Abstracts of papers published in 2025
NeurIPS 2025
Intend to Move: A Multimodal Dataset for Intention-Aware Human Motion Understanding.
Ryo Umagami, Liu Yue, Xuangeng Chu, Ryuto Fukushima, Tetsuya Narita, Yusuke Mukuta, Tomoyuki Takahata, Jianfei Yang, Tatsuya Harada
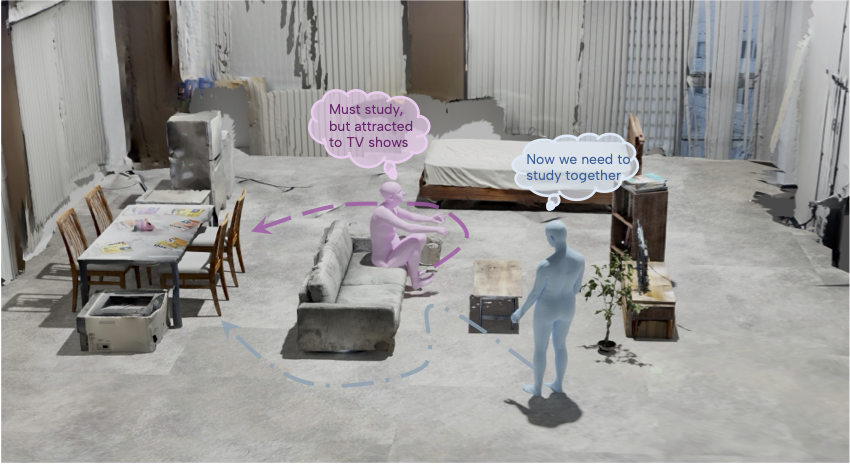 Human motion is inherently intentional, yet most motion modeling paradigms focus on low-level kinematics, overlooking the semantic and causal factors that drive behavior. Existing datasets further limit progress: they capture short, decontextualized actions in static scenes, providing little grounding for embodied reasoning. To address these limitations, we introduce Intend to Move (I2M), a large-scale, multimodal dataset for intention-grounded motion modeling. I2M contains 10.1 hours of two-person 3D motion sequences recorded in dynamic realistic home environments, accompanied by multi-view RGB-D video, 3D scene geometry, and language annotations of each participant’s evolving intentions. Benchmark experiments reveal a fundamental gap in current motion models: they fail to translate high-level goals into physically and socially coherent motion. I2M thus serves not only as a dataset but as a benchmark for embodied intelligence, enabling research on models that can reason about, predict, and act upon the “why” behind human motion.
Human motion is inherently intentional, yet most motion modeling paradigms focus on low-level kinematics, overlooking the semantic and causal factors that drive behavior. Existing datasets further limit progress: they capture short, decontextualized actions in static scenes, providing little grounding for embodied reasoning. To address these limitations, we introduce Intend to Move (I2M), a large-scale, multimodal dataset for intention-grounded motion modeling. I2M contains 10.1 hours of two-person 3D motion sequences recorded in dynamic realistic home environments, accompanied by multi-view RGB-D video, 3D scene geometry, and language annotations of each participant’s evolving intentions. Benchmark experiments reveal a fundamental gap in current motion models: they fail to translate high-level goals into physically and socially coherent motion. I2M thus serves not only as a dataset but as a benchmark for embodied intelligence, enabling research on models that can reason about, predict, and act upon the “why” behind human motion.
Dr. RAW: Towards General High-Level Vision from RAW with Efficient Task Conditioning.
Wenjun Huang*, Ziteng Cui* (*: co-first author), Yinqiang Zheng, Yirui He, Tatsuya Harada, Mohsen Imani
 We introduce Dr.RAW, a unified and tuning-efficient framework for high-level computer vision tasks directly operating on camera RAW data. Unlike previous approaches that optimize image signal processing (ISP) pipelines and fully fine-tune networks for each task, Dr.RAW achieves state-of-the-art performance with minimal parameter updates and frozen backbone weights. At the input stage, we apply lightweight pre-processing steps, including sensor and illumination mapping, along with re-mosaicing, to mitigate data inconsistencies stemming from sensor variations and lighting conditions. At the network level, we introduce task-specific adaptation through two modules: Sensor Prior Prompts (SPP) and task-specific Low-Rank Adaptation (LoRA). SPP injects sensor-aware conditioning into the network via learnable prompts derived from RAW pixel distribution priors, while LoRA enables efficient task-specific tuning by updating only low-rank matrices in key backbone layers. Despite minimal tuning, \mname delivers superior results across four RAW-based tasks (object detection, semantic segmentation, instance segmentation, and pose estimation) on nine datasets encompassing various light conditions. By harnessing the intrinsic physical cues of RAW alongside parameter-efficient techniques, \mname advances RAW-based vision systems, achieving both high accuracy and computational economy. We will release our source code.
We introduce Dr.RAW, a unified and tuning-efficient framework for high-level computer vision tasks directly operating on camera RAW data. Unlike previous approaches that optimize image signal processing (ISP) pipelines and fully fine-tune networks for each task, Dr.RAW achieves state-of-the-art performance with minimal parameter updates and frozen backbone weights. At the input stage, we apply lightweight pre-processing steps, including sensor and illumination mapping, along with re-mosaicing, to mitigate data inconsistencies stemming from sensor variations and lighting conditions. At the network level, we introduce task-specific adaptation through two modules: Sensor Prior Prompts (SPP) and task-specific Low-Rank Adaptation (LoRA). SPP injects sensor-aware conditioning into the network via learnable prompts derived from RAW pixel distribution priors, while LoRA enables efficient task-specific tuning by updating only low-rank matrices in key backbone layers. Despite minimal tuning, \mname delivers superior results across four RAW-based tasks (object detection, semantic segmentation, instance segmentation, and pose estimation) on nine datasets encompassing various light conditions. By harnessing the intrinsic physical cues of RAW alongside parameter-efficient techniques, \mname advances RAW-based vision systems, achieving both high accuracy and computational economy. We will release our source code.
SIGGRAPH Asia 2025
ARTalk: Speech-Driven 3D Head Animation via Autoregressive Model
Xuangeng Chu, Nabarun Goswami, Ziteng Cui, Hanqin Wang, Tatsuya Harada
 Speech-driven 3D facial animation aims to generate realistic lip movements and facial expressions for 3D head models from audio clips. Although existing diffusion-based methods are capable of producing natural motions, their slow generation speed limits their application potential. In this paper, we introduce a novel autoregressive model that achieves real-time generation of highly synchronized lip movements and realistic head poses and eye blinks by learning a mapping from speech to a multi-scale motion codebook. Furthermore, our model can adapt to unseen speaking styles using sample motion sequences, enabling the creation of 3D talking avatars with unique personal styles beyond the identities seen during training. Extensive evaluations and user studies demonstrate that our method outperforms existing approaches in lip synchronization and perceived quality.
Speech-driven 3D facial animation aims to generate realistic lip movements and facial expressions for 3D head models from audio clips. Although existing diffusion-based methods are capable of producing natural motions, their slow generation speed limits their application potential. In this paper, we introduce a novel autoregressive model that achieves real-time generation of highly synchronized lip movements and realistic head poses and eye blinks by learning a mapping from speech to a multi-scale motion codebook. Furthermore, our model can adapt to unseen speaking styles using sample motion sequences, enabling the creation of 3D talking avatars with unique personal styles beyond the identities seen during training. Extensive evaluations and user studies demonstrate that our method outperforms existing approaches in lip synchronization and perceived quality.
Pacific Graphics 2025
Improved 3D Scene Stylization via Text-Guided Generative Image Editing with Region-Based Control
Haruo Fujiwara, Yusuke Mukuta, Tatsuya Harada
 Recent advances in text-driven 3D scene editing and stylization, which leverage the powerful capabilities of 2D generative models, have demonstrated promising outcomes. However, challenges remain in ensuring high-quality stylization and view consistency simultaneously. Moreover, applying style consistently to different regions or objects in the scene with semantic correspondence is a challenging task. To address these limitations, we introduce techniques that enhance the quality of 3D stylization while maintaining view consistency and providing optional region-controlled style transfer. Our method achieves stylization by re-training an initial 3D representation using stylized multi-view 2D images of the source views. Therefore, ensuring both style consistency and view consistency of stylized multi-view images is crucial. We achieve this by extending the style-aligned depth-conditioned view generation framework, replacing the fully shared attention mechanism with a single reference-based attention-sharing mechanism, which effectively aligns style across different viewpoints. Additionally, inspired by recent 3D inpainting methods, we utilize a grid of multiple depth maps as a single-image reference to further strengthen view consistency among stylized images. Finally, we propose Multi-Region Importance-Weighted Sliced Wasserstein Distance Loss, allowing styles to be applied to distinct image regions using segmentation masks from off-the-shelf models. We demonstrate that this optional feature enhances the faithfulness of style transfer and enables the mixing of different styles across distinct regions of the scene. Experimental evaluations, both qualitative and quantitative, demonstrate that our pipeline effectively improves the results of text-driven 3D stylization.
Recent advances in text-driven 3D scene editing and stylization, which leverage the powerful capabilities of 2D generative models, have demonstrated promising outcomes. However, challenges remain in ensuring high-quality stylization and view consistency simultaneously. Moreover, applying style consistently to different regions or objects in the scene with semantic correspondence is a challenging task. To address these limitations, we introduce techniques that enhance the quality of 3D stylization while maintaining view consistency and providing optional region-controlled style transfer. Our method achieves stylization by re-training an initial 3D representation using stylized multi-view 2D images of the source views. Therefore, ensuring both style consistency and view consistency of stylized multi-view images is crucial. We achieve this by extending the style-aligned depth-conditioned view generation framework, replacing the fully shared attention mechanism with a single reference-based attention-sharing mechanism, which effectively aligns style across different viewpoints. Additionally, inspired by recent 3D inpainting methods, we utilize a grid of multiple depth maps as a single-image reference to further strengthen view consistency among stylized images. Finally, we propose Multi-Region Importance-Weighted Sliced Wasserstein Distance Loss, allowing styles to be applied to distinct image regions using segmentation masks from off-the-shelf models. We demonstrate that this optional feature enhances the faithfulness of style transfer and enables the mixing of different styles across distinct regions of the scene. Experimental evaluations, both qualitative and quantitative, demonstrate that our pipeline effectively improves the results of text-driven 3D stylization.
24th International Conference on Humanoid Robots (Humanoids 2025)
Few-shot Imitation Learning by Variable-length Trajectory Retrieval from a Large and Diverse Dataset
Tomoyuki Araki, Yusuke Mukuta, Takayuki Osa, Tatsuya Harada
 Imitation learning offers an effective framework for enabling robots to acquire complex skills, but typically requires a large number of labeled demonstrations, making data collection costly. In contrast, large-scale unlabeled datasets containing diverse trajectories can be obtained more easily, motivating methods that leverage such data to enable learning from few demonstrations. A promising approach along this direction is to retrieve trajectories similar to demonstrations from unlabeled datasets. However, existing retrieval-based methods often rely on frame-level comparisons or fixed-length trajectory embeddings, limiting their ability to capture the temporal structure of behaviors and to generalize across different execution speeds.
To address these limitations, this paper proposes a method that embeds variable-length trajectories using Self-Attention to capture sequence information and robustly retrieve semantically similar behaviors. Using a small number of demonstrations, relevant trajectories are extracted from unlabeled datasets and used alongside demonstrations to train the agent, thereby reducing data collection costs.
Experiments on large-scale, diverse datasets demonstrate that the proposed method achieves higher retrieval accuracy and task success rates than existing retrieval-based imitation learning methods under realistic conditions.
Imitation learning offers an effective framework for enabling robots to acquire complex skills, but typically requires a large number of labeled demonstrations, making data collection costly. In contrast, large-scale unlabeled datasets containing diverse trajectories can be obtained more easily, motivating methods that leverage such data to enable learning from few demonstrations. A promising approach along this direction is to retrieve trajectories similar to demonstrations from unlabeled datasets. However, existing retrieval-based methods often rely on frame-level comparisons or fixed-length trajectory embeddings, limiting their ability to capture the temporal structure of behaviors and to generalize across different execution speeds.
To address these limitations, this paper proposes a method that embeds variable-length trajectories using Self-Attention to capture sequence information and robustly retrieve semantically similar behaviors. Using a small number of demonstrations, relevant trajectories are extracted from unlabeled datasets and used alongside demonstrations to train the agent, thereby reducing data collection costs.
Experiments on large-scale, diverse datasets demonstrate that the proposed method achieves higher retrieval accuracy and task success rates than existing retrieval-based imitation learning methods under realistic conditions.
第28回 画像の認識・理解シンポジウム (MIRU2025), 口頭発表論文, 査読付き
高品質な日本語マルチモーダルデータセットのスケーラブルな構築手法に関する研究
Toshiki katsube, Taiga Fukuhara, Kohei Uehara, Kenichiro Ando, Yusuke Mukuta, Tatsuya harada
 近年,機械学習技術の進歩により視覚情報と言語情報を統合して処理するVision & Language(V&L)モデルの発展がめざましいです。V&Lモデルの学習のためには,テキストとデータがペアになったV&Lデータセットが必要であるが,日本語など英語以外の言語のデータセットは量的にも質的にも不足しています.
本研究では,日本特有の知識や文化を反映した,高品質な画像キャプションデータセットをスケーラブルに構築する手法を提案しました.提案手法は,画像とaltテキストのダウンロード,画像に含まれる物体の検出,LLMによるaltテキストの整形の三段階に分かれます.LLMによってテキストを整形することにより,従来の自動で構築されたデータセットよりも高品質なデータセット構築を可能にしました.構築したデータセットを用いてV&Lモデルを学習し,V&Lモデルの日本語性能の向上に寄与することを確認しました.
近年,機械学習技術の進歩により視覚情報と言語情報を統合して処理するVision & Language(V&L)モデルの発展がめざましいです。V&Lモデルの学習のためには,テキストとデータがペアになったV&Lデータセットが必要であるが,日本語など英語以外の言語のデータセットは量的にも質的にも不足しています.
本研究では,日本特有の知識や文化を反映した,高品質な画像キャプションデータセットをスケーラブルに構築する手法を提案しました.提案手法は,画像とaltテキストのダウンロード,画像に含まれる物体の検出,LLMによるaltテキストの整形の三段階に分かれます.LLMによってテキストを整形することにより,従来の自動で構築されたデータセットよりも高品質なデータセット構築を可能にしました.構築したデータセットを用いてV&Lモデルを学習し,V&Lモデルの日本語性能の向上に寄与することを確認しました.
Interspeech 2025
FUSE: Universal Speech Enhancement using Multi-Stage Fusion of Sparse
Compression and Token Generation Models for the URGENT 2025 Challenge
Nabarun Goswami, Tatsuya Harada
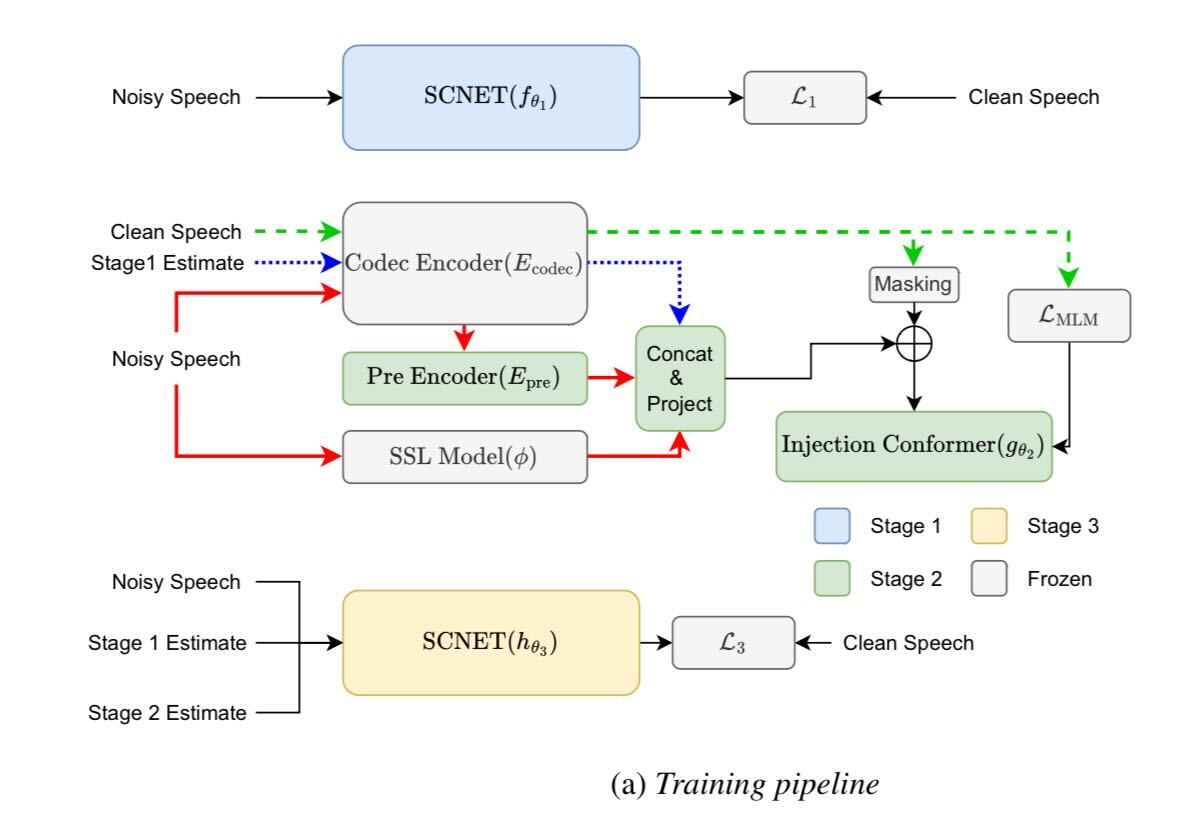 We propose a multi-stage framework for universal speech enhancement, designed for the Interspeech 2025 URGENT Challenge. Our system first employs a Sparse Compression Network to robustly separate sources and extract an initial clean speech estimate from noisy inputs. This is followed by an efficient mask-predict generative model that refines speech quality by leveraging self-supervised features and optimizing a masked language modeling objective on acoustic tokens derived from a neural audio codec. In the final stage, a fusion network integrates the outputs of the first two stages with the original noisy signal, achieving a balanced improvement in both signal fidelity and perceptual quality. Additionally, a shift trick that aggregates multiple time-shifted predictions, along with output blending, further boosts performance. Experimental results on challenging multilingual datasets with variable sampling rates and diverse distortion types validate the effectiveness of our approach.
We propose a multi-stage framework for universal speech enhancement, designed for the Interspeech 2025 URGENT Challenge. Our system first employs a Sparse Compression Network to robustly separate sources and extract an initial clean speech estimate from noisy inputs. This is followed by an efficient mask-predict generative model that refines speech quality by leveraging self-supervised features and optimizing a masked language modeling objective on acoustic tokens derived from a neural audio codec. In the final stage, a fusion network integrates the outputs of the first two stages with the original noisy signal, achieving a balanced improvement in both signal fidelity and perceptual quality. Additionally, a shift trick that aggregates multiple time-shifted predictions, along with output blending, further boosts performance. Experimental results on challenging multilingual datasets with variable sampling rates and diverse distortion types validate the effectiveness of our approach.
Transactions on Machine Learning Research (TMLR), 2025
Enhancing Plaque Segmentation in CCTA with Prompt- based Diffusion Data Augmentation
Yizhe Ruan, Xuangeng Chu, Ziteng Cui, Yusuke Kurose, Junichi Iho, Yoji Tokunaga, Makoto Horie, Yusaku Hayashi, Keisuke Nishizawa, Yasushi Koyama, Tatsuya Harada
 Coronary computed tomography angiography (CCTA) is essential for non-invasive assessment of coronary artery disease (CAD). However, accurate segmentation of atherosclerotic plaques remains challenging due to data scarcity, severe class imbalance, and significant variability between calcified and non-calcified plaques. Inspired by DiffTumor’s tumor synthesis and PromptIR’s adaptive restoration framework, we introduce PromptLesion, a prompt-conditioned diffusion model for multi-class lesion synthesis. Unlike single-class methods, our approach integrates lesion-specific prompts within the diffusion generation process, enhancing diversity and anatomical realism in synthetic data. We validate PromptLesion on a private CCTA dataset and multi-organ tumor segmentation tasks (kidney, liver, pancreas) using public datasets, achieving superior performance compared to baseline methods. Models trained with our prompt-guided synthetic augmentation significantly improve Dice Similarity Coefficient (DSC) scores for both plaque and tumor segmentation. Extensive evaluations and ablation studies confirm the effectiveness of prompt conditioning.
Coronary computed tomography angiography (CCTA) is essential for non-invasive assessment of coronary artery disease (CAD). However, accurate segmentation of atherosclerotic plaques remains challenging due to data scarcity, severe class imbalance, and significant variability between calcified and non-calcified plaques. Inspired by DiffTumor’s tumor synthesis and PromptIR’s adaptive restoration framework, we introduce PromptLesion, a prompt-conditioned diffusion model for multi-class lesion synthesis. Unlike single-class methods, our approach integrates lesion-specific prompts within the diffusion generation process, enhancing diversity and anatomical realism in synthetic data. We validate PromptLesion on a private CCTA dataset and multi-organ tumor segmentation tasks (kidney, liver, pancreas) using public datasets, achieving superior performance compared to baseline methods. Models trained with our prompt-guided synthetic augmentation significantly improve Dice Similarity Coefficient (DSC) scores for both plaque and tumor segmentation. Extensive evaluations and ablation studies confirm the effectiveness of prompt conditioning.
HyperVQ: MLR-based Vector Quantization in Hyperbolic Space
Nabarun Goswami, Yusuke Mukuta, Tatsuya Harada
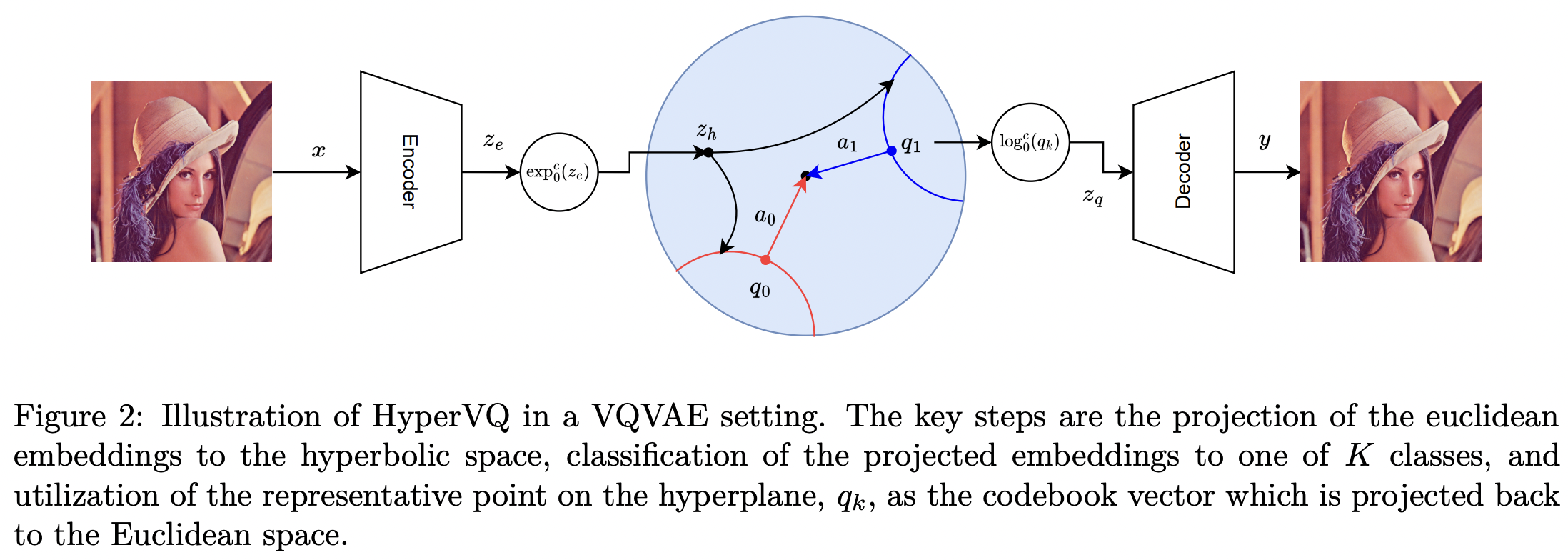 The success of models operating on tokenized data has heightened the need for effective tokenization methods, particularly in vision and auditory tasks where inputs are naturally continuous. A common solution is to employ Vector Quantization (VQ) within VQ Variational Autoencoders (VQVAEs), transforming inputs into discrete tokens by clustering embeddings in Euclidean space. However, Euclidean embeddings not only suffer from inefficient packing and limited separation—due to their polynomial volume growth—but are also prone to codebook collapse, where only a small subset of codebook vectors are effectively utilized. To address these limitations, we introduce HyperVQ, a novel approach that formulates VQ as a hyperbolic Multinomial Logistic Regression (MLR) problem, leveraging the exponential volume growth in hyperbolic space to mitigate collapse and improve cluster separability. Additionally, HyperVQ represents codebook vectors as geometric representatives of hyperbolic decision hyperplanes, encouraging disentangled and robust latent representations. Our experiments demonstrate that HyperVQ matches traditional VQ in generative and reconstruction tasks, while surpassing it in discriminative performance and yielding a more efficient and disentangled codebook.
The success of models operating on tokenized data has heightened the need for effective tokenization methods, particularly in vision and auditory tasks where inputs are naturally continuous. A common solution is to employ Vector Quantization (VQ) within VQ Variational Autoencoders (VQVAEs), transforming inputs into discrete tokens by clustering embeddings in Euclidean space. However, Euclidean embeddings not only suffer from inefficient packing and limited separation—due to their polynomial volume growth—but are also prone to codebook collapse, where only a small subset of codebook vectors are effectively utilized. To address these limitations, we introduce HyperVQ, a novel approach that formulates VQ as a hyperbolic Multinomial Logistic Regression (MLR) problem, leveraging the exponential volume growth in hyperbolic space to mitigate collapse and improve cluster separability. Additionally, HyperVQ represents codebook vectors as geometric representatives of hyperbolic decision hyperplanes, encouraging disentangled and robust latent representations. Our experiments demonstrate that HyperVQ matches traditional VQ in generative and reconstruction tasks, while surpassing it in discriminative performance and yielding a more efficient and disentangled codebook.
EDM-TTS: Efficient Dual-Stage Masked Modeling for Alignment-Free Text-to-Speech Synthesis
Nabarun Goswami, Hanqin Wang, Tatsuya Harada
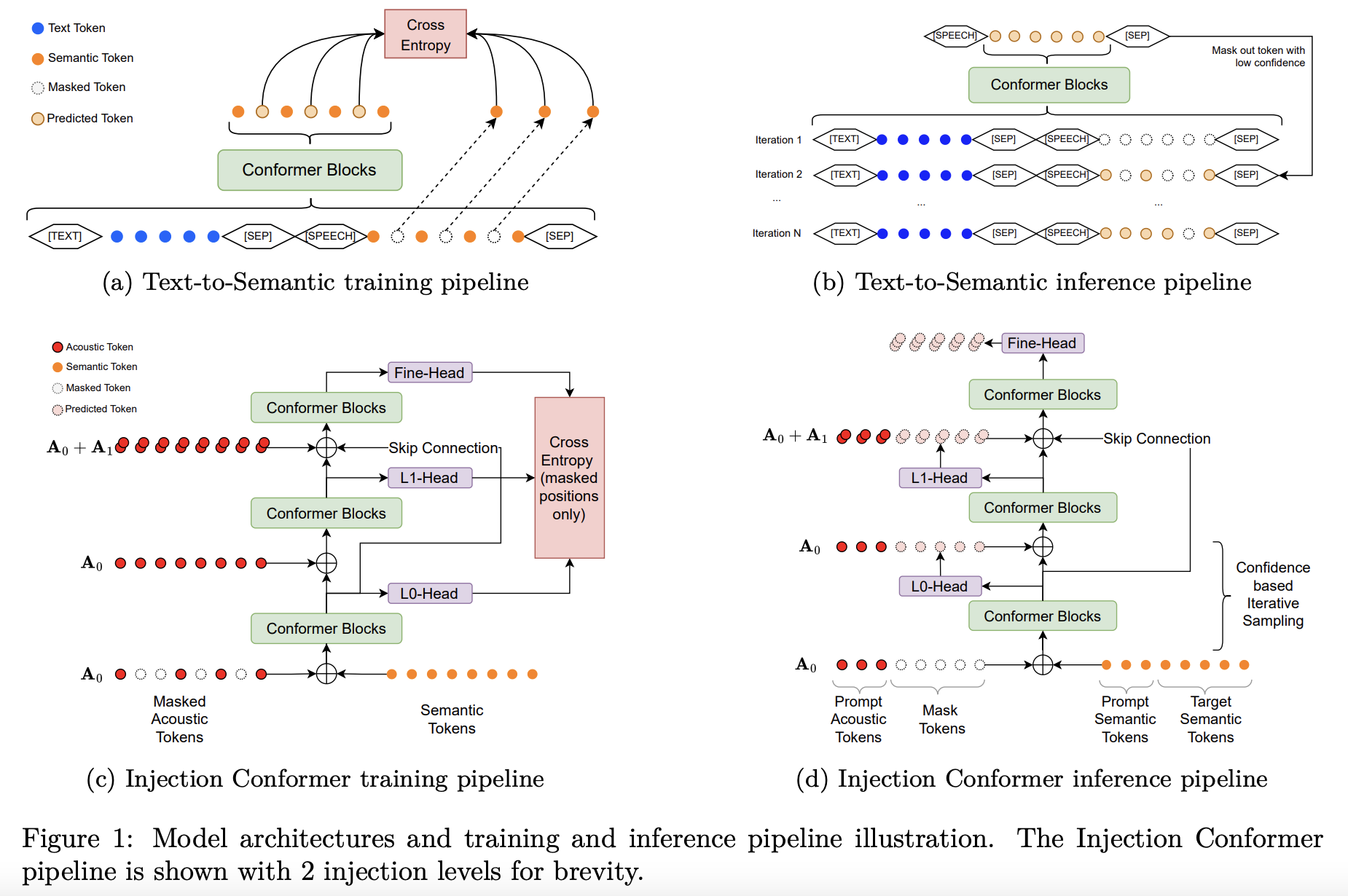 Tokenized speech modeling has significantly advanced zero-shot text-to-speech (TTS) capabilities. The most de facto approach involves a dual-stage process: text-to-semantic (T2S) followed by semantic-to-acoustic (S2A) generation. Several auto-regressive (AR) and non-autoregressive (NAR) methods have been explored in literature for both the stages. While AR models achieve state-of-the-art performance, its token-by-token generation causes inference inefficiencies, while NAR methods while being more efficient, require explicit alignment for upsampling intermediate representations, which constrains the model's capability for more natural prosody. To overcome these issues, we propose an Efficient Dual-stage Masked TTS (EDM-TTS) model that employs an alignment-free masked generative approach for the T2S stage that overcomes the constrains of an explicit aligner, while retaining the efficiency of NAR methods. For the S2A stage, we introduce an innovative NAR approach using a novel Injection Conformer architecture, that effectively models the conditional dependence among different acoustic quantization levels, optimized by a masked language modeling objective, enabling zero-shot speech generation. Our evaluations demonstrated not only the superior inference efficiency of EDM-TTS, but also its state-of-the-art high-quality zero-shot speech quality, naturalness and speaker similarity.
Tokenized speech modeling has significantly advanced zero-shot text-to-speech (TTS) capabilities. The most de facto approach involves a dual-stage process: text-to-semantic (T2S) followed by semantic-to-acoustic (S2A) generation. Several auto-regressive (AR) and non-autoregressive (NAR) methods have been explored in literature for both the stages. While AR models achieve state-of-the-art performance, its token-by-token generation causes inference inefficiencies, while NAR methods while being more efficient, require explicit alignment for upsampling intermediate representations, which constrains the model's capability for more natural prosody. To overcome these issues, we propose an Efficient Dual-stage Masked TTS (EDM-TTS) model that employs an alignment-free masked generative approach for the T2S stage that overcomes the constrains of an explicit aligner, while retaining the efficiency of NAR methods. For the S2A stage, we introduce an innovative NAR approach using a novel Injection Conformer architecture, that effectively models the conditional dependence among different acoustic quantization levels, optimized by a masked language modeling objective, enabling zero-shot speech generation. Our evaluations demonstrated not only the superior inference efficiency of EDM-TTS, but also its state-of-the-art high-quality zero-shot speech quality, naturalness and speaker similarity.
Proceedings of the Reinforcement Learning Conference (RLC), 2025
Offline Reinforcement Learning with Wasserstein Regularization via Optimal Transport Maps
Motoki Omura, Yusuke Mukuta, Kazuki Ota, Takayuki Osa, Tatsuya Harada
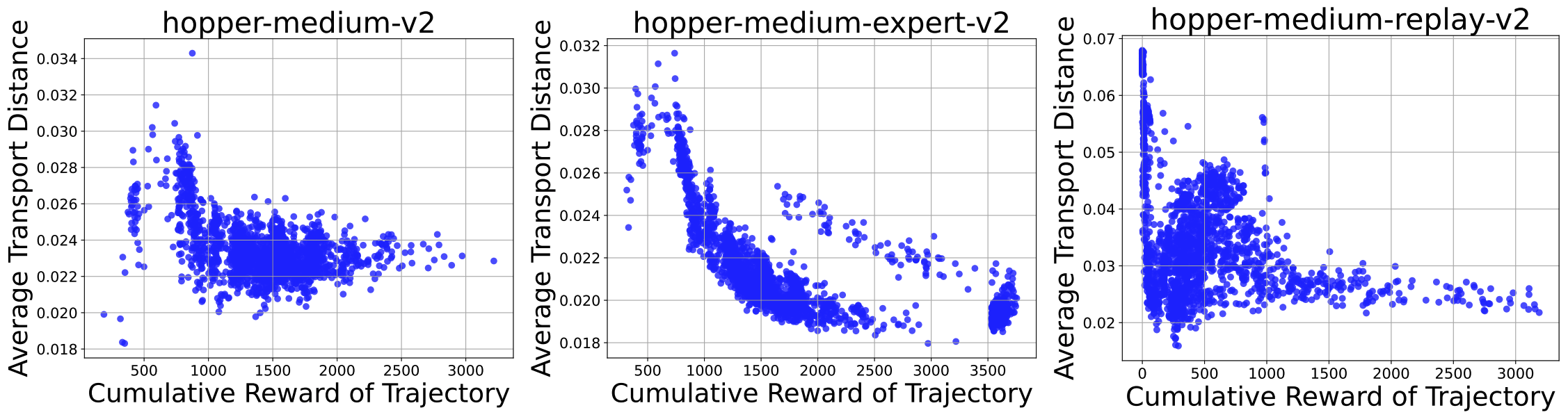 Offline reinforcement learning (RL) aims to learn an optimal policy from a static dataset, making it particularly valuable in scenarios where data collection is costly, such as robotics. A major challenge in offline RL is distributional shift, where the learned policy deviates from the dataset distribution, potentially leading to unreliable out-of-distribution actions. To mitigate this issue, regularization techniques have been employed. While many existing methods utilize density ratio-based measures, such as the f-divergence, for regularization, we propose an approach that utilizes the Wasserstein distance, which is robust to out-of-distribution data and captures the similarity between actions. Our method employs input-convex neural networks (ICNNs) to model optimal transport maps, enabling the computation of the Wasserstein distance in a discriminator-free manner, thereby avoiding adversarial training and ensuring stable learning. Our approach demonstrates comparable or superior performance to widely used existing methods on the D4RL benchmark dataset.
Offline reinforcement learning (RL) aims to learn an optimal policy from a static dataset, making it particularly valuable in scenarios where data collection is costly, such as robotics. A major challenge in offline RL is distributional shift, where the learned policy deviates from the dataset distribution, potentially leading to unreliable out-of-distribution actions. To mitigate this issue, regularization techniques have been employed. While many existing methods utilize density ratio-based measures, such as the f-divergence, for regularization, we propose an approach that utilizes the Wasserstein distance, which is robust to out-of-distribution data and captures the similarity between actions. Our method employs input-convex neural networks (ICNNs) to model optimal transport maps, enabling the computation of the Wasserstein distance in a discriminator-free manner, thereby avoiding adversarial training and ensuring stable learning. Our approach demonstrates comparable or superior performance to widely used existing methods on the D4RL benchmark dataset.
Proceedings of the International Conference on Machine Learning (ICML), 2025
Gradual Transition from Bellman Optimality Operator to Bellman Operator in Online Reinforcement Learning
Motoki Omura, Kazuki Ota, Takayuki Osa, Yusuke Mukuta, Tatsuya Harada
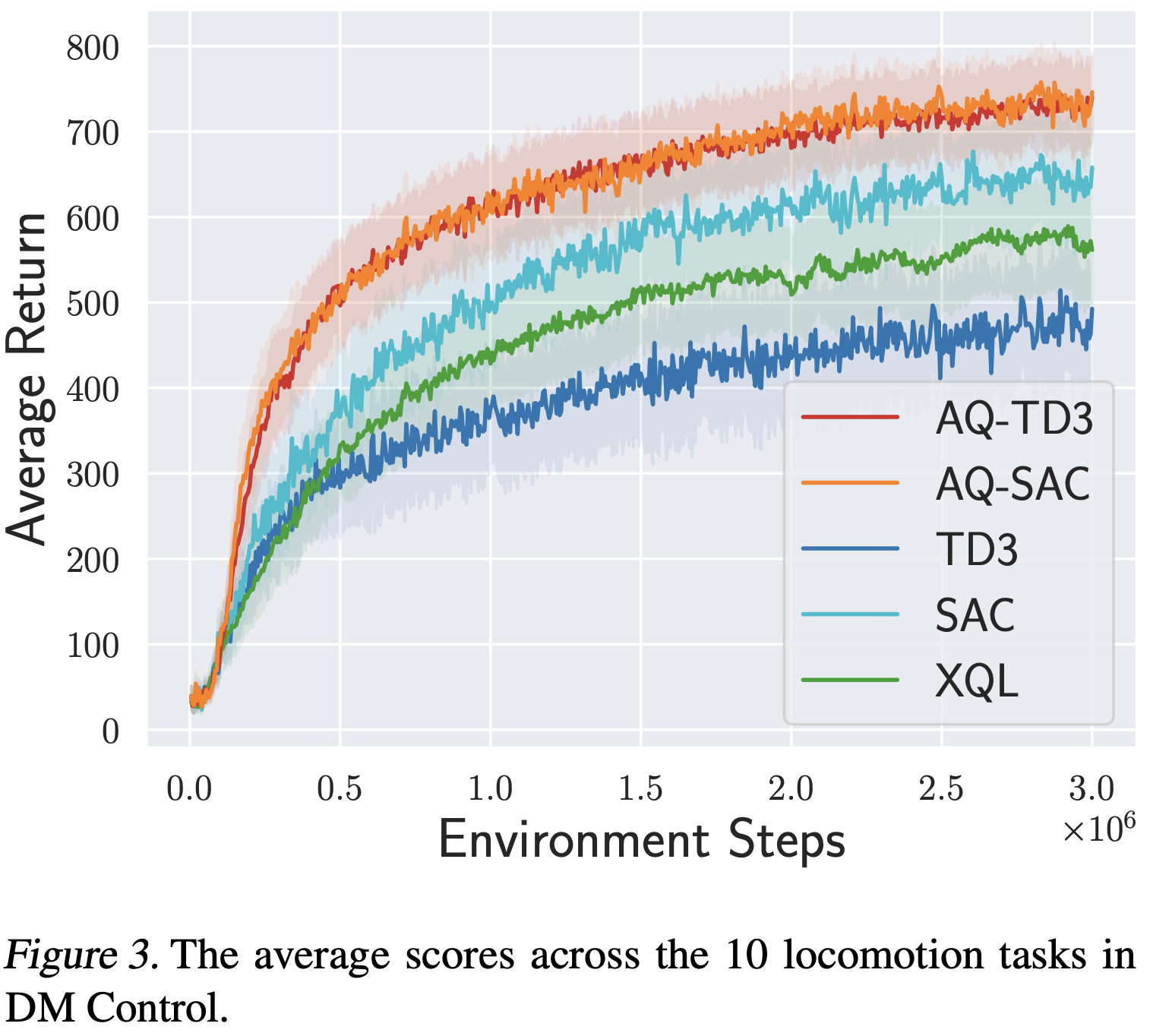 For continuous action spaces, actor-critic methods are widely used in online reinforcement learning (RL). However, unlike RL algorithms for discrete actions, which generally model the optimal value function using the Bellman optimality operator, RL algorithms for continuous actions typically model Q-values for the current policy using the Bellman operator. These algorithms for continuous actions rely exclusively on policy updates for improvement, which often results in low sample efficiency. This study examines the effectiveness of incorporating the Bellman optimality operator into actor-critic frameworks. Experiments in a simple environment show that modeling optimal values accelerates learning but leads to overestimation bias. To address this, we propose an annealing approach that gradually transitions from the Bellman optimality operator to the Bellman operator, thereby accelerating learning while mitigating bias. Our method, combined with TD3 and SAC, significantly outperforms existing approaches across various locomotion and manipulation tasks, demonstrating improved performance and robustness to hyperparameters related to optimality.
For continuous action spaces, actor-critic methods are widely used in online reinforcement learning (RL). However, unlike RL algorithms for discrete actions, which generally model the optimal value function using the Bellman optimality operator, RL algorithms for continuous actions typically model Q-values for the current policy using the Bellman operator. These algorithms for continuous actions rely exclusively on policy updates for improvement, which often results in low sample efficiency. This study examines the effectiveness of incorporating the Bellman optimality operator into actor-critic frameworks. Experiments in a simple environment show that modeling optimal values accelerates learning but leads to overestimation bias. To address this, we propose an annealing approach that gradually transitions from the Bellman optimality operator to the Bellman operator, thereby accelerating learning while mitigating bias. Our method, combined with TD3 and SAC, significantly outperforms existing approaches across various locomotion and manipulation tasks, demonstrating improved performance and robustness to hyperparameters related to optimality.
The IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025
A Theory of Learning Unified Model via Knowledge Integration from Label Space Varying Domains
Dexuan Zhang, Thomas Westfechtel, Tatsuya Harada
 Capturing high-quality photographs across diverse real-world lighting conditions is challenging, as both natural lighting (e.g., low-light) and camera exposure settings (e.g., exposure time) strongly influence image quality. This difficulty intensifies in multi-view scenarios, where each viewpoint can have distinct lighting and image signal processor (ISP) settings, causing photometric inconsistencies between views. These lighting degradations and view variations significant challenges to both NeRF- and 3D Gaussian Splatting (3DGS)-based novel view synthesis (NVS) frameworks.
To address this, we introduce Luminance-GS, a novel approach to achieve high-quality novel view synthesis results under diverse and challenging lighting conditions using 3DGS. By adopting per-view color space mapping and view adaptive curve adjustments, Luminance-GS achieves state-of-the-art (SOTA) results across various lighting conditions—including low-light, overexposure, and varying exposure—without altering the original 3DGS explicit representation. Compared to previous NeRF- and 3DGS-based baselines, Luminance-GS provides real-time rendering speed with improved reconstruction quality. We would release the source code.
Capturing high-quality photographs across diverse real-world lighting conditions is challenging, as both natural lighting (e.g., low-light) and camera exposure settings (e.g., exposure time) strongly influence image quality. This difficulty intensifies in multi-view scenarios, where each viewpoint can have distinct lighting and image signal processor (ISP) settings, causing photometric inconsistencies between views. These lighting degradations and view variations significant challenges to both NeRF- and 3D Gaussian Splatting (3DGS)-based novel view synthesis (NVS) frameworks.
To address this, we introduce Luminance-GS, a novel approach to achieve high-quality novel view synthesis results under diverse and challenging lighting conditions using 3DGS. By adopting per-view color space mapping and view adaptive curve adjustments, Luminance-GS achieves state-of-the-art (SOTA) results across various lighting conditions—including low-light, overexposure, and varying exposure—without altering the original 3DGS explicit representation. Compared to previous NeRF- and 3DGS-based baselines, Luminance-GS provides real-time rendering speed with improved reconstruction quality. We would release the source code.
Luminance-GS: Adapting 3D Gaussian Splatting to Challenging Lighting Conditions with View-Adaptive Curve Adjustment
Ziteng Cui, Xuangeng Chu, Tatsuya Harada
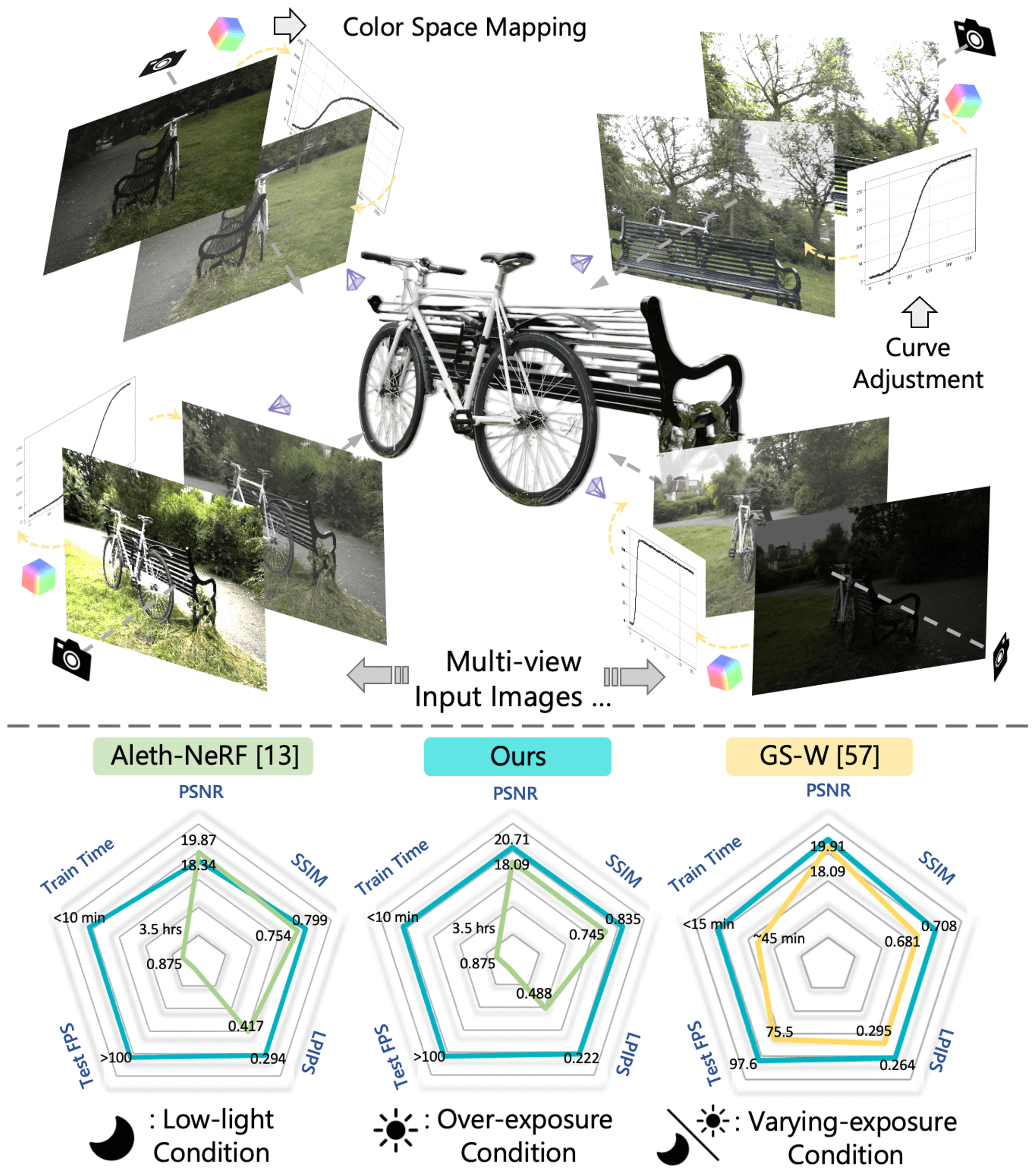 Capturing high-quality photographs across diverse real-world lighting conditions is challenging, as both natural lighting (e.g., low-light) and camera exposure settings (e.g., exposure time) strongly influence image quality. This difficulty intensifies in multi-view scenarios, where each viewpoint can have distinct lighting and image signal processor (ISP) settings, causing photometric inconsistencies between views. These lighting degradations and view variations significant challenges to both NeRF- and 3D Gaussian Splatting (3DGS)-based novel view synthesis (NVS) frameworks.
To address this, we introduce Luminance-GS, a novel approach to achieve high-quality novel view synthesis results under diverse and challenging lighting conditions using 3DGS. By adopting per-view color space mapping and view adaptive curve adjustments, Luminance-GS achieves state-of-the-art (SOTA) results across various lighting conditions—including low-light, overexposure, and varying exposure—without altering the original 3DGS explicit representation. Compared to previous NeRF- and 3DGS-based baselines, Luminance-GS provides real-time rendering speed with improved reconstruction quality. We would release the source code.
Capturing high-quality photographs across diverse real-world lighting conditions is challenging, as both natural lighting (e.g., low-light) and camera exposure settings (e.g., exposure time) strongly influence image quality. This difficulty intensifies in multi-view scenarios, where each viewpoint can have distinct lighting and image signal processor (ISP) settings, causing photometric inconsistencies between views. These lighting degradations and view variations significant challenges to both NeRF- and 3D Gaussian Splatting (3DGS)-based novel view synthesis (NVS) frameworks.
To address this, we introduce Luminance-GS, a novel approach to achieve high-quality novel view synthesis results under diverse and challenging lighting conditions using 3DGS. By adopting per-view color space mapping and view adaptive curve adjustments, Luminance-GS achieves state-of-the-art (SOTA) results across various lighting conditions—including low-light, overexposure, and varying exposure—without altering the original 3DGS explicit representation. Compared to previous NeRF- and 3DGS-based baselines, Luminance-GS provides real-time rendering speed with improved reconstruction quality. We would release the source code.
The Thirteenth International Conference on Learning Representations, ICLR 2025
T2V2: A Unified Non-Autoregressive Model for Speech Recognition and Synthesis via Multitask Learning
Nabarun Goswami, Hanqin Wang, Tatsuya Harada
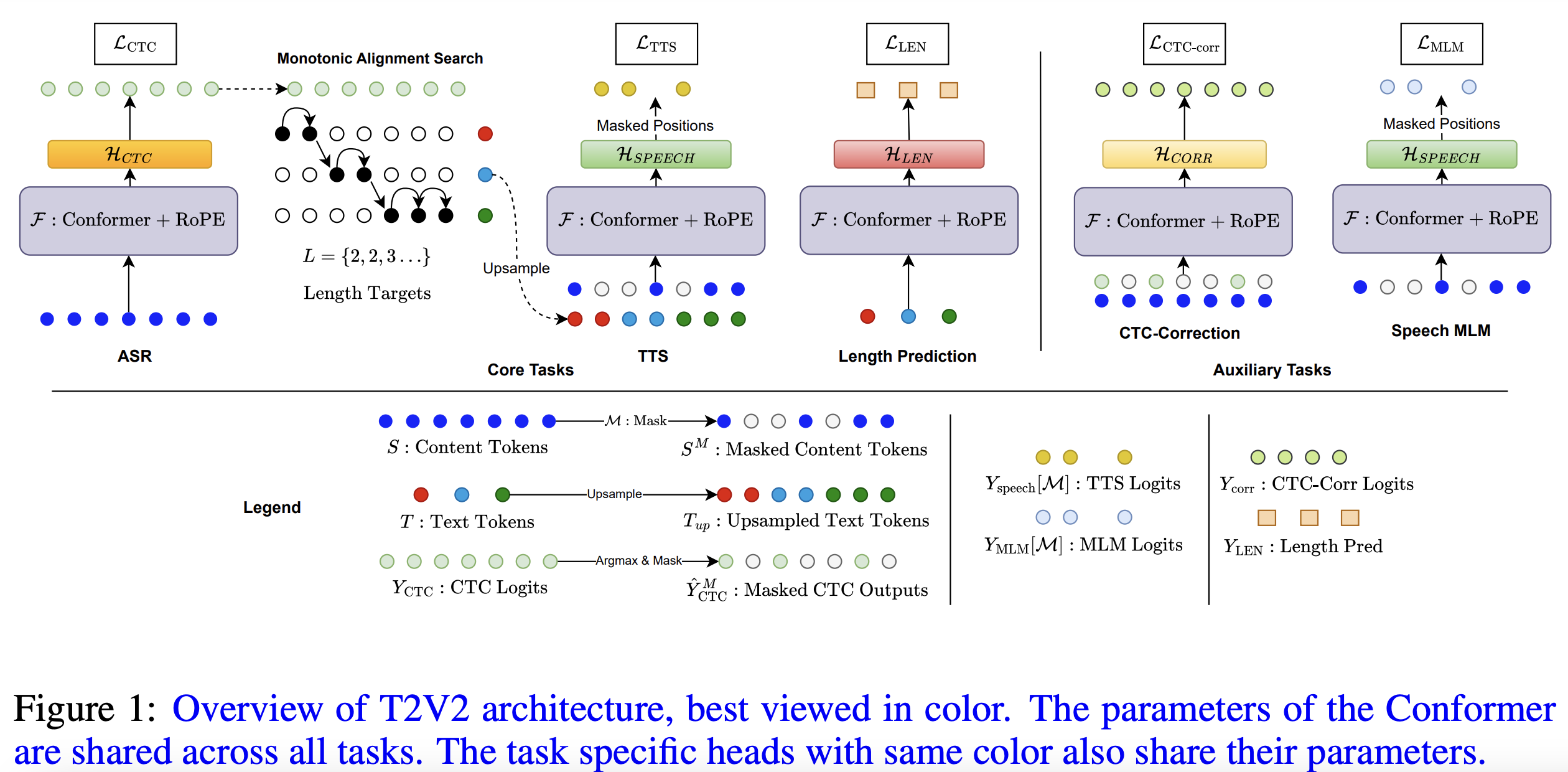 We introduce T2V2 (Text to Voice and Voice to Text), a unified non-autoregressive model capable of performing both automatic speech recognition (ASR) and text-to-speech (TTS) synthesis within the same framework. T2V2 uses a shared Conformer backbone with rotary positional embeddings to efficiently handle these core tasks, with ASR trained using Connectionist Temporal Classification (CTC) loss and TTS using masked language modeling (MLM) loss. The model operates on discrete tokens, where speech tokens are generated by clustering features from a self-supervised learning model. To further enhance performance, we introduce auxiliary tasks: CTC error correction to refine raw ASR outputs using contextual information from speech embeddings, and unconditional speech MLM, enabling classifier free guidance to improve TTS. Our method is self-contained, leveraging intermediate CTC outputs to align text and speech using Monotonic Alignment Search, without relying on external aligners. We perform extensive experimental evaluation to verify the efficacy of the T2V2 framework, achieving state-of-the-art performance on TTS task and competitive performance in discrete ASR.
We introduce T2V2 (Text to Voice and Voice to Text), a unified non-autoregressive model capable of performing both automatic speech recognition (ASR) and text-to-speech (TTS) synthesis within the same framework. T2V2 uses a shared Conformer backbone with rotary positional embeddings to efficiently handle these core tasks, with ASR trained using Connectionist Temporal Classification (CTC) loss and TTS using masked language modeling (MLM) loss. The model operates on discrete tokens, where speech tokens are generated by clustering features from a self-supervised learning model. To further enhance performance, we introduce auxiliary tasks: CTC error correction to refine raw ASR outputs using contextual information from speech embeddings, and unconditional speech MLM, enabling classifier free guidance to improve TTS. Our method is self-contained, leveraging intermediate CTC outputs to align text and speech using Monotonic Alignment Search, without relying on external aligners. We perform extensive experimental evaluation to verify the efficacy of the T2V2 framework, achieving state-of-the-art performance on TTS task and competitive performance in discrete ASR.