Abstracts of papers published in 2023
Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023.
Detection Based Part-level Articulated Object Reconstruction from Single RGBD Image
Yuki Kawana, Tatsuya Harada
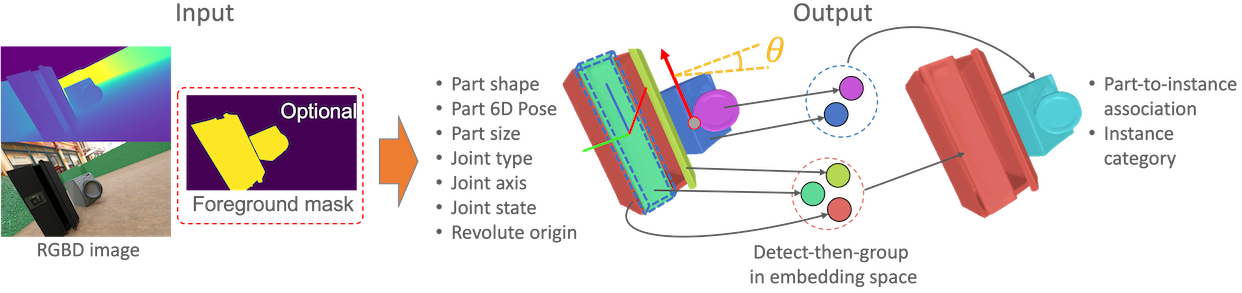 We propose an end-to-end trainable, cross-category method for reconstructing multiple man-made articulated objects from a single RGBD image, focusing on part-level shape reconstruction and pose and kinematics estimation. We depart from previous works that rely on learning instance-level latent space, focusing on man-made articulated objects with predefined part counts. Instead, we propose a novel alternative approach that employs part-level representation, representing instances as combinations of detected parts. While this detect-then-group approach effectively handles instances with diverse part structures and various part counts, it faces issues of false positives, various part sizes and scales, and increasing model size due to end-to-end training. To address these issues, we propose 1) test-time kinematics-aware part fusion that improves detection performance while suppressing false positives, 2) anisotropic scale normalization for part shape learning to accommodate various part sizes and scales, and 3) a balancing strategy for cross-refinement between feature space and output space to improve part detection while maintaining model size. Evaluation on the SAPIEN dataset demonstrates our method successfully reconstructs variously structured multiple instances that previous works cannot handle and outperforms prior works in shape reconstruction and kinematics estimation. We also demonstrate generalization to real data. (Copied directly from current abstract)
We propose an end-to-end trainable, cross-category method for reconstructing multiple man-made articulated objects from a single RGBD image, focusing on part-level shape reconstruction and pose and kinematics estimation. We depart from previous works that rely on learning instance-level latent space, focusing on man-made articulated objects with predefined part counts. Instead, we propose a novel alternative approach that employs part-level representation, representing instances as combinations of detected parts. While this detect-then-group approach effectively handles instances with diverse part structures and various part counts, it faces issues of false positives, various part sizes and scales, and increasing model size due to end-to-end training. To address these issues, we propose 1) test-time kinematics-aware part fusion that improves detection performance while suppressing false positives, 2) anisotropic scale normalization for part shape learning to accommodate various part sizes and scales, and 3) a balancing strategy for cross-refinement between feature space and output space to improve part detection while maintaining model size. Evaluation on the SAPIEN dataset demonstrates our method successfully reconstructs variously structured multiple instances that previous works cannot handle and outperforms prior works in shape reconstruction and kinematics estimation. We also demonstrate generalization to real data. (Copied directly from current abstract)
International Conference on Computer Vision (ICCV) 2023
Name Your Colour For the Task: Artificially Discover Colour Naming via Colour Quantisation Transformer
Shenghan Su, Lin Gu, Yue Yang, Zenghui Zhang, Tatsuya Harada
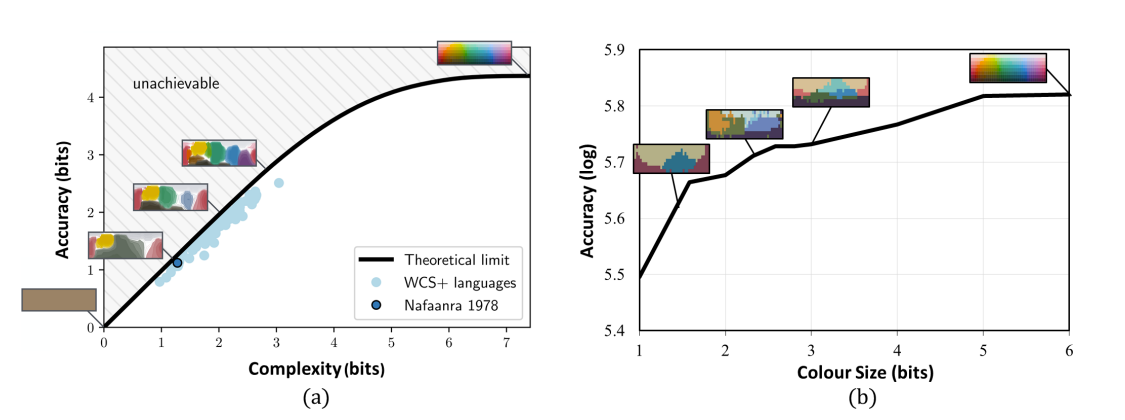 The long-standing theory that a colour-naming system evolves under dual pressure of efficient communication and perceptual mechanism is supported by more and more linguistic studies, including analysing four decades of diachronic data from the Nafaanra language. This inspires us to explore whether machine learning could evolve and discover a similar colour-naming system via optimising the communication efficiency represented by high-level recognition performance. Here, we propose a novel colour quantisation transformer, CQFormer, that quantises colour space while maintaining the accuracy of machine recognition on the quantised images. Given an RGB image, Annotation Branch maps it into an index map before generating the quantised image with a colour palette; meanwhile the Palette Branch utilises a key-point detection way to find proper colours in the palette among the whole colour space. By interacting with colour annotation, CQFormer is able to balance both the machine vision accuracy and colour perceptual structure such as distinct and stable colour distribution for discovered colour system. Very interestingly, we even observe the consistent evolution pattern between our artificial colour system and basic colour terms across human languages. Besides, our colour quantisation method also offers an efficient quantisation method that effectively compresses the image storage while maintaining high performance in high-level recognition tasks such as classification and detection. Extensive experiments demonstrate the superior performance of our method with extremely low bit-rate colours, showing potential to integrate into quantisation network to quantities from image to network activation.
The long-standing theory that a colour-naming system evolves under dual pressure of efficient communication and perceptual mechanism is supported by more and more linguistic studies, including analysing four decades of diachronic data from the Nafaanra language. This inspires us to explore whether machine learning could evolve and discover a similar colour-naming system via optimising the communication efficiency represented by high-level recognition performance. Here, we propose a novel colour quantisation transformer, CQFormer, that quantises colour space while maintaining the accuracy of machine recognition on the quantised images. Given an RGB image, Annotation Branch maps it into an index map before generating the quantised image with a colour palette; meanwhile the Palette Branch utilises a key-point detection way to find proper colours in the palette among the whole colour space. By interacting with colour annotation, CQFormer is able to balance both the machine vision accuracy and colour perceptual structure such as distinct and stable colour distribution for discovered colour system. Very interestingly, we even observe the consistent evolution pattern between our artificial colour system and basic colour terms across human languages. Besides, our colour quantisation method also offers an efficient quantisation method that effectively compresses the image storage while maintaining high performance in high-level recognition tasks such as classification and detection. Extensive experiments demonstrate the superior performance of our method with extremely low bit-rate colours, showing potential to integrate into quantisation network to quantities from image to network activation.
Transactions on Machine Learning Research
Unsupervised Domain Adaptation via Minimized Joint Error
Dexuan Zhang, Thomas Westfechtel, Tatsuya Harada
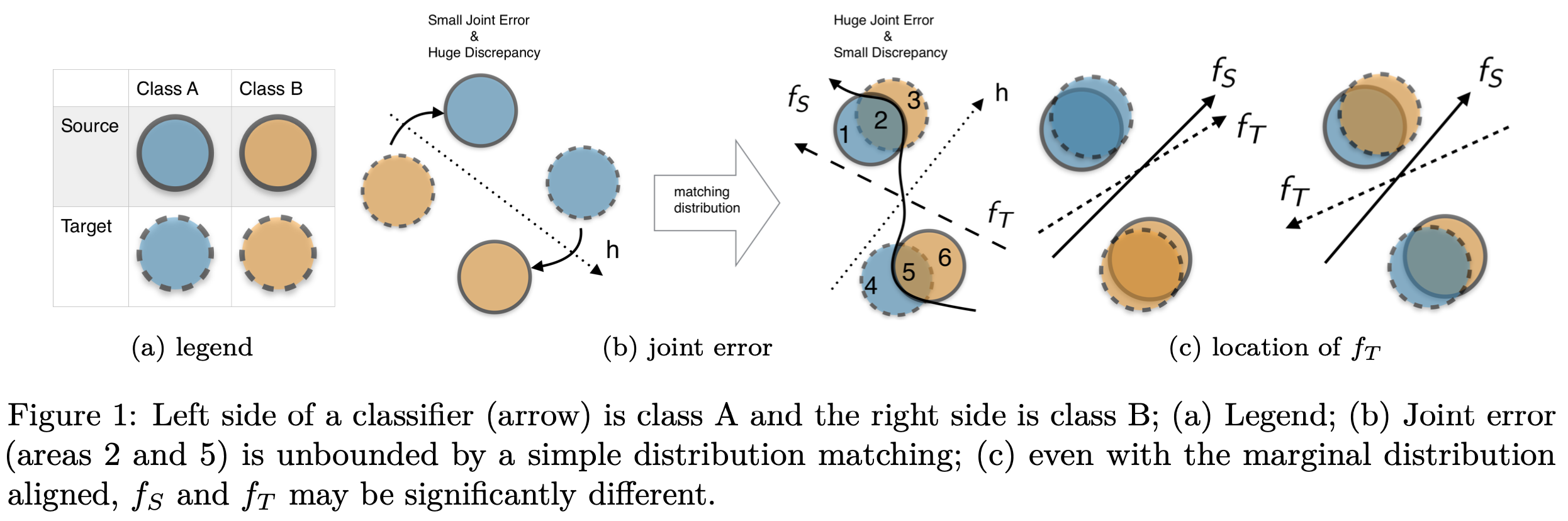 Unsupervised domain adaptation transfers knowledge from a fully labeled source domain to a different target domain, where no labeled data are available. Some researchers have proposed upper bounds for the target error when transferring knowledge. For example, Ben-David et al. (2010) established a theory based on minimizing the source error and distance between marginal distributions simultaneously. However, in most research, the joint error is ignored because of its intractability. In this research, we argue that joint errors are essential for domain adaptation problems, particularly when the domain gap is large. To address this problem, we propose a novel objective related to the upper bound of the joint error. Moreover, we adopt a source/pseudo-target label-induced hypothesis space that can reduce the search space to further tighten this bound. To measure the dissimilarity between hypotheses, we define a novel cross-margin discrepancy to alleviate instability during adversarial learning. In addition, we present extensive empirical evidence showing that the proposed method boosts the performance of image classification accuracy on standard domain adaptation benchmarks.
Unsupervised domain adaptation transfers knowledge from a fully labeled source domain to a different target domain, where no labeled data are available. Some researchers have proposed upper bounds for the target error when transferring knowledge. For example, Ben-David et al. (2010) established a theory based on minimizing the source error and distance between marginal distributions simultaneously. However, in most research, the joint error is ignored because of its intractability. In this research, we argue that joint errors are essential for domain adaptation problems, particularly when the domain gap is large. To address this problem, we propose a novel objective related to the upper bound of the joint error. Moreover, we adopt a source/pseudo-target label-induced hypothesis space that can reduce the search space to further tighten this bound. To measure the dissimilarity between hypotheses, we define a novel cross-margin discrepancy to alleviate instability during adversarial learning. In addition, we present extensive empirical evidence showing that the proposed method boosts the performance of image classification accuracy on standard domain adaptation benchmarks.
Invariant Feature Coding using Tensor Product Representation
Yusuke Mukuta, Tatsuya Harada
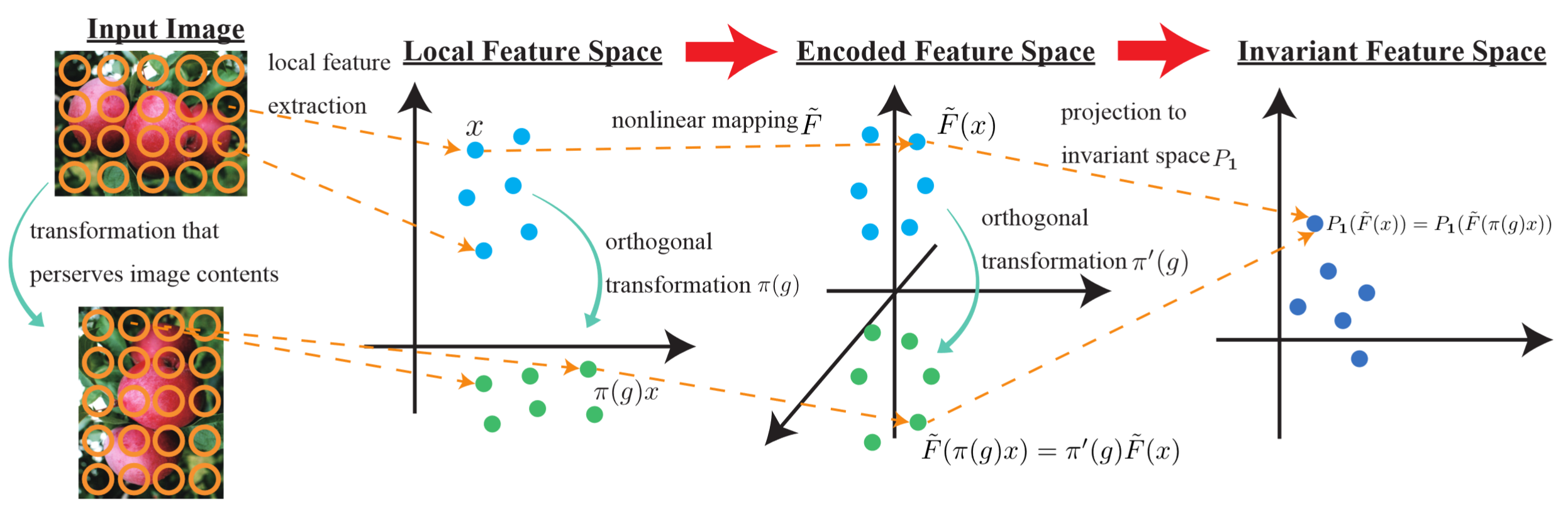 In this study, a novel feature coding method that exploits invariance for transformations represented by a finite group of orthogonal matrices is proposed. We prove that the group-invariant feature vector contains sufficient discriminative information when learning a linear classifier using convex loss minimization. Based on this result, a novel feature model that explicitly considers group action is proposed for principal component analysis and k-means clustering, which are commonly used in most feature coding methods, and global feature functions. Although the global feature functions are in general complex nonlinear functions, the group action on this space can be easily calculated by constructing these functions as tensor-product representations of basic representations, resulting in an explicit form of invariant feature functions.
In this study, a novel feature coding method that exploits invariance for transformations represented by a finite group of orthogonal matrices is proposed. We prove that the group-invariant feature vector contains sufficient discriminative information when learning a linear classifier using convex loss minimization. Based on this result, a novel feature model that explicitly considers group action is proposed for principal component analysis and k-means clustering, which are commonly used in most feature coding methods, and global feature functions. Although the global feature functions are in general complex nonlinear functions, the group action on this space can be easily calculated by constructing these functions as tensor-product representations of basic representations, resulting in an explicit form of invariant feature functions.
IEEE Robotics and Automation Letters
Learning Adaptive Policies for Autonomous Excavation Under Various Soil Conditions by Adversarial Domain Sampling
Takayuki Osa, Naoto Osajima, Masanori Aizawa, Tatsuya Harada
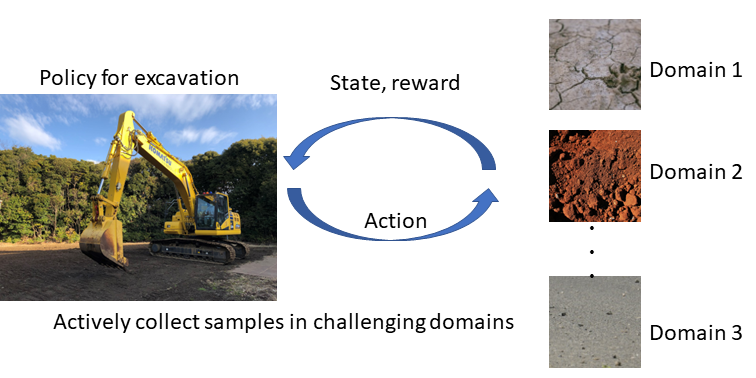 Excavation is a frequent task in construction. In this context, automation is expected to reduce hazard risks and labor-intensive work. To this end, recent studies have investigated using reinforcement learning (RL) to automate
construction machines. One of the challenges in applying RL to excavation tasks concerns obtaining skills adaptable to various conditions. When the conditions of soils differ, the optimal plans for efficiently excavating the target area will significantly differ. In existing meta-learning methods, the domain parameters are often uniformly sampled; this implicitly assumes that the difficulty of the task does not change significantly for different domain parameters.
In this study, we empirically show that uniformly sampling the domain parameters is insufficient when the task difficulty varies according to the task parameters. Correspondingly, we develop a framework for learning a policy that can be generalized to various domain parameters in excavation tasks.
We propose two techniques for improving the performance of an RL method in our problem setting: adversarial domain sampling and domain parameter estimation with a sensitivity-aware importance weight. In the proposed adversarial domain sampling technique, the domain parameters leading to low expected Q-values are actively sampled during the training phase. In addition, we propose a technique for training a domain parameter estimator based on the sensitivity of the Q-function to the domain parameter. The proposed techniques improve the performance of the RL method for our excavation task. We empirically show that our approach outperforms existing meta-learning and domain adaptation methods for excavation tasks.
Excavation is a frequent task in construction. In this context, automation is expected to reduce hazard risks and labor-intensive work. To this end, recent studies have investigated using reinforcement learning (RL) to automate
construction machines. One of the challenges in applying RL to excavation tasks concerns obtaining skills adaptable to various conditions. When the conditions of soils differ, the optimal plans for efficiently excavating the target area will significantly differ. In existing meta-learning methods, the domain parameters are often uniformly sampled; this implicitly assumes that the difficulty of the task does not change significantly for different domain parameters.
In this study, we empirically show that uniformly sampling the domain parameters is insufficient when the task difficulty varies according to the task parameters. Correspondingly, we develop a framework for learning a policy that can be generalized to various domain parameters in excavation tasks.
We propose two techniques for improving the performance of an RL method in our problem setting: adversarial domain sampling and domain parameter estimation with a sensitivity-aware importance weight. In the proposed adversarial domain sampling technique, the domain parameters leading to low expected Q-values are actively sampled during the training phase. In addition, we propose a technique for training a domain parameter estimator based on the sensitivity of the Q-function to the domain parameter. The proposed techniques improve the performance of the RL method for our excavation task. We empirically show that our approach outperforms existing meta-learning and domain adaptation methods for excavation tasks.
Medical Image Computing and Computer-Assisted Intervention (MICCAI 2023)
MedIM: Boost Medical Image Representation via Radiology Report-guided Masking
Yutong Xie, Lin Gu , Tatsuya Harada, Jianpeng Zhang, Yong Xia, Qi Wu
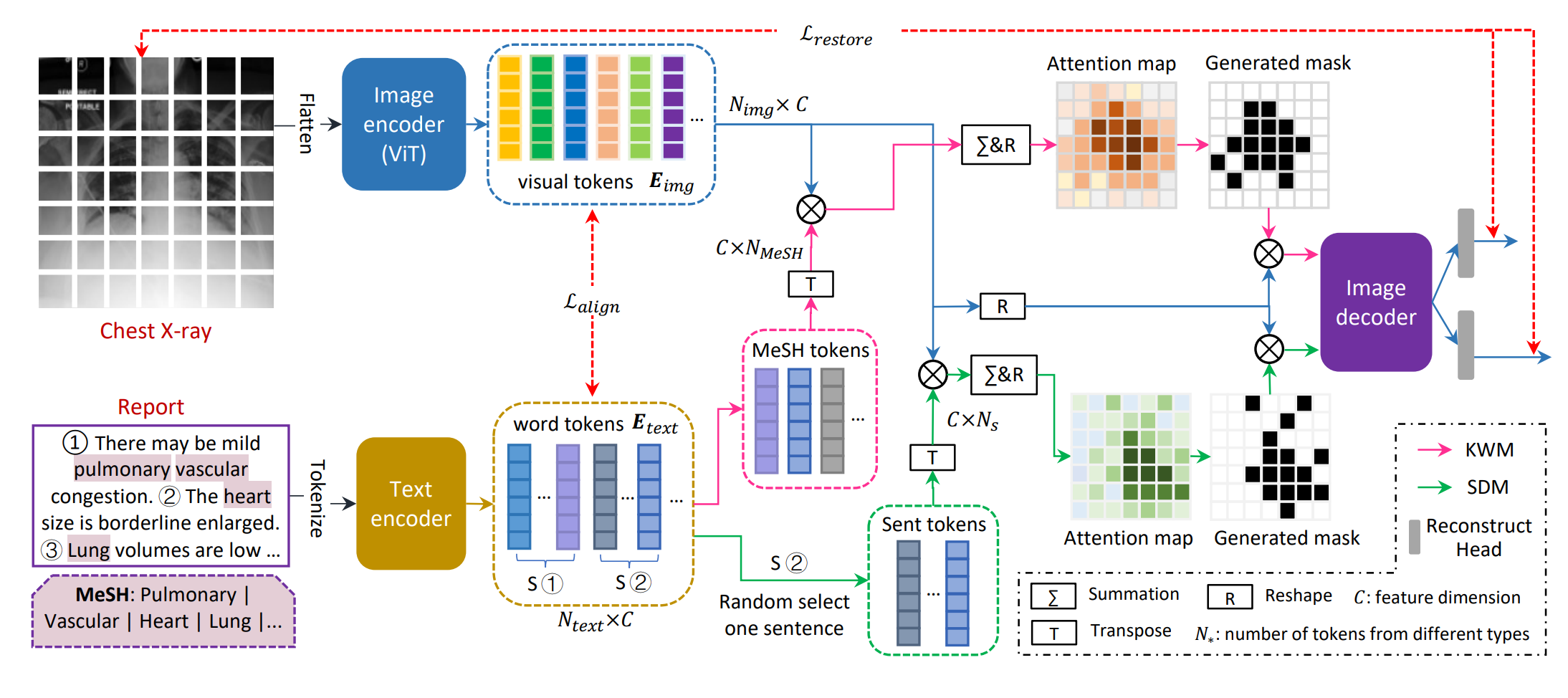 Masked image modelling (MIM)-based pre-training shows promise in improving image representations with limited annotated data by randomly masking image patches and reconstructing them. However, random masking may not be suitable for medical images due to their unique pathology characteristics. This paper proposes Masked medical Image Modelling (MedIM), a novel approach, to our knowledge, the first research that masks and reconstructs discriminative areas guided by radiological reports, encouraging the network to explore the stronger semantic representations from medical images. We introduce two mutual comprehensive masking strategies, knowledge word-driven masking (KWM) and sentence-driven masking (SDM). KWM uses Medical Subject Headings (MeSH) words unique to radiology reports to identify discriminative cues mapped to MeSH words and guide the mask generation. SDM considers that reports usually have multiple sentences, each of which describes different findings, and therefore integrates sentence-level information to identify discriminative regions for mask generation. MedIM integrates both strategies by simultaneously restoring the images masked by KWM and SDM for a more robust and representative medical visual representation. Our extensive experiments on various downstream tasks covering multi-label/class image classification, medical image segmentation, and medical image-text analysis, demonstrate that MedIM with reportguided masking achieves competitive performance. Our method substantially outperforms ImageNet pre-training, MIM-based pre-training, and medical image-report pre-training counterparts.
Masked image modelling (MIM)-based pre-training shows promise in improving image representations with limited annotated data by randomly masking image patches and reconstructing them. However, random masking may not be suitable for medical images due to their unique pathology characteristics. This paper proposes Masked medical Image Modelling (MedIM), a novel approach, to our knowledge, the first research that masks and reconstructs discriminative areas guided by radiological reports, encouraging the network to explore the stronger semantic representations from medical images. We introduce two mutual comprehensive masking strategies, knowledge word-driven masking (KWM) and sentence-driven masking (SDM). KWM uses Medical Subject Headings (MeSH) words unique to radiology reports to identify discriminative cues mapped to MeSH words and guide the mask generation. SDM considers that reports usually have multiple sentences, each of which describes different findings, and therefore integrates sentence-level information to identify discriminative regions for mask generation. MedIM integrates both strategies by simultaneously restoring the images masked by KWM and SDM for a more robust and representative medical visual representation. Our extensive experiments on various downstream tasks covering multi-label/class image classification, medical image segmentation, and medical image-text analysis, demonstrate that MedIM with reportguided masking achieves competitive performance. Our method substantially outperforms ImageNet pre-training, MIM-based pre-training, and medical image-report pre-training counterparts.
Towards AI-driven radiology education: A self-supervised segmentation-based framework for high-precision medical image editing
Kazuma Kobayashi, Lin Gu, Ryuichiro Hataya, Mototaka Miyake, Yasuyuki Takamizawa, Sono Ito, Hirokazu Watanabe, Yukihiro Yoshida, Hiroki Yoshimura, Tatsuya Harada, yuji Hamamoto
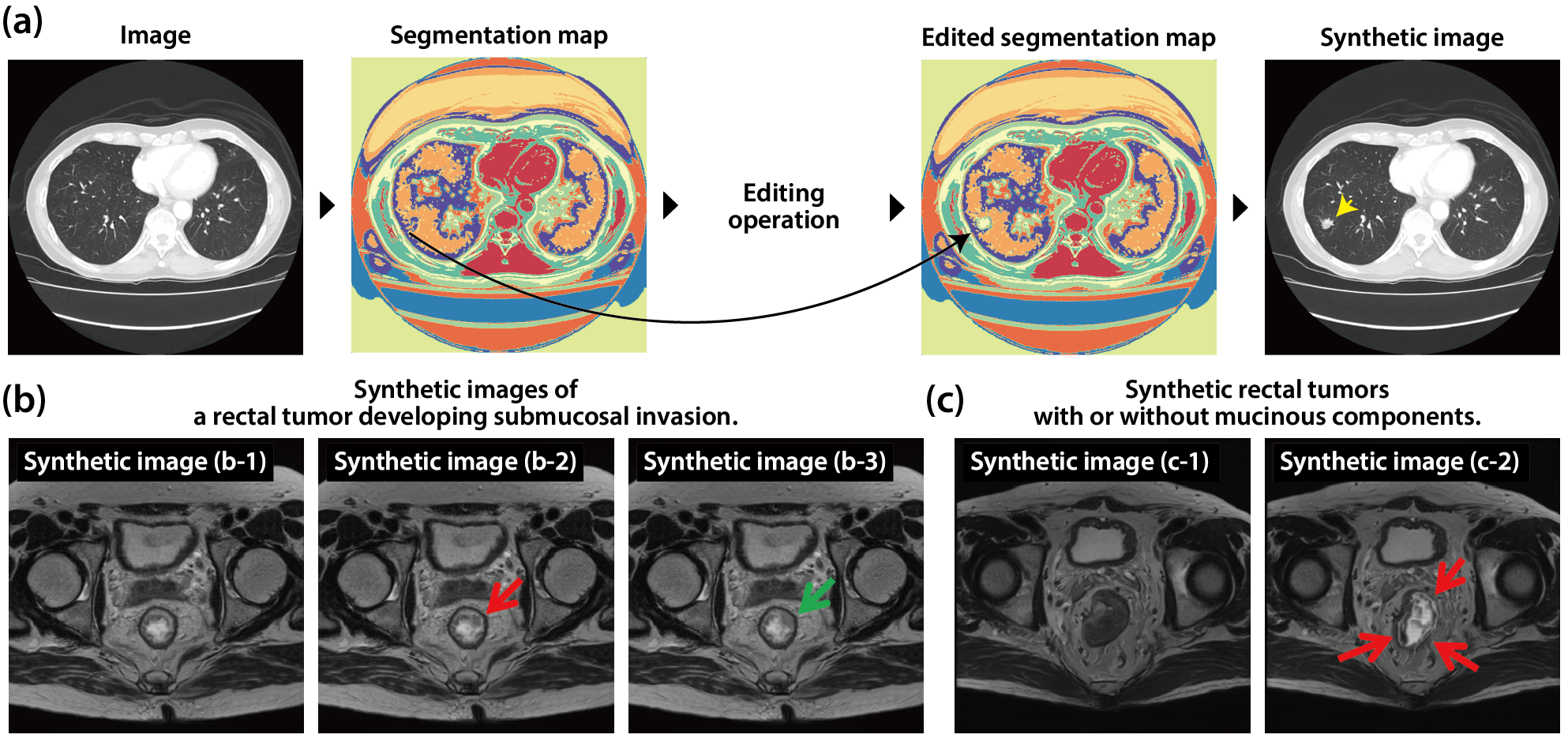 Generating medical images with fine-grained characteristics through image editing can be useful for training both physicians and deep-learning models. However, image editing techniques typically require large, manually annotated labels, which are labor-intensive and often inaccurate for fine-grained anatomical elements. Here, we present an algorithm that allows users to edit any anatomical element by exploiting segmentation labels acquired through self-supervised learning. We developed an efficient algorithm for self-supervised medical image segmentation that achieves pixel-wise clustering under the constraint of ensuring invariance to photometric and geometric transformations. We then applied it to two datasets: a pelvic MRI dataset and a chest CT dataset. The obtained segmentation map can be edited by the user, and by decoding it, a medical image is generated with any detailed findings. Several licenced physicians' evaluations showed that the edited medical images were virtually indistinguishable from the real images, and specific disease features were accurately reproduced, demonstrating our potential for physicians' training and diagnosis assistance.
Generating medical images with fine-grained characteristics through image editing can be useful for training both physicians and deep-learning models. However, image editing techniques typically require large, manually annotated labels, which are labor-intensive and often inaccurate for fine-grained anatomical elements. Here, we present an algorithm that allows users to edit any anatomical element by exploiting segmentation labels acquired through self-supervised learning. We developed an efficient algorithm for self-supervised medical image segmentation that achieves pixel-wise clustering under the constraint of ensuring invariance to photometric and geometric transformations. We then applied it to two datasets: a pelvic MRI dataset and a chest CT dataset. The obtained segmentation map can be edited by the user, and by decoding it, a medical image is generated with any detailed findings. Several licenced physicians' evaluations showed that the edited medical images were virtually indistinguishable from the real images, and specific disease features were accurately reproduced, demonstrating our potential for physicians' training and diagnosis assistance.
Pattern Recognition
Correlated and individual feature learning with contrast-enhanced MR for malignancy characterization of hepatocellular carcinoma
Yunling Li, Shangxuan Li, Hanqiu Ju, Tatsuya Harada, Honglai Zhang, Ting Duan, Guangyi Wang, Lijuan Zhang, Lin Gu, Wu Zhou
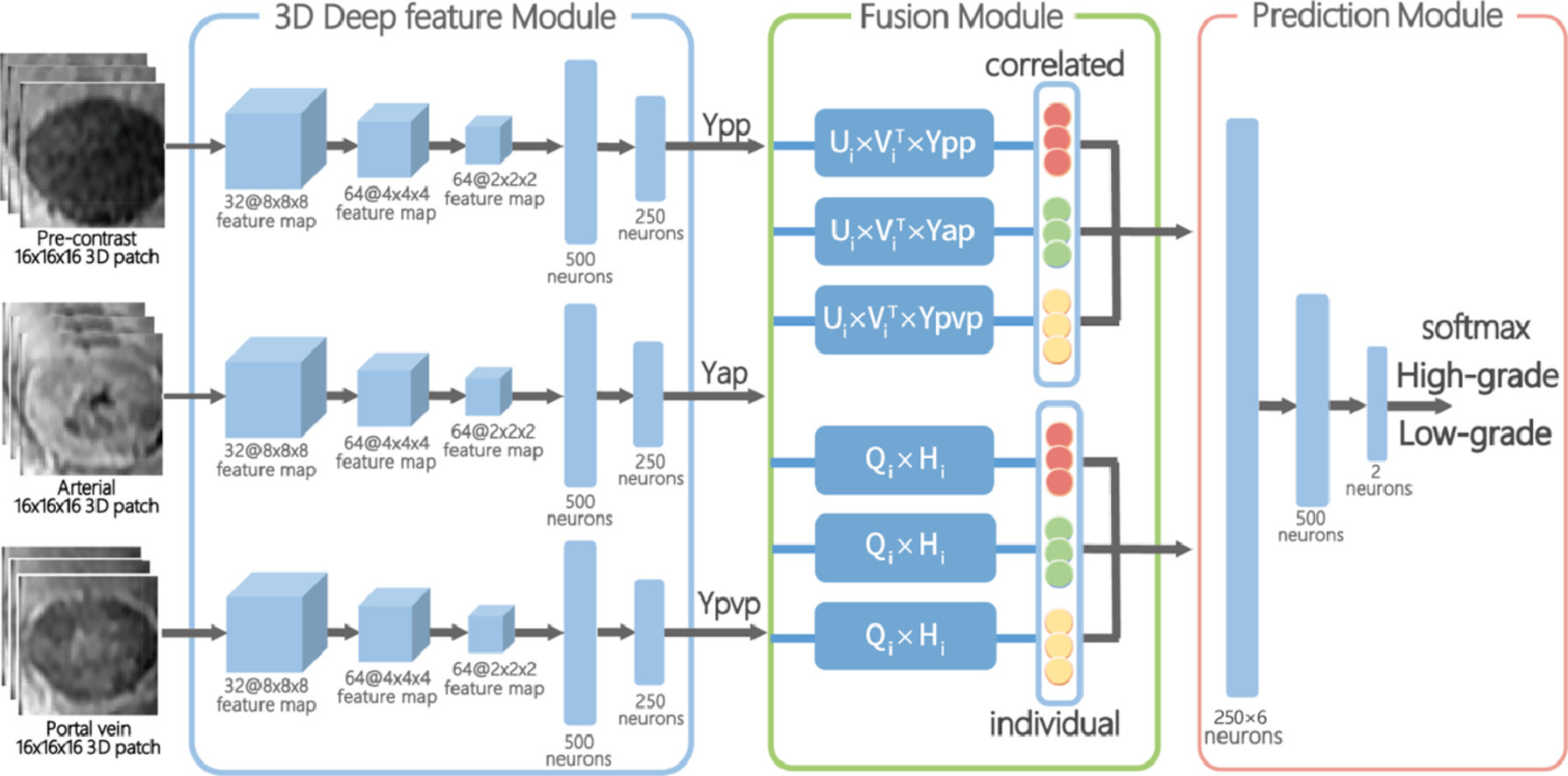 Malignancy characterization of hepatocellular carcinoma (HCC) is of great importance in patient management and prognosis prediction. In this study, we propose an end-to-end correlated and individual feature learning framework to characterize the malignancy of HCC from Contrast-enhanced MR. From the phases of pre-contrast, arterial and portal venous, our framework simultaneously and explicitly learns both the shareable and phase-specific features that are discriminative to malignancy grades. We evaluate our method on the Contrast enhanced MR of 112 consecutive patients with 117 histologically proven HCCs. Experimental results demonstrate that arterial phase yields better results than portal vein and pre-contrast phase. Furthermore, phase specific components show better discriminant ability than the shareable components. Finally, combining the extracted shareable and individual features components has yielded significantly better performance than traditional feature fusion methods. We also conduct t-SNE analysis and feature scoring analysis to qualitatively assess the effectiveness of the proposed method for malignancy characterization.
Malignancy characterization of hepatocellular carcinoma (HCC) is of great importance in patient management and prognosis prediction. In this study, we propose an end-to-end correlated and individual feature learning framework to characterize the malignancy of HCC from Contrast-enhanced MR. From the phases of pre-contrast, arterial and portal venous, our framework simultaneously and explicitly learns both the shareable and phase-specific features that are discriminative to malignancy grades. We evaluate our method on the Contrast enhanced MR of 112 consecutive patients with 117 histologically proven HCCs. Experimental results demonstrate that arterial phase yields better results than portal vein and pre-contrast phase. Furthermore, phase specific components show better discriminant ability than the shareable components. Finally, combining the extracted shareable and individual features components has yielded significantly better performance than traditional feature fusion methods. We also conduct t-SNE analysis and feature scoring analysis to qualitatively assess the effectiveness of the proposed method for malignancy characterization.
SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2023)
Expert Knowledge-Aware Image Difference Graph Representation Learning for Difference-Aware Medical Visual Question Answering
Xinyue Hu, Lin Gu, Qiyuan An, Zhang Mengliang, Liangchen Liu, Kazuma Kobayashi, Tatsuya Harada, Ronald M. Summers, Yingying Zhu
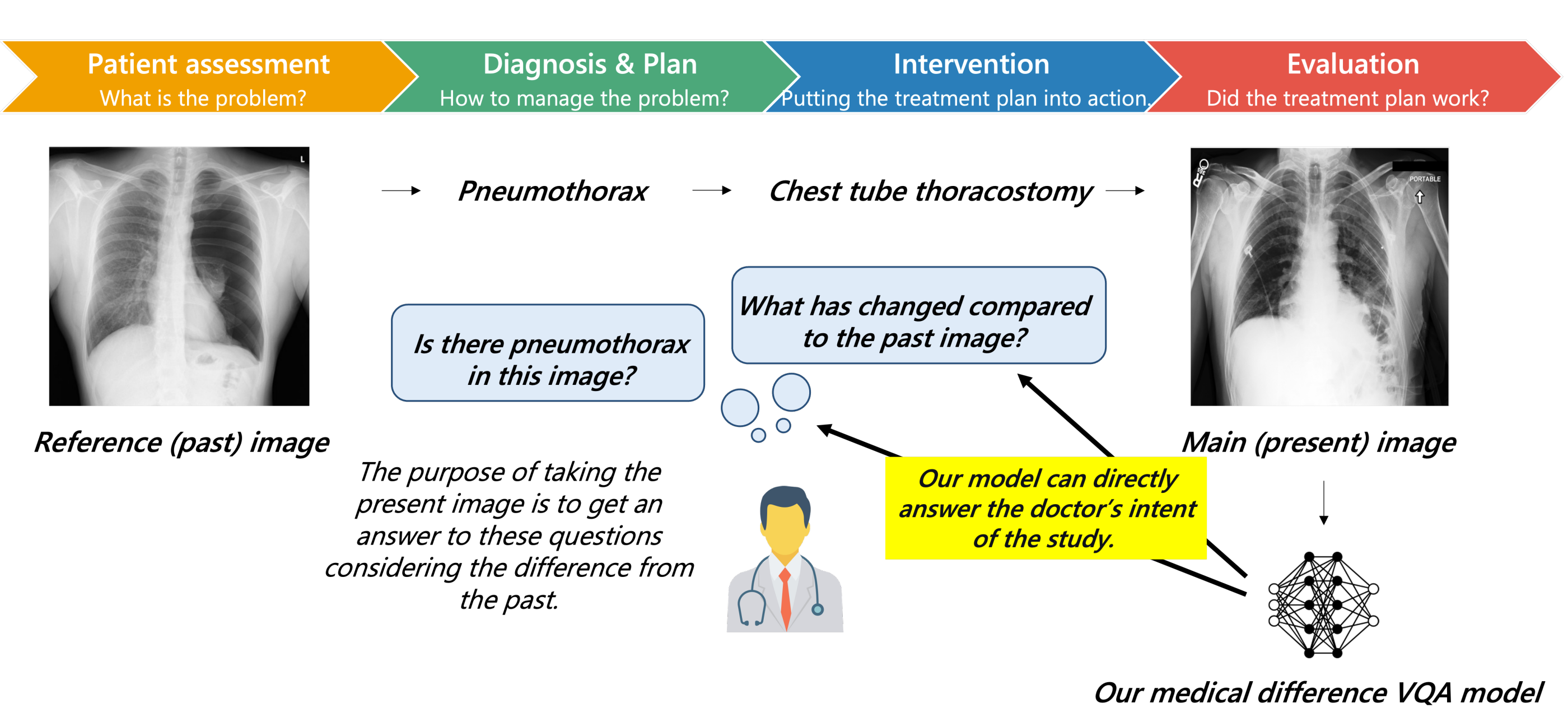 We propose a novel Chest-Xray Different Visual Question Answering (VQA) task. Given a pair of main and reference images, this task attempts to answer several questions on both diseases and, more importantly, the differences between them. This is consistent with the radiologist's diagnosis practice that compares the current image with the reference before concluding the report. We collect a new dataset, namely MIMIC-Diff-VQA, including 698,739 QA pairs on 109,790 pairs of main and reference images. Compared to existing medical VQA datasets, our questions are tailored to the Assessment-Diagnosis-Intervention-Evaluation treatment procedure used by clinical professionals. Meanwhile, we also propose a novel expert knowledge-aware graph representation learning model to address this task. The proposed baseline model leverages expert knowledge such as anatomical structure prior, semantic, and spatial knowledge to construct a multi-relationship graph, representing the image differences between two images for the image difference VQA task. The dataset and code will be released upon publication. We believe this work would further push forward the medical vision language model.
We propose a novel Chest-Xray Different Visual Question Answering (VQA) task. Given a pair of main and reference images, this task attempts to answer several questions on both diseases and, more importantly, the differences between them. This is consistent with the radiologist's diagnosis practice that compares the current image with the reference before concluding the report. We collect a new dataset, namely MIMIC-Diff-VQA, including 698,739 QA pairs on 109,790 pairs of main and reference images. Compared to existing medical VQA datasets, our questions are tailored to the Assessment-Diagnosis-Intervention-Evaluation treatment procedure used by clinical professionals. Meanwhile, we also propose a novel expert knowledge-aware graph representation learning model to address this task. The proposed baseline model leverages expert knowledge such as anatomical structure prior, semantic, and spatial knowledge to construct a multi-relationship graph, representing the image differences between two images for the image difference VQA task. The dataset and code will be released upon publication. We believe this work would further push forward the medical vision language model.
IEEE International Symposium on Biomedical Imaging (ISBI)
Domain Adaptive Multiple Instance Learning for Instance-level Prediction of Pathological Images
Shusuke Takahama, Yusuke Kurose, Yusuke Mukuta, Hiroyuki Abe, Akihiko Yoshizawa, Tetsuo Ushiku, Masashi Fukayama, Masanobu Kitagawa, Masaru Kitsuregawa, Tatsuya Harada
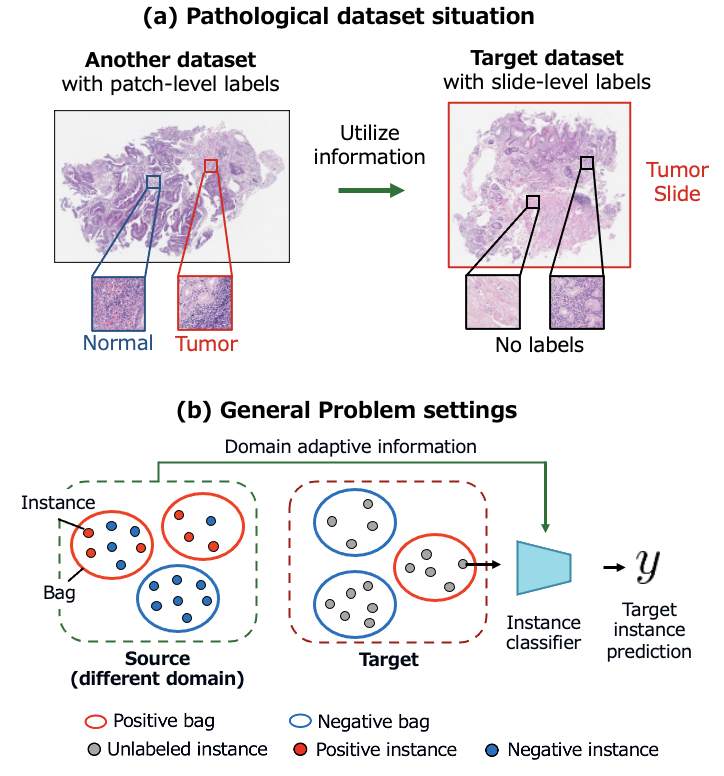 Pathological image analysis is a crucial diagnosis to detect abnormalities such as cancer by observing cell images. Many studies have attempted to apply image recognition technology to pathological images to assist in diagnosis. Learning an accurate classification model requires a large number of labels, but the annotation requires a great deal of effort and a high level of expertise. In this study, to obtain an accurate model while reducing the cost of labeling, we adopted "Multiple instance learning", which can learn a model with only coarse labels. In addition, we proposed a new pipeline that incorporates "Domain adaptation" and "Pseudo-labeling", which are transfer learning methods that take advantage of information from other datasets. We conducted experiments on our own pathological image datasets of the stomach and colon and confirmed that our method can find abnormalities with high accuracy while keeping the labeling cost low. (arXiv)
Pathological image analysis is a crucial diagnosis to detect abnormalities such as cancer by observing cell images. Many studies have attempted to apply image recognition technology to pathological images to assist in diagnosis. Learning an accurate classification model requires a large number of labels, but the annotation requires a great deal of effort and a high level of expertise. In this study, to obtain an accurate model while reducing the cost of labeling, we adopted "Multiple instance learning", which can learn a model with only coarse labels. In addition, we proposed a new pipeline that incorporates "Domain adaptation" and "Pseudo-labeling", which are transfer learning methods that take advantage of information from other datasets. We conducted experiments on our own pathological image datasets of the stomach and colon and confirmed that our method can find abnormalities with high accuracy while keeping the labeling cost low. (arXiv)
2nd Workshop on Learning with Limited Labelled Data for Image and Video Understanding (CVPR2023 workshop)
Zero-shot Object Classification with Large-scale Knowledge Graph
Kohei Shiba, Yusuke Mukuta, Tatsuya Harada
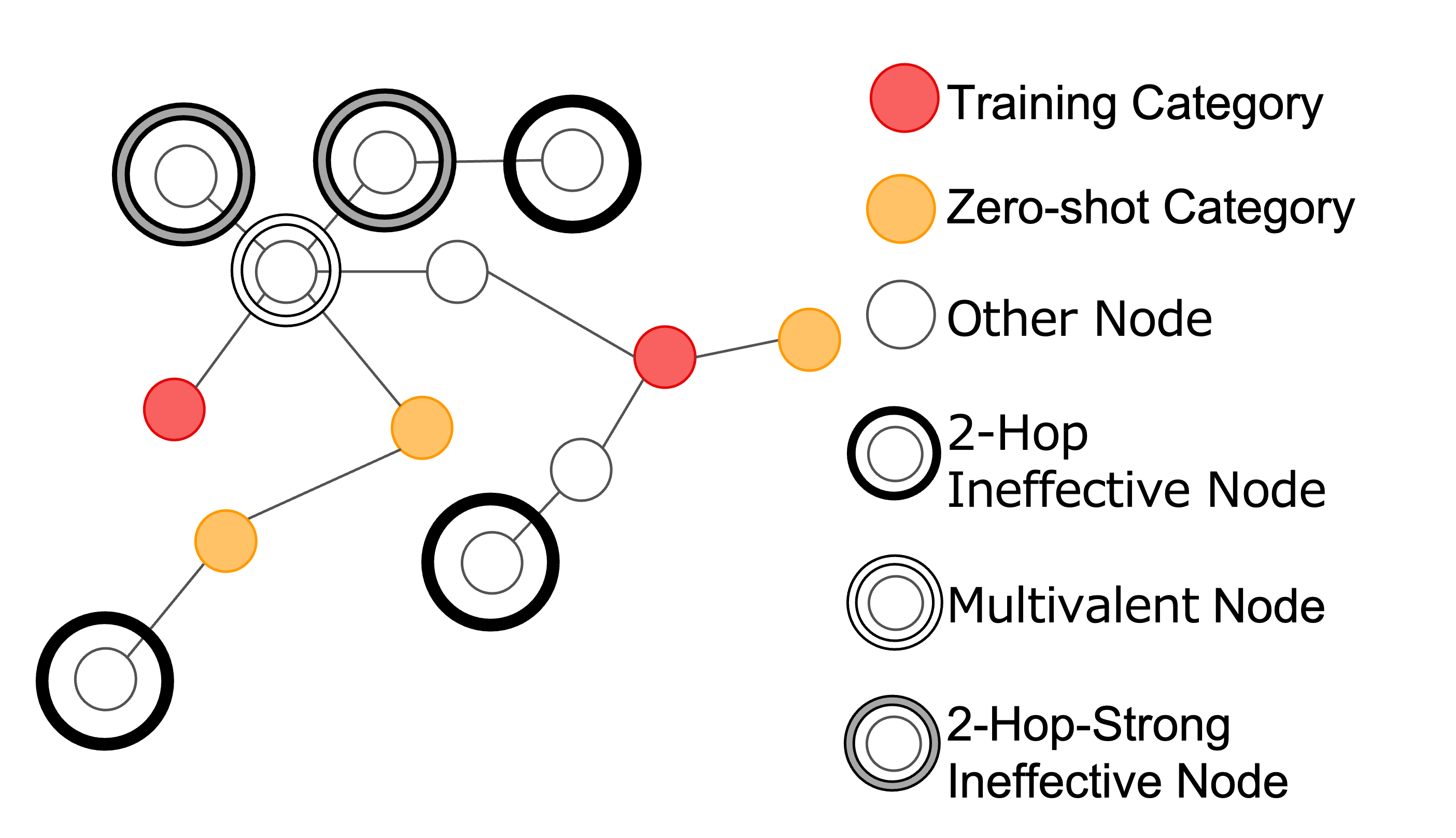 Zero-shot learning is research for predicting unseen categories, and can solve problems such as dealing with unseen categories that were not anticipated at the time of training and the lack of labeled datasets. One of the methods for zero-shot object classification is using a knowledge graph. We use a large-scale knowledge graph to enable classification of a larger number of categories and to achieve more accurate recognition.
We propose a method to extract useful graph information by positional relationships and the types of edges. We classify images that were unclassifiable in existing research and show that the proposed data extraction method improves performance.
Zero-shot learning is research for predicting unseen categories, and can solve problems such as dealing with unseen categories that were not anticipated at the time of training and the lack of labeled datasets. One of the methods for zero-shot object classification is using a knowledge graph. We use a large-scale knowledge graph to enable classification of a larger number of categories and to achieve more accurate recognition.
We propose a method to extract useful graph information by positional relationships and the types of edges. We classify images that were unclassifiable in existing research and show that the proposed data extraction method improves performance.
Computer Speech & Language
COMPASS: A creative support system that alerts novelists to the unnoticed missing contents
Yusuke Mori, Hiroaki Yamane, Ryohei Shimizu, Yusuke Mukuta, Tatsuya Harada
 Writing a story is not easy, and even professional creators do not always write a perfect story at once. Sometimes, objective advice from an editor can help a creator realize what needs to be improved. We proposed COMPASS, a creative writing support system that suggests completing the missing information that storytellers unintentionally omitted. We conducted a user study of four professional creators who use Japanese and confirmed the system's usefulness. We hope this effort will be a basis for further research on collaborative creation between creators and AI. (paper(open access))
Writing a story is not easy, and even professional creators do not always write a perfect story at once. Sometimes, objective advice from an editor can help a creator realize what needs to be improved. We proposed COMPASS, a creative writing support system that suggests completing the missing information that storytellers unintentionally omitted. We conducted a user study of four professional creators who use Japanese and confirmed the system's usefulness. We hope this effort will be a basis for further research on collaborative creation between creators and AI. (paper(open access))
Association for the Advancement of Artificial Intelligence (AAAI 2023)
People taking photos that faces never share: Privacy Protection and Fairness Enhancement from Camera to User
Junjie Zhu, Lin Gu, Xiaoxiao Wu, Zheng Li, Tatsuya Harada, Yingying Zhu
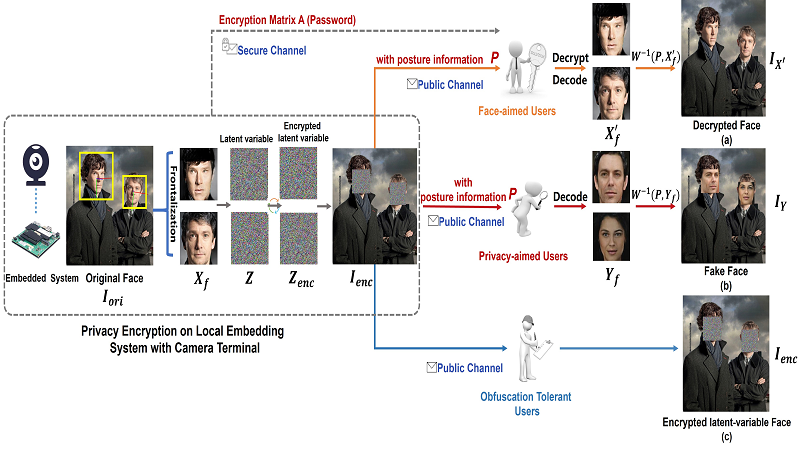 The soaring number of personal mobile devices and public cameras poses a threat to fundamental human rights and ethical principles. For example, the stolen of private information such as face image by malicious third parties will lead to catastrophic consequences. By manipulating appearance of face in the image, most of existing protection algorithms are effective but irreversible. Here, we propose a practical and systematic solution to invertiblely protect face information in the full-process pipeline from camera to final users. Specifically, We design a novel lightweight Flow-based Face Encryption Method (FFEM) on the local embedded system privately connected to the camera, minimizing the risk of eavesdropping during data transmission. FFEM uses a flow-based face encoder to encode each face to a Gaussian distribution and encrypts the encoded face feature by random rotating the Gaussian distribution with the rotation matrix is as the password. While encrypted latent-variable face images are sent to users through public but less reliable channels, password will be protected through more secure channels through technologies such as asymmetric encryption, blockchain, or other sophisticated security schemes. User could select to decode an image with fake faces from the encrypted image on the public channel. Only trusted users are able to recover the original face using the encrypted matrix transmitted in secure channel. More interestingly, by tuning Gaussian ball in latent space, we could control the fairness of the replaced face on attributes such as gender and race. Extensive experiments demonstrate that our solution could protect privacy and enhance fairness with minimal effect on high-level downstream task.
The soaring number of personal mobile devices and public cameras poses a threat to fundamental human rights and ethical principles. For example, the stolen of private information such as face image by malicious third parties will lead to catastrophic consequences. By manipulating appearance of face in the image, most of existing protection algorithms are effective but irreversible. Here, we propose a practical and systematic solution to invertiblely protect face information in the full-process pipeline from camera to final users. Specifically, We design a novel lightweight Flow-based Face Encryption Method (FFEM) on the local embedded system privately connected to the camera, minimizing the risk of eavesdropping during data transmission. FFEM uses a flow-based face encoder to encode each face to a Gaussian distribution and encrypts the encoded face feature by random rotating the Gaussian distribution with the rotation matrix is as the password. While encrypted latent-variable face images are sent to users through public but less reliable channels, password will be protected through more secure channels through technologies such as asymmetric encryption, blockchain, or other sophisticated security schemes. User could select to decode an image with fake faces from the encrypted image on the public channel. Only trusted users are able to recover the original face using the encrypted matrix transmitted in secure channel. More interestingly, by tuning Gaussian ball in latent space, we could control the fairness of the replaced face on attributes such as gender and race. Extensive experiments demonstrate that our solution could protect privacy and enhance fairness with minimal effect on high-level downstream task.
Winter Conference on Applications of Computer Vision (WACV 2023)
Backprop Induced Feature Weighting for Adversarial Domain Adaptation with Iterative Label Distribution Alignment
Thomas Westfechtel, Hao-Wei Yeh, Qier Meng, Yusuke Mukuta, Tatsuya Harada
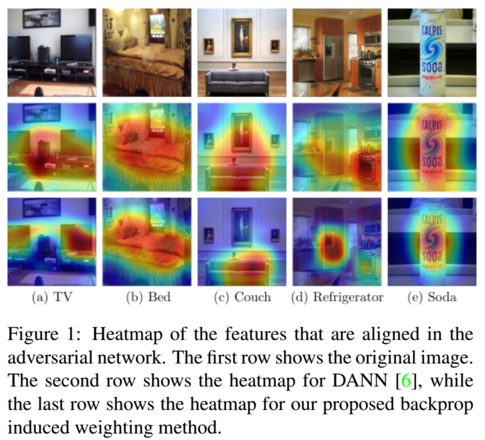 The requirement for large labeled datasets is one of the limiting factors for training accurate deep neural networks. Unsupervised domain adaptation tackles this problem of limited training data by transferring knowledge from one domain, which has many labeled data, to a different domain for which little to no labeled data is available. One common approach is to learn domain-invariant features for example with an adversarial approach. Previous methods often train the domain classifier and label classifier network separately, where both classification networks have little interaction with each other. In this paper, we introduce a classifier based backprop induced weighting of the feature space. This approach has two main advantages. Firstly, it lets the domain classifier focus on features that are important for the classification and, secondly, it couples the classification and adversarial branch more closely. Furthermore, we introduce an iterative label distribution alignment method, that employs results of previous runs to approximate a class-balanced dataloader. We conduct experiments and ablation studies on three benchmarks Office-31, OfficeHome and DomainNet to show the effectiveness of our proposed algorithm.
The requirement for large labeled datasets is one of the limiting factors for training accurate deep neural networks. Unsupervised domain adaptation tackles this problem of limited training data by transferring knowledge from one domain, which has many labeled data, to a different domain for which little to no labeled data is available. One common approach is to learn domain-invariant features for example with an adversarial approach. Previous methods often train the domain classifier and label classifier network separately, where both classification networks have little interaction with each other. In this paper, we introduce a classifier based backprop induced weighting of the feature space. This approach has two main advantages. Firstly, it lets the domain classifier focus on features that are important for the classification and, secondly, it couples the classification and adversarial branch more closely. Furthermore, we introduce an iterative label distribution alignment method, that employs results of previous runs to approximate a class-balanced dataloader. We conduct experiments and ablation studies on three benchmarks Office-31, OfficeHome and DomainNet to show the effectiveness of our proposed algorithm.
K-VQG: Knowledge-aware Visual Question Generation for Common-sense Acquisition
Kohei Uehara, Tatsuya Harada
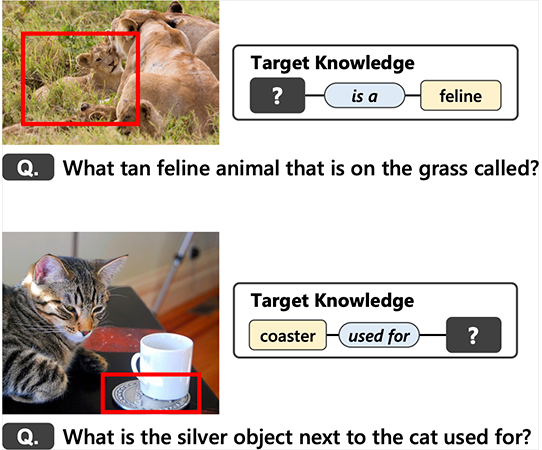 Visual Question Generation (VQG) is a task to generate questions from images. When humans ask questions about an image, their goal is often to acquire some new knowledge. However, existing studies on VQG have mainly addressed question generation from answers or question categories, overlooking the objectives of knowledge acquisition. To introduce a knowledge acquisition perspective into VQG, we constructed a novel knowledge-aware VQG dataset called K-VQG. This is the first large, humanly annotated dataset in which questions regarding images are tied to structured knowledge. We also developed a new VQG model that can encode and use knowledge as the target for a question. The experiment results show that our model outperforms existing models on the K-VQG dataset.
Visual Question Generation (VQG) is a task to generate questions from images. When humans ask questions about an image, their goal is often to acquire some new knowledge. However, existing studies on VQG have mainly addressed question generation from answers or question categories, overlooking the objectives of knowledge acquisition. To introduce a knowledge acquisition perspective into VQG, we constructed a novel knowledge-aware VQG dataset called K-VQG. This is the first large, humanly annotated dataset in which questions regarding images are tied to structured knowledge. We also developed a new VQG model that can encode and use knowledge as the target for a question. The experiment results show that our model outperforms existing models on the K-VQG dataset.