Visual Question Answering(VQA)
VQAとは
Visual Question Answering(VQA)とは,ある画像とその画像に関する質問を提示されたときに,正しい答えを導き出すタスクです. このというタスクが広く知られるようになったきっかけは,2016年のCVPR(画像認識に関する著名な国際学会)でコンペティションが行われたことです. このコンペティションは,数十万規模の質問文,画像,そして回答が含まれたデータセットを用いて,VQAを解くモデルを学習させ,その性能を競うというものでした. データセットに含まれる質問文は,YES/NOで答えられるものから,画像に何が映っているかを答えるもの,物体の数を答えなければならないものまで,様々な難易度・種類のものが用意されています.

画像と画像に対する質問文の例(参考文献1から引用)
なお,このコンペでは,自然画像に対する質問文に回答する部門と,アブストラクト画像(クリップアートの組み合わせ)に対する質問文に回答する部門が用意されていました.
さて,画像や音,言語などのことを,それぞれ「モダリティ」と呼びます.VQAは,画像と言語という二つのモダリティを扱ったタスクということができます. このような,ひとつのモダリティではなく複数のモダリティを対象とする「マルチモーダル」な研究というのは,これまでも行われてきました. 例えば,画像についての説明文を生成する研究などは,弊研究室でもいろいろな取り組みがなされています. マルチモーダルな研究の中でも,VQAは,ヒトとAIがコミュニケーションを取る上で大きな一歩になると期待されています.
この研究室の独自性と成果
VQAに関する多くの研究では,アテンション(attention,注意)の取扱を組み込んだモデルが用いられています. このようなモデルというのは,質問文と画像が投げかけられたときに,「質問文に応じて画像のどこに注目すれば適切な答えが得られるのか」というものを考えるモデルです. これまで,多くの精度の高いモデルはそういった枠組みを使っていました. しかし,アブストラクト画像は,実画像と異なる特徴を持つので,実画像と同じようにアテンションの手法を適用しても性能改善が見込めないという問題点があります.
そこで,我々はアテンションを使うのではなく,画像の情報と文章の情報をどう混ぜ合わせるのかに注目して研究を行いました. VQAにおいては,質問文の内容に基づいて画像中のどういう情報を持ってくればいいのかが概ね決定されるため,具体的に画像中のどこに注目するのかを考えるより,どのように混ぜ合わせるのかを考えよう,というアプローチです. 結果としては,我々が今回提案した手法は,実画像のみならず,従来手法が苦手としていたアブストラクト画像でも,適用可能なものとなりました. 冒頭に挙げたコンペティションでは,実画像部門で世界8位となりました.アブストラクト画像部門では,よりアブストラクト画像に特化した別の手法で世界1位となっていますが,実画像に適用した手法でも世界1位(当時)相当の精度が出ることを確認しています.

アブストラクト画像に対する質問文と生成された回答の例(参考文献2から引用)
VQG
VQAに関連する研究として,画像に関する質問文を生成する「VQG」(Visual Question Generation)という研究分野もあります. ロボットのように実世界で人間とともにはたらく知能システムにとって,「分からないこと」について人間に質問することは,極めて重要なコミュニケーション能力と考えられます.
弊研究室では,VQGによって画像についての情報獲得を行うための研究が行われてきました. 従来のVQGの研究では,画像に関連した質問を生成することそのものが目標になっていることが多く,「何を目的として」質問生成をするかに関する明確なアプローチは存在しませんでした. 我々の研究室では,「画像中の未知物体に関する情報を獲得する」という目的のためのVQG手法を提案し,人間による評価でも従来手法よりも高い評価を受けました.

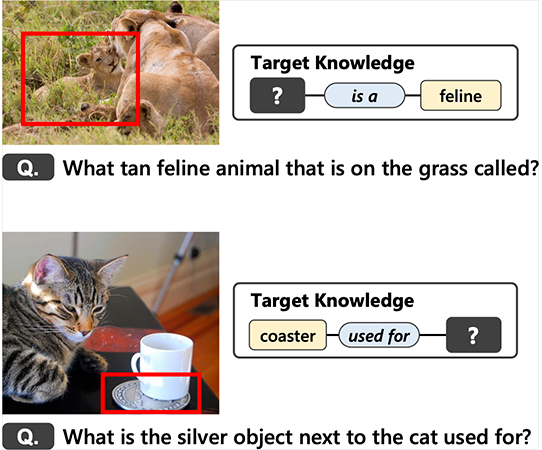
さらに,質問によって獲得できる「知識」に注目したVQGの研究も行っています.
この研究では,「質問」と「獲得できる知識」がセットになった大規模データセットを新規に構築しました.
さらに,構築したデータセットを用いて質問生成モデルの訓練を行い,「狙った知識を正確に獲得できるVQG」を実現しました.
たとえば,下図の上の例では,画像中のネコ科の動物(feline)の名前という「知識」を獲得するための質問生成が行われています.
参考文献
- Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, Devi Parikh, "VQA: Visual Question Answering", International Conference on Computer Vision (ICCV 2015), 2015
- Kuniaki Saito, Andrew Shin, Yoshitaka Ushiku, Tatsuya Harada, "DUALNET: DOMAIN-INVARIANT NETWORK FOR VISUAL QUESTION ANSWERING", The 18th IEEE International Conference on Multimedia and Expo (ICME 2017), 2017
- Kohei Uehara, Antonio Tejero-de-Pablos, Yoshitaka Ushiku and Tatsuya Harada. Visual Question Generation for Class Acquisition of Unknown Objects. The 15th European Conference on Computer Vision (ECCV2018), 2018.
- Kohei Uehara and Tatsuya Harada. K-VQG: Knowledge-aware Visual Question Generation for Common-sense Acquisition. WACV, 2023.