する評価-診断-介入-評価の治療手順に合わせて調整されています。一方、私たちはまた、このタスクに対処するための新しい専門家知識に基づいたグラフ表現学習モデルを提案しています。提案されたベースラインモデルは、解剖学的構造事前情報、意味的知識、空間的知識などの専門家知識を活用して、メイン画像と参照画像の間の画像の違いを表現する多関係グラフを構築します。データセットとコードは、公開された際に提供されます。この研究が医療ビジョン言語モデルをさらに前進させると考えています。
私たちは、新しい胸部 X 線異なる視覚的質問応答(VQA)タスクを提案します。このタスクでは、メイン画像と参照画像のペアが与えられ、病気に関するいくつかの質問と、さらに重要なこととして、それらの間の違いについて答えようとします。これは、診断医の診断手法と一致しており、レポートをまとめる前に現在の画像を参照画像と比較する実践を反映しています。私たちは、MIMIC-Diff-VQA という新しいデータセットを収集しました。このデータセットには、109,790 対のメイン画像と参照画像に関する 698,739 の QA ペアが含まれています。既存の医療 VQA データセットと比較して、私たちの質問は臨床専門家が使用する評価-診断-介入-評価の治療手順に合わせて調整されています。一方、私たちはまた、このタスクに対処するための新しい専門家知識に基づいたグラフ表現学習モデルを提案しています。提案されたベースラインモデルは、解剖学的構造事前情報、意味的知識、空間的知識などの専門家知識を活用して、メイン画像と参照画像の間の画像の違いを表現する多関係グラフを構築します。データセットとコードは、公開された際に提供されます。この研究が医療ビジョン言語モデルをさらに前進させると考えています。
IEEE International Symposium on Biomedical Imaging (ISBI)
Domain Adaptive Multiple Instance Learning for Instance-level Prediction of Pathological Images
Shusuke Takahama, Yusuke Kurose, Yusuke Mukuta, Hiroyuki Abe, Akihiko Yoshizawa, Tetsuo Ushiku, Masashi Fukayama, Masanobu Kitagawa, Masaru Kitsuregawa, Tatsuya Harada
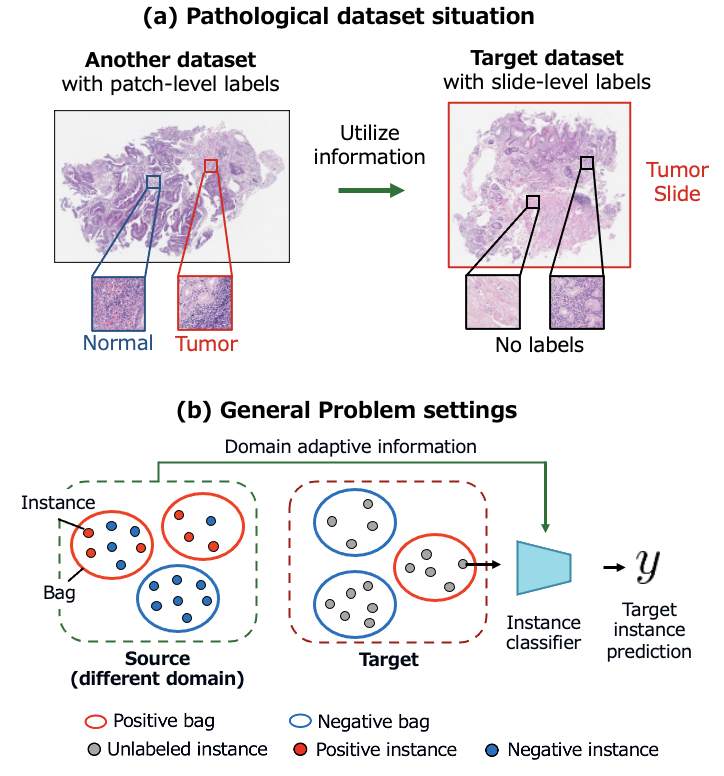 病理画像解析は細胞画像を観察してガンなどの異常を発見するための重要な診断であり、近年画像認識技術を病理画像に適用して医師を診断を補助する試みが多く行われています。
精度良い診断モデルの学習には大量の正解データが必要ですが、病理画像のラベリングには医師の専門知識と多大な労力が必要になるのが課題です。
本研究では、ラベリングのコストを抑えつつ精度良い診断モデルを得るため、粗い粒度のみのラベルでモデル学習ができる Multiple instance learning という弱教師あり学習手法を取り入れました。さらに、別のデータセットの情報を活かす転移学習の手法である Domain adaptation や擬似ラベリングなどの技術を取り入れた新しい学習パイプラインを提案しました。
実験では、我々が独自に集めた胃生検と大腸の病理画像データセットを使って実験を行い、ラベル付けコストを抑えたまま高い精度で異常箇所を発見できることを確かめました。 (arXiv)
病理画像解析は細胞画像を観察してガンなどの異常を発見するための重要な診断であり、近年画像認識技術を病理画像に適用して医師を診断を補助する試みが多く行われています。
精度良い診断モデルの学習には大量の正解データが必要ですが、病理画像のラベリングには医師の専門知識と多大な労力が必要になるのが課題です。
本研究では、ラベリングのコストを抑えつつ精度良い診断モデルを得るため、粗い粒度のみのラベルでモデル学習ができる Multiple instance learning という弱教師あり学習手法を取り入れました。さらに、別のデータセットの情報を活かす転移学習の手法である Domain adaptation や擬似ラベリングなどの技術を取り入れた新しい学習パイプラインを提案しました。
実験では、我々が独自に集めた胃生検と大腸の病理画像データセットを使って実験を行い、ラベル付けコストを抑えたまま高い精度で異常箇所を発見できることを確かめました。 (arXiv)
2nd Workshop on Learning with Limited Labelled Data for Image and Video Understanding (CVPR2023 workshop)
Zero-shot Object Classification with Large-scale Knowledge Graph
Kohei Shiba, Yusuke Mukuta, Tatsuya Harada
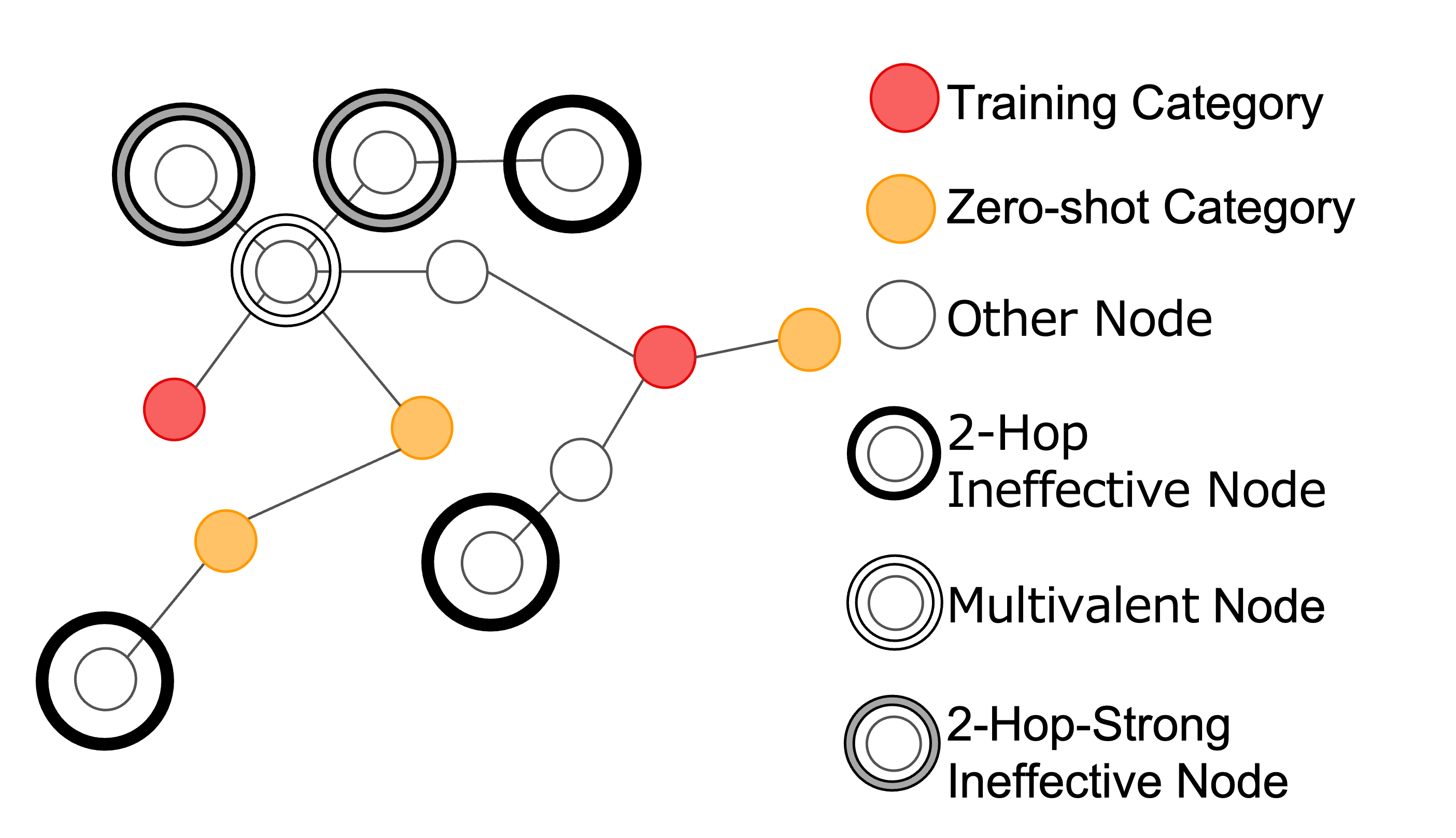 一般に画像認識は大量のデータセットを使用し、新たなカテゴリの分類には再学習を必要とします.それに対し、未知カテゴリの予測を目的としたゼロショット学習が研究されており、知識グラフを用いる手法があります。本研究では、大規模知識グラフをゼロショット画像認識に適用し、より多くの対象の分類と高精度な認識を目指します。ノイズとなる情報も増加するため,知識グラフ上の位置関係や関係性の種類といった情報を用いて有効な情報のみを抽出する手法を提案します。既存手法では不可能であった対象の分類を行うとともに、提案するデータ抽出手法で精度が向上することを示しました。
一般に画像認識は大量のデータセットを使用し、新たなカテゴリの分類には再学習を必要とします.それに対し、未知カテゴリの予測を目的としたゼロショット学習が研究されており、知識グラフを用いる手法があります。本研究では、大規模知識グラフをゼロショット画像認識に適用し、より多くの対象の分類と高精度な認識を目指します。ノイズとなる情報も増加するため,知識グラフ上の位置関係や関係性の種類といった情報を用いて有効な情報のみを抽出する手法を提案します。既存手法では不可能であった対象の分類を行うとともに、提案するデータ抽出手法で精度が向上することを示しました。
Computer Speech & Language
COMPASS: A creative support system that alerts novelists to the unnoticed missing contents
Yusuke Mori, Hiroaki Yamane, Ryohei Shimizu, Yusuke Mukuta, Tatsuya Harada
 物語を書くことは簡単なことではなく、プロの小説家でもいきなり完璧な物語が書けるとは限りません。時には、編集者からの客観的なアドバイスによって、作家自身では気付いていなかった改善点を知ることもあります。私たちは、作家が意図せず欠落させてしまった情報の補完を提案する小説執筆支援システム「COMPASS」を提案しました。創作活動において日本語を用いるプロのクリエイター 4 名に評価実験に参加していただき、提案システムの有用性を確認しました。この取り組みが、クリエイターと AI との共作の研究を、さらに発展させるための一助となることを願っています。 (paper(open access))
物語を書くことは簡単なことではなく、プロの小説家でもいきなり完璧な物語が書けるとは限りません。時には、編集者からの客観的なアドバイスによって、作家自身では気付いていなかった改善点を知ることもあります。私たちは、作家が意図せず欠落させてしまった情報の補完を提案する小説執筆支援システム「COMPASS」を提案しました。創作活動において日本語を用いるプロのクリエイター 4 名に評価実験に参加していただき、提案システムの有用性を確認しました。この取り組みが、クリエイターと AI との共作の研究を、さらに発展させるための一助となることを願っています。 (paper(open access))
Association for the Advancement of Artificial Intelligence (AAAI 2023)
People taking photos that faces never share: Privacy Protection and Fairness Enhancement from Camera to User
Junjie Zhu, Lin Gu, Xiaoxiao Wu, Zheng Li, Tatsuya Harada, Yingying Zhu
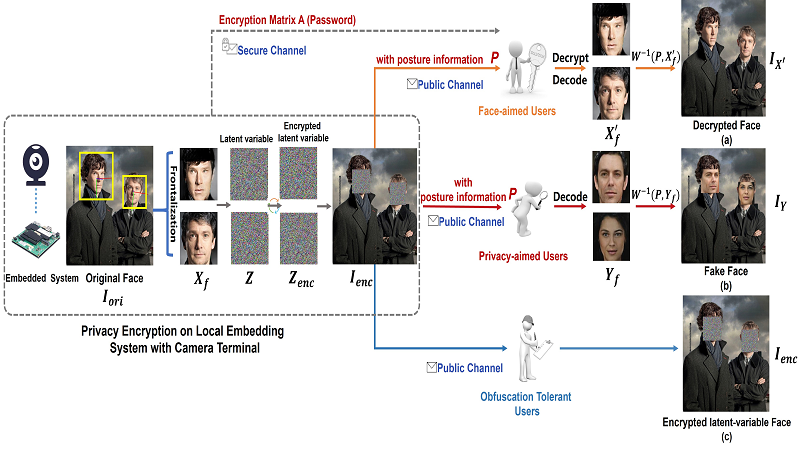 携帯端末や公衆カメラの急増は,基本的人権や倫理観に脅威を与えています.例えば,悪意のある第三者によって顔画像のような個人情報が盗まれると,悲惨な結果に繋がります.既存の顔画像保護アルゴリズムは,画像中の顔の外観を操作することで,効果的ですが不可逆なものがほとんどです.本論文では,カメラから最終ユーザーまでの全プロセスにおいて,顔情報を不可逆的に保護する実用的かつ体系的なソリューションを提案します.具体的には,カメラとプライベートに接続されたローカルな組み込みシステム上で,データ伝送中の盗聴のリスクを最小化する,新しい軽量の Flow-based Face Encryption Method(フローベースの顔暗号化方式,FFEM)を設計します.FFEM は,フローベースの顔エンコーダを用いて各顔をガウス分布に符号化し,回転行列をパスワードとしてガウス分布をランダムに回転させることで符号化された顔特徴量を暗号化します.暗号化された潜在変数型顔画像が比較的信頼性の低い経路でユーザーに公開されるのに対し,パスワードは非対称暗号化,ブロックチェーン,その他の高度なセキュリティスキームなどの技術により,より安全な経路で保護されます.ユーザーは,公開チャンネルで暗号化された画像から偽の顔を含む画像を選択して復号することができます.信頼できるユーザーのみが,安全なチャネルで送信された暗号化された行列を使用して,元の顔を復元することができます.さらに興味深いことに,潜在空間におけるガウス球を調整することで,性別や人種などの属性に対して,置き換えられた顔の公平性を制御することが可能です.提案手法が,高度なタスクに影響を与えることなく,プライバシーの保護と公平性の向上を実現できることを,広範な実験により実証しています.
携帯端末や公衆カメラの急増は,基本的人権や倫理観に脅威を与えています.例えば,悪意のある第三者によって顔画像のような個人情報が盗まれると,悲惨な結果に繋がります.既存の顔画像保護アルゴリズムは,画像中の顔の外観を操作することで,効果的ですが不可逆なものがほとんどです.本論文では,カメラから最終ユーザーまでの全プロセスにおいて,顔情報を不可逆的に保護する実用的かつ体系的なソリューションを提案します.具体的には,カメラとプライベートに接続されたローカルな組み込みシステム上で,データ伝送中の盗聴のリスクを最小化する,新しい軽量の Flow-based Face Encryption Method(フローベースの顔暗号化方式,FFEM)を設計します.FFEM は,フローベースの顔エンコーダを用いて各顔をガウス分布に符号化し,回転行列をパスワードとしてガウス分布をランダムに回転させることで符号化された顔特徴量を暗号化します.暗号化された潜在変数型顔画像が比較的信頼性の低い経路でユーザーに公開されるのに対し,パスワードは非対称暗号化,ブロックチェーン,その他の高度なセキュリティスキームなどの技術により,より安全な経路で保護されます.ユーザーは,公開チャンネルで暗号化された画像から偽の顔を含む画像を選択して復号することができます.信頼できるユーザーのみが,安全なチャネルで送信された暗号化された行列を使用して,元の顔を復元することができます.さらに興味深いことに,潜在空間におけるガウス球を調整することで,性別や人種などの属性に対して,置き換えられた顔の公平性を制御することが可能です.提案手法が,高度なタスクに影響を与えることなく,プライバシーの保護と公平性の向上を実現できることを,広範な実験により実証しています.
Winter Conference on Applications of Computer Vision (WACV 2023)
Backprop Induced Feature Weighting for Adversarial Domain Adaptation with Iterative Label Distribution Alignment
Thomas Westfechtel, Hao-Wei Yeh, Qier Meng, Yusuke Mukuta, Tatsuya Harada
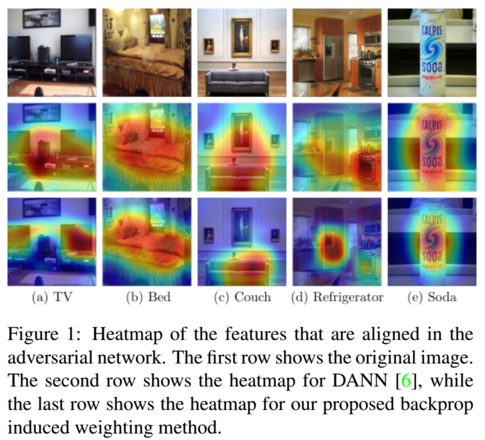 大規模なラベル付きデータセットが必要であることは,正確なディープニューラルネットワークの訓練を制限している要因の 1 つです.教師なしドメイン適応は,多くのラベル付きデータを持つあるドメインから,ラベル付きデータがほとんどない別のドメインに知識を転送することで,この限られた学習データの問題に取り組むものです.
一般的なアプローチとして,例えば敵対的アプローチでドメイン不変の特徴を学習することがあります.従来の方法では,ドメイン分類器とラベル分類器ネットワークを別々に学習することが多く,両分類器ネットワークは互いにほとんど相互作用しません.
本論文では,特徴空間のバックプロップ誘導による重み付けに基づく分類器を紹介します.このアプローチには主に 2 つの利点があります.まず,領域分類器が分類に重要な特徴に焦点を当てることができ,次に,分類と敵対的分岐をより密接に結合させることができます.
さらに,クラスバランスのとれたデータローダを実現するために,過去の実行結果を利用した反復ラベル分布アライメント法を導入しています.提案アルゴリズムの有効性を示すため,Office-31,OfficeHome,DomainNet の 3 つのベンチマークで実験とアブレーションを行いました.
大規模なラベル付きデータセットが必要であることは,正確なディープニューラルネットワークの訓練を制限している要因の 1 つです.教師なしドメイン適応は,多くのラベル付きデータを持つあるドメインから,ラベル付きデータがほとんどない別のドメインに知識を転送することで,この限られた学習データの問題に取り組むものです.
一般的なアプローチとして,例えば敵対的アプローチでドメイン不変の特徴を学習することがあります.従来の方法では,ドメイン分類器とラベル分類器ネットワークを別々に学習することが多く,両分類器ネットワークは互いにほとんど相互作用しません.
本論文では,特徴空間のバックプロップ誘導による重み付けに基づく分類器を紹介します.このアプローチには主に 2 つの利点があります.まず,領域分類器が分類に重要な特徴に焦点を当てることができ,次に,分類と敵対的分岐をより密接に結合させることができます.
さらに,クラスバランスのとれたデータローダを実現するために,過去の実行結果を利用した反復ラベル分布アライメント法を導入しています.提案アルゴリズムの有効性を示すため,Office-31,OfficeHome,DomainNet の 3 つのベンチマークで実験とアブレーションを行いました.
K-VQG: Knowledge-aware Visual Question Generation for Common-sense Acquisition
Kohei Uehara, Tatsuya Harada
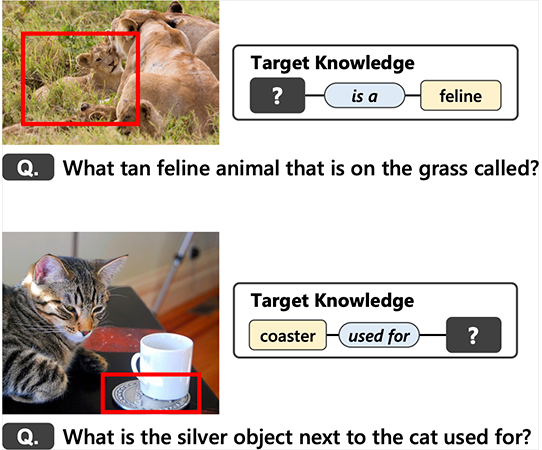 本研究では,画像中の物体についての知識を獲得できるような画像質問文生成(VQG,Visual Question Generation)に取り組んでいます.物体に関する知識の獲得は,画像に関する質問の動機として重要と考えられますが,そのための手法やデータセットは今まで存在しませんでした.そこで,我々は,画像と獲得したい知識に関する質問文をクラウドソーシングを用いて大規模に収集し,知識に関する VQG データセット(K-VQG データセット)を構築しました.さらに,所望の知識情報(知識トリプレット)を入力として利用する VQG モデルを提案し,知識をターゲットとした質問生成を実現しました.
本研究では,画像中の物体についての知識を獲得できるような画像質問文生成(VQG,Visual Question Generation)に取り組んでいます.物体に関する知識の獲得は,画像に関する質問の動機として重要と考えられますが,そのための手法やデータセットは今まで存在しませんでした.そこで,我々は,画像と獲得したい知識に関する質問文をクラウドソーシングを用いて大規模に収集し,知識に関する VQG データセット(K-VQG データセット)を構築しました.さらに,所望の知識情報(知識トリプレット)を入力として利用する VQG モデルを提案し,知識をターゲットとした質問生成を実現しました.