Domain Adaptation
What is Domain Adaptation?
Advances in deep neural network (DNN) research have led to high performance in tasks such as image identification. However, training a discriminative model using a DNN requires a large number of samples with teacher labels (ground truth labels).
The cost of collecting a large number of teacher labels is quite high. Therefore, methods have been explored to train with fewer labels or to use labels from other datasets.
Domain Adaptation is a type of learning technique called Transfer Learning. By applying knowledge obtained from a domain with sufficient teacher labels (Source Domain) to a target domain without sufficient information (Target Domain), a discriminator that works with high accuracy in the target domain is learned, Domain refers to a collection of data.
In particular, when the target domain has no labels at all, it is called Unsupervised Domain Adaptation (UDA) and is the most difficult task in domain adaptation.

Discriminative models learned using the teacher labels of synthetic images can be applied to real images, for example.
Related work
The mainstream idea in domain adaptation research is to apply discriminators learned using the source domain to the target domain by approximating the distribution of samples in the target domain to the distribution in the source domain.
The application of adversarial learning is a well-known method for achieving this idea. However, since this method only approximates the distribution, it has the problem of inaccurate discrimination around the boundaries of the classifiers.
Contributions and Results
Our laboratory has published various research results on domain adaptation in recent years.
The problem with conventional methods is that their discriminability with respect to the target domain is not sufficiently guaranteed [Saito et al. In [Saito et al., 2017 ICML], we proposed a method that accurately attaches pseudo-labels to samples in the target domain and uses them for learning.
In [Saito et al., 2018 CVPR], we devised a method to match the target domain to the distribution of each class in the source domain, rather than matching the distributions of the target and source domains. This new learning method builds two class discriminators and focuses on the discrepancy (discrepancy) between these estimation results. The two discriminators are updated to increase the discrepancy (Maximize Discrepancy in the figure below). Feature extraction from the target domain is updated in the direction of smaller discrepancy("Minimize Discrepancy" in the below image.). This adversarial learning brings the target domain closer to the distribution considering the boundaries of the class discriminator, and identification at the boundaries is also more accurate.
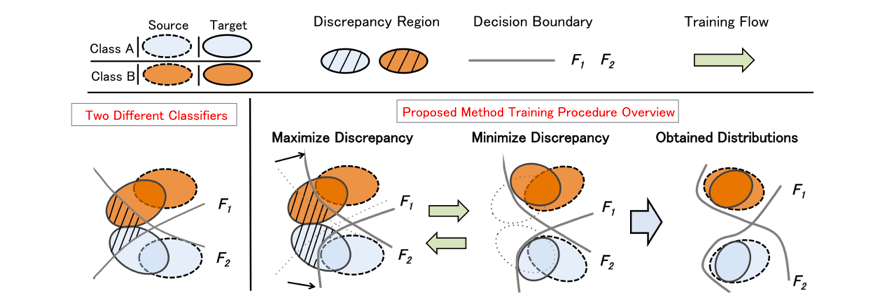
Proposed method based on the discrepancy [Saito et al., 2018 CVPR]
In the work [Westfechtel et al., 2023 WACV], we introduced a classifier-based backprop-induced weighting of the feature space. The weighting allows the adaptation network focus on features that are important for the classification, and, secondly, it the approach couples classification and adversarial branch more closely.
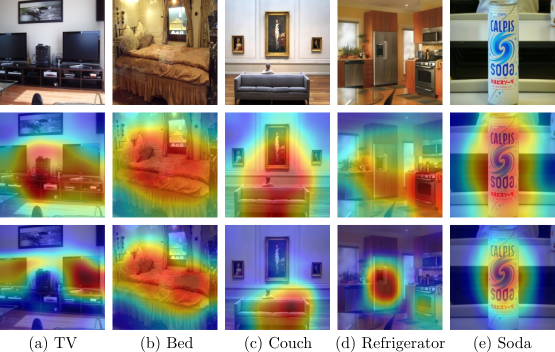
Visualization of the focused regions for the adaptation process. Second row DANN, last row proposed method. [Westfechtel et al., 2023 WACV]
Future research directions
When considering the application of domain adaptation methods to a more realistic setting, it is necessary to detect samples of classes that were not present in the source domain but may appear in the target domain, and adapt them to the target domain. In such cases, it is necessary to infer that a class is unknown if it did not exist in the source domain. Such a condition is called open set domain adaptation, which is a more difficult task that we are working on in our laboratory.
References
- Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada. Asymmetric Tri-training for Unsupervised Domain Adaptation. The 34th International Conference on Machine Learning (ICML 2017), 2017.(PDF)
- Kuniaki Saito, Yusuke Mukuta, Yoshitaka Ushiku, Tatsuya Harada. Deep Modality Invariant Adversarial Network for Shared Representation Learning. The 16th International Conference on Computer Vision Workshop on Transferring and Adapting Source Knowledge in Computer Vision (ICCV 2017, Workshop), 2017.(PDF)
- Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada, Kate Saenko. Adversarial Dropout Regularization. The 6th International Conference on Learning Representations (ICLR 2018), 2018.(PDF)(PROJECT PAGE)
- Kuniaki Saito, Kohei Watanabe, Yoshitaka Ushiku, Tatsuya Harada. Maximum Classifier Discrepancy for Unsupervised Domain Adaptation. The 31th IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2018), 2018, (oral).(PDF)(PROJECT PAGE)
- Thomas Westfechtel, HaoWei Yeh, Qier Meng, Yusuke Mukuta, Tatsuya Harada. Backprop Induced Feature Weighting for Adversarial Domain Adaptation with Iterative Label Distribution Alignment. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023 (PDF)