Reinforcement Learning
What is reinforcement learning?
Reinforcement learning is a field of machine learning in which optimal behavior is learned through trial and error. Reinforcement learning has gained social attention since it was used to train AIs that defeated professional Go and Shogi players. Recently, reinforcement learning has also been used to train ChatGPT, a language generation AI.
In reinforcement learning, an environment for trial-and-error and a reward function for quantitatively evaluating behavior are given, and a strategy to maximize the expected value of the reward function is learned. In conventional machine learning, a dataset is given in advance, and models such as neural networks are trained using the dataset. In reinforcement learning, on the other hand, the agent, which is learning the data necessary for learning, collects the data autonomously through trial and error and learns the optimal policy. Reinforcement learning is used for a variety of tasks because it does not require prior preparation of training data.
Related work
In the field of reinforcement learning, various algorithms have been proposed to learn optimal strategies. A central theme that has been studied for many years is how to learn skills with fewer trials and errors. To address this problem, classical algorithms such as policy gradient and Q-learning [Watkins+, Machine Learning 1992], as well as actor-critic methods such as Soft Actor Critic [Haarnoja+, ICML2018] and TD3 [Fujimoto+,ICML2018] and other actor-critic methods have been developed. In addition, meta-learning [Finn+,ICML2017], which learns a meta-model to quickly adapt to a given task, multi-task reinforcement learning [Kalashnikov+,CoRL2022], which learns multiple tasks simultaneously, and the learning of a new task from past experience have also been developed. Off-line reinforcement learning [Levine+, arXiv 2020], which tries to utilize past experience for learning new tasks, and many other topics are being actively researched.
Originality of this lab
In our laboratory, we are working on an approach to reinforcement learning in which a variety of behaviors are learned simultaneously. In reinforcement learning, it is known that there are often multiple optimal behaviors for a single task. By learning multiple optimal behaviors, when there is a change in the environment or task, the system can adapt to the new environment or task by simply selecting the most suitable one from the learned behaviors. In our recent work, we developed an algorithm that discovers multiple solutions from a single task in offline reinforcement learning [Osa&Harada, ICML2024]. For example, in the figure below, the agent in the simulation has discovered multiple behaviors for walking. (z=[-1.64, -1.64] for one-legged hopping, z=[0,0] for bipedal walking, etc.)
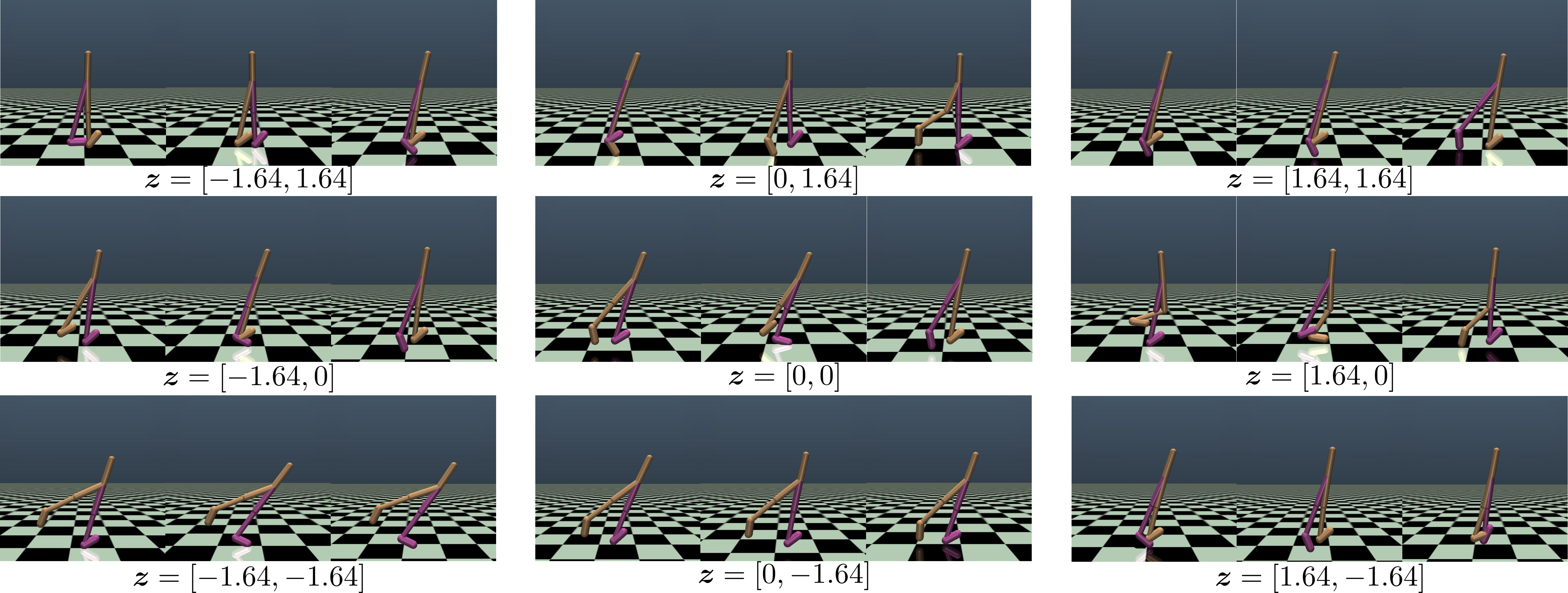
Diverse locomotion behaviors obtained by RL
When the agent's body structure changes, the system can adapt by selecting a walking style from the previously learned walking styles that is suitable for the agent after the change. Based on past experience, humans use a variety of movements to adapt to different situations. We believe that by continuing this research, we can build a human-like adaptive system that uses different behaviors depending on the situation.
One benefit of learning diverse behaviors is that it can be utilized in multi-agent reinforcement learning to learn robust policies that are resistant to changes in other agents' behavior. In recent research in our lab, we have proposed a framework for learning the movements of a caregiving robot while autonomously generating diverse movements of the care recipient, aiming to learn robust policies for handling the diverse movements of the care recipient in the context of a dining care task [Osa & Harada, ICRA 2024]
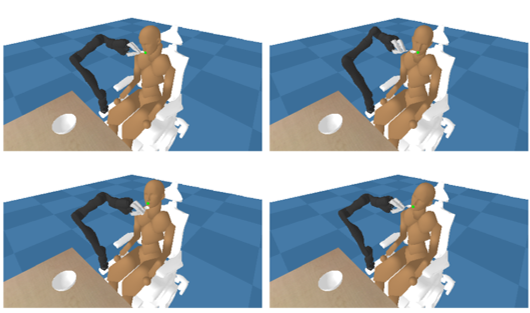
Policy learning in assistive tasks.
Future research directions
Reinforcement learning is one of the fastest growing areas of machine learning as a whole, with a very large number of publications. The time required for learning is gradually decreasing, and the range of real-world applications is expected to continue to expand. Reinforcement learning differs from language and image tasks in that the "body" in which the trial-and-error process is performed is important. Like the emergence of large-scale models in language and image generation AI, large-scale models are also being introduced in reinforcement learning [Brohan+ arXiv 2022], and our lab is participating in projects such as the Open-X-Embodiment Project [Open X-Embodiment Collaboration, ICRA 2024], contributing with data and other resources.
However, the ability to learn quickly on a small scale with a specific body remains an important aspect of reinforcement learning research and will continue to be significant in the future.
References
- Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning Vol. 8, pages 229–256, 1992.
- Christopher J. C. H. Watkins and Peter Dayan. Q-learning. Machine Learning, Vol. 8, pages 279–292, 1992.
- Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, Sergey Levine. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. Proceedings of the 35th International Conference on Machine Learning, PMLR 80:1861-1870, 2018.
- Scott Fujimoto, Herke Hoof, David Meger. Addressing Function Approximation Error in Actor-Critic Methods. Proceedings of the 35th International Conference on Machine Learning, PMLR 80:1587-1596, 2018.
- Chelsea Finn, Pieter Abbeel, Sergey Levine. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. Proceedings of the 34th International Conference on Machine Learning, PMLR 70:1126-1135, 2017.
- Dmitry Kalashnikov, Jake Varley, Yevgen Chebotar, Benjamin Swanson, Rico Jonschkowski, Chelsea Finn, Sergey Levine, Karol Hausman. Scaling Up Multi-Task Robotic Reinforcement Learning. Proceedings of the 5th Conference on Robot Learning, PMLR 164:557-575, 2022.
- Sergey Levine, Aviral Kumar, George Tucker, Justin Fu. Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems. arXiv, 2020.
- Takayuki Osa and Tatsuya Harada. Discovering Multiple Solutions from a Single Task in Offline Reinforcement Learning. Proceedings of the International Conference on Machine Learning (ICML), 2024.
- Takayuki Osa and Tatsuya Harada. Robustifying a Policy in Multi-Agent RL with Diverse Cooperative Behaviors and Adversarial Style Sampling for Assistive Tasks. Proceedings of the IEEE International Conference on Robotics and Automation, 2024 (arXiv).
- Anthony Brohan et al. RT-1: Robotics Transformer for Real-World Control at Scale. arXiv, 2022.
- Open X-Embodiment Collaboration (173 authors, including Takayuki Osa and Tatsuya Harada). Open X-Embodiment: Robotic Learning Datasets and RT-X Models. Proceedings of the IEEE International Conference on Robotics and Automation, 2024.