Abstracts of papers published in 2024
Neurocomputing
Defender of privacy and fairness: Tiny but reversible generative model via mutually collaborative knowledge distillation
Sissi Xiaoxiao Wu , Zehong Huang , Zhicong Liang , Lin Gu, Tatsuya Harada, Zheng Li, Yingying Zhu
 Sharing vast amounts of data to train powerful artificial intelligence (AI) models raises public interest concerns such as privacy and fairness. While reversible anonymization techniques are very effective for privacy preservation and fairness enhancement, these methods rely on heavy reversible generative models, making them only suitable to run in the cloud or on a server independent from the image source. For example, data transmission might be under the privacy threats such as channel eavesdropping. Therefore, we propose a novel mutually collaborative knowledge distillation strategy to train a tiny and reversible generative model. This enables us to build a synthesis-based privacy and fairness protection system in embedded devices for anonymizing privacy-sensitive data and thus improve security protection capabilities from the source. The proposed mutually collaborative knowledge distillation method exploits the reversibility of the generative model. By pairing the teacher encoder (decoder) with the student decoder (encoder), we train the student decoder (encoder) by reconstructing the image space (latent space) from the prior image space (latent space). This results in tiny-size student models that can be embedded into devices. We deploy and evaluate our system on NVIDIA Jetson TX2 devices, which operate in real-time. Extensive experiments demonstrate that our system effectively anonymizes face images and thus protects privacy and also improves fairness while minimizing the impact on downstream tasks. Our code will be publicly available on GitHub.
Sharing vast amounts of data to train powerful artificial intelligence (AI) models raises public interest concerns such as privacy and fairness. While reversible anonymization techniques are very effective for privacy preservation and fairness enhancement, these methods rely on heavy reversible generative models, making them only suitable to run in the cloud or on a server independent from the image source. For example, data transmission might be under the privacy threats such as channel eavesdropping. Therefore, we propose a novel mutually collaborative knowledge distillation strategy to train a tiny and reversible generative model. This enables us to build a synthesis-based privacy and fairness protection system in embedded devices for anonymizing privacy-sensitive data and thus improve security protection capabilities from the source. The proposed mutually collaborative knowledge distillation method exploits the reversibility of the generative model. By pairing the teacher encoder (decoder) with the student decoder (encoder), we train the student decoder (encoder) by reconstructing the image space (latent space) from the prior image space (latent space). This results in tiny-size student models that can be embedded into devices. We deploy and evaluate our system on NVIDIA Jetson TX2 devices, which operate in real-time. Extensive experiments demonstrate that our system effectively anonymizes face images and thus protects privacy and also improves fairness while minimizing the impact on downstream tasks. Our code will be publicly available on GitHub.
2024 IEEE-RAS 23rd International Conference on Humanoid Robots (Humanoids) 2024 (Oral)
Latent Space Curriculum Reinforcement Learning in High-Dimensional Contextual Spaces and Its Application to Robotic Piano Playing
Haruki Abe, Takayuki Osa, Motoki Omura, Jen-Yen Chang, Tatsuya Harada
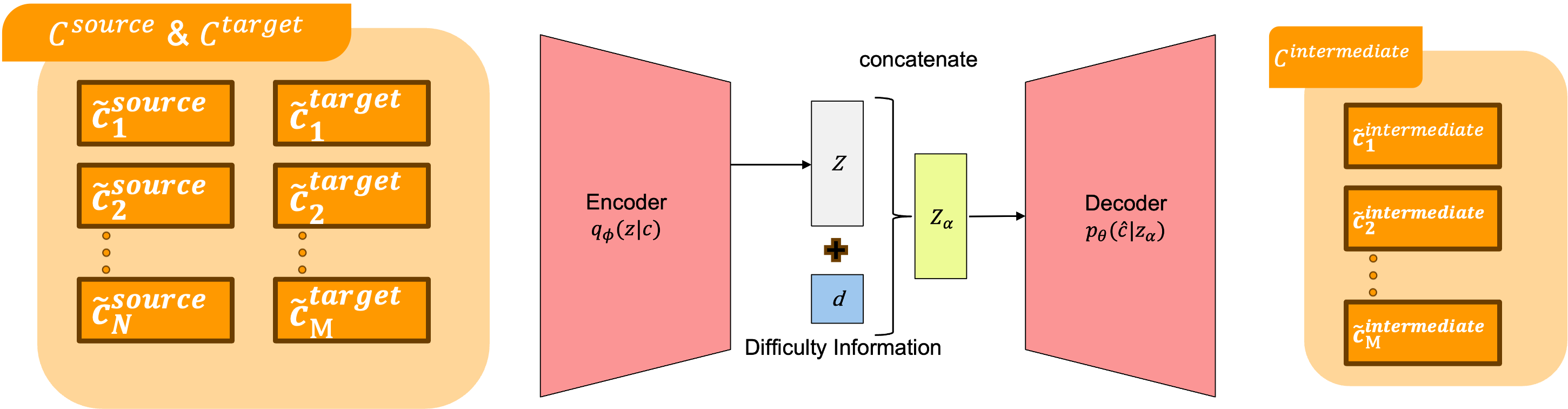 Curriculum reinforcement learning (CRL) enables learning optimal policies in complex tasks such as robotic hand manipulation. However, in tasks with high-dimensional contexts with temporally continuous goals, previous research has encountered issues such as increased computational costs and the inability to create appropriate curricula to facilitate learning. Therefore, this study proposes a novel CRL method that appropriately segments high-dimensional contexts and learns them using a generative model. Additionally, we propose a method to further enhance learning by incorporating difficulty information into the generative model. Finally, we experimentally confirm that our proposed method significantly accelerates learning in complex tasks such as dual-arm dexterous hand tasks, specifically, RoboPianist.
Curriculum reinforcement learning (CRL) enables learning optimal policies in complex tasks such as robotic hand manipulation. However, in tasks with high-dimensional contexts with temporally continuous goals, previous research has encountered issues such as increased computational costs and the inability to create appropriate curricula to facilitate learning. Therefore, this study proposes a novel CRL method that appropriately segments high-dimensional contexts and learns them using a generative model. Additionally, we propose a method to further enhance learning by incorporating difficulty information into the generative model. Finally, we experimentally confirm that our proposed method significantly accelerates learning in complex tasks such as dual-arm dexterous hand tasks, specifically, RoboPianist.
IEEE/CVF Winter Conference on Applications of Computer Vision(WACV) 2025
Combining inherent knowledge of vision-language models with unsupervised domain adaptation through weak-strong guidance
Thomas Westfechtel, Dexuan Zhang, Tatsuya Harada
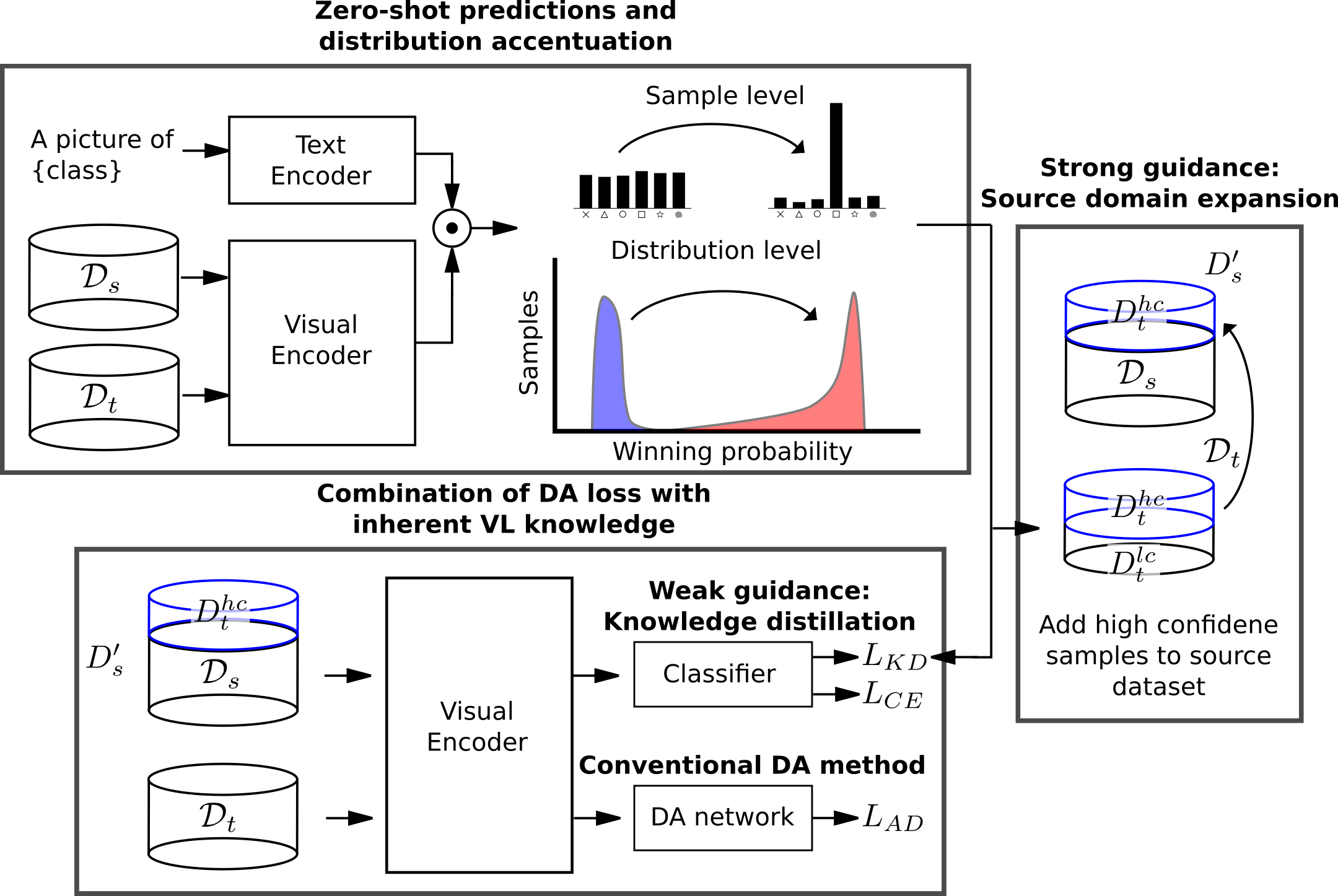 Unsupervised domain adaptation (UDA) tries to overcome the tedious work of labeling data by leveraging a labeled source dataset and transferring its knowledge to a similar but different target dataset. Meanwhile, current vision-language models exhibit remarkable zero-shot prediction capabilities.
In this work, we combine knowledge gained through UDA with the inherent knowledge of vision-language models.
We introduce a strong-weak guidance learning scheme that employs zero-shot predictions to help align the source and target dataset. For the strong guidance, we expand the source dataset with the most confident samples of the target dataset. Additionally, we employ a knowledge distillation loss as weak guidance.
The strong guidance uses hard labels but is only applied to the most confident predictions from the target dataset. Conversely, the weak guidance is employed to the whole dataset but uses soft labels. The weak guidance is implemented as a knowledge distillation loss with (adjusted) zero-shot predictions.
We show that our method complements and benefits from prompt adaptation techniques for vision-language models.
We conduct experiments and ablation studies on three benchmarks (OfficeHome, VisDA, and DomainNet), outperforming state-of-the-art methods. Our ablation studies further demonstrate the contributions of different components of our algorithm.
Unsupervised domain adaptation (UDA) tries to overcome the tedious work of labeling data by leveraging a labeled source dataset and transferring its knowledge to a similar but different target dataset. Meanwhile, current vision-language models exhibit remarkable zero-shot prediction capabilities.
In this work, we combine knowledge gained through UDA with the inherent knowledge of vision-language models.
We introduce a strong-weak guidance learning scheme that employs zero-shot predictions to help align the source and target dataset. For the strong guidance, we expand the source dataset with the most confident samples of the target dataset. Additionally, we employ a knowledge distillation loss as weak guidance.
The strong guidance uses hard labels but is only applied to the most confident predictions from the target dataset. Conversely, the weak guidance is employed to the whole dataset but uses soft labels. The weak guidance is implemented as a knowledge distillation loss with (adjusted) zero-shot predictions.
We show that our method complements and benefits from prompt adaptation techniques for vision-language models.
We conduct experiments and ablation studies on three benchmarks (OfficeHome, VisDA, and DomainNet), outperforming state-of-the-art methods. Our ablation studies further demonstrate the contributions of different components of our algorithm.
Physiology-aware PolySnake For Coronary Vessel Segmentation
Yizhe Ruan, Lin Gu ,Yusuke Kurose , Junichi Iho, Youji Tokunaga, Makoto Horie, Yusaku Hayashi, Keisuke Nishizawa, Yasushi Koyama,Tatsuya Harada
 The code and project page will be released very soon.
Coronary artery disease (CAD) poses a significant health risk, underscoring the need for early detection to enable effective treatment. Computer-aided detection and diagnosis systems leveraging coronary computed tomography angiography (CCTA) imaging have demonstrated promise in CAD detection. Recent advances in deep learning have sparked a growing interest in automating CAD detection from CCTA images using these techniques. Accurate segmentation of coronary vessels is crucial for CAD detection and diagnosis using CCTA images. Despite the promising performance of deep learning in automated CAD detection, challenges persist, particularly in addressing the imbalanced presence of plaque in unhealthy vessels.
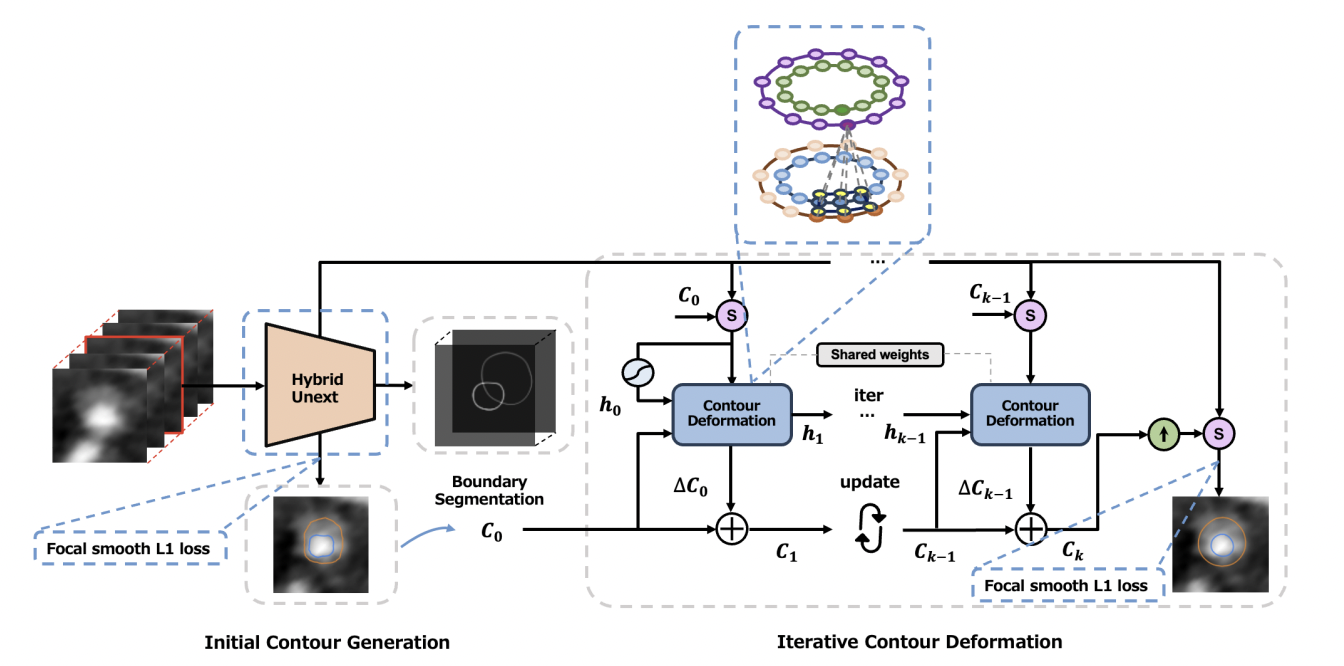
This paper introduces a novel approach to coronary vessel segmentation that explicitly considers the physiology of the coronary artery. The physiology-aware pipeline comprises three key components: First, we designed a hybrid Unext architecture to segment artery boundaries and predict initial boundary contours by incorporating 3D spatial relations among adjacent slices. Second, we propose multi-class circular convolution for iterative contour deformation, generating well-connected contour pairs of inner and outer boundaries of the artery wall through iterative refinement of the initial contour pairs. Additionally, we introduce focal smooth L1 loss to tackle implicit class imbalance caused by plaque in unhealthy vessels, explicitly limiting the accuracy of initial contours to enhance the robustness of the relation-aware poly snake network. Comparisons with existing approaches and extensive evaluations demonstrate that our methods significantly enhance model performance at each step, ultimately achieving state-of-the-art performance in coronary vessel
The code and project page will be released very soon.
Coronary artery disease (CAD) poses a significant health risk, underscoring the need for early detection to enable effective treatment. Computer-aided detection and diagnosis systems leveraging coronary computed tomography angiography (CCTA) imaging have demonstrated promise in CAD detection. Recent advances in deep learning have sparked a growing interest in automating CAD detection from CCTA images using these techniques. Accurate segmentation of coronary vessels is crucial for CAD detection and diagnosis using CCTA images. Despite the promising performance of deep learning in automated CAD detection, challenges persist, particularly in addressing the imbalanced presence of plaque in unhealthy vessels.
This paper introduces a novel approach to coronary vessel segmentation that explicitly considers the physiology of the coronary artery. The physiology-aware pipeline comprises three key components: First, we designed a hybrid Unext architecture to segment artery boundaries and predict initial boundary contours by incorporating 3D spatial relations among adjacent slices. Second, we propose multi-class circular convolution for iterative contour deformation, generating well-connected contour pairs of inner and outer boundaries of the artery wall through iterative refinement of the initial contour pairs. Additionally, we introduce focal smooth L1 loss to tackle implicit class imbalance caused by plaque in unhealthy vessels, explicitly limiting the accuracy of initial contours to enhance the robustness of the relation-aware poly snake network. Comparisons with existing approaches and extensive evaluations demonstrate that our methods significantly enhance model performance at each step, ultimately achieving state-of-the-art performance in coronary vessel
Transactions on Machine Learning Research (TMLR), 2024
Offline Deep Reinforcement Learning for Visual Distractions via Domain Adversarial Training
Jen-Yen Chang, Thomas Westfectel, Takayuki Osa, Tatsuya Harada.
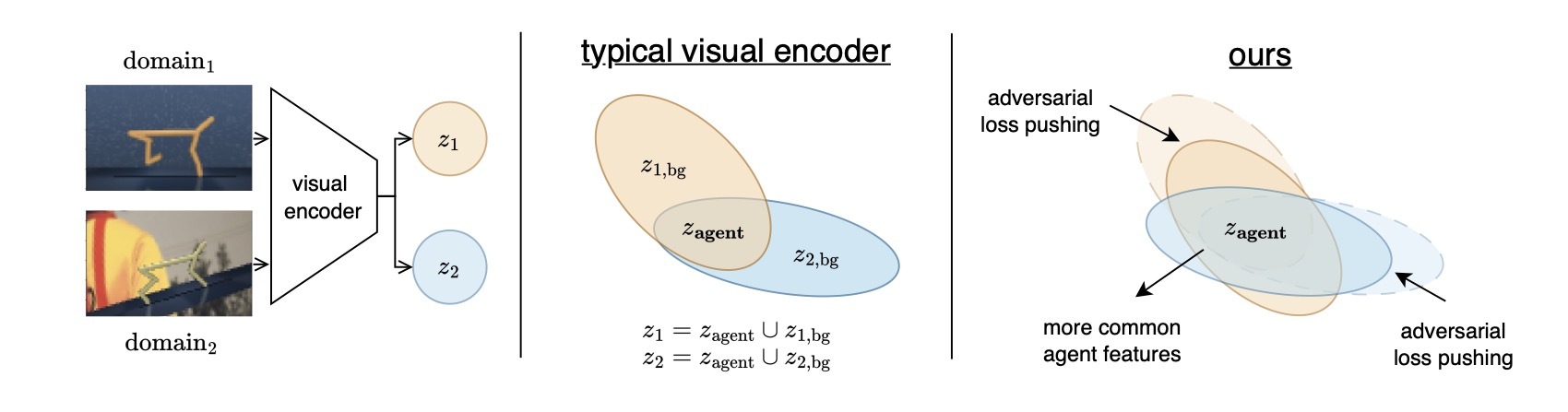 Recent advances in offline reinforcement learning (RL) have relied predominantly on learning from proprioceptive states. However, obtaining proprioceptive states for all objects may not always be feasible, particularly in offline settings. Therefore, RL agents must be capable of learning from raw sensor inputs such as images. However, recent studies have indicated that visual distractions can impair the performance of RL agents when observations in the evaluation environment differ significantly from those in the training environment. This issue is even more crucial in the visual offline RL paradigm, where the collected datasets can differ drastically from the testing environment. In this work, we investigated an adversarial-based algorithm to address the problem of visual distraction in offline RL settings. Our adversarial approach involves training agents to learn features that are more robust against visual distractions. Furthermore, we proposed a complementary dataset to add to the V-D4RL distraction dataset by extending it to more locomotion tasks. We empirically demonstrate that our method surpasses state-of-the-art baselines in tasks on both the VD4RL and proposed dataset when evaluated on random visual distractions.Code, Link
Recent advances in offline reinforcement learning (RL) have relied predominantly on learning from proprioceptive states. However, obtaining proprioceptive states for all objects may not always be feasible, particularly in offline settings. Therefore, RL agents must be capable of learning from raw sensor inputs such as images. However, recent studies have indicated that visual distractions can impair the performance of RL agents when observations in the evaluation environment differ significantly from those in the training environment. This issue is even more crucial in the visual offline RL paradigm, where the collected datasets can differ drastically from the testing environment. In this work, we investigated an adversarial-based algorithm to address the problem of visual distraction in offline RL settings. Our adversarial approach involves training agents to learn features that are more robust against visual distractions. Furthermore, we proposed a complementary dataset to add to the V-D4RL distraction dataset by extending it to more locomotion tasks. We empirically demonstrate that our method surpasses state-of-the-art baselines in tasks on both the VD4RL and proposed dataset when evaluated on random visual distractions.Code, Link
The Thirty-Eighth Annual Conference on Neural Information Processing Systems (NeurIPS), 2024
Generalizable and Animatable Gaussian Head Avatar
Xuangeng Chu, Tatsuya Harada
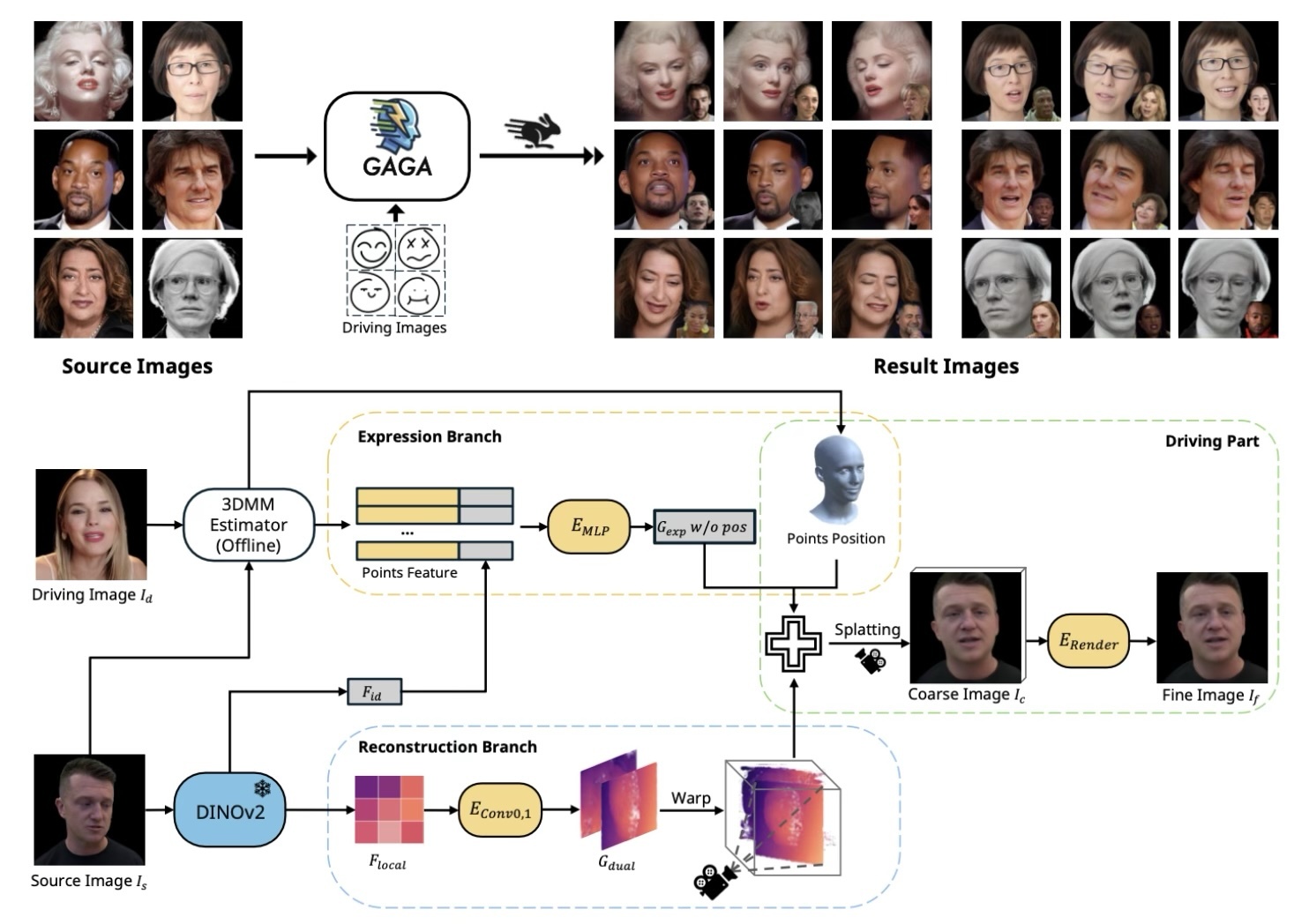 We propose the first generalizable 3DGS-based head avatar reconstruction framework. Existing methods rely on neural radiance fields, leading to heavy rendering consumption and low reenactment speeds. To address these limitations, we generate the parameters of 3D Gaussians from a single image in a single forward pass. The key innovation of our work is the proposed dual-lifting method, which produces high-fidelity 3D Gaussians that capture identity and facial details. Additionally, we leverage global image features and the 3D morphable model to construct 3D Gaussians for controlling expressions. After training, our model can reconstruct unseen identities without specific optimizations and perform reenactment rendering at real-time speeds. Experiments show that our method exhibits superior performance compared to previous methods in terms of reconstruction quality and expression accuracy. We believe our method can establish new benchmarks for future research and advance applications of digital avatars.
We propose the first generalizable 3DGS-based head avatar reconstruction framework. Existing methods rely on neural radiance fields, leading to heavy rendering consumption and low reenactment speeds. To address these limitations, we generate the parameters of 3D Gaussians from a single image in a single forward pass. The key innovation of our work is the proposed dual-lifting method, which produces high-fidelity 3D Gaussians that capture identity and facial details. Additionally, we leverage global image features and the 3D morphable model to construct 3D Gaussians for controlling expressions. After training, our model can reconstruct unseen identities without specific optimizations and perform reenactment rendering at real-time speeds. Experiments show that our method exhibits superior performance compared to previous methods in terms of reconstruction quality and expression accuracy. We believe our method can establish new benchmarks for future research and advance applications of digital avatars.
ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia 2024 (SIGGRAPH ASIA)
Style-NeRF2NeRF: 3D Style Transfer from Style-Aligned Multi-View Images
Haruo Fujiwara, Yusuke Mukuta, Tatsuya Harada
 We propose a simple yet effective pipeline for stylizing a 3D scene, harnessing the power of 2D image diffusion models. Given a NeRF model reconstructed from a set of multi-view images, we perform 3D style transfer by refining the source NeRF model using stylized images generated by a style-aligned image-to-image diffusion model. Given a target style prompt, we first generate perceptually similar multi-view images by leveraging a depth-conditioned diffusion model with an attention-sharing mechanism. Next, based on the stylized multi-view images, we propose to guide the style transfer process with the sliced Wasserstein loss based on the feature maps extracted from a pre-trained CNN model. Our pipeline consists of decoupled steps, allowing users to test various prompt ideas and preview the stylized 3D result before proceeding to the NeRF fine-tuning stage. We demonstrate that our method can transfer diverse artistic styles to real-world 3D scenes with competitive quality.
We propose a simple yet effective pipeline for stylizing a 3D scene, harnessing the power of 2D image diffusion models. Given a NeRF model reconstructed from a set of multi-view images, we perform 3D style transfer by refining the source NeRF model using stylized images generated by a style-aligned image-to-image diffusion model. Given a target style prompt, we first generate perceptually similar multi-view images by leveraging a depth-conditioned diffusion model with an attention-sharing mechanism. Next, based on the stylized multi-view images, we propose to guide the style transfer process with the sliced Wasserstein loss based on the feature maps extracted from a pre-trained CNN model. Our pipeline consists of decoupled steps, allowing users to test various prompt ideas and preview the stylized 3D result before proceeding to the NeRF fine-tuning stage. We demonstrate that our method can transfer diverse artistic styles to real-world 3D scenes with competitive quality.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
Frequency-aware Feature Fusion for Dense Image Prediction
Linwei Chen, Ying Fu, Lin Gu, Chenggang Yan, Tatsuya Harada, and Gao Huang
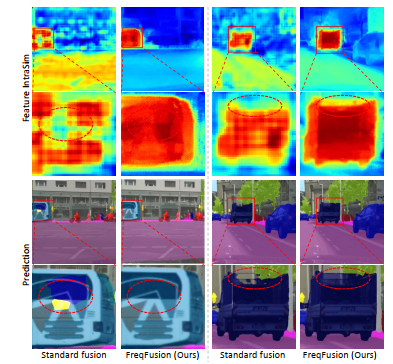 Dense image prediction tasks demand features with strong category information and precise spatial boundary details at high resolution. To achieve this, modern hierarchical models often utilize feature fusion, directly adding upsampled coarse features from deep layers and high-resolution features from lower levels. In this paper, we observe rapid variations in fused feature values within objects, resulting in intra-category inconsistency due to disturbed high-frequency features. Additionally, blurred boundaries in fused features lack accurate high frequency, leading to boundary displacement. Building upon these observations, we propose Frequency-Aware Feature Fusion (FreqFusion), integrating an Adaptive Low-Pass Filter (ALPF) generator, an offset generator, and an Adaptive High-Pass Filter (AHPF) generator. The ALPF generator predicts spatially-variant low-pass filters to attenuate high-frequency components within objects, reducing intra-class inconsistency during upsampling. The offset generator refines large inconsistent features and thin boundaries by replacing inconsistent features with more consistent ones through resampling, while the AHPF generator enhances high-frequency detailed boundary information lost during downsampling. Comprehensive visualization and quantitative analysis demonstrate that FreqFusion effectively improves feature consistency and sharpens object boundaries. Extensive experiments across various dense prediction tasks confirm its effectiveness. The code is made publicly available at https://github.com/Linwei-Chen/
Dense image prediction tasks demand features with strong category information and precise spatial boundary details at high resolution. To achieve this, modern hierarchical models often utilize feature fusion, directly adding upsampled coarse features from deep layers and high-resolution features from lower levels. In this paper, we observe rapid variations in fused feature values within objects, resulting in intra-category inconsistency due to disturbed high-frequency features. Additionally, blurred boundaries in fused features lack accurate high frequency, leading to boundary displacement. Building upon these observations, we propose Frequency-Aware Feature Fusion (FreqFusion), integrating an Adaptive Low-Pass Filter (ALPF) generator, an offset generator, and an Adaptive High-Pass Filter (AHPF) generator. The ALPF generator predicts spatially-variant low-pass filters to attenuate high-frequency components within objects, reducing intra-class inconsistency during upsampling. The offset generator refines large inconsistent features and thin boundaries by replacing inconsistent features with more consistent ones through resampling, while the AHPF generator enhances high-frequency detailed boundary information lost during downsampling. Comprehensive visualization and quantitative analysis demonstrate that FreqFusion effectively improves feature consistency and sharpens object boundaries. Extensive experiments across various dense prediction tasks confirm its effectiveness. The code is made publicly available at https://github.com/Linwei-Chen/
IEEE Transactions on Medical Imaging
A New Benchmark: Clinical Uncertainty and Severity Aware Labeled Chest X-Ray Images with Multi-Relationship Graph Learning
Mengliang Zhang, Xinyue Hu, Lin Gu, Liangchen Liu, Kazuma Kobayashi, Tatsuya Harada, Yan Yan, Ronald M. Summers, and Yingying Zhu
 Chest radiography, commonly known as CXR, is frequently utilized in clinical settings to detect cardiopulmonary conditions. However, even seasoned radiologists might offer different evaluations regarding the seriousness and uncertainty associated with observed abnormalities. Previous research has attempted to utilize clinical notes to extract abnormal labels for training deep-learning models in CXR image diagnosis. However, these methods often neglected the varying degrees of severity and uncertainty linked to different labels. In our study, we initially assembled a comprehensive new dataset of CXR images based on clinical textual data, which incorporated radiologists' assessments of uncertainty and severity. Using this dataset, we introduced a multi-relationship graph learning framework that leverages spatial and semantic relationships while addressing expert uncertainty through a dedicated loss function. Our research showcases a notable enhancement in CXR image diagnosis and the interpretability of the diagnostic model, surpassing existing state-of-the-art methodologies. The dataset address of disease severity and uncertainty we extracted is: Link.
Chest radiography, commonly known as CXR, is frequently utilized in clinical settings to detect cardiopulmonary conditions. However, even seasoned radiologists might offer different evaluations regarding the seriousness and uncertainty associated with observed abnormalities. Previous research has attempted to utilize clinical notes to extract abnormal labels for training deep-learning models in CXR image diagnosis. However, these methods often neglected the varying degrees of severity and uncertainty linked to different labels. In our study, we initially assembled a comprehensive new dataset of CXR images based on clinical textual data, which incorporated radiologists' assessments of uncertainty and severity. Using this dataset, we introduced a multi-relationship graph learning framework that leverages spatial and semantic relationships while addressing expert uncertainty through a dedicated loss function. Our research showcases a notable enhancement in CXR image diagnosis and the interpretability of the diagnostic model, surpassing existing state-of-the-art methodologies. The dataset address of disease severity and uncertainty we extracted is: Link.
Medical Image Analysis
Rethinking masked image modeling for medical image representation
Yutong Xie, Lin Gu, Tatsuya Harada, Jianpeng Zhang, Yong Xia, Qi Wu
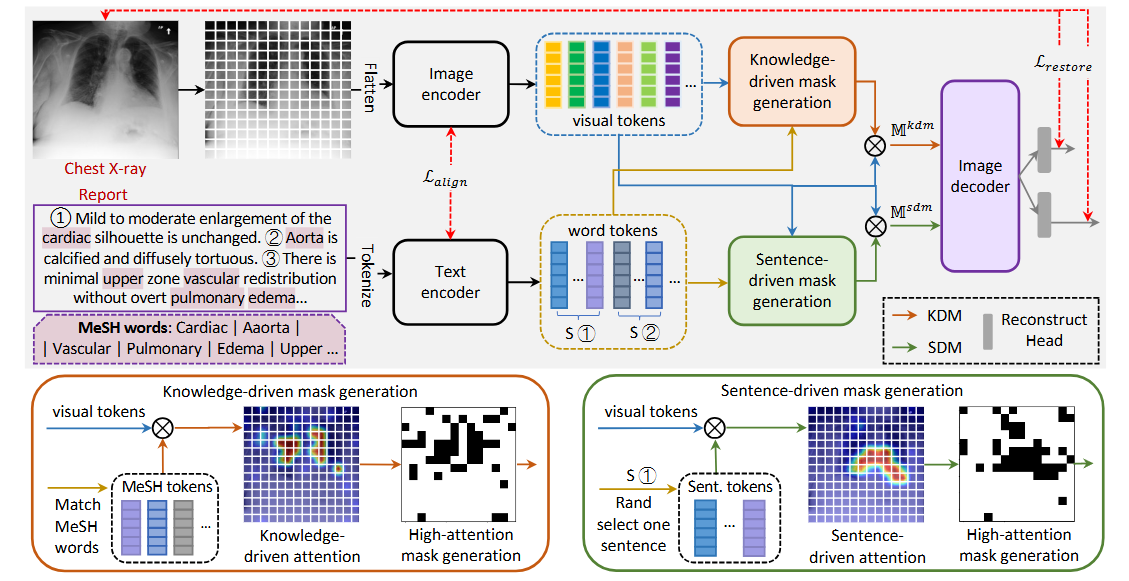
 Masked Image Modeling (MIM), a form of self-supervised learning, has garnered significant success in computer vision by improving image representations using unannotated data. Traditional MIMs typically employ a strategy of random sampling across the image. However, this random masking technique may not be ideally suited for medical imaging, which possesses distinct characteristics divergent from natural images. In medical imaging, particularly in pathology, disease-related features are often exceedingly sparse and localized, while the remaining regions appear normal and undifferentiated. Additionally, medical images frequently accompany reports, directly pinpointing pathological changes’ location. Inspired by this, we propose Masked medical Image Modelling (MedIM), a novel approach, to our knowledge, the first research that employs radiological reports to guide the masking and restore the informative areas of images, encouraging the network to explore the stronger semantic representations from medical images. We introduce two mutual comprehensive masking strategies, knowledge-driven masking (KDM), and sentence-driven masking (SDM). KDM uses Medical Subject Headings (MeSH) words unique to radiology reports to identify symptom clues mapped to MeSH words (e.g., cardiac, edema, vascular, pulmonary) and guide the mask generation. Recognizing that radiological reports often comprise several sentences detailing varied findings, SDM integrates sentence-level information to identify key regions for masking. MedIM reconstructs images informed by this masking from the KDM and SDM modules, promoting a comprehensive and enriched medical image representation. Our extensive experiments on seven downstream tasks covering multi-label/class image classification, pneumothorax segmentation, and medical image-report analysis, demonstrate that MedIM with report-guided masking achieves competitive performance. Our method substantially outperforms ImageNet pre-training, MIM-based pre-training, and medical image-report pre-training counterparts.
Masked Image Modeling (MIM), a form of self-supervised learning, has garnered significant success in computer vision by improving image representations using unannotated data. Traditional MIMs typically employ a strategy of random sampling across the image. However, this random masking technique may not be ideally suited for medical imaging, which possesses distinct characteristics divergent from natural images. In medical imaging, particularly in pathology, disease-related features are often exceedingly sparse and localized, while the remaining regions appear normal and undifferentiated. Additionally, medical images frequently accompany reports, directly pinpointing pathological changes’ location. Inspired by this, we propose Masked medical Image Modelling (MedIM), a novel approach, to our knowledge, the first research that employs radiological reports to guide the masking and restore the informative areas of images, encouraging the network to explore the stronger semantic representations from medical images. We introduce two mutual comprehensive masking strategies, knowledge-driven masking (KDM), and sentence-driven masking (SDM). KDM uses Medical Subject Headings (MeSH) words unique to radiology reports to identify symptom clues mapped to MeSH words (e.g., cardiac, edema, vascular, pulmonary) and guide the mask generation. Recognizing that radiological reports often comprise several sentences detailing varied findings, SDM integrates sentence-level information to identify key regions for masking. MedIM reconstructs images informed by this masking from the KDM and SDM modules, promoting a comprehensive and enriched medical image representation. Our extensive experiments on seven downstream tasks covering multi-label/class image classification, pneumothorax segmentation, and medical image-report analysis, demonstrate that MedIM with report-guided masking achieves competitive performance. Our method substantially outperforms ImageNet pre-training, MIM-based pre-training, and medical image-report pre-training counterparts.
The 35th British Machine Vision Conference, BMVC 2024
Discovering an Image-Adaptive Coordinate System for Photography Processing
Ziteng Cui, Lin Gu, Tatsuya Harada
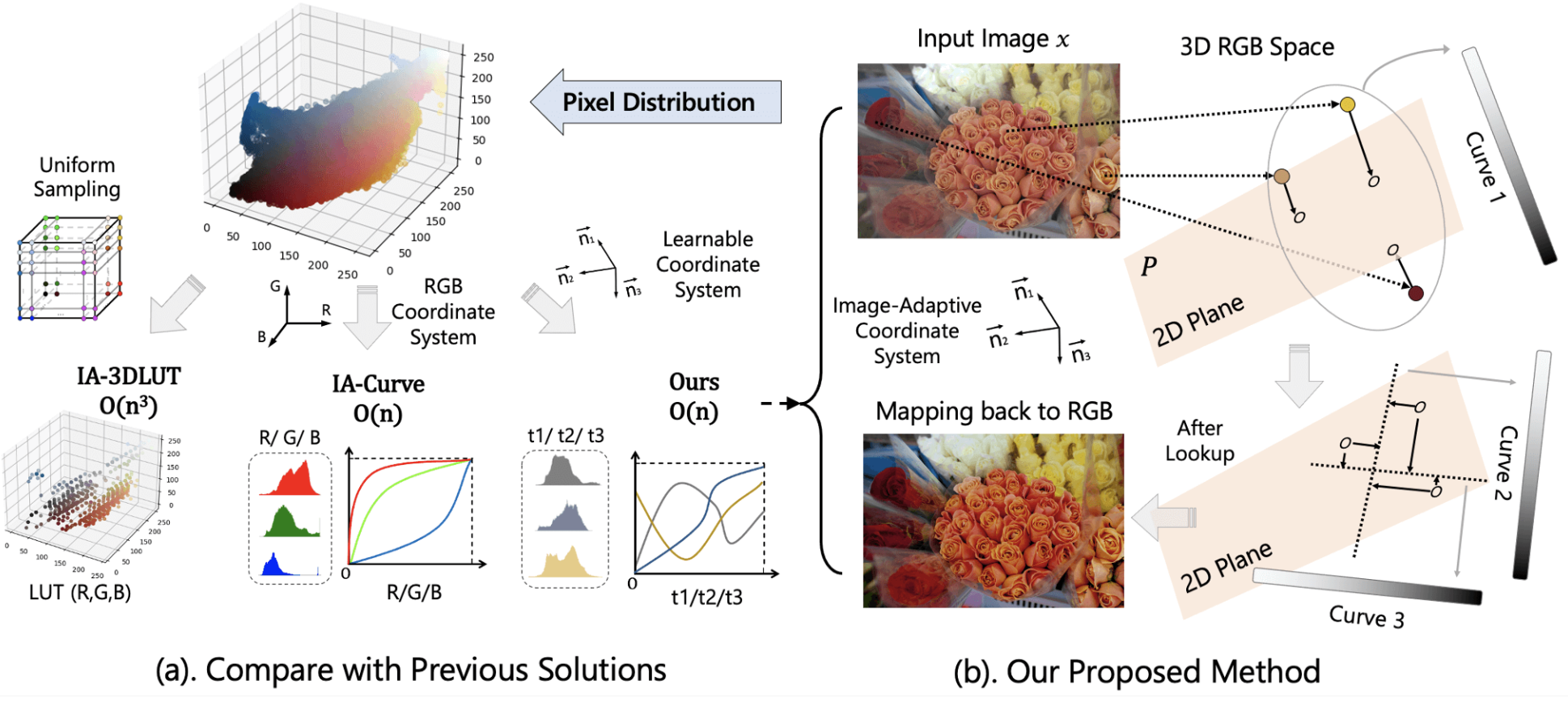 Curve & Lookup Table (LUT) based methods directly map a pixel to the target output, making them highly efficient tools for real-time photography processing. However, due to extreme memory complexity to learn full RGB space mapping, existing methods either sample a discretized 3D lattice to build a 3D LUT or decompose into three separate curves (1D LUTs) on the RGB channels. Here, we propose a novel algorithm, IAC, to learn an image-adaptive Cartesian coordinate system in the RGB color space before performing curve operations. This end-to-end trainable approach enables us to efficiently adjust images with a jointly learned image-adaptive coordinate system and curves. Experimental results demonstrate that this simple strategy achieves state-of-the-art (SOTA) performance in various photography processing tasks, including photo retouching, exposure correction, and white-balance editing, while also maintaining a lightweight design and fast inference speed.
Curve & Lookup Table (LUT) based methods directly map a pixel to the target output, making them highly efficient tools for real-time photography processing. However, due to extreme memory complexity to learn full RGB space mapping, existing methods either sample a discretized 3D lattice to build a 3D LUT or decompose into three separate curves (1D LUTs) on the RGB channels. Here, we propose a novel algorithm, IAC, to learn an image-adaptive Cartesian coordinate system in the RGB color space before performing curve operations. This end-to-end trainable approach enables us to efficiently adjust images with a jointly learned image-adaptive coordinate system and curves. Experimental results demonstrate that this simple strategy achieves state-of-the-art (SOTA) performance in various photography processing tasks, including photo retouching, exposure correction, and white-balance editing, while also maintaining a lightweight design and fast inference speed.
Medical Image Analysis
OInterpretable Medical Image Visual Question Answering via Multi-Modal Relationship Graph Learning
Xinyue Hu, Lin Gu, Kazuma Kobayashi, Qiyuan An, Qingyu Chen, Zhiyong Lu, Chang Su, Tatsuya Harada, Yingying Zhu
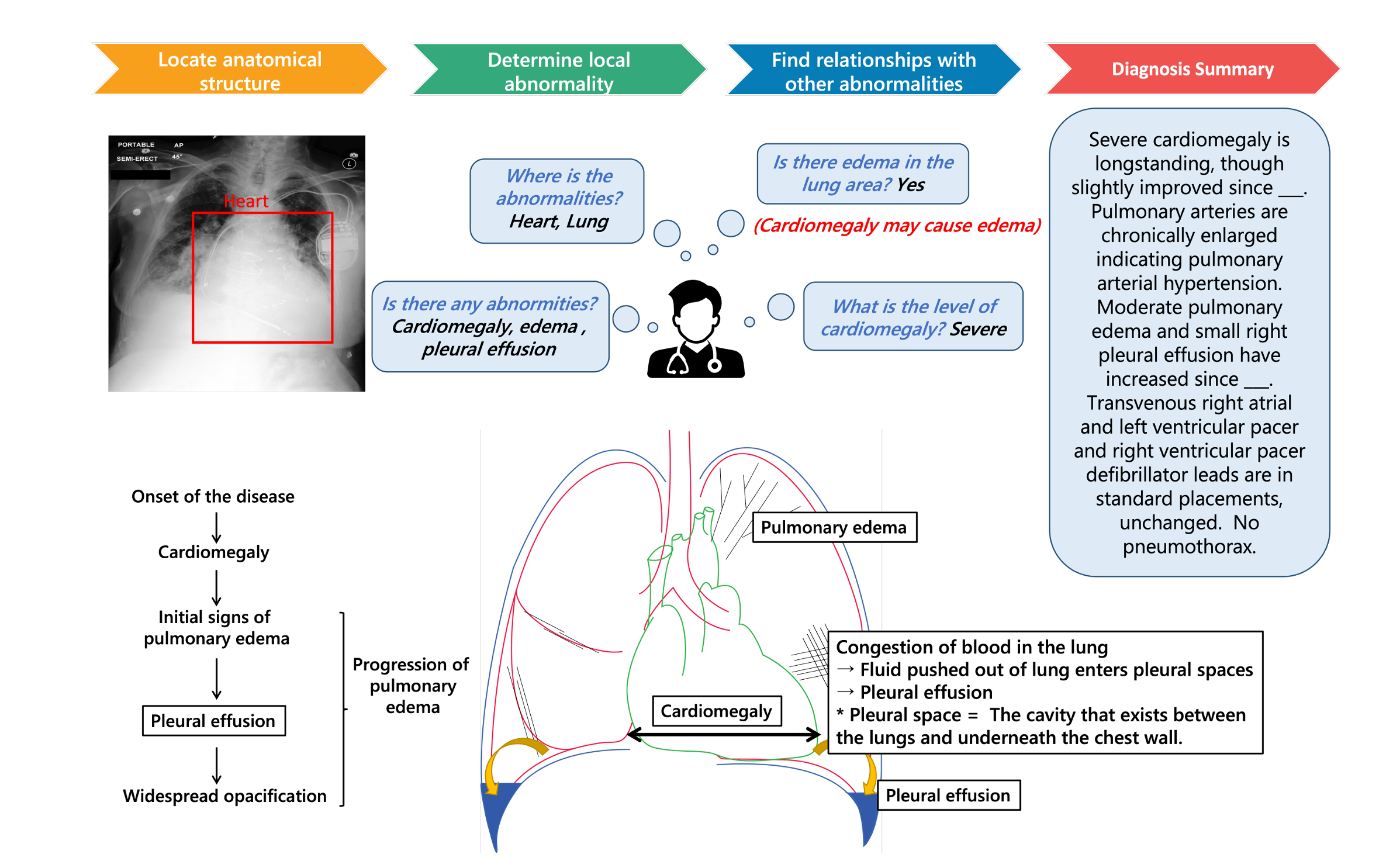 Medical visual question answering (VQA) aims to answer clinically relevant questions regarding input medical images. This tech nique has the potential to improve the effi ciency of medical professionals while reliev ing the burden on the public health system, par ticularly in resource-poor countries. Existing medical VQAmethodstend to encode medical images and learn the correspondence between visual features and questions without exploit ing the spatial, semantic, or medical knowl edge behind them. This is partially because of the small size of the current medical VQA dataset, which often includes simple questions. Therefore, we first collected a comprehensive and large-scale medical VQA dataset, focus ing on chest X-ray images. The questions involved detailed relationships, such as dis ease names, locations, levels, and types in our dataset. Based on this dataset, we also pro pose a novel baseline method by constructing three different relationship graphs: spatial re lationship, semantic relationship, and implicit relationship graphs on the image regions, ques tions, and semantic labels. The answer and graph reasoning paths are learned for different questions.
Medical visual question answering (VQA) aims to answer clinically relevant questions regarding input medical images. This tech nique has the potential to improve the effi ciency of medical professionals while reliev ing the burden on the public health system, par ticularly in resource-poor countries. Existing medical VQAmethodstend to encode medical images and learn the correspondence between visual features and questions without exploit ing the spatial, semantic, or medical knowl edge behind them. This is partially because of the small size of the current medical VQA dataset, which often includes simple questions. Therefore, we first collected a comprehensive and large-scale medical VQA dataset, focus ing on chest X-ray images. The questions involved detailed relationships, such as dis ease names, locations, levels, and types in our dataset. Based on this dataset, we also pro pose a novel baseline method by constructing three different relationship graphs: spatial re lationship, semantic relationship, and implicit relationship graphs on the image regions, ques tions, and semantic labels. The answer and graph reasoning paths are learned for different questions.
The European Conference on Computer Vision, ECCV 2024
Open-set Domain Adaptation via Joint Error based Multi-class Positive and Unlabeled Learning
Dexuan Zhang, Thomas Westfechtel, Tatsuya Harada
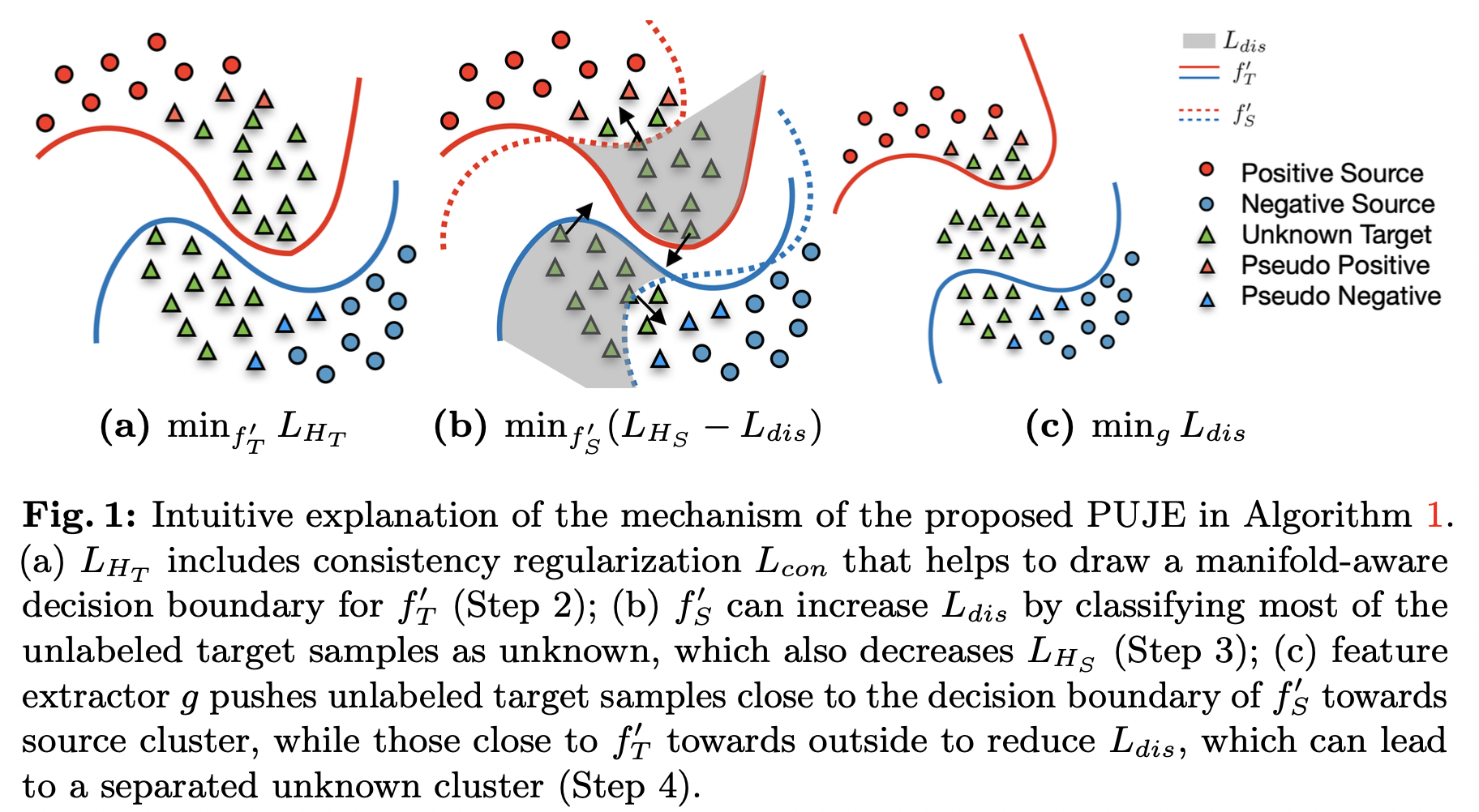 Open-set domain adaptation aims to improve the generalization performance of a learning algorithm on a more realistic problem of open-set domain shift where the target data contains an additional unknown class that is not present in the source data. Most existing algorithms include two phases that can be described as closed-set domain adaptation given heuristic unknown class separation. Therefore, the generalization error cannot be strictly bounded due to the gap between the true distribution and samples inferred from heuristics. In this paper, we propose an end-to-end algorithm that tightly bound the risk of the entire target task by positive-unlabeled (PU) learning theory and the joint error from domain adaptation. Extensive experiments on various data sets demonstrate the effectiveness and efficiency of our proposed algorithm over open-set domain adaptation baselines.
Open-set domain adaptation aims to improve the generalization performance of a learning algorithm on a more realistic problem of open-set domain shift where the target data contains an additional unknown class that is not present in the source data. Most existing algorithms include two phases that can be described as closed-set domain adaptation given heuristic unknown class separation. Therefore, the generalization error cannot be strictly bounded due to the gap between the true distribution and samples inferred from heuristics. In this paper, we propose an end-to-end algorithm that tightly bound the risk of the entire target task by positive-unlabeled (PU) learning theory and the joint error from domain adaptation. Extensive experiments on various data sets demonstrate the effectiveness and efficiency of our proposed algorithm over open-set domain adaptation baselines.
RAW-Adapter: Adapting Pre-trained Visual Model to Camera RAW Images
Ziteng Cui, Tatsuya Harada
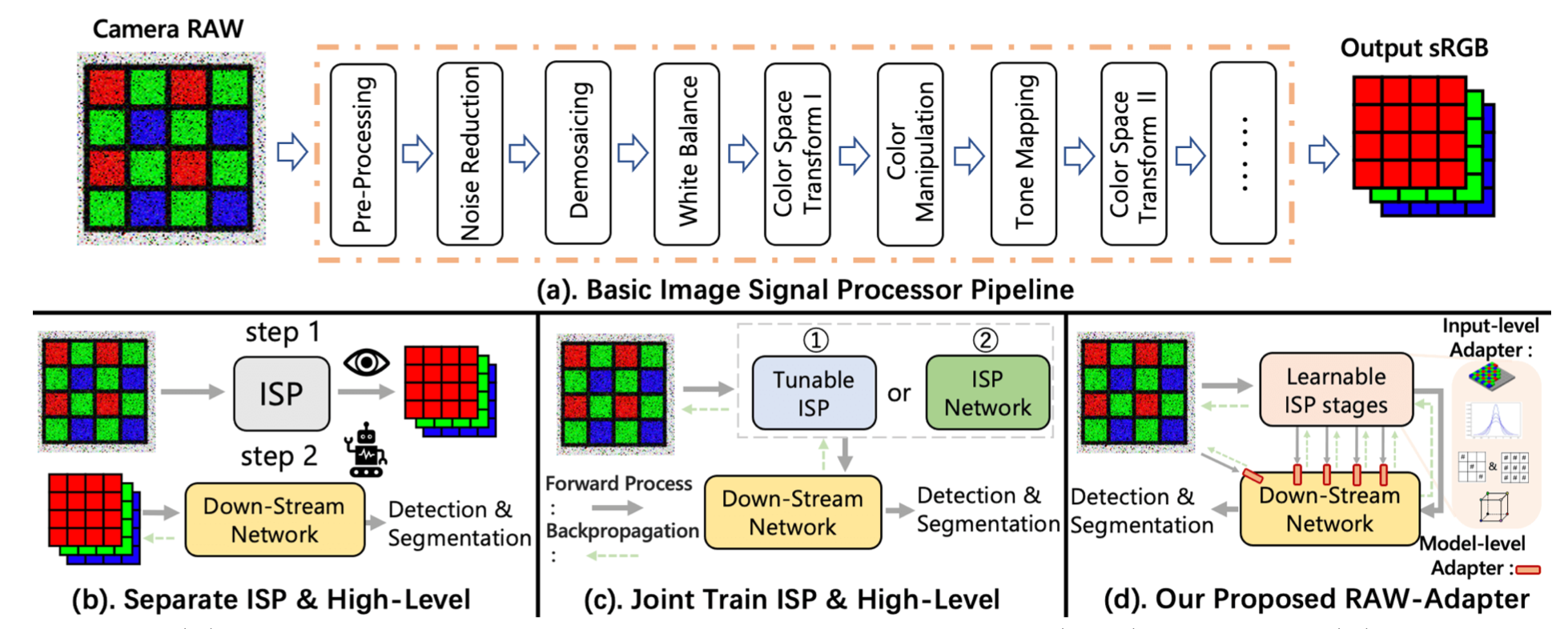 sRGB images are now the predominant choice for pre-training visual models in computer vision research, owing to their ease of acquisition and efficient storage.
Meanwhile, the advantage of RAW images lies in their rich physical information under variable real-world lighting conditions. For computer vision tasks directly based on camera RAW data, most existing studies adopt methods of integrating image signal processor (ISP) with backend networks, yet often overlook the interaction capabilities between the ISP stages and subsequent networks.
Drawing inspiration from ongoing adapter research in NLP and CV areas, we introduce RAW-Adapter, a novel approach aimed at adapting sRGB pre-trained models to camera RAW data. RAW-Adapter comprises input-level adapters that employ learnable ISP stages to adjust RAW inputs, as well as model-level adapters to build connections between ISP stages and subsequent high-level networks.
Additionally, RAW-Adapter is a general framework that could be used in various computer vision frameworks. Abundant experiments under different lighting conditions have shown our algorithm’s state-of-the-art (SOTA) performance, demonstrating its effectiveness and efficiency across a range of real-world and synthetic datasets. Code
sRGB images are now the predominant choice for pre-training visual models in computer vision research, owing to their ease of acquisition and efficient storage.
Meanwhile, the advantage of RAW images lies in their rich physical information under variable real-world lighting conditions. For computer vision tasks directly based on camera RAW data, most existing studies adopt methods of integrating image signal processor (ISP) with backend networks, yet often overlook the interaction capabilities between the ISP stages and subsequent networks.
Drawing inspiration from ongoing adapter research in NLP and CV areas, we introduce RAW-Adapter, a novel approach aimed at adapting sRGB pre-trained models to camera RAW data. RAW-Adapter comprises input-level adapters that employ learnable ISP stages to adjust RAW inputs, as well as model-level adapters to build connections between ISP stages and subsequent high-level networks.
Additionally, RAW-Adapter is a general framework that could be used in various computer vision frameworks. Abundant experiments under different lighting conditions have shown our algorithm’s state-of-the-art (SOTA) performance, demonstrating its effectiveness and efficiency across a range of real-world and synthetic datasets. Code
Artificial Intelligence In Medicine
Can Physician Judgment Enhance Model Trustworthiness? A Case Study on Predicting Pathological Lymph Nodes in Rectal Cancer
Kazuma Kobayashi, Yasuyuki Takamizawa, Mototaka Miyake, Sono Ito, Lin Gu, Tatsuya Nakatsuka, Yu Akagi, Tatsuya Harada, Yukihide Kanemitsu, Ryuji Hamamoto
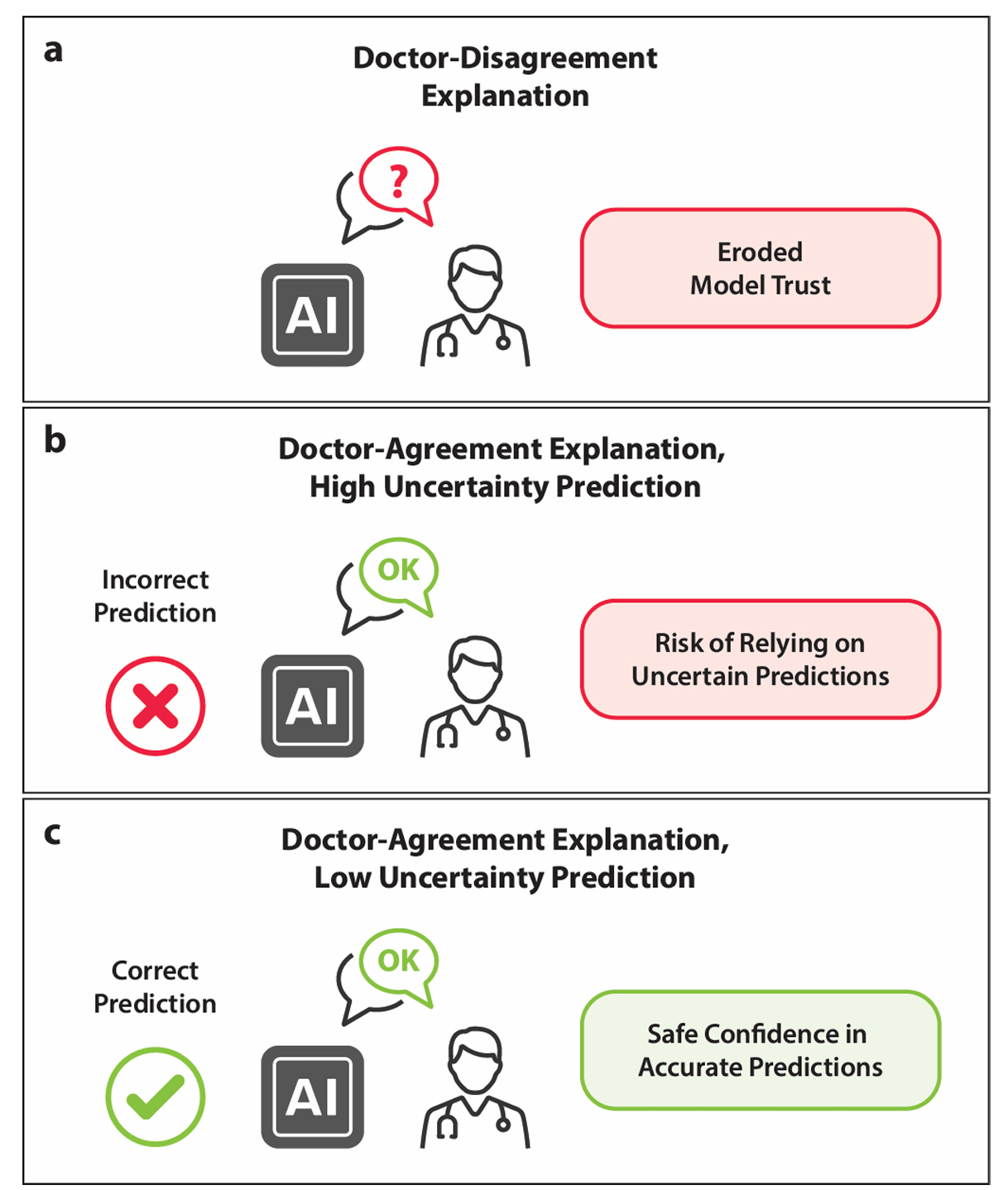 Abstract: Explainability is key to enhancing artificial intelligence’s trustworthiness in medicine. However, several issues remain concern ing the actual benefit of explainable models for clinical decision-making. Firstly, there is a lack of consensus on an evaluation framework for quantitatively assessing the practical benefits that effective explainability should provide to practitioners. Secondly, physician-centered evaluations of explainability are limited. Thirdly, the utility of built-in attention mechanisms in transformer based models as an explainability technique is unclear. We hypothesize that superior attention maps should align with the in formation that physicians focus on, potentially reducing prediction uncertainty and increasing model reliability. We employed a multimodal transformer to predict lymph node metastasis in rectal cancer using clinical data and magnetic resonance imaging, exploring how well attention maps, visualized through a state-of-the-art technique, can achieve agreement with physician under standing. We estimated the model’s uncertainty using meta-level information like prediction probability variance and quantified agreement. Our assessment of whether this agreement reduces uncertainty found no significant effect. In conclusion, this case study did not confirm the anticipated benefit of attention maps in enhancing model reliability. Superficial explanations could do more harm than good by misleading physicians into relying on uncertain predictions, suggesting that the current state of atten tion mechanisms in explainability should not be overestimated. Identifying explainability mechanisms truly beneficial for clinical decision-making remains essential.
Abstract: Explainability is key to enhancing artificial intelligence’s trustworthiness in medicine. However, several issues remain concern ing the actual benefit of explainable models for clinical decision-making. Firstly, there is a lack of consensus on an evaluation framework for quantitatively assessing the practical benefits that effective explainability should provide to practitioners. Secondly, physician-centered evaluations of explainability are limited. Thirdly, the utility of built-in attention mechanisms in transformer based models as an explainability technique is unclear. We hypothesize that superior attention maps should align with the in formation that physicians focus on, potentially reducing prediction uncertainty and increasing model reliability. We employed a multimodal transformer to predict lymph node metastasis in rectal cancer using clinical data and magnetic resonance imaging, exploring how well attention maps, visualized through a state-of-the-art technique, can achieve agreement with physician under standing. We estimated the model’s uncertainty using meta-level information like prediction probability variance and quantified agreement. Our assessment of whether this agreement reduces uncertainty found no significant effect. In conclusion, this case study did not confirm the anticipated benefit of attention maps in enhancing model reliability. Superficial explanations could do more harm than good by misleading physicians into relying on uncertain predictions, suggesting that the current state of atten tion mechanisms in explainability should not be overestimated. Identifying explainability mechanisms truly beneficial for clinical decision-making remains essential.
AI for Content Creation Workshop @ CVPR 2024
The Lost Melody: Empirical Observations on Text-to-Video Generation From A Storytelling Perspective
Andrew Shin, Yusuke Mori, Kunitake Kaneko
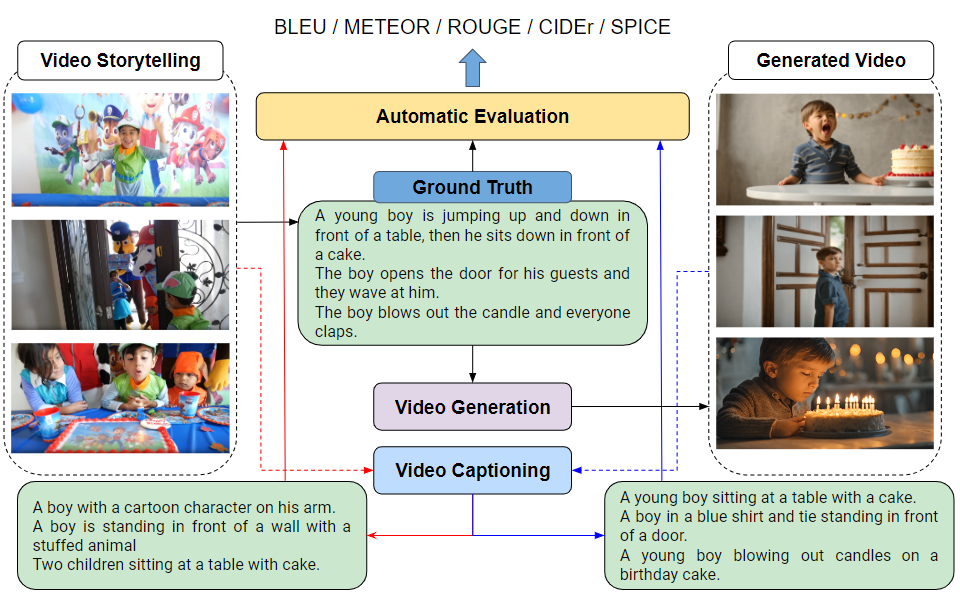 Text-to-video generation task has witnessed a notable progress, with the generated outcomes reflecting the text prompts with high fidelity and impressive visual qualities. However, current text-to-video generation models are invariably focused on conveying the visual elements of a single scene, and have so far been indifferent to another important potential of the medium, namely a storytelling. In this paper, we examine text-to-video generation from a storytelling perspective, which has been hardly investigated, and make empirical remarks that spotlight the limitations of current text-to-video generation scheme. We also propose an evaluation framework for storytelling aspects of videos, and discuss the potential future directions.
Text-to-video generation task has witnessed a notable progress, with the generated outcomes reflecting the text prompts with high fidelity and impressive visual qualities. However, current text-to-video generation models are invariably focused on conveying the visual elements of a single scene, and have so far been indifferent to another important potential of the medium, namely a storytelling. In this paper, we examine text-to-video generation from a storytelling perspective, which has been hardly investigated, and make empirical remarks that spotlight the limitations of current text-to-video generation scheme. We also propose an evaluation framework for storytelling aspects of videos, and discuss the potential future directions.
In Proceedings of the Reinforcement Learning Conference (RLC), 2024
Stabilizing Extreme Q-learning by Maclaurin Expansion
Motoki Omura, Takayuki Osa, Yusuke Mukuta, Tatsuya Harada
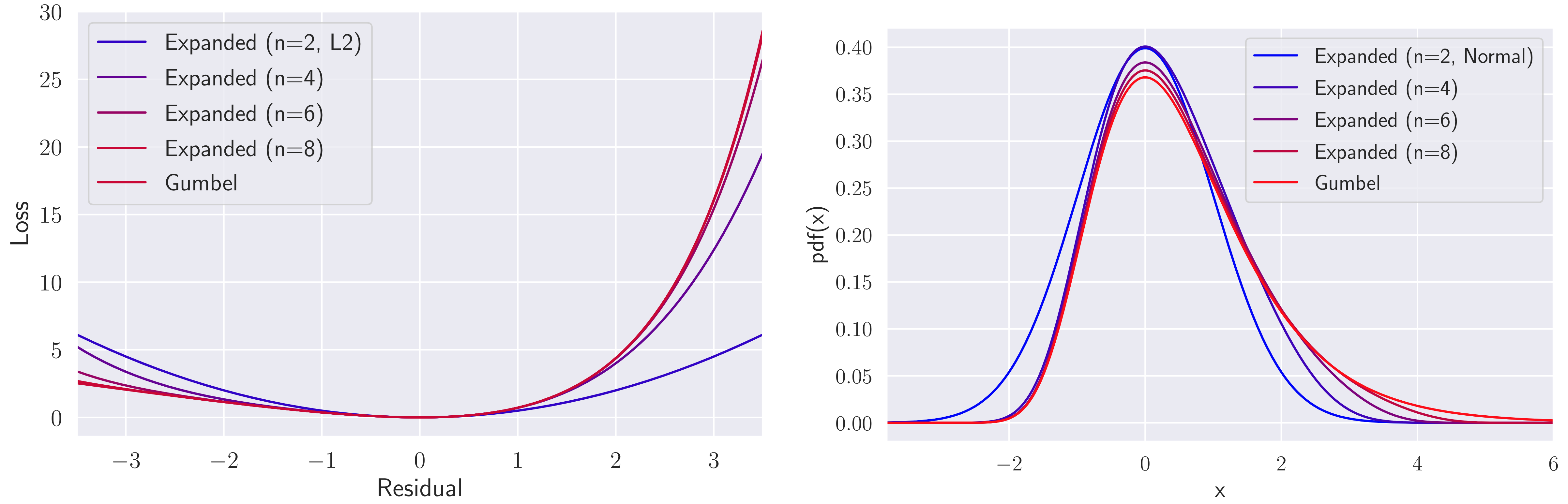 In Extreme Q-learning (XQL), Gumbel Regression is performed with an assumed Gumbel distribution for the error distribution. This allows learning of the value function without sampling out-of-distribution actions and has shown excellent performance mainly in Offline RL. However, issues remained, including the exponential term in the loss function causing instability and the potential for an error distribution diverging from the Gumbel distribution. Therefore, we propose Maclaurin Expanded Extreme Q-learning to enhance stability. In this method, applying Maclaurin expansion to the loss function in XQL enhances stability against large errors. It also allows adjusting the error distribution assumption from normal to Gumbel based on the expansion order. Our method significantly stabilizes learning in Online RL tasks from DM Control, where XQL was previously unstable. Additionally, it improves performance in several Offline RL tasks from D4RL, where XQL already showed excellent results.
In Extreme Q-learning (XQL), Gumbel Regression is performed with an assumed Gumbel distribution for the error distribution. This allows learning of the value function without sampling out-of-distribution actions and has shown excellent performance mainly in Offline RL. However, issues remained, including the exponential term in the loss function causing instability and the potential for an error distribution diverging from the Gumbel distribution. Therefore, we propose Maclaurin Expanded Extreme Q-learning to enhance stability. In this method, applying Maclaurin expansion to the loss function in XQL enhances stability against large errors. It also allows adjusting the error distribution assumption from normal to Gumbel based on the expansion order. Our method significantly stabilizes learning in Online RL tasks from DM Control, where XQL was previously unstable. Additionally, it improves performance in several Offline RL tasks from D4RL, where XQL already showed excellent results.
第27回 画像の認識・理解シンポジウム (MIRU2024), 口頭発表論文, 査読付き
スパイキングニューラルネットワークによる画像生成拡散モデル
Ryo Watanabe, Yusuke Mukuta, Tatsuya Harada
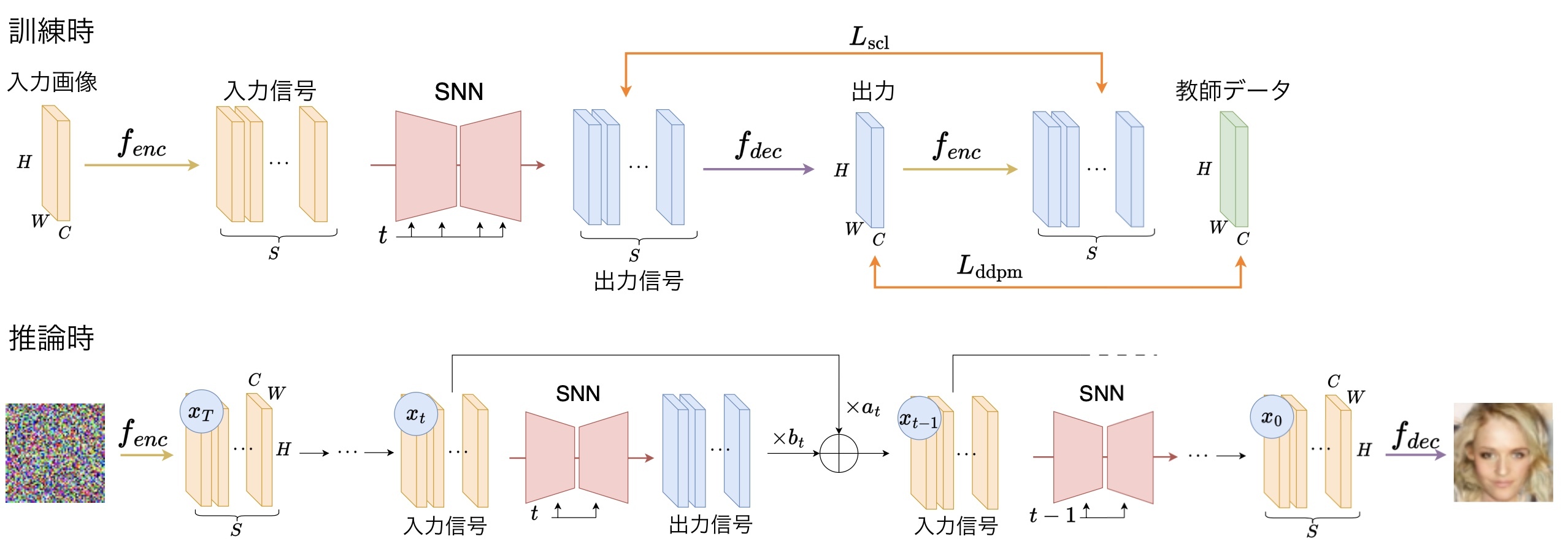 スパイキングニューラルネットワーク(SNN)はその計算効率の高さから近年注目を集めている.拡散モデルは拡散過程の逆過程を学習する生成モデルであり,高性能な画像生成が可能だが計算コストが高い.そこで本研究では,提案するシナプス電流学習(SCL)によりSNNのみで完結する拡散モデルを実現した.実験では提案手法が既存の画像生成手法より優れていることを示し,ANNに比べ消費電力が小さいことを確認した.
スパイキングニューラルネットワーク(SNN)はその計算効率の高さから近年注目を集めている.拡散モデルは拡散過程の逆過程を学習する生成モデルであり,高性能な画像生成が可能だが計算コストが高い.そこで本研究では,提案するシナプス電流学習(SCL)によりSNNのみで完結する拡散モデルを実現した.実験では提案手法が既存の画像生成手法より優れていることを示し,ANNに比べ消費電力が小さいことを確認した.
2nd Workshop on MAD-Games: Multi-Agent Dynamic Games, ICRA 2024
RallySim : Simulated Environment with Continuous Control for Turn-based Multi-agent Reinforcement Learning
Shun Yoshikawa, Yusuke Mukuta, Takayuki Osa, Tatsuya Harada
 Multi-agent reinforcement learning has been considered a promising approach to train agents for tasks that involve cooperative and competitive interactions between players. Several games have already been used as multi-agent problems, and studies have proven that existing reinforcement learning methods along with the multi-agent architecture can get an agent with satisfied behavior. However, the difficulty of the existing multiagent tasks is modest in that they usually have as small and discrete action spaces as game controller inputs. There need to be more multi-agent tasks with complicated continuous control. In this paper, we propose a customized multi-agent environment, RallySim, where agents play a task that is inspired by rally sports. In this task, two player robots placed on a court are supposed to hit a ball with their end effectors to perform multiple exchanges of the ball between them. It entails both the learning of motor-skills and strategies, a factor that the existing tasks do not contain. We use hierarchical reinforcement learning for training an agent for the RallySim task, and the evaluation results show that outperforms agents trained with ordinary architecture. Link
Multi-agent reinforcement learning has been considered a promising approach to train agents for tasks that involve cooperative and competitive interactions between players. Several games have already been used as multi-agent problems, and studies have proven that existing reinforcement learning methods along with the multi-agent architecture can get an agent with satisfied behavior. However, the difficulty of the existing multiagent tasks is modest in that they usually have as small and discrete action spaces as game controller inputs. There need to be more multi-agent tasks with complicated continuous control. In this paper, we propose a customized multi-agent environment, RallySim, where agents play a task that is inspired by rally sports. In this task, two player robots placed on a court are supposed to hit a ball with their end effectors to perform multiple exchanges of the ball between them. It entails both the learning of motor-skills and strategies, a factor that the existing tasks do not contain. We use hierarchical reinforcement learning for training an agent for the RallySim task, and the evaluation results show that outperforms agents trained with ordinary architecture. Link
Index Terms—Multi-Agent Systems, Deep Reinforcement Learning
Proceeding of the International Conference on Machine Learning (ICML), 2024
Discovering Multiple Solutions from a Single Task in Offline Reinforcement Learning
Takayuki Osa and Tatsuya Harada
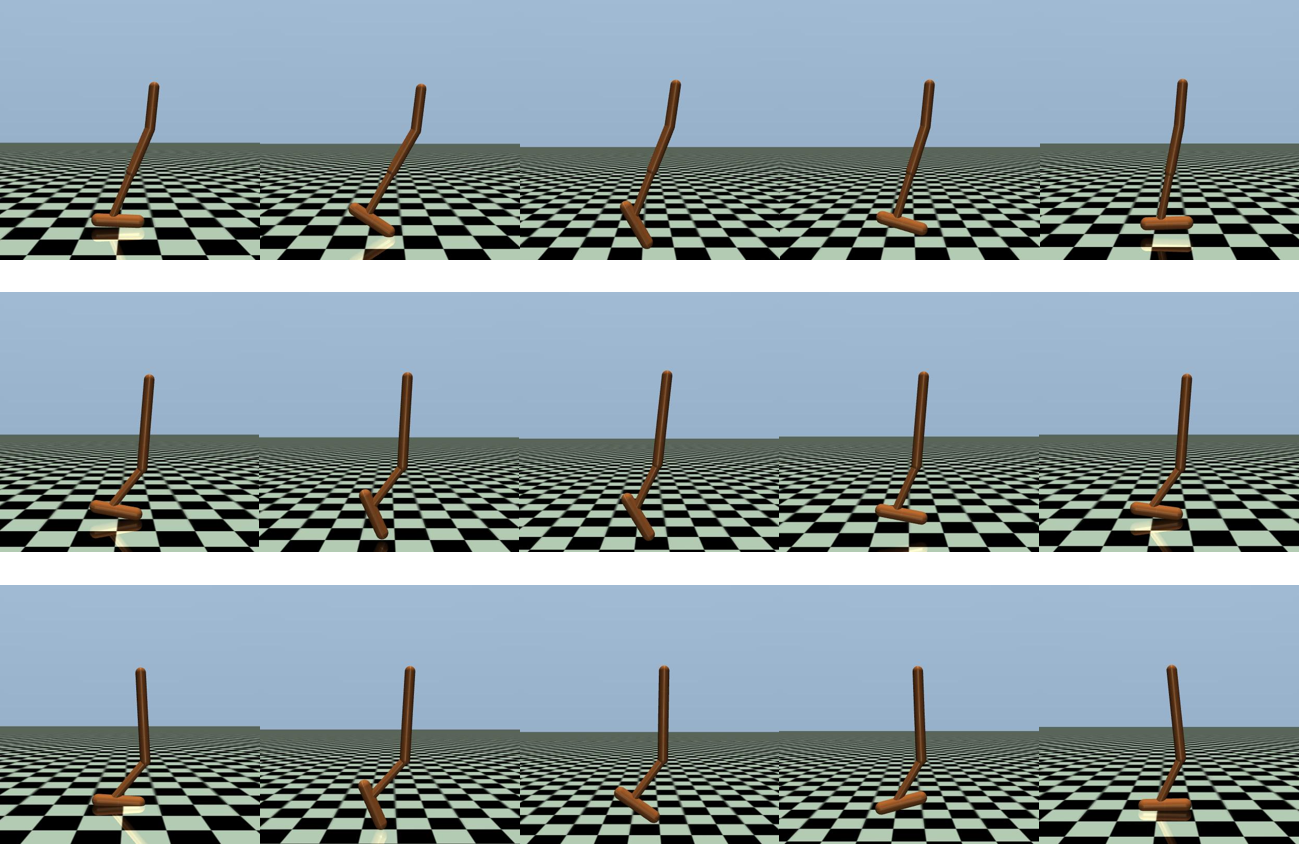 Recent studies on online reinforcement learning (RL) have demonstrated the advantages of learning multiple behaviors from a single task, as in the case of few-shot adaptation to a new environment. Although this approach is expected to yield similar benefits in offline RL, appropriate methods for learning multiple solutions have not been fully investigated in previous studies. In this study, we therefore addressed the problem of learning multiple solutions in offline RL. We propose algorithms that can learn multiple solutions in offline RL, and empirically investigate their performance. Our experimental results show that the proposed algorithm learns multiple qualitatively and quantitatively distinctive solutions in offline RL.
Recent studies on online reinforcement learning (RL) have demonstrated the advantages of learning multiple behaviors from a single task, as in the case of few-shot adaptation to a new environment. Although this approach is expected to yield similar benefits in offline RL, appropriate methods for learning multiple solutions have not been fully investigated in previous studies. In this study, we therefore addressed the problem of learning multiple solutions in offline RL. We propose algorithms that can learn multiple solutions in offline RL, and empirically investigate their performance. Our experimental results show that the proposed algorithm learns multiple qualitatively and quantitatively distinctive solutions in offline RL.
Transactions of the International Society for Music Information Retrieval (ISMIR), April 2024
The Sound Demixing Challenge 2023 – Music Demixing Track
Fabbro, Giorgio and Uhlich, Stefan and Lai, Chieh-Hsin and Choi, Woosung and Martínez-Ramírez, Marco and Liao, Weihsiang and Gadelha, Igor and Ramos, Geraldo and Hsu, Eddie and Rodrigues, Hugo and Stöter, Fabian-Robert and Défossez, Alexandre and Luo, Yi and Yu, Jianwei and Chakraborty, Dipam and Mohanty, Sharada and Solovyev, Roman and Stempkovskiy, Alexander and Habruseva, Tatiana and Goswami, Nabarun and Harada, Tatsuya and Kim, Minseok and Lee, Jun Hyung and Dong, Yuanliang and Zhang, Xinran and Liu, Jiafeng and Mitsufuji, Yuki
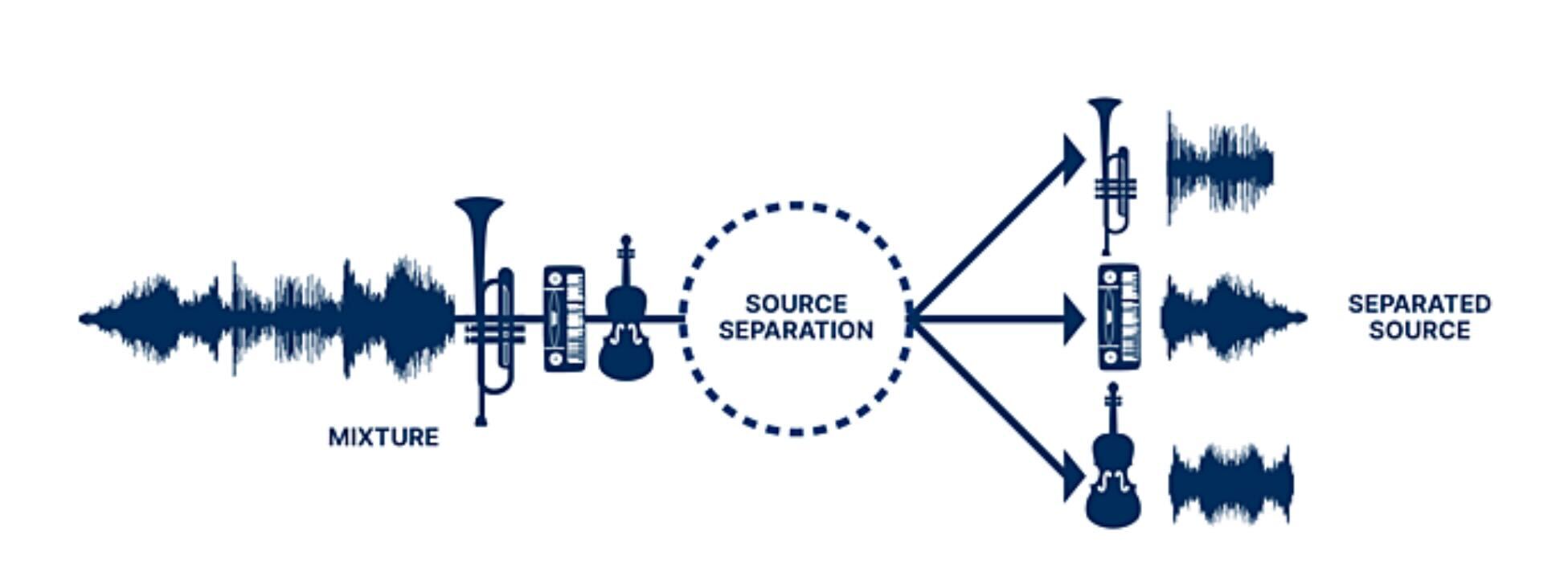 This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers and musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions. Link
This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers and musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions. Link
Proceedings of the IEEE International Conferences on Robotics and Automation (ICRA), 2024
Robustifying a Policy in Multi-Agent RL with Diverse Cooperative Behavior and Adversarial Style Sampling for Assistive Tasks
Takayuki Osa and Tatsuya Harada
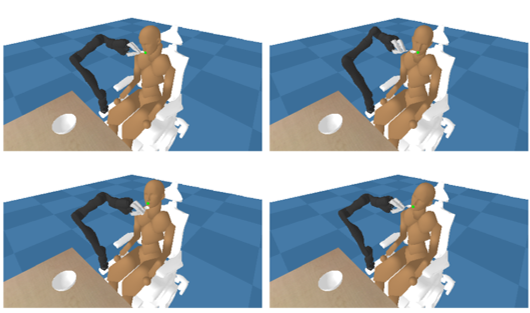 Autonomous assistance of people with motor impairments is one of the most promising applications of autonomous robotic systems. Recent studies have reported encouraging results using deep reinforcement learning (RL) in the healthcare domain. Previous studies showed that assistive tasks can be formulated as multi-agent RL, wherein there are two agents: a caregiver and a care-receiver. However, policies trained in multi-agent RL are often sensitive to the policies of other agents. In such a case, a trained caregiver’s policy may not work for different care-receivers. To alleviate this issue, we propose a framework that learns a robust caregiver’s policy by training it for diverse care-receiver responses. In our framework, diverse care-receiver responses are autonomously learned through trials and errors. In addition, to robustify the care-giver’s policy, we propose a strategy for sampling a care-receiver’s response in an adversarial manner during the training. We evaluated the proposed method using tasks in an Assistive Gym. We demonstrate that policies trained with a popular deep RL method are vulnerable to changes in policies of other agents and that the proposed framework improves the robustness against such changes.
Autonomous assistance of people with motor impairments is one of the most promising applications of autonomous robotic systems. Recent studies have reported encouraging results using deep reinforcement learning (RL) in the healthcare domain. Previous studies showed that assistive tasks can be formulated as multi-agent RL, wherein there are two agents: a caregiver and a care-receiver. However, policies trained in multi-agent RL are often sensitive to the policies of other agents. In such a case, a trained caregiver’s policy may not work for different care-receivers. To alleviate this issue, we propose a framework that learns a robust caregiver’s policy by training it for diverse care-receiver responses. In our framework, diverse care-receiver responses are autonomously learned through trials and errors. In addition, to robustify the care-giver’s policy, we propose a strategy for sampling a care-receiver’s response in an adversarial manner during the training. We evaluated the proposed method using tasks in an Assistive Gym. We demonstrate that policies trained with a popular deep RL method are vulnerable to changes in policies of other agents and that the proposed framework improves the robustness against such changes.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration (173 authors, including Takayuki Osa, Yujin Tang, and Tatsuya Harada)
 Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train “generalist” X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms.
Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train “generalist” X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms.
The 12th International Conference on Learning Representations (ICLR), 2024
GPAvatar: Generalizable and Precise Head Avatar from Image(s)
Xuangeng Chu, Yu Li, Ailing Zeng, Tianyu Yang, Lijian Lin, Yunfei Liu, Tatsuya Harada
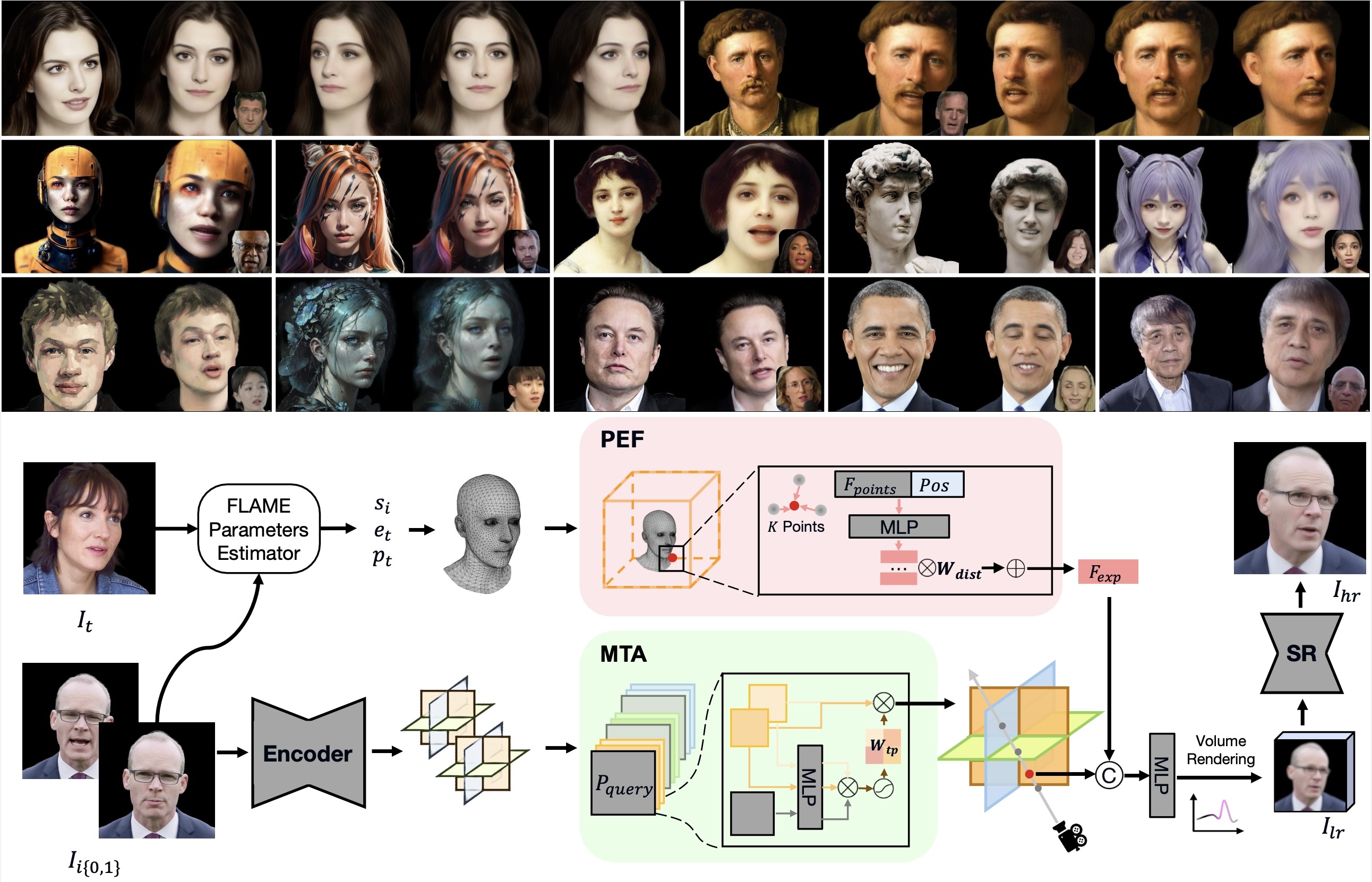 Head avatar reconstruction, crucial for applications in virtual reality, online meetings, gaming, and film industries, has garnered substantial attention within the computer vision community. The fundamental objective of this field is to faithfully recreate the head avatar and precisely control expressions and postures. Existing methods, categorized into 2D-based warping, mesh-based, and neural rendering approaches, present challenges in maintaining multi-view consistency, incorporating non-facial information, and generalizing to new identities. In this paper, we propose a framework named GPAvatar that reconstructs 3D head avatars from one or several images in a single forward pass. The key idea of this work is to introduce a dynamic point-based expression field driven by a point cloud to precisely and effectively capture expressions. Furthermore, we use a Multi Tri-planes Attention (MTA) fusion module in tri-planes canonical field to leverage information from multiple input images. The proposed method achieves faithful identity reconstruction, precise expression control, and multi-view consistency, demonstrating promising results for free-viewpoint rendering and novel view synthesis.
Head avatar reconstruction, crucial for applications in virtual reality, online meetings, gaming, and film industries, has garnered substantial attention within the computer vision community. The fundamental objective of this field is to faithfully recreate the head avatar and precisely control expressions and postures. Existing methods, categorized into 2D-based warping, mesh-based, and neural rendering approaches, present challenges in maintaining multi-view consistency, incorporating non-facial information, and generalizing to new identities. In this paper, we propose a framework named GPAvatar that reconstructs 3D head avatars from one or several images in a single forward pass. The key idea of this work is to introduce a dynamic point-based expression field driven by a point cloud to precisely and effectively capture expressions. Furthermore, we use a Multi Tri-planes Attention (MTA) fusion module in tri-planes canonical field to leverage information from multiple input images. The proposed method achieves faithful identity reconstruction, precise expression control, and multi-view consistency, demonstrating promising results for free-viewpoint rendering and novel view synthesis.
Medical Image Analysis
Sketch-based semantic retrieval of medical images
Kazuma Kobayashi, Lin Gu, Ryuichiro Hataya, Takaaki Mizuno, Mototaka Miyake, Hirokazu Watanabe, Masamichi Takahashi, Yasuyuki Takamizawa, Yukihiro Yoshida, Satoshi Nakamura, Nobuji Kouno, Amina Bolatkan, Yusuke Kurose, Tatsuya Harada, Ryuji Hamamoto
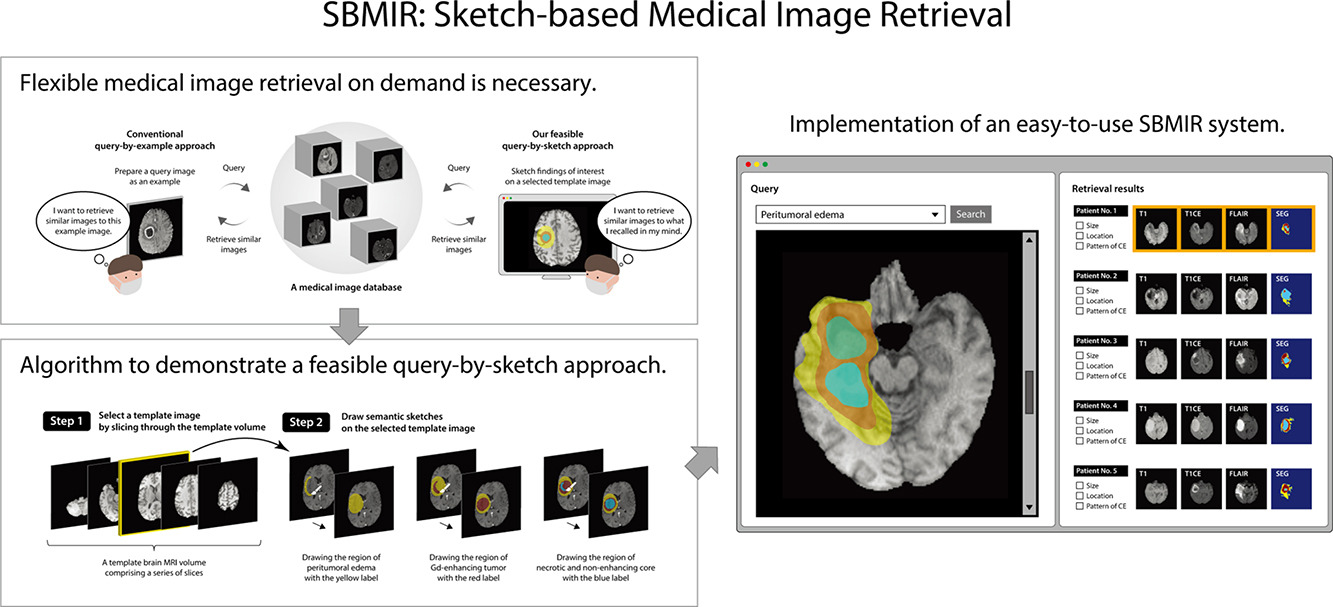 The volume of medical images stored in hospitals is rapidly increasing; however, the utilization of these accumulated medical images remains limited. Existing content-based medical image retrieval (CBMIR) systems typically require example images, leading to practical limitations, such as the lack of customizable, fine-grained image retrieval, the inability to search without example images, and difficulty in retrieving rare cases. In this paper, we introduce a sketch-based medical image retrieval (SBMIR) system that enables users to find images of interest without the need for example images. The key concept is feature decomposition of medical images, which allows the entire feature of a medical image to be decomposed into and reconstructed from normal and abnormal features. Building on this concept, our SBMIR system provides an easy-to-use two-step graphical user interface: users first select a template image to specify a normal feature and then draw a semantic sketch of the disease on the template image to represent an abnormal feature. The system integrates both types of input to construct a query vector and retrieves reference images. For evaluation, ten healthcare professionals participated in a user test using two datasets. Consequently, our SBMIR system enabled users to overcome previous challenges, including image retrieval based on fine-grained image characteristics, image retrieval without example images, and image retrieval for rare cases. Our SBMIR system provides on-demand, customizable medical image retrieval, thereby expanding the utility of medical image databases.
The volume of medical images stored in hospitals is rapidly increasing; however, the utilization of these accumulated medical images remains limited. Existing content-based medical image retrieval (CBMIR) systems typically require example images, leading to practical limitations, such as the lack of customizable, fine-grained image retrieval, the inability to search without example images, and difficulty in retrieving rare cases. In this paper, we introduce a sketch-based medical image retrieval (SBMIR) system that enables users to find images of interest without the need for example images. The key concept is feature decomposition of medical images, which allows the entire feature of a medical image to be decomposed into and reconstructed from normal and abnormal features. Building on this concept, our SBMIR system provides an easy-to-use two-step graphical user interface: users first select a template image to specify a normal feature and then draw a semantic sketch of the disease on the template image to represent an abnormal feature. The system integrates both types of input to construct a query vector and retrieves reference images. For evaluation, ten healthcare professionals participated in a user test using two datasets. Consequently, our SBMIR system enabled users to overcome previous challenges, including image retrieval based on fine-grained image characteristics, image retrieval without example images, and image retrieval for rare cases. Our SBMIR system provides on-demand, customizable medical image retrieval, thereby expanding the utility of medical image databases.
IJCV Special Issue on Multimodal Learning
Learning by Asking Questions for Knowledge-based Novel Object Recognition
Motoki Omura, Takayuki Osa, Yusuke Mukuta, Tatsuya Harada
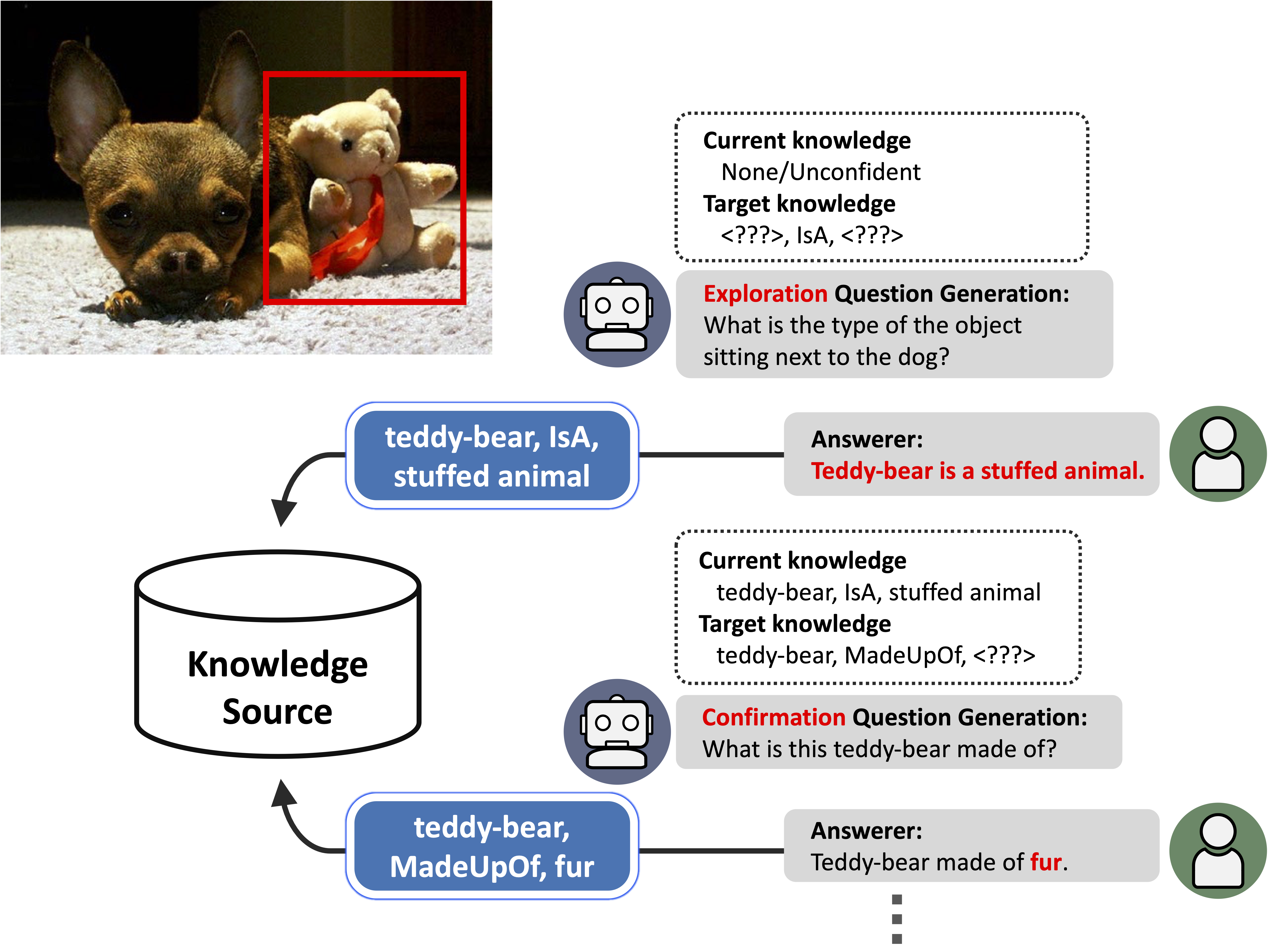 In real-world object recognition, there are numerous object classes to be recognized. Traditional image recognition methods based on supervised learning can only recognize object classes present in the training data, and have limited applicability in the real world. In contrast, humans can recognize novel objects by questioning and acquiring knowledge about them. Inspired by this, we propose a framework for acquiring external knowledge by generating questions that enable the model to instantly recognize novel objects. Our framework comprises three components: the Object Classifier (OC), which performs knowledge-based object recognition, the Question Generator (QG), which generates knowledge-aware questions to acquire novel knowledge, and the Policy Decision (PD) Model, which determines the
In real-world object recognition, there are numerous object classes to be recognized. Traditional image recognition methods based on supervised learning can only recognize object classes present in the training data, and have limited applicability in the real world. In contrast, humans can recognize novel objects by questioning and acquiring knowledge about them. Inspired by this, we propose a framework for acquiring external knowledge by generating questions that enable the model to instantly recognize novel objects. Our framework comprises three components: the Object Classifier (OC), which performs knowledge-based object recognition, the Question Generator (QG), which generates knowledge-aware questions to acquire novel knowledge, and the Policy Decision (PD) Model, which determines the policy'' of questions to be asked. The PD model utilizes two strategies, namely confirmation'' and ``exploration'' --- the former confirms candidate knowledge while the latter explores completely new knowledge. Our experiments demonstrate that the proposed pipeline effectively acquires knowledge about novel objects compared to several baselines, and realizes novel object recognition utilizing the obtained knowledge. We also performed a real-world evaluation in which humans responded to the generated questions, and the model used the acquired knowledge to retrain the OC, which is a fundamental step toward a real-world human-in-the-loop learning-by-asking framework.
AAAI Conference on Artificial Intelligence (AAAI-24)
Symmetric Q-Learning: Reducing Skewness of Bellman Error in Online Reinforcement Learning
Motoki Omura, Takayuki Osa, Yusuke Mukuta, Tatsuya Harada
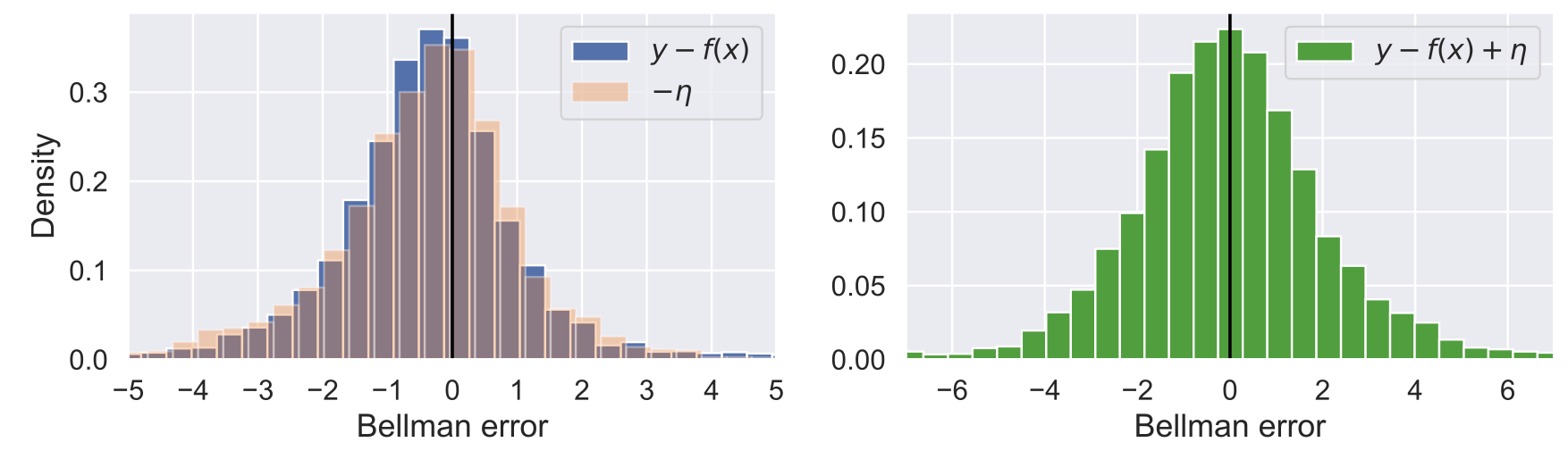 In deep reinforcement learning, estimating the value function to evaluate the quality of states and actions is essential. The value function is often trained using the least squares method, which implicitly assumes a Gaussian error distribution. However, a recent study suggested that the error distribution for training the value function is often skewed because of the properties of the Bellman operator, and violates the implicit assumption of normal error distribution in the least squares method. To address this, we proposed a method called Symmetric Q-learning, in which the synthetic noise generated from a zero-mean distribution is added to the target values to generate a Gaussian error distribution. We evaluated the proposed method on continuous control benchmark tasks in MuJoCo. It improved the sample efficiency of a state-of-the-art reinforcement learning method by reducing the skewness of the error distribution.
In deep reinforcement learning, estimating the value function to evaluate the quality of states and actions is essential. The value function is often trained using the least squares method, which implicitly assumes a Gaussian error distribution. However, a recent study suggested that the error distribution for training the value function is often skewed because of the properties of the Bellman operator, and violates the implicit assumption of normal error distribution in the least squares method. To address this, we proposed a method called Symmetric Q-learning, in which the synthetic noise generated from a zero-mean distribution is added to the target values to generate a Gaussian error distribution. We evaluated the proposed method on continuous control benchmark tasks in MuJoCo. It improved the sample efficiency of a state-of-the-art reinforcement learning method by reducing the skewness of the error distribution.
Aleth-NeRF: Illumination Adaptive NeRF with Concealing Field Assumption
Ziteng Cui, Lin Gu, Xiao Sun, Xianzheng Ma, Yu Qiao, Tatsuya Harada
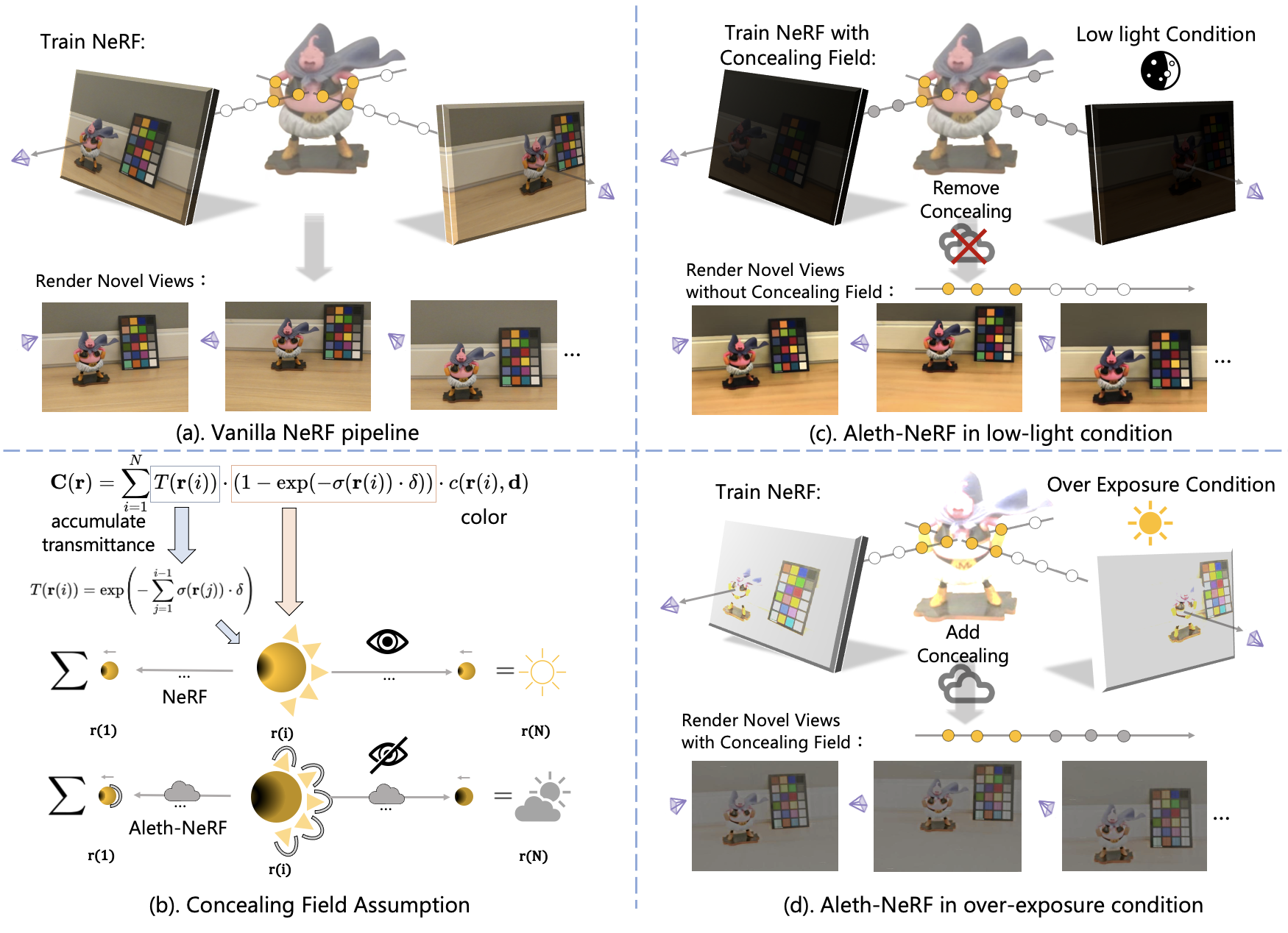 The standard Neural Radiance Fields (NeRF) paradigm employs a viewer-centered methodology, entangling the aspects of illumination and material reflectance into emission solely from 3D points. This simplified rendering approach presents challenges in accurately modeling images captured under adverse lighting conditions, such as low light or over-exposure. Motivated by the ancient Greek emission theory that posits visual perception as a result of rays emanating from the eyes, we slightly refine the conventional NeRF framework to train NeRF under challenging light conditions and generate normal-light condition novel views unsupervised. We introduce the concept of a ”Concealing Field,” which assigns transmittance values to the surrounding air to account for illumination effects. In dark scenarios, we assume that object emissions maintain a standard lighting level but are attenuated as they traverse the air during the rendering process. Concealing Field thus compel NeRF to learn reasonable density and colour estimations for objects even in dimly lit situations. Similarly, the Concealing Field can mitigate over-exposed emissions during the rendering stage. Furthermore, we present a comprehensive multi-view dataset captured under challenging illumination conditions for evaluation.
The standard Neural Radiance Fields (NeRF) paradigm employs a viewer-centered methodology, entangling the aspects of illumination and material reflectance into emission solely from 3D points. This simplified rendering approach presents challenges in accurately modeling images captured under adverse lighting conditions, such as low light or over-exposure. Motivated by the ancient Greek emission theory that posits visual perception as a result of rays emanating from the eyes, we slightly refine the conventional NeRF framework to train NeRF under challenging light conditions and generate normal-light condition novel views unsupervised. We introduce the concept of a ”Concealing Field,” which assigns transmittance values to the surrounding air to account for illumination effects. In dark scenarios, we assume that object emissions maintain a standard lighting level but are attenuated as they traverse the air during the rendering process. Concealing Field thus compel NeRF to learn reasonable density and colour estimations for objects even in dimly lit situations. Similarly, the Concealing Field can mitigate over-exposed emissions during the rendering stage. Furthermore, we present a comprehensive multi-view dataset captured under challenging illumination conditions for evaluation.
Winter Conference on Applications of Computer Vision (WACV), 2024
Gradual Source Domain Expansion for Unsupervised Domain Adaptation
Thomas Westfechtel, Hao-Wei Yeh, Dexuan Zhang, Tatsuya Harada
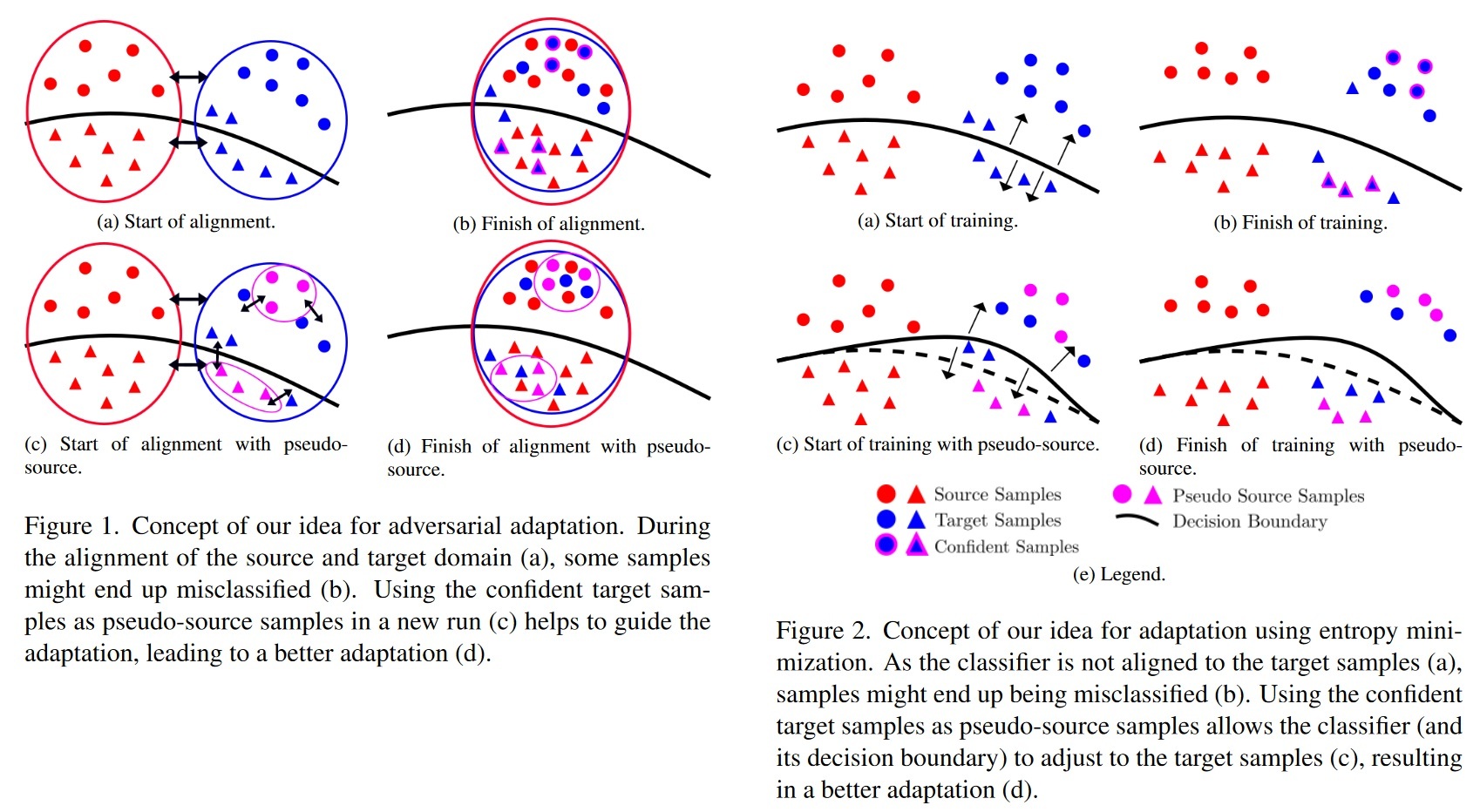 Unsupervised domain adaptation (UDA) tries to overcome the need for a large labeled dataset by transferring
knowledge from a source dataset, with lots of labeled data, to a target dataset, that has no labeled data. Since there are no labels in the target domain, early misalignment might propagate into the later stages and lead to an error build-up. In order to overcome this problem, we propose a gradual source domain expansion (GSDE) algorithm. GSDE trains the UDA task several times from scratch, each time reinitializing the network weights, but each time expands the source dataset with target data. In particular, the highest-scoring target data of the previous run are employed as pseudo-source samples with their respective pseudo-label. Using this strategy, the pseudo-source samples induce knowledge extracted from the previous run directly from the start of the new training. This helps align the two domains better, especially in the early training epochs. In this study, we first introduce a strong baseline network and apply our GSDE strategy to it. We conduct experiments and ablation studies on three benchmarks (Office-31, OfficeHome, and DomainNet) and outperform state-of-the-art methods. We further show that the proposed GSDE strategy can improve the accuracy of a variety of different state-of-the-art UDA approaches.
Unsupervised domain adaptation (UDA) tries to overcome the need for a large labeled dataset by transferring
knowledge from a source dataset, with lots of labeled data, to a target dataset, that has no labeled data. Since there are no labels in the target domain, early misalignment might propagate into the later stages and lead to an error build-up. In order to overcome this problem, we propose a gradual source domain expansion (GSDE) algorithm. GSDE trains the UDA task several times from scratch, each time reinitializing the network weights, but each time expands the source dataset with target data. In particular, the highest-scoring target data of the previous run are employed as pseudo-source samples with their respective pseudo-label. Using this strategy, the pseudo-source samples induce knowledge extracted from the previous run directly from the start of the new training. This helps align the two domains better, especially in the early training epochs. In this study, we first introduce a strong baseline network and apply our GSDE strategy to it. We conduct experiments and ablation studies on three benchmarks (Office-31, OfficeHome, and DomainNet) and outperform state-of-the-art methods. We further show that the proposed GSDE strategy can improve the accuracy of a variety of different state-of-the-art UDA approaches.