Abstracts of papers published in 2022
IEEE TPAMI 2022
Spherical Image Generation From a Few Normal-Field-of-View Images by Considering Scene Symmetry
Takayuki Hara, Yusuke Mukuta, Tatsuya Harada
 In this research, we address the problem of generating a spherical image, which captures the entire 360-degree field of view, from a few partially captured images. We proposed a method based on variational autoencoders that estimate the distribution of possible symmetry intensities in the target scene from input images and generates images by controlling the combination of symmetry patterns in the feature space based on the distribution. Experiments verified that the proposed method can generate more diverse and plausible spherical images than conventional methods. The results of this research can be applied to support the creation of virtual spaces and to generate environmental maps for AR.
In this research, we address the problem of generating a spherical image, which captures the entire 360-degree field of view, from a few partially captured images. We proposed a method based on variational autoencoders that estimate the distribution of possible symmetry intensities in the target scene from input images and generates images by controlling the combination of symmetry patterns in the feature space based on the distribution. Experiments verified that the proposed method can generate more diverse and plausible spherical images than conventional methods. The results of this research can be applied to support the creation of virtual spaces and to generate environmental maps for AR.
(pdf)
COLING 2022 Workshop
Learning to Evaluate Humor in Memes Based on the Incongruity Theory
Kohtaro Tanaka, Hiroaki Yamane, Yusuke Mori, Yusuke Mukuta, Tatsuya Harada
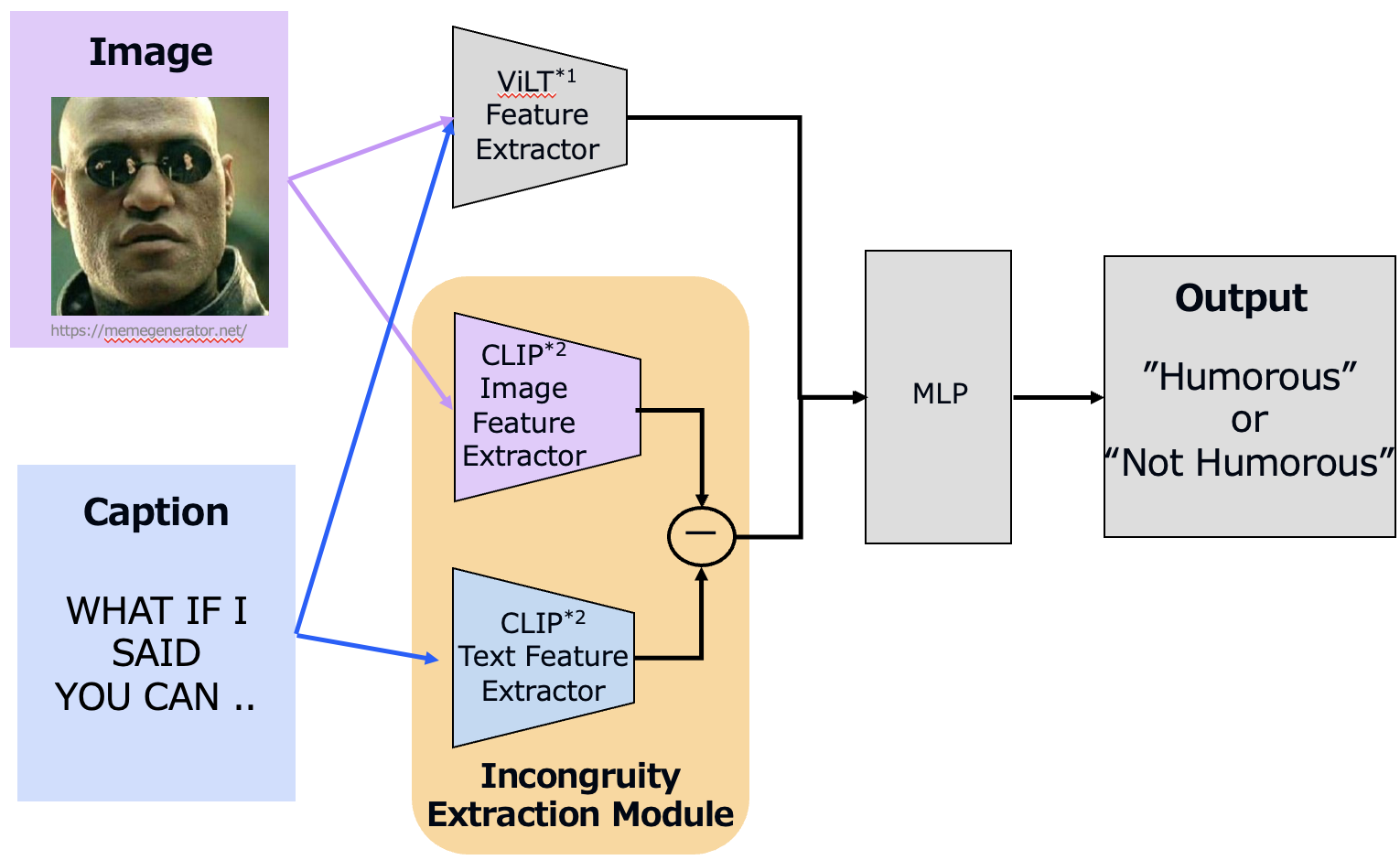 Memes are a widely used means of communication on social media platforms, and are known for their ability to “go viral”. In prior works, researchers have aimed to develop an AI system to understand humor in memes. However, existing methods are limited by the reliability and consistency of the annotations in the dataset used to train the underlying models. Moreover, they do not explicitly take advantage of the incongruity between images and their captions, which is known to be an important element of humor in memes. In this study, we first gathered real-valued humor annotations of 7,500 memes through a crowdwork platform. Based on this data, we propose a refinement process to extract memes that are not influenced by interpersonal differences in the perception of humor and a method designed to extract and utilize incongruities between images and captions. The results of an experimental comparison with models using vision and language pretraining models show that our proposed approach outperformed other models in a binary classification task of evaluating whether a given meme was humorous.
Memes are a widely used means of communication on social media platforms, and are known for their ability to “go viral”. In prior works, researchers have aimed to develop an AI system to understand humor in memes. However, existing methods are limited by the reliability and consistency of the annotations in the dataset used to train the underlying models. Moreover, they do not explicitly take advantage of the incongruity between images and their captions, which is known to be an important element of humor in memes. In this study, we first gathered real-valued humor annotations of 7,500 memes through a crowdwork platform. Based on this data, we propose a refinement process to extract memes that are not influenced by interpersonal differences in the perception of humor and a method designed to extract and utilize incongruities between images and captions. The results of an experimental comparison with models using vision and language pretraining models show that our proposed approach outperformed other models in a binary classification task of evaluating whether a given meme was humorous.
(pdf)
NeurIPS 2022
Non-rigid Point Cloud Registration with Neural Deformation Pyramid. Thirty-sixth Conference on Neural Information Processing Systems
Yang Li, Tatsuya Harada
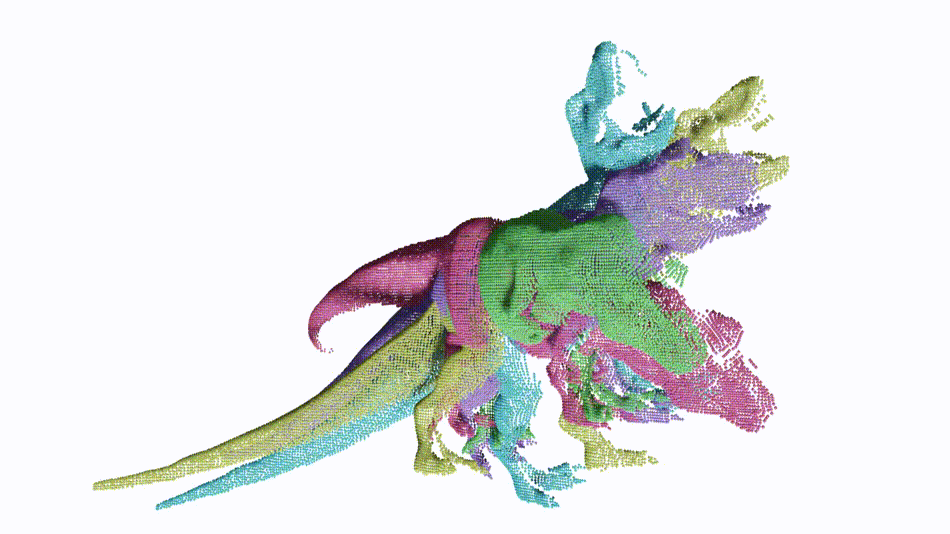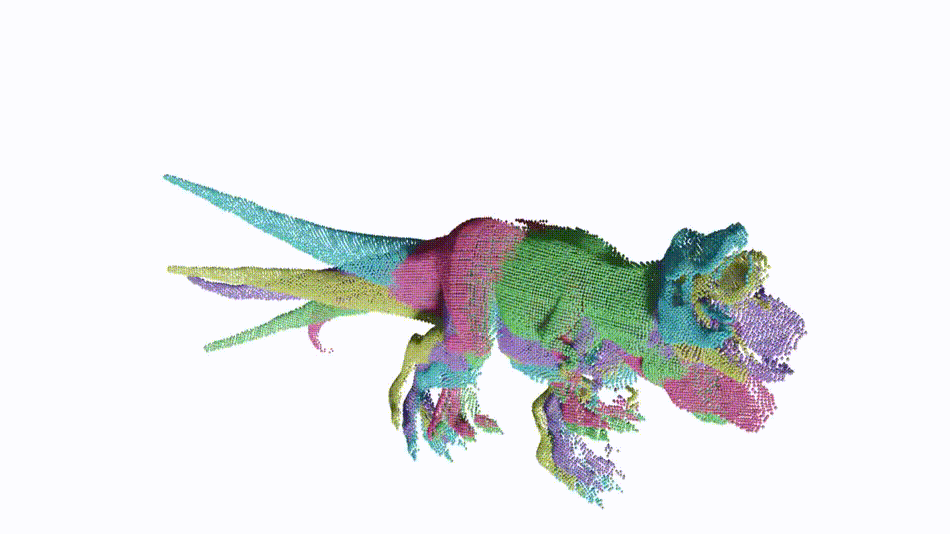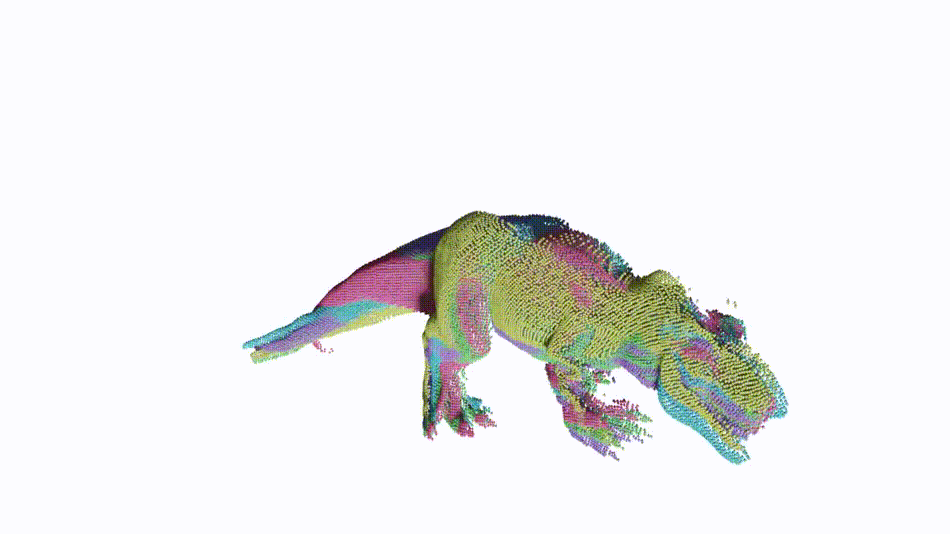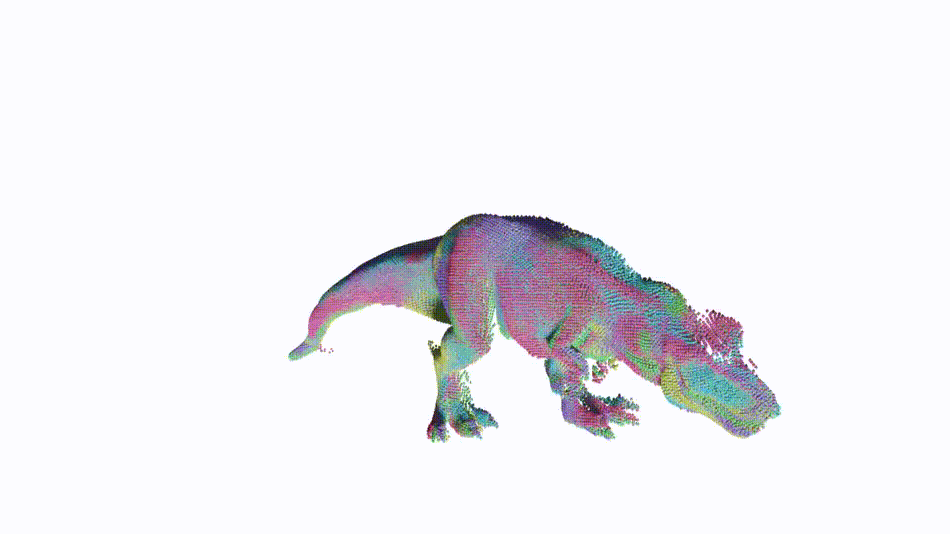 Non-rigid point cloud registration is a key component in many computer vision and computer graphics applications. The high complexity of the unknown non-rigid motion make this task a challenging problem. In this paper, we break down this problem via hierarchical motion decomposition. Our method called Neural Deformation Pyramid (NDP) represents non-rigid motion using a pyramid architecture. Each pyramid level, denoted by a Multi-Layer Perception (MLP), takes as input a sinusoidally encoded 3D point and outputs its motion increments from the previous level. The sinusoidal function starts with a low input frequency and gradually increases when the pyramid level goes down. This allows a multi-level rigid to nonrigid motion decomposition and also speeds up the solving by 50 times compared to the existing MLP-based approach. Our method achieves advanced partialto-partial non-rigid point cloud registration results on the 4DMatch/4DLoMatch benchmark under both no-learned and supervised settings.
Non-rigid point cloud registration is a key component in many computer vision and computer graphics applications. The high complexity of the unknown non-rigid motion make this task a challenging problem. In this paper, we break down this problem via hierarchical motion decomposition. Our method called Neural Deformation Pyramid (NDP) represents non-rigid motion using a pyramid architecture. Each pyramid level, denoted by a Multi-Layer Perception (MLP), takes as input a sinusoidally encoded 3D point and outputs its motion increments from the previous level. The sinusoidal function starts with a low input frequency and gradually increases when the pyramid level goes down. This allows a multi-level rigid to nonrigid motion decomposition and also speeds up the solving by 50 times compared to the existing MLP-based approach. Our method achieves advanced partialto-partial non-rigid point cloud registration results on the 4DMatch/4DLoMatch benchmark under both no-learned and supervised settings.
ECCV 2022
Deforming Radiance Fields with Cages
Tianhan Xu, Tatsuya Harada
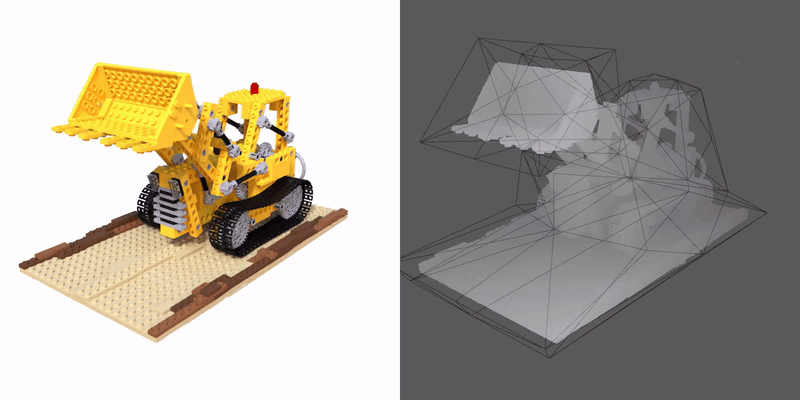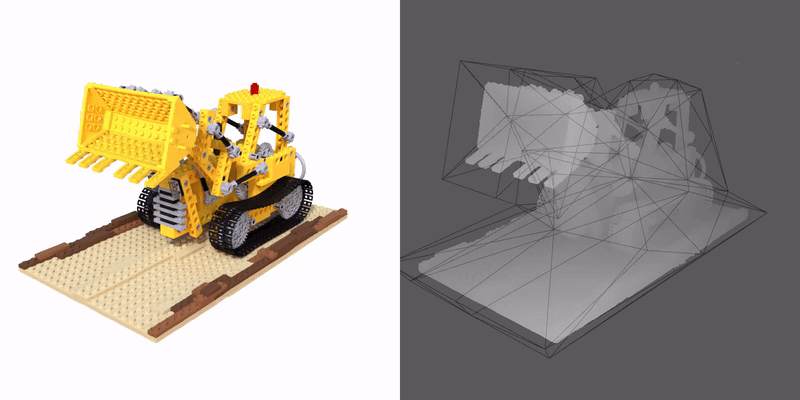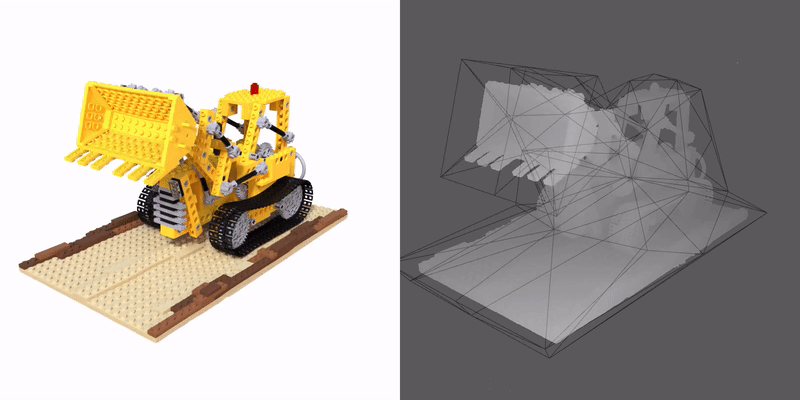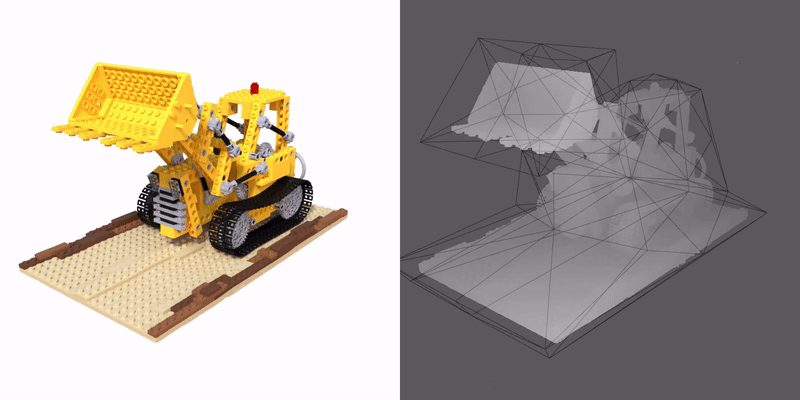 We propose a method that enables a new type of deformation of the radiance field: free-form radiance field deformation. We use a triangular mesh that encloses the foreground object called cage as an interface, and by manipulating the cage vertices, our approach enables the free-form deformation of the radiance field. The core of our approach is cage-based deformation. We propose a novel formulation to extend it to the radiance field, which maps the position and the view direction of the sampling points from the deformed space to the canonical space, thus enabling the rendering of the deformed scene.
We propose a method that enables a new type of deformation of the radiance field: free-form radiance field deformation. We use a triangular mesh that encloses the foreground object called cage as an interface, and by manipulating the cage vertices, our approach enables the free-form deformation of the radiance field. The core of our approach is cage-based deformation. We propose a novel formulation to extend it to the radiance field, which maps the position and the view direction of the sampling points from the deformed space to the canonical space, thus enabling the rendering of the deformed scene.
Unsupervised Learning of Efficient Geometry-Aware Neural Articulated Representations
Atsuhiro Noguchi, Xiao Sun, Stephen Lin, Tatsuya Harada
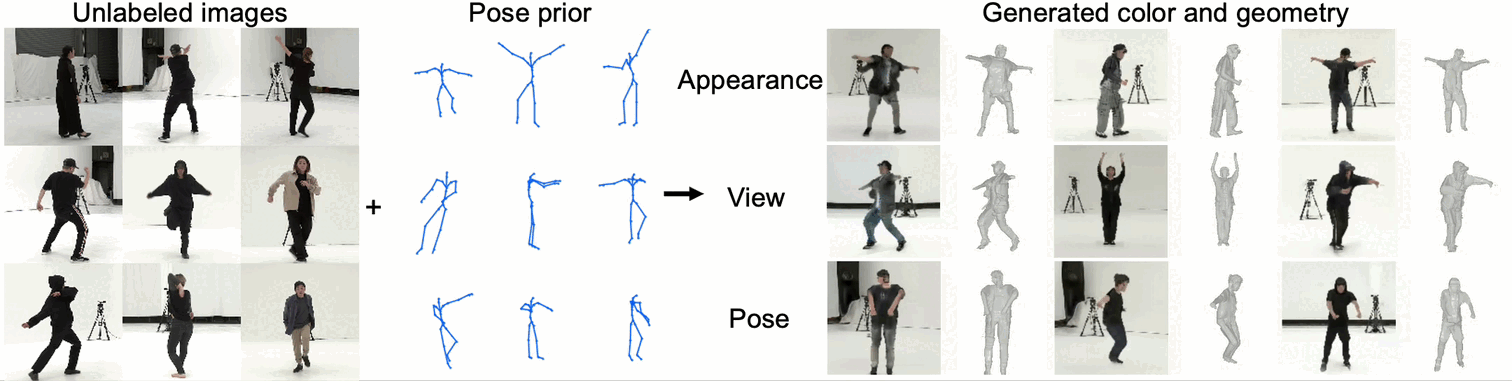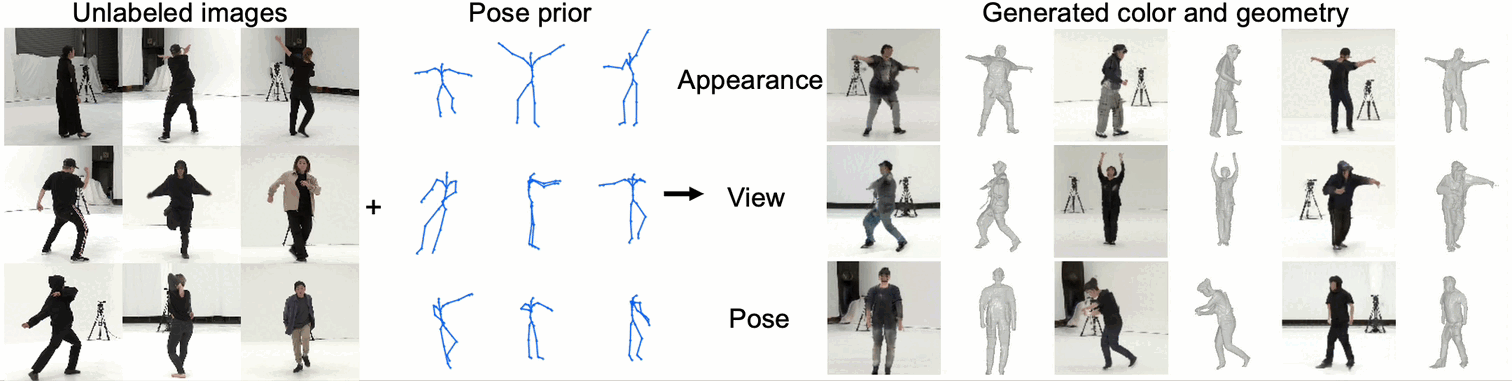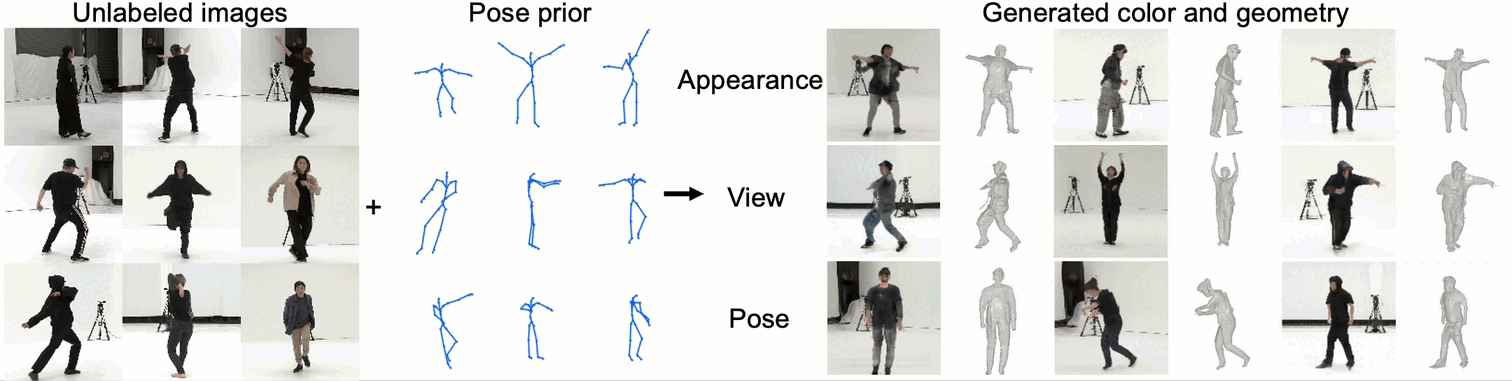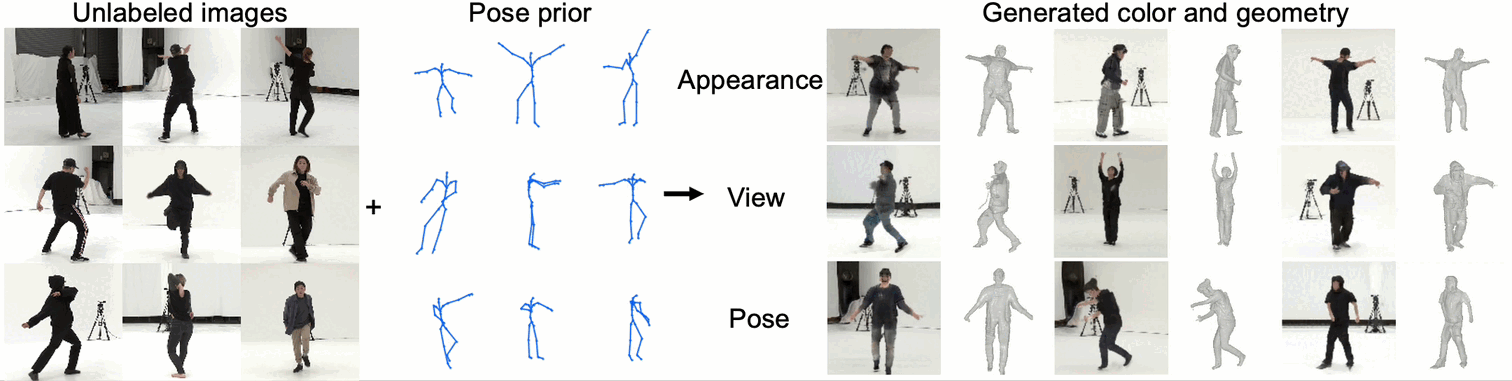 We propose an unsupervised method for 3D geometry-aware representation learning of articulated objects.
Though photorealistic images of articulated objects can be rendered with explicit pose control through existing 3D neural representations, these methods require ground truth 3D pose and foreground masks for training,
which are expensive to obtain. We obviate this need by learning the representations with GAN training.
From random poses and latent vectors, the generator is trained to produce realistic images of articulated objects by adversarial training.
To avoid a large computational cost for GAN training, we propose an efficient neural representation for articulated objects based on tri-planes and then present a GAN-based framework for its unsupervised training.
Experiments demonstrate the efficiency of our method and show that GAN-based training enables learning of controllable 3D representations without supervision.
We propose an unsupervised method for 3D geometry-aware representation learning of articulated objects.
Though photorealistic images of articulated objects can be rendered with explicit pose control through existing 3D neural representations, these methods require ground truth 3D pose and foreground masks for training,
which are expensive to obtain. We obviate this need by learning the representations with GAN training.
From random poses and latent vectors, the generator is trained to produce realistic images of articulated objects by adversarial training.
To avoid a large computational cost for GAN training, we propose an efficient neural representation for articulated objects based on tri-planes and then present a GAN-based framework for its unsupervised training.
Experiments demonstrate the efficiency of our method and show that GAN-based training enables learning of controllable 3D representations without supervision.
(PROJECT PAGE) (PDF) (CODE)
Unsupervised Pose-Aware Part Decomposition for 3D Articulated Objects
Yuki Kawana, Yusuke Mukuta, Tatsuya Harada
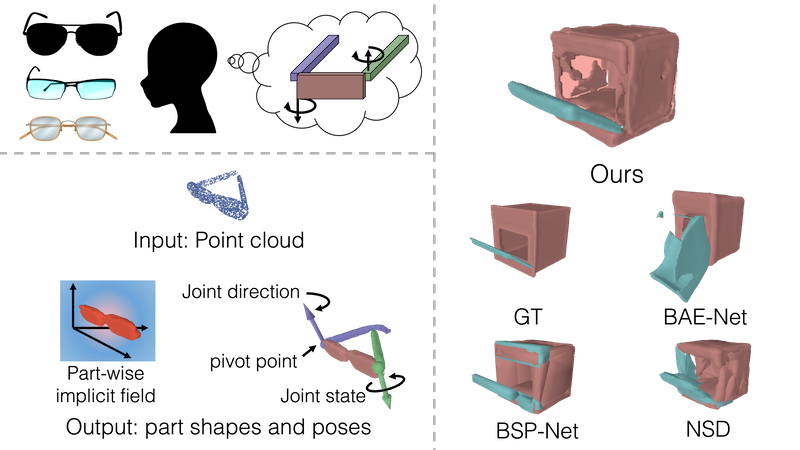 In this study, we propose PPD (unsupervised Pose-aware Part Decomposition) to address a novel setting that explicitly targets man-made articulated objects with mechanical joints, considering the part poses in part parsing.
As an analysis-by-synthesis approach, we show that category-common prior learning for both part shapes and poses facilitates the unsupervised learning of (1) part parsing with abstracted part shapes, and (2) part poses as joint parameters under single-frame shape supervision.
We evaluate our method on synthetic and real datasets, and we show that it outperforms previous works in consistent part parsing of the articulated objects based on comparable part pose estimation performance to the supervised baseline.
In this study, we propose PPD (unsupervised Pose-aware Part Decomposition) to address a novel setting that explicitly targets man-made articulated objects with mechanical joints, considering the part poses in part parsing.
As an analysis-by-synthesis approach, we show that category-common prior learning for both part shapes and poses facilitates the unsupervised learning of (1) part parsing with abstracted part shapes, and (2) part poses as joint parameters under single-frame shape supervision.
We evaluate our method on synthetic and real datasets, and we show that it outperforms previous works in consistent part parsing of the articulated objects based on comparable part pose estimation performance to the supervised baseline.
Exploring Resolution and Degradation Clues as Self-supervised Signal for Low Quality Object Detection
Ziteng Cui, Yingying Zhu, Lin Gu, Guo-Jun Qi, Xiaoxiao Li, Renrui Zhang, Zenghui Zhang, Tatsuya Harada
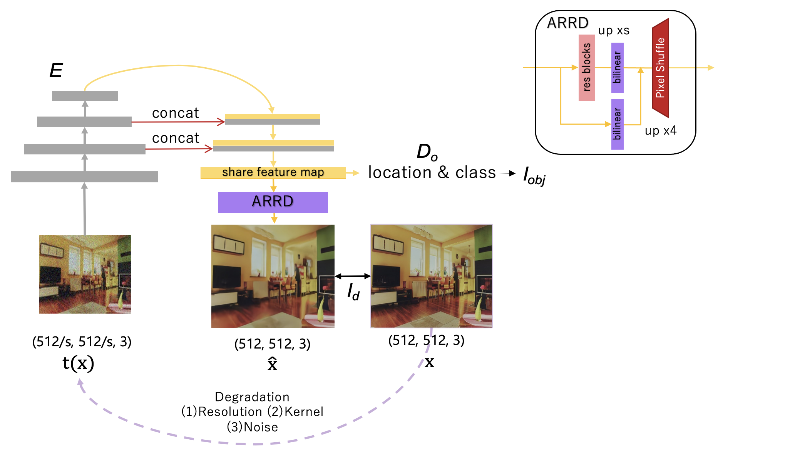 Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in low quality images. Most of these algorithms assume the degradation is fixed and known a priori. However, in pratical, either the real degrdation or optimal up-sampling ratio rate is unknown or differs from assumption, leading to a deteriorating performance for both the pre-processing module and the consequent high-level task such as object detection. Here, we propose a novel self-supervised framework to detect objects in degraded low resolution images. We utilizes the downsampling degradation as a kind of transformation for self-supervised signals to explore the equivariant representation against various resolutions and other degradation conditions. The Auto Encoding Resolution in Self-supervision (AERIS) framework could further take the advantage of advanced SR architectures with an arbitrary resolution restoring decoder to reconstruct the original correspondence from the degraded input image. Both the representation learning and object detection are optimized jointly in an end-to-end training fashion. The generic AERIS framework could be implemented on various mainstream object detection architectures from CNN to Transformer. The extensive experiments show that our methods has achieved superior performance compared with existing methods when facing variant degradation situations.
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in low quality images. Most of these algorithms assume the degradation is fixed and known a priori. However, in pratical, either the real degrdation or optimal up-sampling ratio rate is unknown or differs from assumption, leading to a deteriorating performance for both the pre-processing module and the consequent high-level task such as object detection. Here, we propose a novel self-supervised framework to detect objects in degraded low resolution images. We utilizes the downsampling degradation as a kind of transformation for self-supervised signals to explore the equivariant representation against various resolutions and other degradation conditions. The Auto Encoding Resolution in Self-supervision (AERIS) framework could further take the advantage of advanced SR architectures with an arbitrary resolution restoring decoder to reconstruct the original correspondence from the degraded input image. Both the representation learning and object detection are optimized jointly in an end-to-end training fashion. The generic AERIS framework could be implemented on various mainstream object detection architectures from CNN to Transformer. The extensive experiments show that our methods has achieved superior performance compared with existing methods when facing variant degradation situations.
Interspeech 2022
SATTS: Speaker Attractor Text to Speech, Learning to Speak by Learning to Separate
Nabarun Goswami, Tatsuya Harada
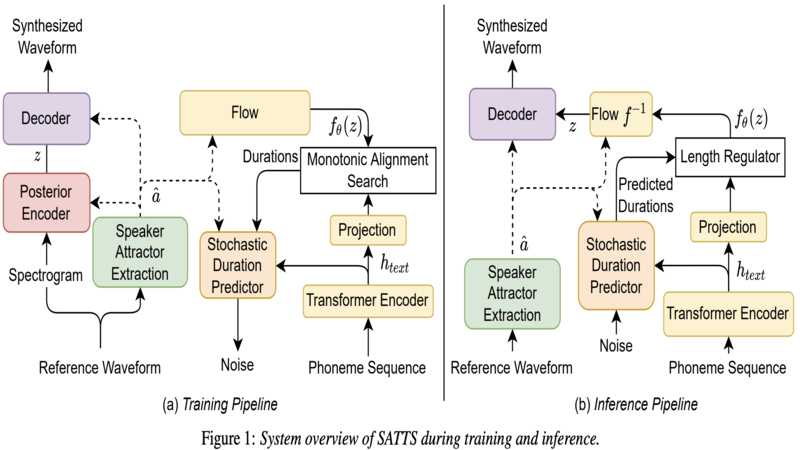 The mapping of text to speech (TTS) is non-deterministic, letters may be pronounced differently based on context, or phonemes can vary depending on various physiological and stylistic factors like gender, age, accent, emotions, etc. Neural speaker embeddings, trained to identify or verify speakers are typically used to represent and transfer such characteristics from reference speech to synthesized speech. Speech separation on the other hand is the challenging task of separating individual speakers from an overlapping mixed signal of various speakers. Speaker attractors are high-dimensional embedding vectors that pull the time-frequency bins of each speaker's speech towards themselves while repelling those belonging to other speakers. In this work, we explore the possibility of using these powerful speaker attractors for zero-shot speaker adaptation in multi-speaker TTS synthesis and propose speaker attractor text to speech (SATTS). Through various experiments, we show that SATTS can synthesize natural speech from text from an unseen target speaker's reference signal which might have less than ideal recording conditions, i.e. reverberations or mixed with other speakers.
The mapping of text to speech (TTS) is non-deterministic, letters may be pronounced differently based on context, or phonemes can vary depending on various physiological and stylistic factors like gender, age, accent, emotions, etc. Neural speaker embeddings, trained to identify or verify speakers are typically used to represent and transfer such characteristics from reference speech to synthesized speech. Speech separation on the other hand is the challenging task of separating individual speakers from an overlapping mixed signal of various speakers. Speaker attractors are high-dimensional embedding vectors that pull the time-frequency bins of each speaker's speech towards themselves while repelling those belonging to other speakers. In this work, we explore the possibility of using these powerful speaker attractors for zero-shot speaker adaptation in multi-speaker TTS synthesis and propose speaker attractor text to speech (SATTS). Through various experiments, we show that SATTS can synthesize natural speech from text from an unseen target speaker's reference signal which might have less than ideal recording conditions, i.e. reverberations or mixed with other speakers.
(DEMO)
CVPR 2022
Lepard: Learning partial point cloud matching in rigid and deformable scenes
Yang Li, Tatsuya Harada
 We present Lepard, a Learning based approach for partial point cloud matching in rigid and deformable scenes.
The key characteristics are the following techniques that exploit 3D positional knowledge for point cloud matching: 1) An architecture that disentangles point cloud representation into feature space and 3D position space.
2) A position encoding method that explicitly reveals 3D relative distance information through the dot product of vectors.
3) A repositioning technique that modifies the crosspoint-cloud relative positions. Ablation studies demonstrate the effectiveness of the above techniques.
In rigid cases, Lepard combined with RANSAC and ICP demonstrates state-of-the-art registration recall of 93.9% / 71.3% on the 3DMatch / 3DLoMatch.
In deformable cases, Lepard achieves +27.1% / +34.8% higher non-rigid feature matching recall than the prior art on our newly constructed 4DMatch / 4DLoMatch benchmark.
We present Lepard, a Learning based approach for partial point cloud matching in rigid and deformable scenes.
The key characteristics are the following techniques that exploit 3D positional knowledge for point cloud matching: 1) An architecture that disentangles point cloud representation into feature space and 3D position space.
2) A position encoding method that explicitly reveals 3D relative distance information through the dot product of vectors.
3) A repositioning technique that modifies the crosspoint-cloud relative positions. Ablation studies demonstrate the effectiveness of the above techniques.
In rigid cases, Lepard combined with RANSAC and ICP demonstrates state-of-the-art registration recall of 93.9% / 71.3% on the 3DMatch / 3DLoMatch.
In deformable cases, Lepard achieves +27.1% / +34.8% higher non-rigid feature matching recall than the prior art on our newly constructed 4DMatch / 4DLoMatch benchmark.
(PDF)
(CODE)
Watch It Move: Unsupervised Discovery of 3D Joints for Re-Posing of Articulated Objects
Atsuhiro Noguchi, Umar Iqbal, Jonathan Tremblay, Tatsuya Harada, Orazio Gallo
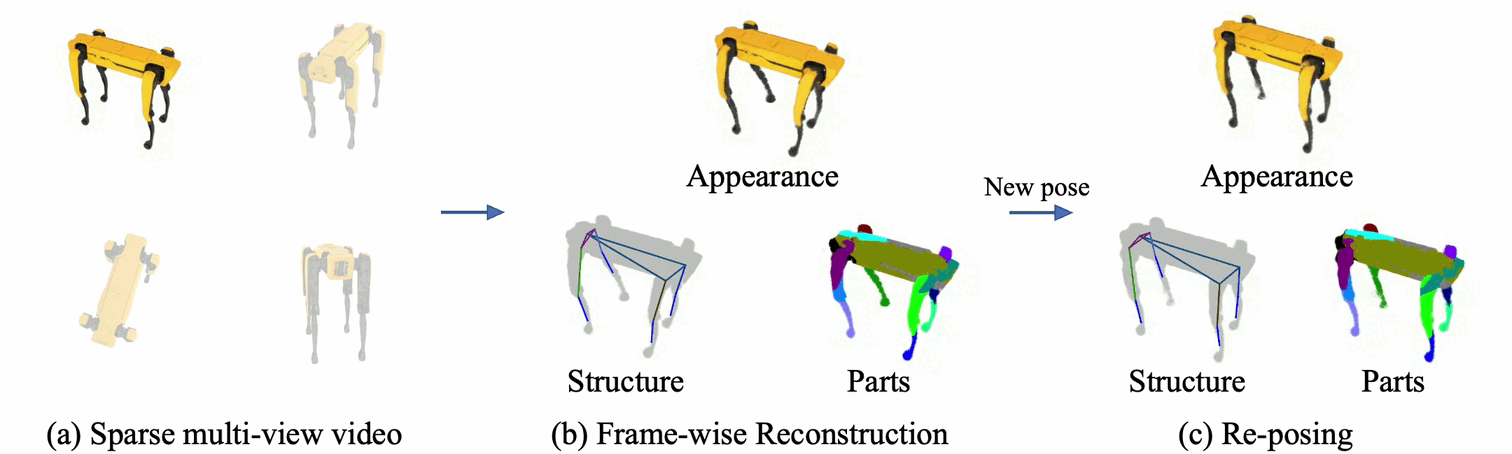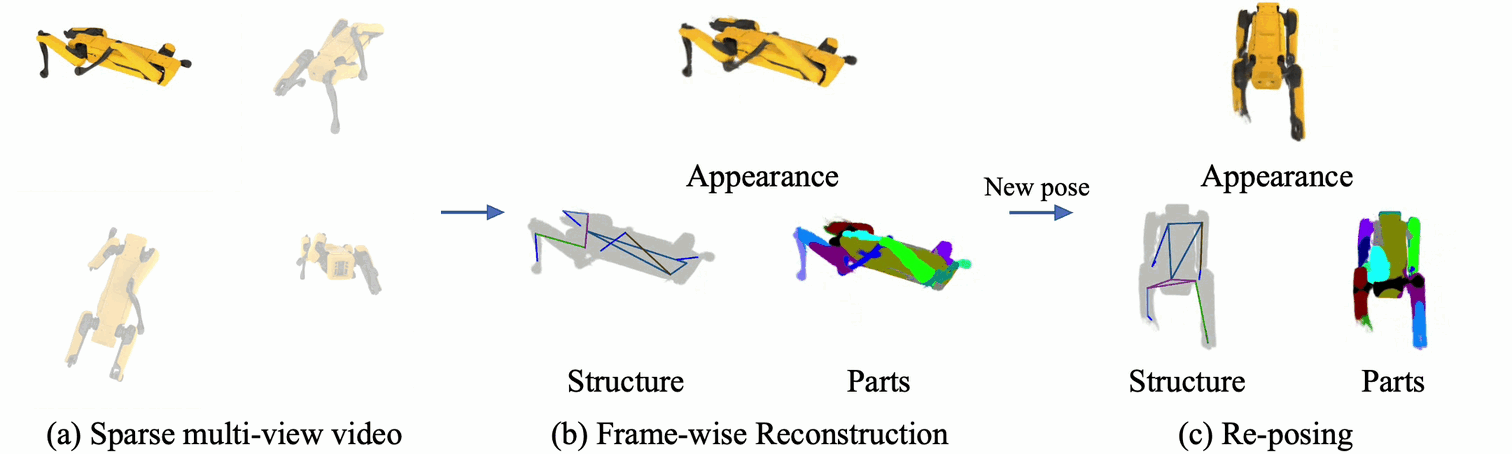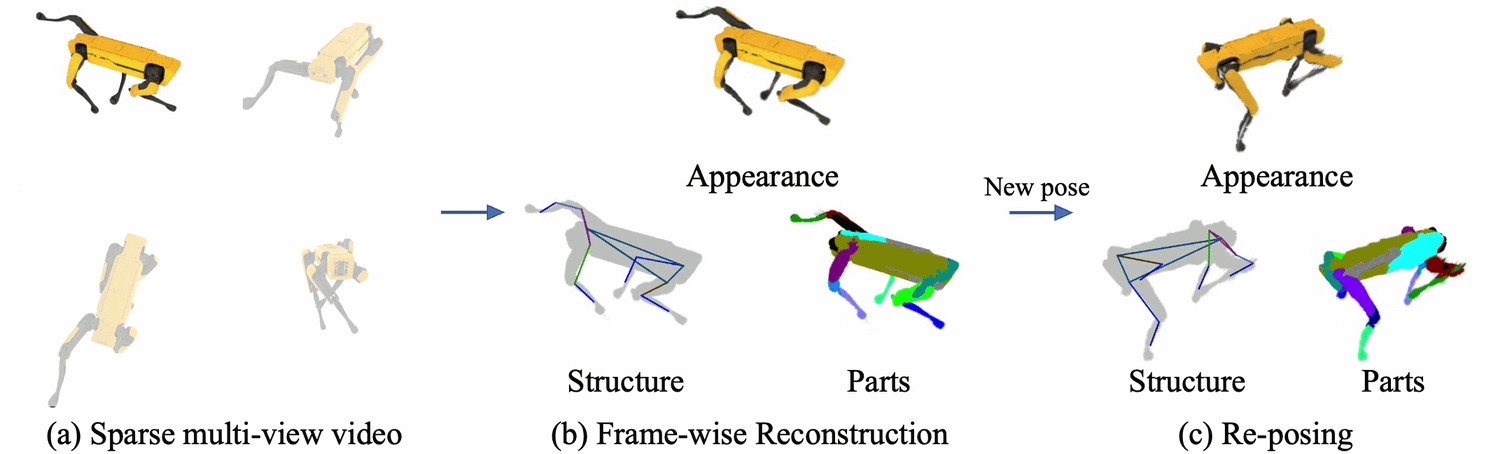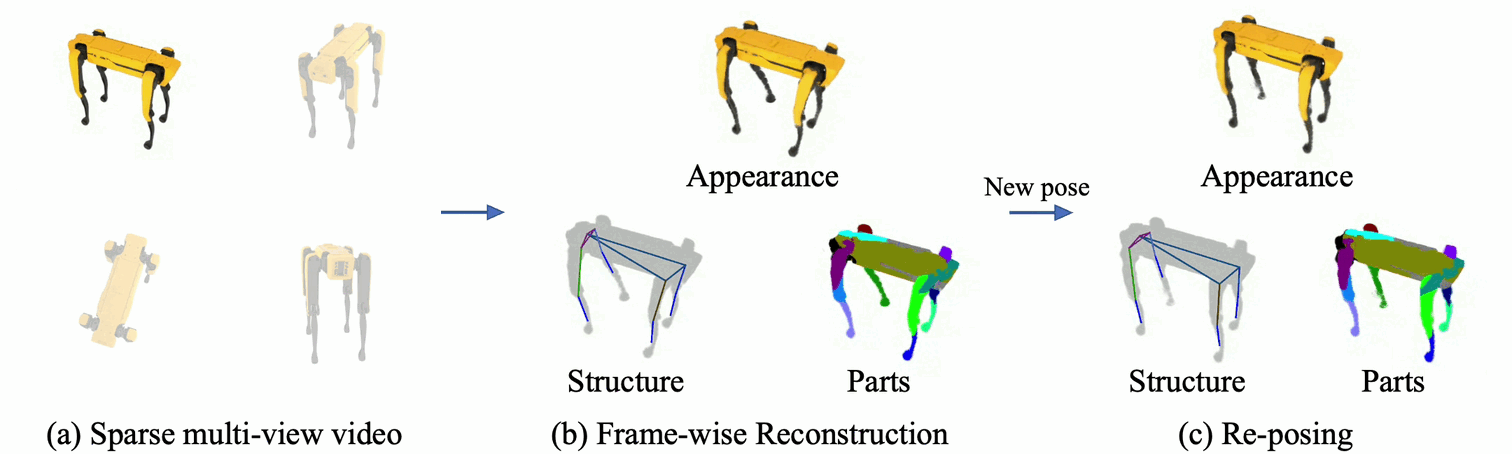 Rendering articulated objects while controlling their poses is critical to applications such as virtual reality or animation for movies.
Manipulating the pose of an object, however, requires the understanding of its underlying structure, that is, its joints and how they interact with each other.
Unfortunately, assuming the structure to be known, as existing methods do, precludes the ability to work on new object categories.
We propose to learn both the appearance and the structure of previously unseen articulated objects by observing them move from multiple views, with no additional supervision, such as joints annotations, or information about the structure.
Our insight is that adjacent parts that move relative to each other must be connected by a joint.
To leverage this observation, we model the object parts in 3D as ellipsoids, which allows us to identify joints. We combine this explicit representation with an implicit one that compensates for the approximation introduced.
We show that our method works for different structures, from quadrupeds, to single-arm robots, to humans.
Rendering articulated objects while controlling their poses is critical to applications such as virtual reality or animation for movies.
Manipulating the pose of an object, however, requires the understanding of its underlying structure, that is, its joints and how they interact with each other.
Unfortunately, assuming the structure to be known, as existing methods do, precludes the ability to work on new object categories.
We propose to learn both the appearance and the structure of previously unseen articulated objects by observing them move from multiple views, with no additional supervision, such as joints annotations, or information about the structure.
Our insight is that adjacent parts that move relative to each other must be connected by a joint.
To leverage this observation, we model the object parts in 3D as ellipsoids, which allows us to identify joints. We combine this explicit representation with an implicit one that compensates for the approximation introduced.
We show that our method works for different structures, from quadrupeds, to single-arm robots, to humans.
(PROJECT PAGE)