Visual Question Answering (VQA)
About VQA
Visual Question Answering (VQA) is a task where the goal is to find the correct answer when given an image and a question about the image. This task became widely known after a competition was held at CVPR (one of the most famous international conference on computer vision) in 2016. This competition involved training models to solve VQA task using a dataset containing hundreds of thousands of questions, images, and answers. The questions in the dataset varied in difficulty and type, ranging from those that could be answered with a simple yes/no, to ones that required identifying what is depicted in the image or counting the number of objects.

Example of image and corresponding questions (Quoted from Reference 1)
In this competition, there were divisions for answering questions about natural images and abstract images (i.e., combinations of clip art).
In this research field, we call terms like image, sound, and language are referred to as 'modalities'. VQA can be considered a task that deals with two modalities: images and language. This kind of 'multimodal' research that targets multiple modalities, not just one, has been conducted before; for example, research to generate descriptive sentences about images is one such endeavor our lab has undertaken. Among these multimodal researches, VQA is expected to be a significant step towards enabling effective communication between humans and AI.
Uniqueness and Achievement of This Lab in VQA
In many VQA studies, models incorporating attention mechanisms are used. These models determine where in the image to focus in response to a given question, in order to provide a suitable answer. Many highly accurate models have used such a framework. However, abstract images possess different characteristics from real images, so the same attention mechanisms may not lead to performance improvements when applied to abstract images.
Therefore, we focused our research on how to fuse image information and text information, rather than using attention. In VQA, it is generally determined what information to take from the image based on the content of the question. So, our approach is to consider how to fuse these two information rather than specifically where to pay attention in the image. As a result, the method we proposed can be applied not only to real images but also to abstract images, which traditional methods struggled with. In the aforementioned competition, our method achieved 8th place in the real image division, and modified method specialized for abstract images won first place in the abstract image division. Later, we confirmed that the method we applied to real images could also achieve performance equivalent to state-of-the-art at the time.

Example of question and generated answer for abstract images (Quoted from Reference 2)
VQG
In relation to VQA, there is also a field of study called Visual Question Generation (VQG), which involves generating questions about images. For intelligent systems like robots working alongside humans in the real world, the ability to ask humans questions about 'unknown things' is considered extremely important.
Our lab has been conducting research to acquire information about images using VQG. In traditional VQG research, the goal has often been simply to generate questions related to the image, with no clear approach regarding 'what purpose' the question generation serves. In our lab, we proposed a VQG method for the purpose of 'acquiring information about unknown objects in images' and received higher evaluations from humans than conventional methods.

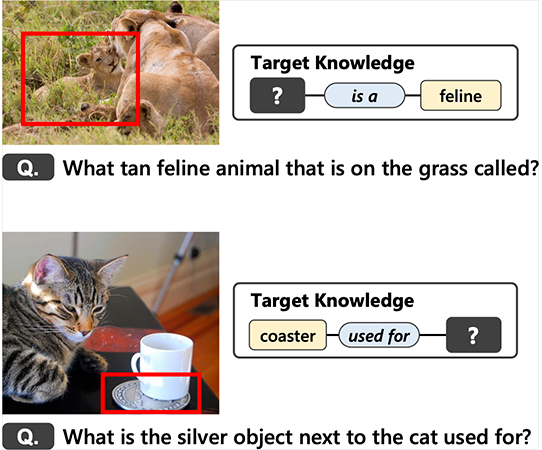
Furthermore, we are conducting VQG research focused on the 'knowledge' that can be acquired through questions. In this research, we newly constructed a large-scale dataset in which 'questions' and 'acquirable knowledge' are paired. Additionally, using the new dataset, we trained a question generation model and achieved a VQG that can accurately acquire targeted knowledge. For instance, in the example below, a question is generated to acquire the 'knowledge' of the name of the feline animal in the image.
References
- Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, Devi Parikh, "VQA: Visual Question Answering", International Conference on Computer Vision (ICCV 2015), 2015
- Kuniaki Saito, Andrew Shin, Yoshitaka Ushiku, Tatsuya Harada, "DUALNET: DOMAIN-INVARIANT NETWORK FOR VISUAL QUESTION ANSWERING", The 18th IEEE International Conference on Multimedia and Expo (ICME 2017), 2017
- Kohei Uehara, Antonio Tejero-de-Pablos, Yoshitaka Ushiku and Tatsuya Harada. Visual Question Generation for Class Acquisition of Unknown Objects. The 15th European Conference on Computer Vision (ECCV2018), 2018.
- Kohei Uehara and Tatsuya Harada. K-VQG: Knowledge-aware Visual Question Generation for Common-sense Acquisition. WACV, 2023.