Abstracts of papers published in 2026
International Conference on Machine Learning, ICML 2026
Revisiting Regularized Policy Optimization for Stable and Efficient Reinforcement Learning in Two-Player Games
Kazuki Ota, Takayuki Osa, Motoki Omura, Tatsuya Harada
 Two-player games such as board games have long been used as traditional benchmarks for reinforcement learning. This work revisits a policy optimization method with reverse Kullback-Leibler regularization and entropy regularization and analyzes this combination in two-player zero-sum settings from theoretical and empirical perspectives. From a theoretical perspective, we investigate the stability of the policy update rule in two theoretical settings: game-theoretic normal-form games and finite-length games. We provide novel convergence guarantees and verify our theoretical results through numerical experiments on synthetic games. From an empirical perspective, we derive a practical model-free reinforcement learning algorithm based on the regularized policy optimization. We validate the training efficiency of our algorithm through comprehensive experiments on five board games: Animal Shogi, Gardner Chess, Go, Hex, and Othello. Experimental results show that our agent learns more efficiently than existing methods across environments.
Two-player games such as board games have long been used as traditional benchmarks for reinforcement learning. This work revisits a policy optimization method with reverse Kullback-Leibler regularization and entropy regularization and analyzes this combination in two-player zero-sum settings from theoretical and empirical perspectives. From a theoretical perspective, we investigate the stability of the policy update rule in two theoretical settings: game-theoretic normal-form games and finite-length games. We provide novel convergence guarantees and verify our theoretical results through numerical experiments on synthetic games. From an empirical perspective, we derive a practical model-free reinforcement learning algorithm based on the regularized policy optimization. We validate the training efficiency of our algorithm through comprehensive experiments on five board games: Animal Shogi, Gardner Chess, Go, Hex, and Othello. Experimental results show that our agent learns more efficiently than existing methods across environments.
International Conference on Acoustics, Speech and Signal Processing, ICASSP 2026
Hybrid Speech Enhancement with Discriminative and Codec Token Prediction Models Guided by Cleaned SSL Features for the ICASSP 2026 Urgent Challenge
Nabarun Goswami, Tatsuya Harada
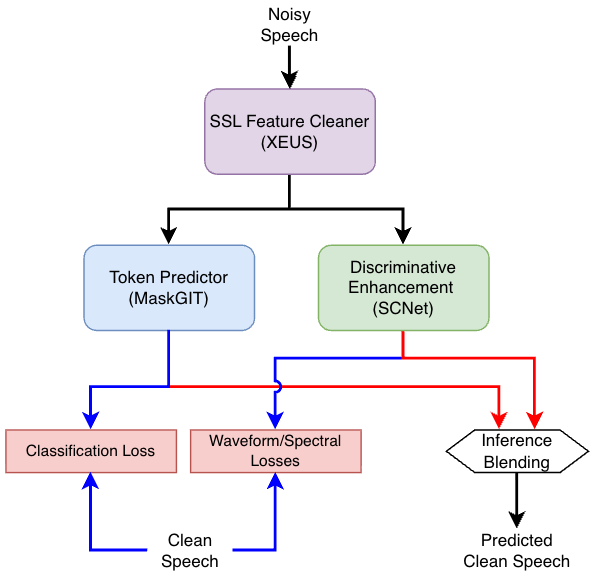 This paper presents a hybrid speech enhancement system for the ICASSP 2026 URGENT Challenge. The system combines a discriminative speech enhancement model with a generative token prediction model operating in a neural audio codec domain. Both models are conditioned on cleaned self-supervised (SSL) features obtained via parallel adapters applied to early SSL layers. The final enhanced waveform is produced by blending the discriminative and generative outputs. Despite being trained only on URGENT2025 data and without exposure to newly introduced speech categories, the proposed system generalizes well, achieving a third-place ranking in the objective evaluation phase and second place in the final subjective evaluation.
This paper presents a hybrid speech enhancement system for the ICASSP 2026 URGENT Challenge. The system combines a discriminative speech enhancement model with a generative token prediction model operating in a neural audio codec domain. Both models are conditioned on cleaned self-supervised (SSL) features obtained via parallel adapters applied to early SSL layers. The final enhanced waveform is produced by blending the discriminative and generative outputs. Despite being trained only on URGENT2025 data and without exposure to newly introduced speech categories, the proposed system generalizes well, achieving a third-place ranking in the objective evaluation phase and second place in the final subjective evaluation.
Reinforcement Learning Conference, RLC 2026
Learning the Supports for Categorical Critic in Reinforcement Learning
Jen-Yen Chang, Takayuki Osa, Tatsuya Harada
Value functions are an essential component in actor-critic based deep reinforcement learning (RL). Conventionally, these functions are trained as a regression task by minimising the mean squared error (MSE) relative to bootstrapped target values. Meanwhile, in distributional RL, a distribution of returns is modelled based on the distributional Bellman operator. This work investigates the Gaussian Histogram Loss (HL-Gauss), a recent approach in value-based categorical distributional RL that reframes value estimation as a classification problem by minimising the cross-entropy between a target distribution and a predicted histogram. Despite its potential, applying histogram-based losses to RL presents inherent challenges, most notably the requirement to pre-define a fixed support interval, which is often complicated by the non-stationary and stochastic nature of target values typically found in RL tasks. In this work, we propose an approach that dynamically learns the lower and upper bounds of the support instead of assigning them beforehand. We derive an objective that jointly learns these bounds whilst approximating the categorical return distribution, and we show that this objective forms an upper bound on the mean-squared Bellman error. Our theoretical analysis further shows that this bound is tighter than that of non-learned supports of HL-Gauss. Empirically, the proposed objective enables stable adaptation of the support interval and improves the performance of categorical-critic RL algorithms on continuous control tasks.
Transactions on Pattern Analysis and Machine Intelligence, TPAMI 2026
RAW-Adapter: Adapting Pre-trained Visual Model to Camera RAW Images and A Benchmark
Ziteng Cui, Jianfei Yang, Tatsuya Harada
 In the computer vision community, the preference for pre-training visual models has largely shifted toward sRGB images due to their ease of acquisition and compact storage. However, camera RAW images preserve abundant physical details across diverse real-world scenarios. Despite this, most existing visual perception methods that utilize RAW data directly integrate image signal processing (ISP) stages with subsequent network modules, often overlooking potential synergies at the model level.
Building on recent advances in adapter-based methodologies in both NLP and computer vision, we propose RAW-Adapter, a novel framework that incorporates learnable ISP modules as input-level adapters to adjust RAW inputs. At the same time, it employs model-level adapters to seamlessly bridge ISP processing with high-level downstream architectures. Moreover, RAW-Adapter serves as a general framework applicable to various computer vision frameworks.
In the computer vision community, the preference for pre-training visual models has largely shifted toward sRGB images due to their ease of acquisition and compact storage. However, camera RAW images preserve abundant physical details across diverse real-world scenarios. Despite this, most existing visual perception methods that utilize RAW data directly integrate image signal processing (ISP) stages with subsequent network modules, often overlooking potential synergies at the model level.
Building on recent advances in adapter-based methodologies in both NLP and computer vision, we propose RAW-Adapter, a novel framework that incorporates learnable ISP modules as input-level adapters to adjust RAW inputs. At the same time, it employs model-level adapters to seamlessly bridge ISP processing with high-level downstream architectures. Moreover, RAW-Adapter serves as a general framework applicable to various computer vision frameworks.
Furthermore, we introduce RAW-Bench, which incorporates 17 types of RAW-based common corruptions, including lightness degradations, weather effects, blurriness, camera imaging degradations, and variations in camera color response. Using this benchmark, we systematically compare the performance of RAW-Adapter with state-of-the-art (SOTA) ISP methods and other RAW-based high-level vision algorithms. Additionally, we propose a RAW-based data augmentation strategy to further enhance RAW-Adapter’s performance and improve its out-of-domain (OOD) generalization ability. Extensive experiments substantiate the effectiveness and efficiency of RAW-Adapter, highlighting its robust performance across diverse scenarios.
Transactions on Machine Learning Research, TMLR 2026
Contrastive VQ Priors for Multi-Class Plaque Segmentation via SAM Adaptation
Yizhe Ruan, Yusuke Kurose, Junichi Iho, Yoji Tokunaga, Makoto Horie, Yusaku Hayashi, Keisuke Nishizawa, Yasushi Koyama, Tatsuya Harada
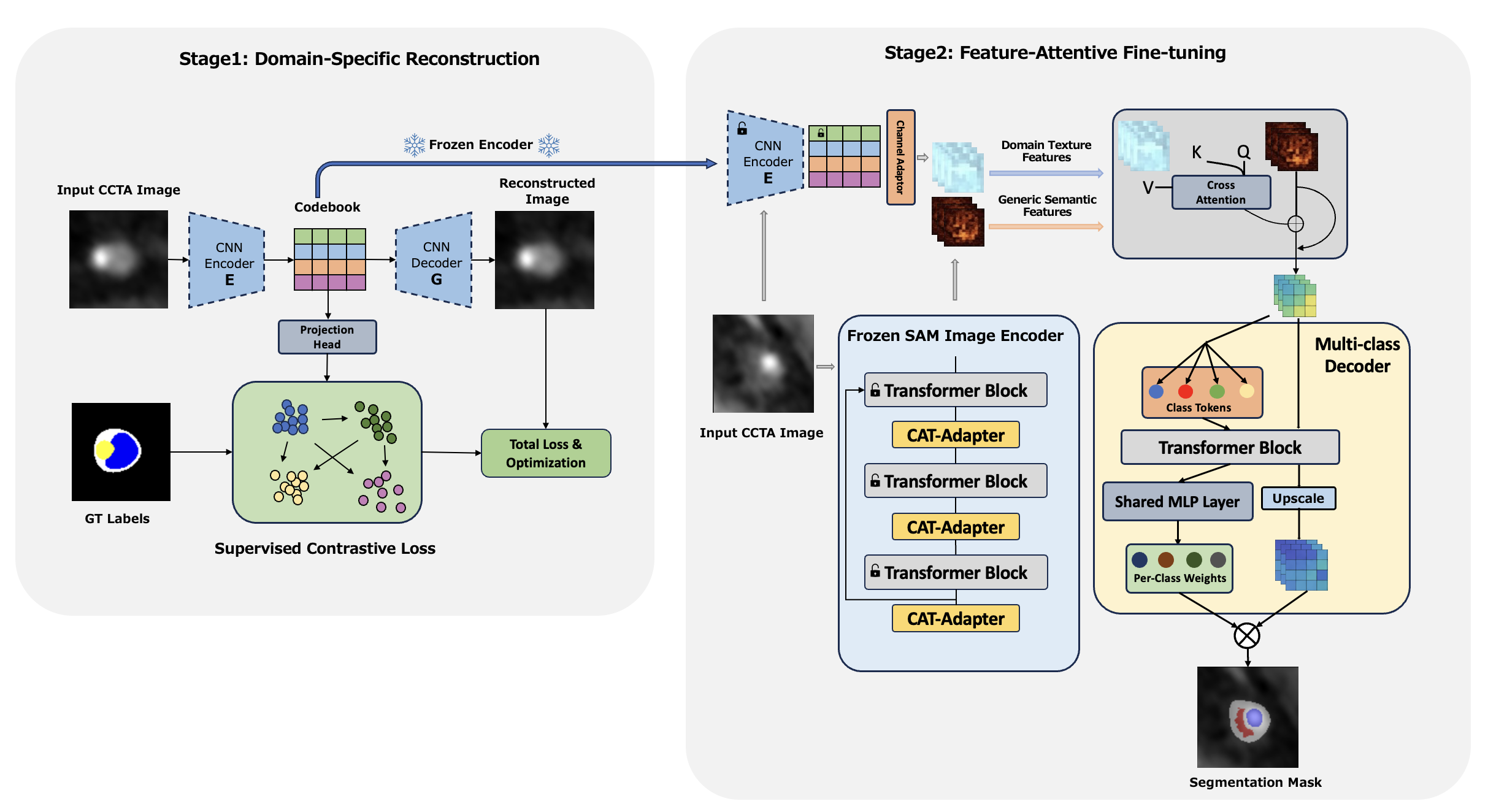 Accurate plaque subtype segmentation in coronary CT angiography (CCTA) is clinically relevant yet remains difficult in practice, where annotations are scarce, and the visual evidence for non-calcified lesions is subtle and highly variable. Meanwhile, segmentation foundation models such as SAM provide strong robustness from large-scale pretraining, but their benefits do not reliably transfer to private CCTA tasks under naïve fine-tuning, especially for multi-class plaque taxonomy. We present a targeted strategy to transfer SAM’s segmentation robustness to a private CCTA setting by injecting a task-specific, texture-aware prior into the SAM feature stream. Our framework is two-stage: (i) we learn a discrete latent prior from the private CCTA data using a vector-quantized autoencoder, and structure it with supervised contrastive learning to emphasize hard class boundaries; (ii) we fuse this prior into a SAM-based encoder through a query-based feature-aware cross-attention module, and decode with a multi-class head/decoder tailored for plaque taxonomy. On this private CCTA cohort, the proposed design improves overall performance over the compared baselines, with the largest gains on vessel wall and non-calcified plaque. Ablations suggest that the class-structured prior, query-based fusion, and multi-class decoding each contribute to the final result within this setting.
Accurate plaque subtype segmentation in coronary CT angiography (CCTA) is clinically relevant yet remains difficult in practice, where annotations are scarce, and the visual evidence for non-calcified lesions is subtle and highly variable. Meanwhile, segmentation foundation models such as SAM provide strong robustness from large-scale pretraining, but their benefits do not reliably transfer to private CCTA tasks under naïve fine-tuning, especially for multi-class plaque taxonomy. We present a targeted strategy to transfer SAM’s segmentation robustness to a private CCTA setting by injecting a task-specific, texture-aware prior into the SAM feature stream. Our framework is two-stage: (i) we learn a discrete latent prior from the private CCTA data using a vector-quantized autoencoder, and structure it with supervised contrastive learning to emphasize hard class boundaries; (ii) we fuse this prior into a SAM-based encoder through a query-based feature-aware cross-attention module, and decode with a multi-class head/decoder tailored for plaque taxonomy. On this private CCTA cohort, the proposed design improves overall performance over the compared baselines, with the largest gains on vessel wall and non-calcified plaque. Ablations suggest that the class-structured prior, query-based fusion, and multi-class decoding each contribute to the final result within this setting.
Language Resources and Evaluation Conference, LREC 2026
DEJIMA: A Novel Large-scale Japanese Dataset for Image Captioning and Visual Question Answering
Toshiki Katsube, Taiga Fukuhara, Kenichiro Ando, Yusuke Mukuta, Kohei Uehara, Tatsuya Harada
 This work addresses the scarcity of high-quality, large-scale resources for Japanese Vision-and-Language (V&L) modeling. We present a scalable and reproducible pipeline that integrates large-scale web collection with rigorous filtering/deduplication, object-detection-driven evidence extraction, and Large Language Model (LLM)-based refinement under grounding constraints. Using this pipeline, we build two resources: an image-caption dataset (DEJIMA-Cap) and a VQA dataset (DEJIMA-VQA), each containing 3.88M image-text pairs, far exceeding the size of existing Japanese V&L datasets. Human evaluations demonstrate that DEJIMA achieves substantially higher Japaneseness and linguistic naturalness than datasets constructed via translation or manual annotation, while maintaining factual correctness at a level comparable to human-annotated corpora. Quantitative analyses of image feature distributions further confirm that DEJIMA broadly covers diverse visual domains characteristic of Japan, complementing its linguistic and cultural representativeness. Models trained on DEJIMA exhibit consistent improvements across multiple Japanese multimodal benchmarks, confirming that culturally grounded, large-scale resources play a key role in enhancing model performance. All data sources and modules in our pipeline are licensed for commercial use, and we publicly release the resulting dataset and metadata to encourage further research and industrial applications in Japanese V&L modeling.
This work addresses the scarcity of high-quality, large-scale resources for Japanese Vision-and-Language (V&L) modeling. We present a scalable and reproducible pipeline that integrates large-scale web collection with rigorous filtering/deduplication, object-detection-driven evidence extraction, and Large Language Model (LLM)-based refinement under grounding constraints. Using this pipeline, we build two resources: an image-caption dataset (DEJIMA-Cap) and a VQA dataset (DEJIMA-VQA), each containing 3.88M image-text pairs, far exceeding the size of existing Japanese V&L datasets. Human evaluations demonstrate that DEJIMA achieves substantially higher Japaneseness and linguistic naturalness than datasets constructed via translation or manual annotation, while maintaining factual correctness at a level comparable to human-annotated corpora. Quantitative analyses of image feature distributions further confirm that DEJIMA broadly covers diverse visual domains characteristic of Japan, complementing its linguistic and cultural representativeness. Models trained on DEJIMA exhibit consistent improvements across multiple Japanese multimodal benchmarks, confirming that culturally grounded, large-scale resources play a key role in enhancing model performance. All data sources and modules in our pipeline are licensed for commercial use, and we publicly release the resulting dataset and metadata to encourage further research and industrial applications in Japanese V&L modeling.
IEEE International Conference on Robotics and Automation, ICRA 2026
Unsupervised Domain Adaptation for Robust Imitation Learning under Visual Perturbations
Yasuhiro Kato, Thomas Westfechtel, Jen-Yen Chang, Naoki Morihira, Akinobu Hayashi, Tatsuya Harada, Takayuki Osa
 Vision-based robot manipulation systems often suffer from performance degradation under domain shifts in visual inputs. While data augmentation is commonly employed in reinforcement learning, its application in imitation learning remains relatively underexplored. Our preliminary experiments indicate that simply incorporating augmentation techniques does not yield effective improvements in imitation learning. To address this challenge, we propose a two-stage learning process. First, we develop an adversarial feature learning framework that leverages data augmentation to enhance robustness against domain shifts. Second, we introduce an unsupervised domain adaptation method that adapts models to target environments using only easily collected image data. In robotic tasks, visual domain shifts can often be detected from initial observations alone. Since collecting complete action-labeled episodes in new domains is expensive, adapting with only initial images greatly reduces data collection costs. To this end, we develop an adaptation strategy that relies solely on initial target-domain observations, eliminating the need for labeled demonstrations.
Experimental results across both simulation and physical robot implementations demonstrate that our method preserves source domain performance while exhibiting enhanced resilience to visual perturbations, including varying lighting conditions, background modifications, and environmental distractors.
Vision-based robot manipulation systems often suffer from performance degradation under domain shifts in visual inputs. While data augmentation is commonly employed in reinforcement learning, its application in imitation learning remains relatively underexplored. Our preliminary experiments indicate that simply incorporating augmentation techniques does not yield effective improvements in imitation learning. To address this challenge, we propose a two-stage learning process. First, we develop an adversarial feature learning framework that leverages data augmentation to enhance robustness against domain shifts. Second, we introduce an unsupervised domain adaptation method that adapts models to target environments using only easily collected image data. In robotic tasks, visual domain shifts can often be detected from initial observations alone. Since collecting complete action-labeled episodes in new domains is expensive, adapting with only initial images greatly reduces data collection costs. To this end, we develop an adaptation strategy that relies solely on initial target-domain observations, eliminating the need for labeled demonstrations.
Experimental results across both simulation and physical robot implementations demonstrate that our method preserves source domain performance while exhibiting enhanced resilience to visual perturbations, including varying lighting conditions, background modifications, and environmental distractors.
The Fourteenth International Conference on Learning Representations, ICLR 2026
R2-Dreamer: Redundancy-Reduced World Models without Decoders or Augmentation
Naoki Morihira, Amal Nahar, Kartik Bharadwaj, Kato Yasuhiro, Akinobu Hayashi, Tatsuya Harada
 A central challenge in image-based Model-Based Reinforcement Learning (MBRL) is to learn representations that distill task-essential information from irrelevant visual details. While promising, reconstruction-based methods often waste capacity on large task-irrelevant regions (e.g., backgrounds). Decoder-free methods instead learn robust representations by leveraging Data Augmentation (DA), but reliance on such external regularizers to prevent collapse limits versatility. We propose R2-Dreamer, a decoder-free MBRL framework with a self-supervised objective that serves as an internal regularizer, preventing collapse without resorting to DA. The core of our method is a feature redundancy reduction objective inspired by Barlow Twins, which can be easily integrated into existing frameworks. On DeepMind Control Suite and Meta-World, R2-Dreamer is competitive with strong baselines such as DreamerV3 and TD-MPC2 while training 1.59 times faster than DreamerV3, and yields substantial gains on DMC-Subtle with tiny task-relevant objects. These results suggest that an effective internal regularizer can enable versatile, high-performance decoder-free MBRL.
A central challenge in image-based Model-Based Reinforcement Learning (MBRL) is to learn representations that distill task-essential information from irrelevant visual details. While promising, reconstruction-based methods often waste capacity on large task-irrelevant regions (e.g., backgrounds). Decoder-free methods instead learn robust representations by leveraging Data Augmentation (DA), but reliance on such external regularizers to prevent collapse limits versatility. We propose R2-Dreamer, a decoder-free MBRL framework with a self-supervised objective that serves as an internal regularizer, preventing collapse without resorting to DA. The core of our method is a feature redundancy reduction objective inspired by Barlow Twins, which can be easily integrated into existing frameworks. On DeepMind Control Suite and Meta-World, R2-Dreamer is competitive with strong baselines such as DreamerV3 and TD-MPC2 while training 1.59 times faster than DreamerV3, and yields substantial gains on DMC-Subtle with tiny task-relevant objects. These results suggest that an effective internal regularizer can enable versatile, high-performance decoder-free MBRL.
Rethinking Policy Diversity in Ensemble Policy Gradient in Large-Scale Reinforcement Learning
Naoki Shitanda, Motoki Omura, Tatsuya Harada, Takayuki Osa
 Scaling reinforcement learning to tens of thousands of parallel environments requires overcoming the limited exploration capacity of a single policy. Ensemble-based policy gradient methods, which employ multiple policies to collect diverse samples, have recently been proposed to promote exploration. However, merely broadening the exploration space does not always enhance learning capability, since excessive exploration can reduce exploration quality or compromise training stability. In this work, we theoretically analyze the impact of inter-policy diversity on learning efficiency in policy ensembles, and propose Coupled Policy Optimization (CPO), which regulates diversity through KL constraints between policies. The proposed method enables effective exploration and outperforms strong baselines such as SAPG, PBT, and PPO across multiple dexterous manipulation tasks in both sample efficiency and final performance. Furthermore, analysis of policy diversity and effective sample size during training reveals that follower policies naturally distribute around the leader, demonstrating the emergence of structured and efficient exploratory behavior. Our results indicate that diverse exploration under appropriate regulation is key to achieving stable and sample-efficient learning in ensemble policy gradient methods.
Scaling reinforcement learning to tens of thousands of parallel environments requires overcoming the limited exploration capacity of a single policy. Ensemble-based policy gradient methods, which employ multiple policies to collect diverse samples, have recently been proposed to promote exploration. However, merely broadening the exploration space does not always enhance learning capability, since excessive exploration can reduce exploration quality or compromise training stability. In this work, we theoretically analyze the impact of inter-policy diversity on learning efficiency in policy ensembles, and propose Coupled Policy Optimization (CPO), which regulates diversity through KL constraints between policies. The proposed method enables effective exploration and outperforms strong baselines such as SAPG, PBT, and PPO across multiple dexterous manipulation tasks in both sample efficiency and final performance. Furthermore, analysis of policy diversity and effective sample size during training reveals that follower policies naturally distribute around the leader, demonstrating the emergence of structured and efficient exploratory behavior. Our results indicate that diverse exploration under appropriate regulation is key to achieving stable and sample-efficient learning in ensemble policy gradient methods.
Cross-Embodiment Offline Reinforcement Learning for Heterogeneous Robot Datasets
Haruki Abe, Takayuki Osa, Yusuke Mukuta, Tatsuya Harada
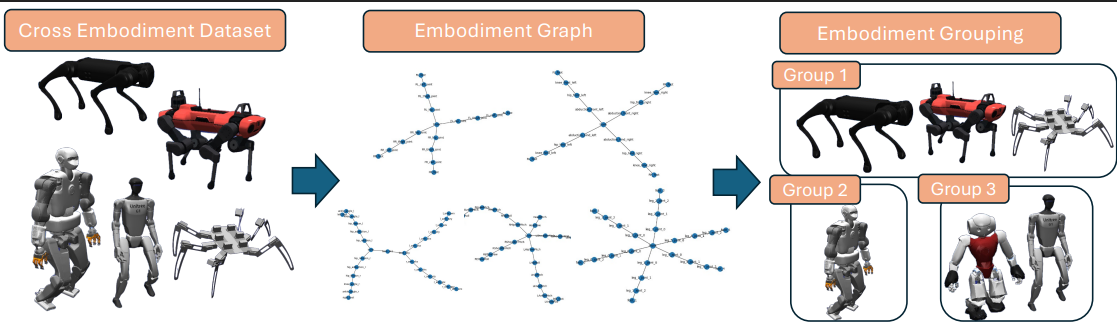 Scalable robot policy pre-training has been hindered by the high cost of collecting high-quality demonstrations for each platform. In this study, we address this issue by uniting offline reinforcement learning (offline RL) with cross-embodiment learning. Offline RL leverages both expert and abundant suboptimal data, and cross-embodiment learning aggregates heterogeneous robot trajectories across diverse morphologies to acquire universal control priors. We perform a systematic analysis of this offline RL and cross-embodiment paradigm, providing a principled understanding of its strengths and limitations. To evaluate this offline RL and cross-embodiment paradigm, we construct a suite of locomotion datasets spanning 16 distinct robot platforms. Our experiments confirm that this combined approach excels at pre-training with datasets rich in suboptimal trajectories, outperforming pure behavior cloning. However, as the proportion of suboptimal data and the number of robot types increase, we observe that conflicting gradients across morphologies begin to impede learning. To mitigate this, we introduce an embodiment-based grouping strategy in which robots are clustered by morphological similarity and the model is updated with a group gradient. This simple, static grouping substantially reduces inter-robot conflicts and outperforms existing conflict-resolution methods.
Scalable robot policy pre-training has been hindered by the high cost of collecting high-quality demonstrations for each platform. In this study, we address this issue by uniting offline reinforcement learning (offline RL) with cross-embodiment learning. Offline RL leverages both expert and abundant suboptimal data, and cross-embodiment learning aggregates heterogeneous robot trajectories across diverse morphologies to acquire universal control priors. We perform a systematic analysis of this offline RL and cross-embodiment paradigm, providing a principled understanding of its strengths and limitations. To evaluate this offline RL and cross-embodiment paradigm, we construct a suite of locomotion datasets spanning 16 distinct robot platforms. Our experiments confirm that this combined approach excels at pre-training with datasets rich in suboptimal trajectories, outperforming pure behavior cloning. However, as the proportion of suboptimal data and the number of robot types increase, we observe that conflicting gradients across morphologies begin to impede learning. To mitigate this, we introduce an embodiment-based grouping strategy in which robots are clustered by morphological similarity and the model is updated with a group gradient. This simple, static grouping substantially reduces inter-robot conflicts and outperforms existing conflict-resolution methods.
WACV 2026
Semi-supervised Domain Adaptation via Mutual Alignment through Joint Error.
Dexuan Zhang, Thomas Westfechtel, Tatsuya Harada
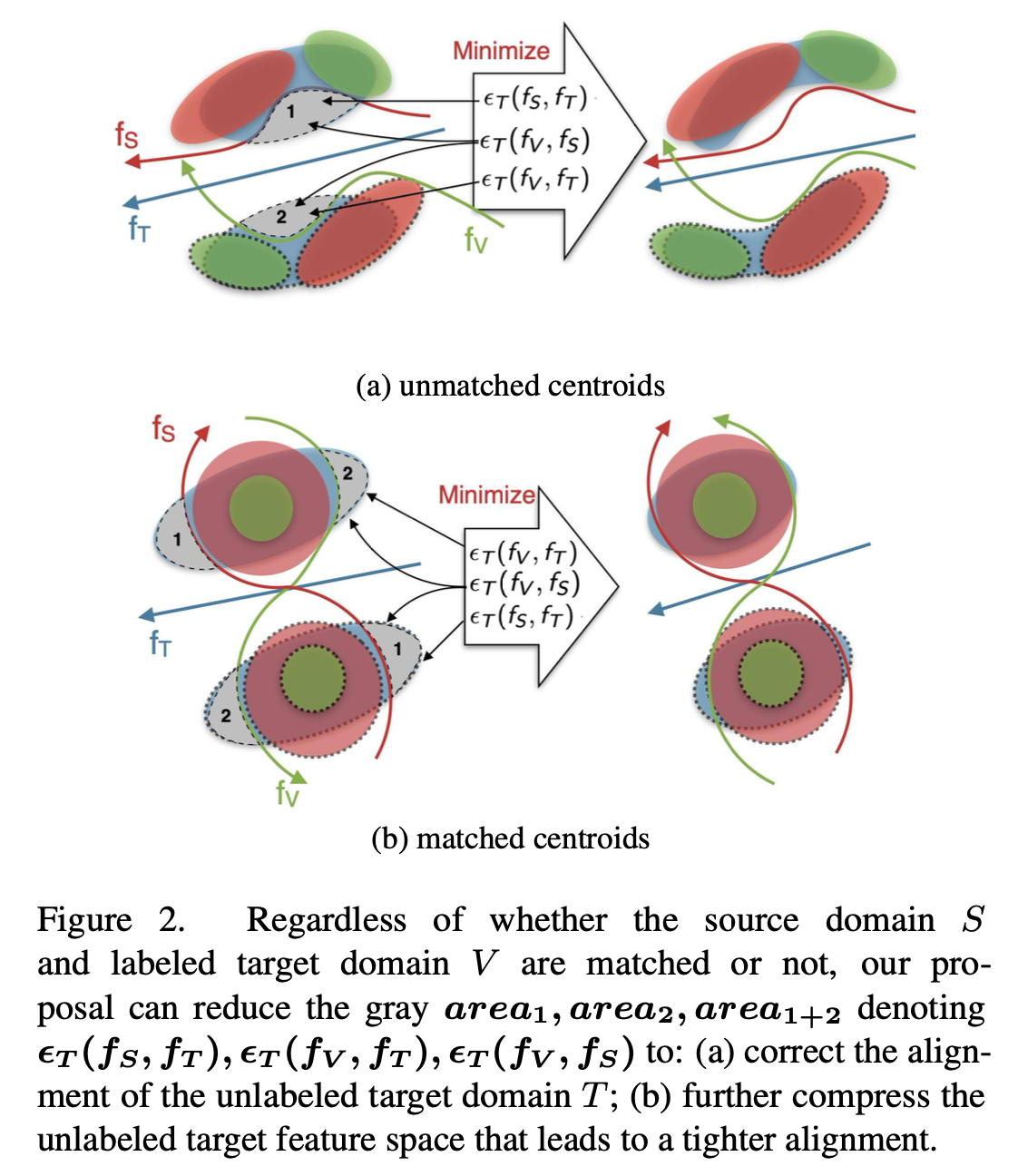 Most existing methods for unsupervised domain adaptation focus on learning domain-invariant representations. However, recent works have shown that the generalization on the target domain can fail due to the trade-off between marginal distribution alignment and joint error under a large domain shift. A few labeled target data points can enhance adaptation quality, but the distribution shift between labeled and unlabeled target data is often overlooked. Therefore, we propose a novel learning theory to address the joint error in semi-supervised domain adaptation that can reduce the mutual distribution shift between pairs from labeled and unlabeled domains. Furthermore, we introduce a discrepancy measurement between hypotheses to tackle the inconsistency of the loss functions in the algorithm and theory. Extensive experiments demonstrate that our method consistently outperforms baseline approaches, particularly in scenarios with large domain shifts and scarce labeled target data.
Most existing methods for unsupervised domain adaptation focus on learning domain-invariant representations. However, recent works have shown that the generalization on the target domain can fail due to the trade-off between marginal distribution alignment and joint error under a large domain shift. A few labeled target data points can enhance adaptation quality, but the distribution shift between labeled and unlabeled target data is often overlooked. Therefore, we propose a novel learning theory to address the joint error in semi-supervised domain adaptation that can reduce the mutual distribution shift between pairs from labeled and unlabeled domains. Furthermore, we introduce a discrepancy measurement between hypotheses to tackle the inconsistency of the loss functions in the algorithm and theory. Extensive experiments demonstrate that our method consistently outperforms baseline approaches, particularly in scenarios with large domain shifts and scarce labeled target data.
SceneProp: Combining Neural Network and Markov Random Field for Scene-Graph Grounding.
Keita Otani, Tatsuya Harada
 Grounding complex, compositional visual queries with multiple objects and relationships is a fundamental challenge for vision-language models. While standard phrase grounding methods excel at localizing single objects, they lack the structural inductive bias to parse intricate relational descriptions, often failing as queries become more descriptive. To address this structural deficit, we focus on scene-graph grounding, a powerful but less-explored formulation where the query is an explicit graph of objects and their relationships. However, existing methods for this task also struggle, paradoxically showing decreased performance as the query graph grows---failing to leverage the very information that should make grounding easier. We introduce SceneProp, a novel method that resolves this issue by reformulating scene-graph grounding as a Maximum a Posteriori (MAP) inference problem in a Markov Random Field (MRF). By performing global inference over the entire query graph, SceneProp finds the optimal assignment of image regions to nodes that jointly satisfies all constraints. This is achieved within an end-to-end framework via a differentiable implementation of the Belief Propagation algorithm. Experiments on four benchmarks show that our dedicated focus on the scene-graph grounding formulation allows SceneProp to significantly outperform prior work. Critically, its accuracy consistently improves with the size and complexity of the query graph, demonstrating for the first time that more relational context can, and should, lead to better grounding.
Grounding complex, compositional visual queries with multiple objects and relationships is a fundamental challenge for vision-language models. While standard phrase grounding methods excel at localizing single objects, they lack the structural inductive bias to parse intricate relational descriptions, often failing as queries become more descriptive. To address this structural deficit, we focus on scene-graph grounding, a powerful but less-explored formulation where the query is an explicit graph of objects and their relationships. However, existing methods for this task also struggle, paradoxically showing decreased performance as the query graph grows---failing to leverage the very information that should make grounding easier. We introduce SceneProp, a novel method that resolves this issue by reformulating scene-graph grounding as a Maximum a Posteriori (MAP) inference problem in a Markov Random Field (MRF). By performing global inference over the entire query graph, SceneProp finds the optimal assignment of image regions to nodes that jointly satisfies all constraints. This is achieved within an end-to-end framework via a differentiable implementation of the Belief Propagation algorithm. Experiments on four benchmarks show that our dedicated focus on the scene-graph grounding formulation allows SceneProp to significantly outperform prior work. Critically, its accuracy consistently improves with the size and complexity of the query graph, demonstrating for the first time that more relational context can, and should, lead to better grounding.